 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Online Learning Approach to Interpolation and Extrapolation in Domain Generalization
Feb 25, 2021A popular assumption for out-of-distribution generalization is that the training data comprises sub-datasets, each drawn from a distinct distribution; the goal is then to "interpolate" these distributions and "extrapolate" beyond them -- this objective is broadly known as domain generalization. A common belief is that ERM can interpolate but not extrapolate and that the latter is considerably more difficult, but these claims are vague and lack formal justification. In this work, we recast generalization over sub-groups as an online game between a player minimizing risk and an adversary presenting new test distributions. Under an existing notion of inter- and extrapolation based on reweighting of sub-group likelihoods, we rigorously demonstrate that extrapolation is computationally much harder than interpolation, though their statistical complexity is not significantly different. Furthermore, we show that ERM -- or a noisy variant -- is provably minimax-optimal for both tasks. Our framework presents a new avenue for the formal analysis of domain generalization algorithms which may be of independent interest.
The Risks of Invariant Risk Minimization
Oct 12, 2020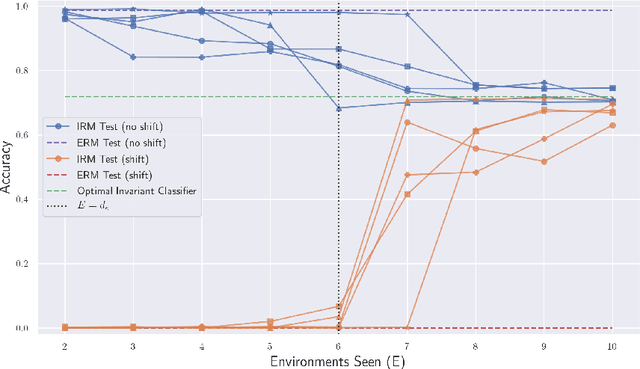
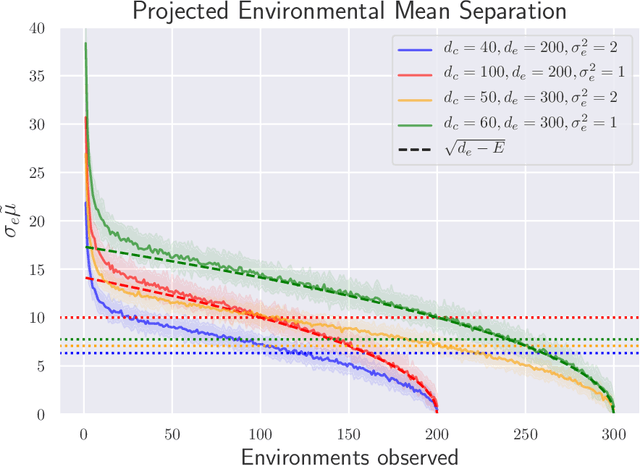
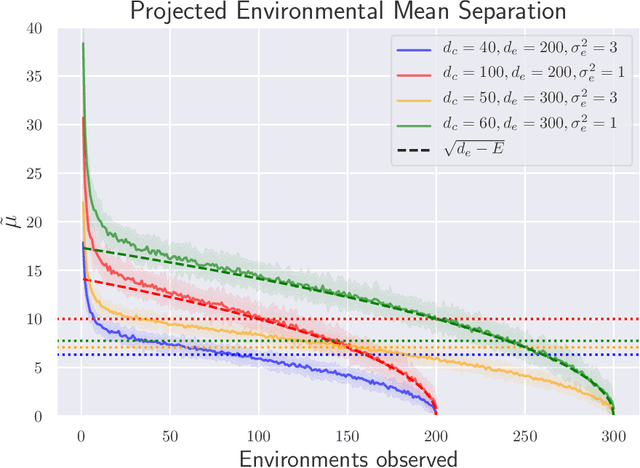
Invariant Causal Prediction (Peters et al., 2016) is a technique for out-of-distribution generalization which assumes that some aspects of the data distribution vary across the training set but that the underlying causal mechanisms remain constant. Recently, Arjovsky et al. (2019) proposed Invariant Risk Minimization (IRM), an objective based on this idea for learning deep, invariant features of data which are a complex function of latent variables; many alternatives have subsequently been suggested. However, formal guarantees for all of these works are severely lacking. In this paper, we present the first analysis of classification under the IRM objective$-$as well as these recently proposed alternatives$-$under a fairly natural and general model. In the linear case, we show simple conditions under which the optimal solution succeeds or, more often, fails to recover the optimal invariant predictor. We furthermore present the very first results in the non-linear regime: we demonstrate that IRM can fail catastrophically unless the test data are sufficiently similar to the training distribution$-$this is precisely the issue that it was intended to solve. Thus, in this setting we find that IRM and its alternatives fundamentally do not improve over standard Empirical Risk Minimization.
Representational aspects of depth and conditioning in normalizing flows
Oct 02, 2020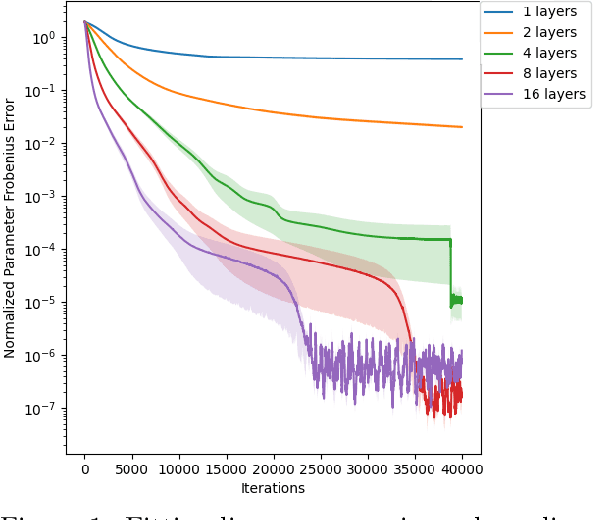
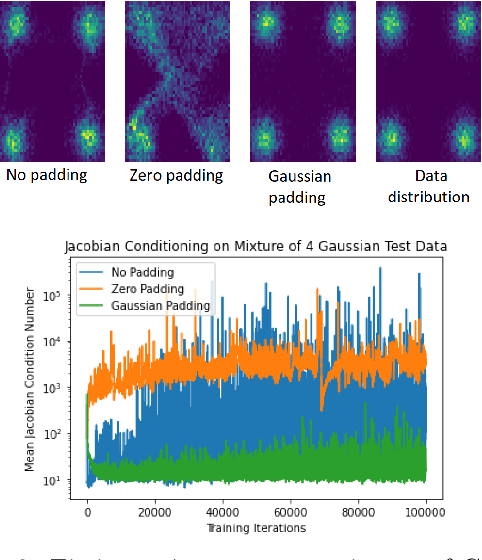
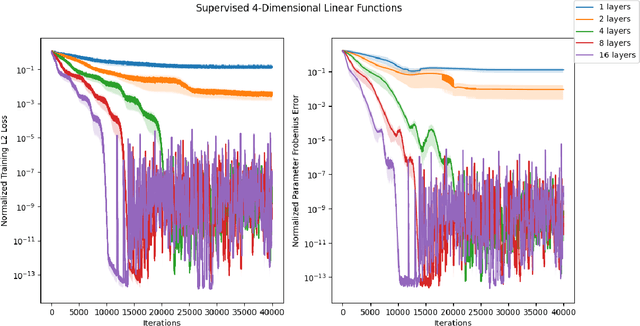
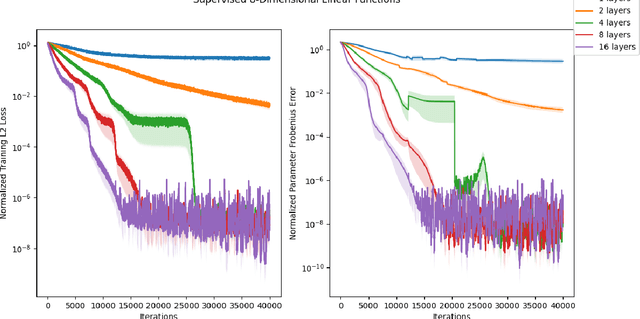
Normalizing flows are among the most popular paradigms in generative modeling, especially for images, primarily because we can efficiently evaluate the likelihood of a data point. Normalizing flows also come with difficulties: models which produce good samples typically need to be extremely deep -- which comes with accompanying vanishing/exploding gradient problems. Relatedly, they are often poorly conditioned since typical training data like images intuitively are lower-dimensional, and the learned maps often have Jacobians that are close to being singular. In our paper, we tackle representational aspects around depth and conditioning of normalizing flows -- both for general invertible architectures, and for a particular common architecture -- affine couplings. For general invertible architectures, we prove that invertibility comes at a cost in terms of depth: we show examples where a much deeper normalizing flow model may need to be used to match the performance of a non-invertible generator. For affine couplings, we first show that the choice of partitions isn't a likely bottleneck for depth: we show that any invertible linear map (and hence a permutation) can be simulated by a constant number of affine coupling layers, using a fixed partition. This shows that the extra flexibility conferred by 1x1 convolution layers, as in GLOW, can in principle be simulated by increasing the size by a constant factor. Next, in terms of conditioning, we show that affine couplings are universal approximators -- provided the Jacobian of the model is allowed to be close to singular. We furthermore empirically explore the benefit of different kinds of padding -- a common strategy for improving conditioning -- on both synthetic and real-life datasets.
Efficient sampling from the Bingham distribution
Sep 30, 2020We give a algorithm for exact sampling from the Bingham distribution $p(x)\propto \exp(x^\top A x)$ on the sphere $\mathcal S^{d-1}$ with expected runtime of $\operatorname{poly}(d, \lambda_{\max}(A)-\lambda_{\min}(A))$. The algorithm is based on rejection sampling, where the proposal distribution is a polynomial approximation of the pdf, and can be sampled from by explicitly evaluating integrals of polynomials over the sphere. Our algorithm gives exact samples, assuming exact computation of an inverse function of a polynomial. This is in contrast with Markov Chain Monte Carlo algorithms, which are not known to enjoy rapid mixing on this problem, and only give approximate samples. As a direct application, we use this to sample from the posterior distribution of a rank-1 matrix inference problem in polynomial time.
On Learning Language-Invariant Representations for Universal Machine Translation
Aug 11, 2020
The goal of universal machine translation is to learn to translate between any pair of languages, given a corpus of paired translated documents for \emph{a small subset} of all pairs of languages. Despite impressive empirical results and an increasing interest in massively multilingual models, theoretical analysis on translation errors made by such universal machine translation models is only nascent. In this paper, we formally prove certain impossibilities of this endeavour in general, as well as prove positive results in the presence of additional (but natural) structure of data. For the former, we derive a lower bound on the translation error in the many-to-many translation setting, which shows that any algorithm aiming to learn shared sentence representations among multiple language pairs has to make a large translation error on at least one of the translation tasks, if no assumption on the structure of the languages is made. For the latter, we show that if the paired documents in the corpus follow a natural \emph{encoder-decoder} generative process, we can expect a natural notion of ``generalization'': a linear number of language pairs, rather than quadratic, suffices to learn a good representation. Our theory also explains what kinds of connection graphs between pairs of languages are better suited: ones with longer paths result in worse sample complexity in terms of the total number of documents per language pair needed. We believe our theoretical insights and implications contribute to the future algorithmic design of universal machine translation.
Fast Convergence for Langevin Diffusion with Matrix Manifold Structure
Feb 13, 2020In this paper, we study the problem of sampling from distributions of the form p(x) \propto e^{-\beta f(x)} for some function f whose values and gradients we can query. This mode of access to f is natural in the scenarios in which such problems arise, for instance sampling from posteriors in parametric Bayesian models. Classical results show that a natural random walk, Langevin diffusion, mixes rapidly when f is convex. Unfortunately, even in simple examples, the applications listed above will entail working with functions f that are nonconvex -- for which sampling from p may in general require an exponential number of queries. In this paper, we study one aspect of nonconvexity relevant for modern machine learning applications: existence of invariances (symmetries) in the function f, as a result of which the distribution p will have manifolds of points with equal probability. We give a recipe for proving mixing time bounds of Langevin dynamics in order to sample from manifolds of local optima of the function f in settings where the distribution is well-concentrated around them. We specialize our arguments to classic matrix factorization-like Bayesian inference problems where we get noisy measurements A(XX^T), X \in R^{d \times k} of a low-rank matrix, i.e. f(X) = \|A(XX^T) - b\|^2_2, X \in R^{d \times k}, and \beta the inverse of the variance of the noise. Such functions f are invariant under orthogonal transformations, and include problems like matrix factorization, sensing, completion. Beyond sampling, Langevin dynamics is a popular toy model for studying stochastic gradient descent. Along these lines, we believe that our work is an important first step towards understanding how SGD behaves when there is a high degree of symmetry in the space of parameters the produce the same output.
Benefits of Overparameterization in Single-Layer Latent Variable Generative Models
Jun 28, 2019
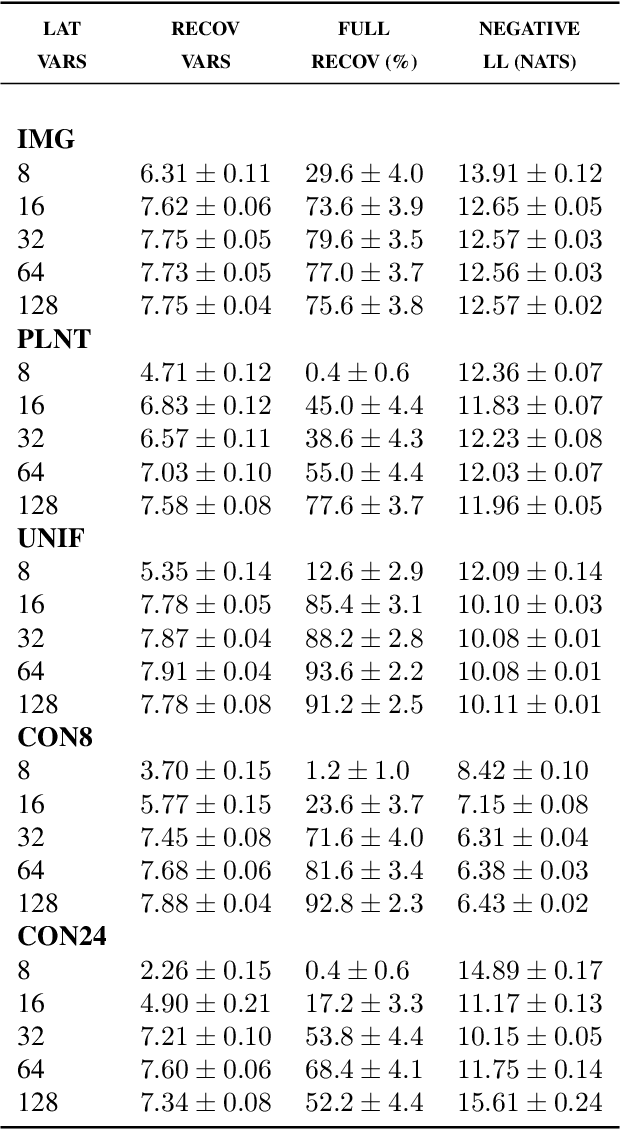
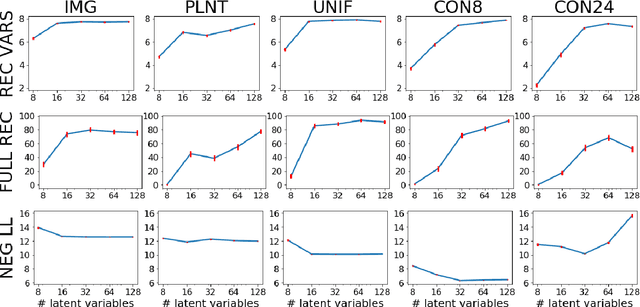
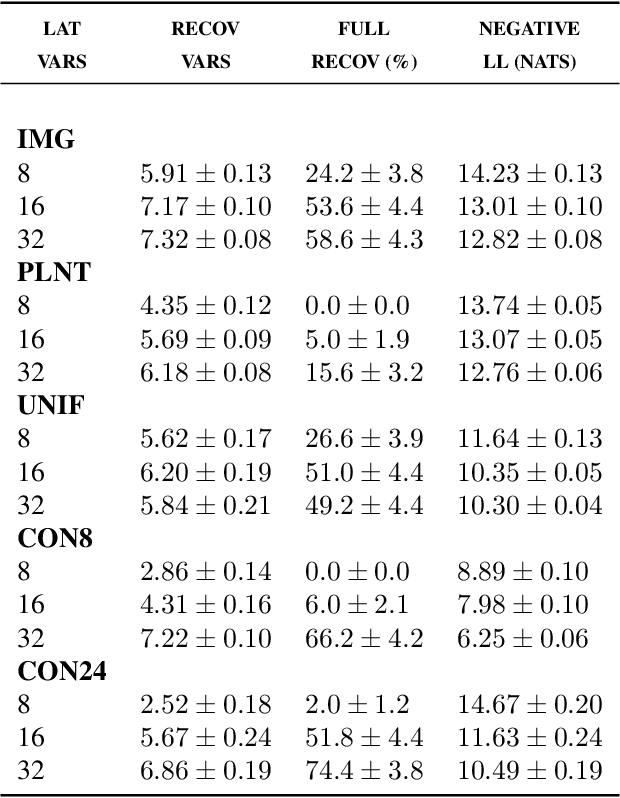
One of the most surprising and exciting discoveries in supervising learning was the benefit of overparametrization (i.e. training a very large model) to improving the optimization landscape of a problem, with minimal effect on statistical performance (i.e. generalization). In contrast, unsupervised settings have been under-explored, despite the fact that it has been observed that overparameterization can be helpful as early as Dasgupta & Schulman (2007). In this paper, we perform an exhaustive study of different aspects of overparameterization in unsupervised learning via synthetic and semi-synthetic experiments. We discuss benefits to different metrics of success (held-out log-likelihood, recovering the parameters of the ground-truth model), sensitivity to variations of the training algorithm, and behavior as the amount of overparameterization increases. We find that, when learning using methods such as variational inference, larger models can significantly increase the number of ground truth latent variables recovered.
Sum-of-squares meets square loss: Fast rates for agnostic tensor completion
May 30, 2019We study tensor completion in the agnostic setting. In the classical tensor completion problem, we receive $n$ entries of an unknown rank-$r$ tensor and wish to exactly complete the remaining entries. In agnostic tensor completion, we make no assumption on the rank of the unknown tensor, but attempt to predict unknown entries as well as the best rank-$r$ tensor. For agnostic learning of third-order tensors with the square loss, we give the first polynomial time algorithm that obtains a "fast" (i.e., $O(1/n)$-type) rate improving over the rate obtained by reduction to matrix completion. Our prediction error rate to compete with the best $d\times{}d\times{}d$ tensor of rank-$r$ is $\tilde{O}(r^{2}d^{3/2}/n)$. We also obtain an exact oracle inequality that trades off estimation and approximation error. Our algorithm is based on the degree-six sum-of-squares relaxation of the tensor nuclear norm. The key feature of our analysis is to show that a certain characterization for the subgradient of the tensor nuclear norm can be encoded in the sum-of-squares proof system. This unlocks the standard toolbox for localization of empirical processes under the square loss, and allows us to establish restricted eigenvalue-type guarantees for various tensor regression models, with tensor completion as a special case. The new analysis of the relaxation complements Barak and Moitra (2016), who gave slow rates for agnostic tensor completion, and Potechin and Steurer (2017), who gave exact recovery guarantees for the noiseless setting. Our techniques are user-friendly, and we anticipate that they will find use elsewhere.
Simulated Tempering Langevin Monte Carlo II: An Improved Proof using Soft Markov Chain Decomposition
Nov 29, 2018
A key task in Bayesian machine learning is sampling from distributions that are only specified up to a partition function (i.e., constant of proportionality). One prevalent example of this is sampling posteriors in parametric distributions, such as latent-variable generative models. However sampling (even very approximately) can be #P-hard. Classical results going back to Bakry and \'Emery (1985) on sampling focus on log-concave distributions, and show a natural Markov chain called Langevin diffusion mixes in polynomial time. However, all log-concave distributions are uni-modal, while in practice it is very common for the distribution of interest to have multiple modes. In this case, Langevin diffusion suffers from torpid mixing. We address this problem by combining Langevin diffusion with simulated tempering. The result is a Markov chain that mixes more rapidly by transitioning between different temperatures of the distribution. We analyze this Markov chain for a mixture of (strongly) log-concave distributions of the same shape. In particular, our technique applies to the canonical multi-modal distribution: a mixture of gaussians (of equal variance). Our algorithm efficiently samples from these distributions given only access to the gradient of the log-pdf. For the analysis, we introduce novel techniques for proving spectral gaps based on decomposing the action of the generator of the diffusion. Previous approaches rely on decomposing the state space as a partition of sets, while our approach can be thought of as decomposing the stationary measure as a mixture of distributions (a "soft partition"). Additional materials for the paper can be found at http://tiny.cc/glr17. The proof and results have been improved and generalized from the precursor at www.arxiv.org/abs/1710.02736.
* 55 pages. arXiv admin note: text overlap with arXiv:1710.02736
Mean-field approximation, convex hierarchies, and the optimality of correlation rounding: a unified perspective
Aug 29, 2018The free energy is a key quantity of interest in Ising models, but unfortunately, computing it in general is computationally intractable. Two popular (variational) approximation schemes for estimating the free energy of general Ising models (in particular, even in regimes where correlation decay does not hold) are: (i) the mean-field approximation with roots in statistical physics, which estimates the free energy from below, and (ii) hierarchies of convex relaxations with roots in theoretical computer science, which estimate the free energy from above. We show, surprisingly, that the tight regime for both methods to compute the free energy to leading order is identical. More precisely, we show that the mean-field approximation is within $O((n\|J\|_{F})^{2/3})$ of the free energy, where $\|J\|_F$ denotes the Frobenius norm of the interaction matrix of the Ising model. This simultaneously subsumes both the breakthrough work of Basak and Mukherjee, who showed the tight result that the mean-field approximation is within $o(n)$ whenever $\|J\|_{F} = o(\sqrt{n})$, as well as the work of Jain, Koehler, and Mossel, who gave the previously best known non-asymptotic bound of $O((n\|J\|_{F})^{2/3}\log^{1/3}(n\|J\|_{F}))$. We give a simple, algorithmic proof of this result using a convex relaxation proposed by Risteski based on the Sherali-Adams hierarchy, automatically giving sub-exponential time approximation schemes for the free energy in this entire regime. Our algorithmic result is tight under Gap-ETH. We furthermore combine our techniques with spin glass theory to prove (in a strong sense) the optimality of correlation rounding, refuting a recent conjecture of Allen, O'Donnell, and Zhou. Finally, we give the tight generalization of all of these results to $k$-MRFs, capturing as a special case previous work on approximating MAX-$k$-CSP.