 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccuracy-Memory Tradeoffs and Phase Transitions in Belief Propagation
May 24, 2019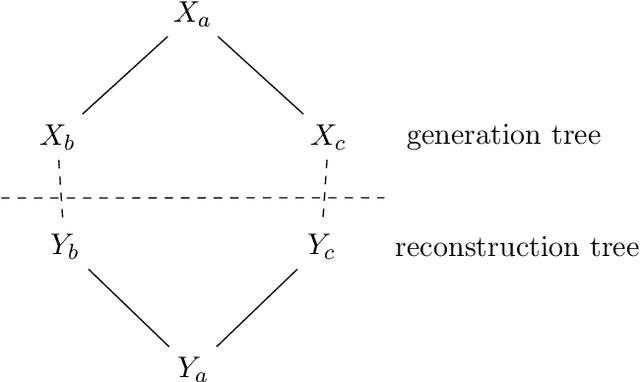
The analysis of Belief Propagation and other algorithms for the {\em reconstruction problem} plays a key role in the analysis of community detection in inference on graphs, phylogenetic reconstruction in bioinformatics, and the cavity method in statistical physics. We prove a conjecture of Evans, Kenyon, Peres, and Schulman (2000) which states that any bounded memory message passing algorithm is statistically much weaker than Belief Propagation for the reconstruction problem. More formally, any recursive algorithm with bounded memory for the reconstruction problem on the trees with the binary symmetric channel has a phase transition strictly below the Belief Propagation threshold, also known as the Kesten-Stigum bound. The proof combines in novel fashion tools from recursive reconstruction, information theory, and optimal transport, and also establishes an asymptotic normality result for BP and other message-passing algorithms near the critical threshold.
Mean-field approximation, convex hierarchies, and the optimality of correlation rounding: a unified perspective
Aug 29, 2018The free energy is a key quantity of interest in Ising models, but unfortunately, computing it in general is computationally intractable. Two popular (variational) approximation schemes for estimating the free energy of general Ising models (in particular, even in regimes where correlation decay does not hold) are: (i) the mean-field approximation with roots in statistical physics, which estimates the free energy from below, and (ii) hierarchies of convex relaxations with roots in theoretical computer science, which estimate the free energy from above. We show, surprisingly, that the tight regime for both methods to compute the free energy to leading order is identical. More precisely, we show that the mean-field approximation is within $O((n\|J\|_{F})^{2/3})$ of the free energy, where $\|J\|_F$ denotes the Frobenius norm of the interaction matrix of the Ising model. This simultaneously subsumes both the breakthrough work of Basak and Mukherjee, who showed the tight result that the mean-field approximation is within $o(n)$ whenever $\|J\|_{F} = o(\sqrt{n})$, as well as the work of Jain, Koehler, and Mossel, who gave the previously best known non-asymptotic bound of $O((n\|J\|_{F})^{2/3}\log^{1/3}(n\|J\|_{F}))$. We give a simple, algorithmic proof of this result using a convex relaxation proposed by Risteski based on the Sherali-Adams hierarchy, automatically giving sub-exponential time approximation schemes for the free energy in this entire regime. Our algorithmic result is tight under Gap-ETH. We furthermore combine our techniques with spin glass theory to prove (in a strong sense) the optimality of correlation rounding, refuting a recent conjecture of Allen, O'Donnell, and Zhou. Finally, we give the tight generalization of all of these results to $k$-MRFs, capturing as a special case previous work on approximating MAX-$k$-CSP.
The Vertex Sample Complexity of Free Energy is Polynomial
Feb 24, 2018We study the following question: given a massive Markov random field on $n$ nodes, can a small sample from it provide a rough approximation to the free energy $\mathcal{F}_n = \log{Z_n}$? Results in graph limit literature by Borgs, Chayes, Lov\'asz, S\'os, and Vesztergombi show that for Ising models on $n$ nodes and interactions of strength $\Theta(1/n)$, an $\epsilon$ approximation to $\log Z_n / n$ can be achieved by sampling a randomly induced model on $2^{O(1/\epsilon^2)}$ nodes. We show that the sampling complexity of this problem is {\em polynomial in} $1/\epsilon$. We further show a polynomial dependence on $\epsilon$ cannot be avoided. Our results are very general as they apply to higher order Markov random fields. For Markov random fields of order $r$, we obtain an algorithm that achieves $\epsilon$ approximation using a number of samples polynomial in $r$ and $1/\epsilon$ and running time that is $2^{O(1/\epsilon^2)}$ up to polynomial factors in $r$ and $\epsilon$. For ferromagnetic Ising models, the running time is polynomial in $1/\epsilon$. Our results are intimately connected to recent research on the regularity lemma and property testing, where the interest is in finding which properties can tested within $\epsilon$ error in time polynomial in $1/\epsilon$. In particular, our proofs build on results from a recent work by Alon, de la Vega, Kannan and Karpinski, who also introduced the notion of polynomial vertex sample complexity. Another critical ingredient of the proof is an effective bound by the authors of the paper relating the variational free energy and the free energy.
The Mean-Field Approximation: Information Inequalities, Algorithms, and Complexity
Feb 20, 2018The mean field approximation to the Ising model is a canonical variational tool that is used for analysis and inference in Ising models. We provide a simple and optimal bound for the KL error of the mean field approximation for Ising models on general graphs, and extend it to higher order Markov random fields. Our bound improves on previous bounds obtained in work in the graph limit literature by Borgs, Chayes, Lov\'asz, S\'os, and Vesztergombi and another recent work by Basak and Mukherjee. Our bound is tight up to lower order terms. Building on the methods used to prove the bound, along with techniques from combinatorics and optimization, we study the algorithmic problem of estimating the (variational) free energy for Ising models and general Markov random fields. For a graph $G$ on $n$ vertices and interaction matrix $J$ with Frobenius norm $\| J \|_F$, we provide algorithms that approximate the free energy within an additive error of $\epsilon n \|J\|_F$ in time $\exp(poly(1/\epsilon))$. We also show that approximation within $(n \|J\|_F)^{1-\delta}$ is NP-hard for every $\delta > 0$. Finally, we provide more efficient approximation algorithms, which find the optimal mean field approximation, for ferromagnetic Ising models and for Ising models satisfying Dobrushin's condition.
Approximating Partition Functions in Constant Time
Feb 20, 2018We study approximations of the partition function of dense graphical models. Partition functions of graphical models play a fundamental role is statistical physics, in statistics and in machine learning. Two of the main methods for approximating the partition function are Markov Chain Monte Carlo and Variational Methods. An impressive body of work in mathematics, physics and theoretical computer science provides conditions under which Markov Chain Monte Carlo methods converge in polynomial time. These methods often lead to polynomial time approximation algorithms for the partition function in cases where the underlying model exhibits correlation decay. There are very few theoretical guarantees for the performance of variational methods. One exception is recent results by Risteski (2016) who considered dense graphical models and showed that using variational methods, it is possible to find an $O(\epsilon n)$ additive approximation to the log partition function in time $n^{O(1/\epsilon^2)}$ even in a regime where correlation decay does not hold. We show that under essentially the same conditions, an $O(\epsilon n)$ additive approximation of the log partition function can be found in constant time, independent of $n$. In particular, our results cover dense Ising and Potts models as well as dense graphical models with $k$-wise interaction. They also apply for low threshold rank models.