 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGather-Excite: Exploiting Feature Context in Convolutional Neural Networks
Oct 29, 2018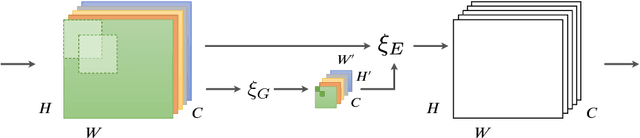
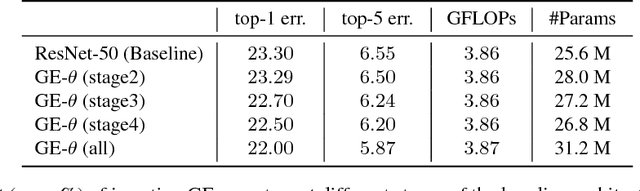
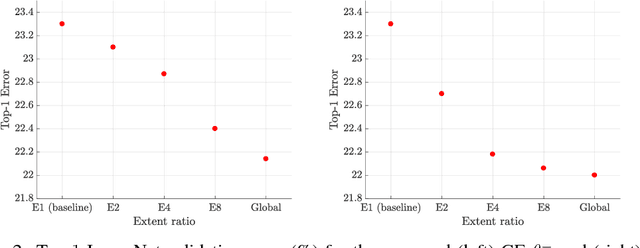
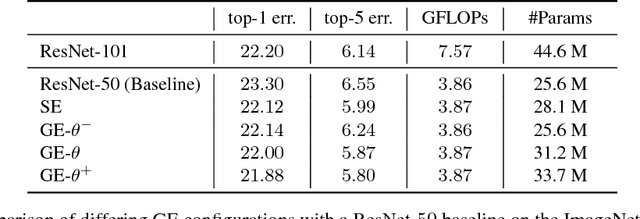
While the use of bottom-up local operators in convolutional neural networks (CNNs) matches well some of the statistics of natural images, it may also prevent such models from capturing contextual long-range feature interactions. In this work, we propose a simple, lightweight approach for better context exploitation in CNNs. We do so by introducing a pair of operators: gather, which efficiently aggregates feature responses from a large spatial extent, and excite, which redistributes the pooled information to local features. The operators are cheap, both in terms of number of added parameters and computational complexity, and can be integrated directly in existing architectures to improve their performance. Experiments on several datasets show that gather-excite can bring benefits comparable to increasing the depth of a CNN at a fraction of the cost. For example, we find ResNet-50 with gather-excite operators is able to outperform its 101-layer counterpart on ImageNet with no additional learnable parameters. We also propose a parametric gather-excite operator pair which yields further performance gains, relate it to the recently-introduced Squeeze-and-Excitation Networks, and analyse the effects of these changes to the CNN feature activation statistics.
Learning to Read by Spelling: Towards Unsupervised Text Recognition
Sep 23, 2018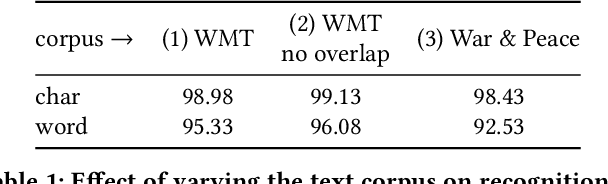
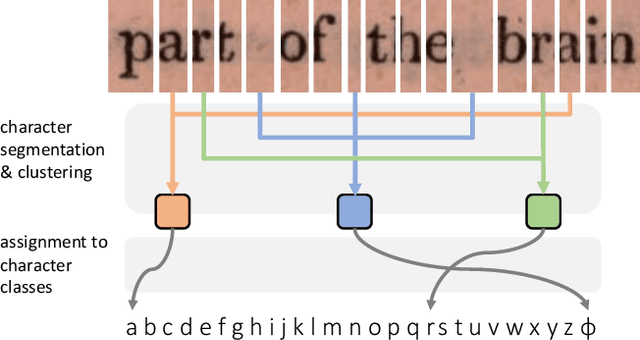


This work presents a method for visual text recognition without using any paired supervisory data. We formulate the text recognition task as one of aligning the conditional distribution of strings predicted from given text images, with lexically valid strings sampled from target corpora. This enables fully automated, and unsupervised learning from just line-level text-images, and unpaired text-string samples, obviating the need for large aligned datasets. We present detailed analysis for various aspects of the proposed method, namely - (1) the impact of the length of training sequences on convergence, (2) relation between character frequencies and the order in which they are learnt, and (3) demonstrate the generalisation ability of our recognition network to inputs of arbitrary lengths. Finally, we demonstrate excellent text recognition accuracy on both synthetically generated text images, and scanned images of real printed books, using no labelled training examples.
Emotion Recognition in Speech using Cross-Modal Transfer in the Wild
Aug 16, 2018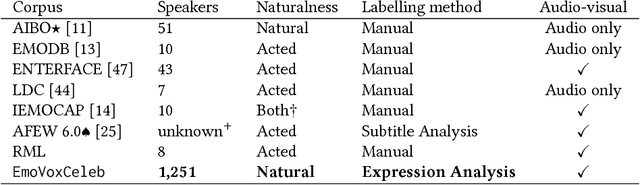



Obtaining large, human labelled speech datasets to train models for emotion recognition is a notoriously challenging task, hindered by annotation cost and label ambiguity. In this work, we consider the task of learning embeddings for speech classification without access to any form of labelled audio. We base our approach on a simple hypothesis: that the emotional content of speech correlates with the facial expression of the speaker. By exploiting this relationship, we show that annotations of expression can be transferred from the visual domain (faces) to the speech domain (voices) through cross-modal distillation. We make the following contributions: (i) we develop a strong teacher network for facial emotion recognition that achieves the state of the art on a standard benchmark; (ii) we use the teacher to train a student, tabula rasa, to learn representations (embeddings) for speech emotion recognition without access to labelled audio data; and (iii) we show that the speech emotion embedding can be used for speech emotion recognition on external benchmark datasets. Code, models and data are available.
Long-term Tracking in the Wild: A Benchmark
Aug 10, 2018
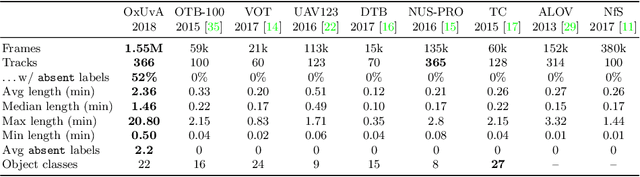
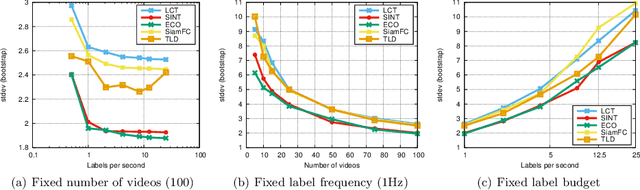
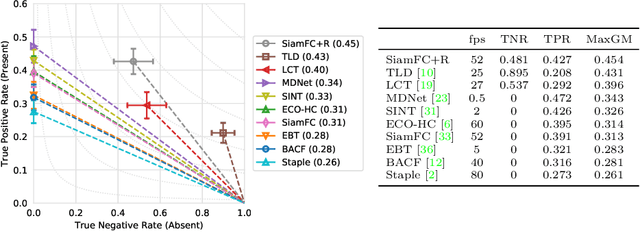
We introduce the OxUvA dataset and benchmark for evaluating single-object tracking algorithms. Benchmarks have enabled great strides in the field of object tracking by defining standardized evaluations on large sets of diverse videos. However, these works have focused exclusively on sequences that are just tens of seconds in length and in which the target is always visible. Consequently, most researchers have designed methods tailored to this "short-term" scenario, which is poorly representative of practitioners' needs. Aiming to address this disparity, we compile a long-term, large-scale tracking dataset of sequences with average length greater than two minutes and with frequent target object disappearance. The OxUvA dataset is much larger than the object tracking datasets of recent years: it comprises 366 sequences spanning 14 hours of video. We assess the performance of several algorithms, considering both the ability to locate the target and to determine whether it is present or absent. Our goal is to offer the community a large and diverse benchmark to enable the design and evaluation of tracking methods ready to be used "in the wild". The project website is http://oxuva.net
Semi-convolutional Operators for Instance Segmentation
Jul 27, 2018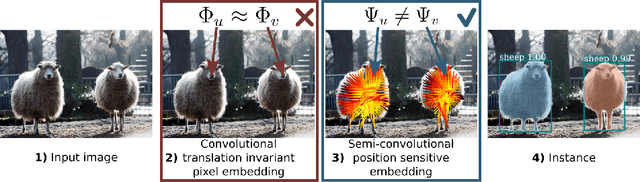



Object detection and instance segmentation are dominated by region-based methods such as Mask RCNN. However, there is a growing interest in reducing these problems to pixel labeling tasks, as the latter could be more efficient, could be integrated seamlessly in image-to-image network architectures as used in many other tasks, and could be more accurate for objects that are not well approximated by bounding boxes. In this paper we show theoretically and empirically that constructing dense pixel embeddings that can separate object instances cannot be easily achieved using convolutional operators. At the same time, we show that simple modifications, which we call semi-convolutional, have a much better chance of succeeding at this task. We use the latter to show a connection to Hough voting as well as to a variant of the bilateral kernel that is spatially steered by a convolutional network. We demonstrate that these operators can also be used to improve approaches such as Mask RCNN, demonstrating better segmentation of complex biological shapes and PASCAL VOC categories than achievable by Mask RCNN alone.
Invariant Information Distillation for Unsupervised Image Segmentation and Clustering
Jul 21, 2018
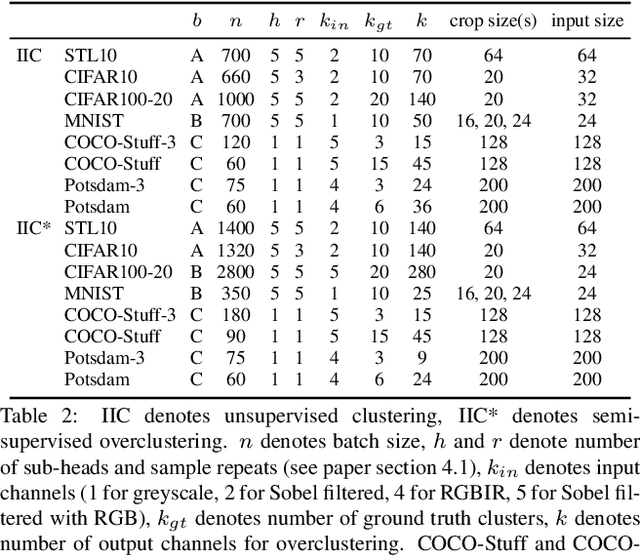

We present a new method that learns to segment and cluster images without labels of any kind. A simple loss based on information theory is used to extract meaningful representations directly from raw images. This is achieved by maximising mutual information of images known to be related by spatial proximity or randomized transformations, which distills their shared abstract content. Unlike much of the work in unsupervised deep learning, our learned function outputs segmentation heatmaps and discrete classifications labels directly, rather than embeddings that need further processing to be usable. The loss can be formulated as a convolution, making it the first end-to-end unsupervised learning method that learns densely and efficiently for semantic segmentation. Implemented using realistic settings on generic deep neural network architectures, our method attains superior performance on COCO-Stuff and ISPRS-Potsdam for segmentation and STL for clustering, beating state-of-the-art baselines.
Inductive Visual Localisation: Factorised Training for Superior Generalisation
Jul 21, 2018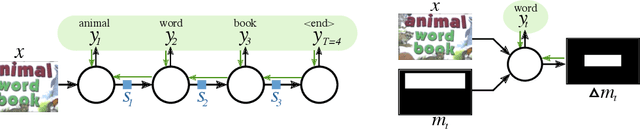

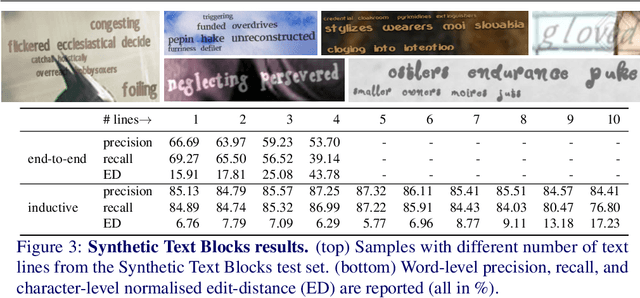
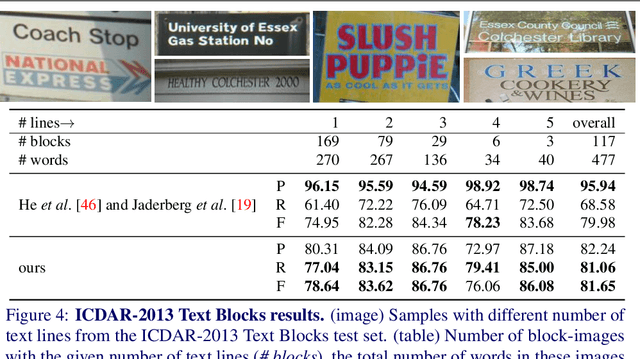
End-to-end trained Recurrent Neural Networks (RNNs) have been successfully applied to numerous problems that require processing sequences, such as image captioning, machine translation, and text recognition. However, RNNs often struggle to generalise to sequences longer than the ones encountered during training. In this work, we propose to optimise neural networks explicitly for induction. The idea is to first decompose the problem in a sequence of inductive steps and then to explicitly train the RNN to reproduce such steps. Generalisation is achieved as the RNN is not allowed to learn an arbitrary internal state; instead, it is tasked with mimicking the evolution of a valid state. In particular, the state is restricted to a spatial memory map that tracks parts of the input image which have been accounted for in previous steps. The RNN is trained for single inductive steps, where it produces updates to the memory in addition to the desired output. We evaluate our method on two different visual recognition problems involving visual sequences: (1) text spotting, i.e. joint localisation and reading of text in images containing multiple lines (or a block) of text, and (2) sequential counting of objects in aerial images. We show that inductive training of recurrent models enhances their generalisation ability on challenging image datasets.
Large scale evaluation of local image feature detectors on homography datasets
Jul 20, 2018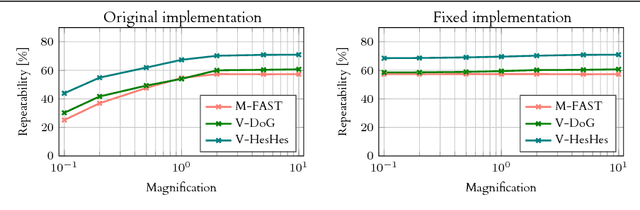
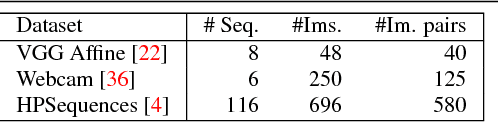
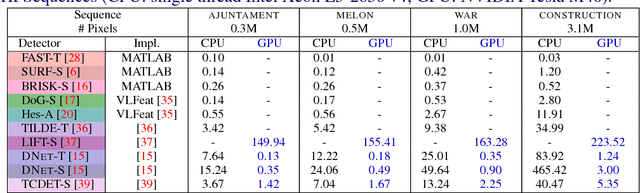
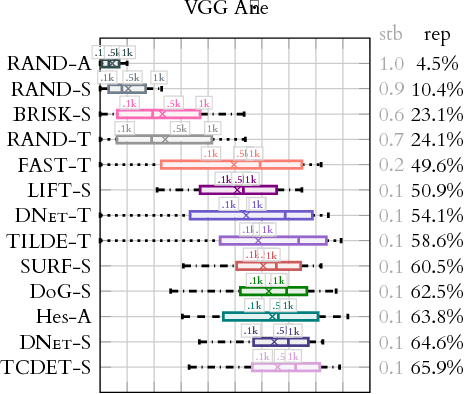
We present a large scale benchmark for the evaluation of local feature detectors. Our key innovation is the introduction of a new evaluation protocol which extends and improves the standard detection repeatability measure. The new protocol is better for assessment on a large number of images and reduces the dependency of the results on unwanted distractors such as the number of detected features and the feature magnification factor. Additionally, our protocol provides a comprehensive assessment of the expected performance of detectors under several practical scenarios. Using images from the recently-introduced HPatches dataset, we evaluate a range of state-of-the-art local feature detectors on two main tasks: viewpoint and illumination invariant detection. Contrary to previous detector evaluations, our study contains an order of magnitude more image sequences, resulting in a quantitative evaluation significantly more robust to over-fitting. We also show that traditional detectors are still very competitive when compared to recent deep-learning alternatives.
Cross Pixel Optical Flow Similarity for Self-Supervised Learning
Jul 15, 2018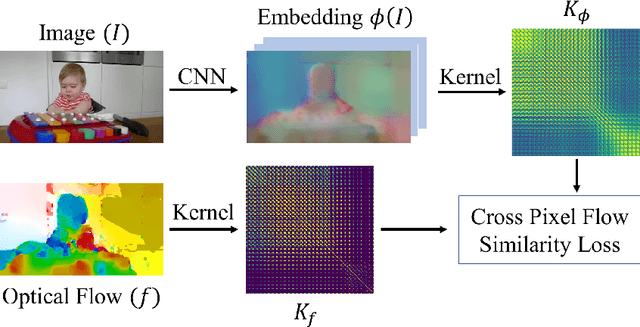
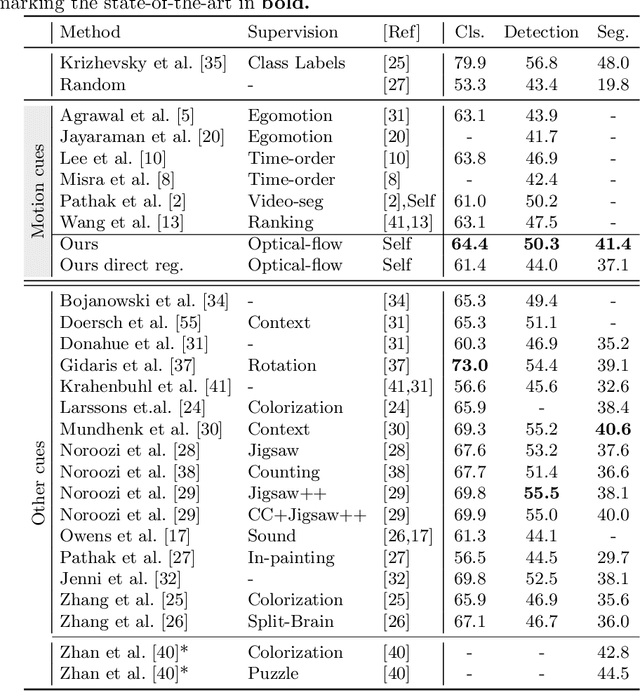
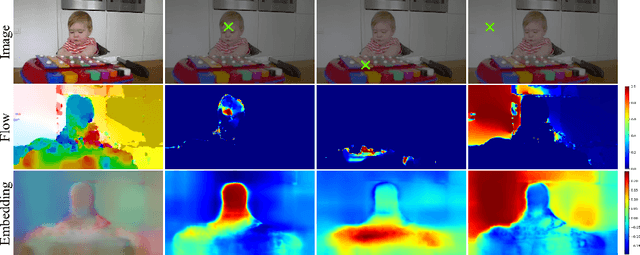
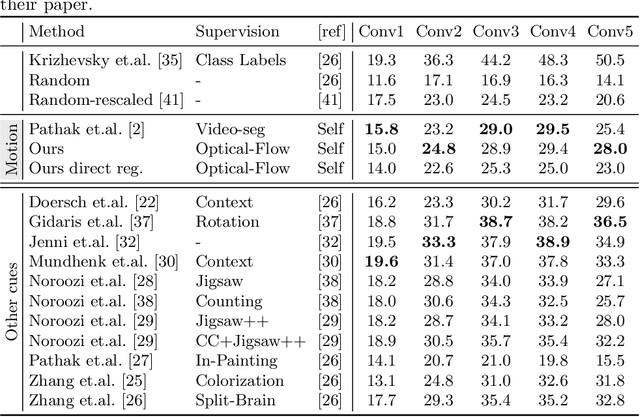
We propose a novel method for learning convolutional neural image representations without manual supervision. We use motion cues in the form of optical flow, to supervise representations of static images. The obvious approach of training a network to predict flow from a single image can be needlessly difficult due to intrinsic ambiguities in this prediction task. We instead propose a much simpler learning goal: embed pixels such that the similarity between their embeddings matches that between their optical flow vectors. At test time, the learned deep network can be used without access to video or flow information and transferred to tasks such as image classification, detection, and segmentation. Our method, which significantly simplifies previous attempts at using motion for self-supervision, achieves state-of-the-art results in self-supervision using motion cues, competitive results for self-supervision in general, and is overall state of the art in self-supervised pretraining for semantic image segmentation, as demonstrated on standard benchmarks.
ShapeStacks: Learning Vision-Based Physical Intuition for Generalised Object Stacking
Jul 06, 2018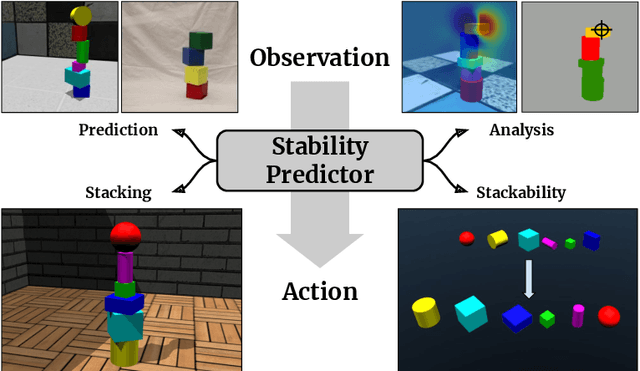
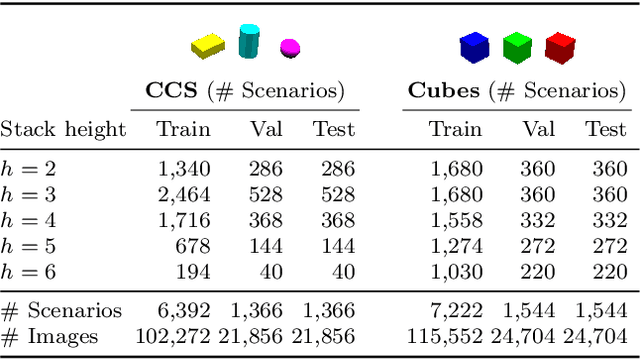
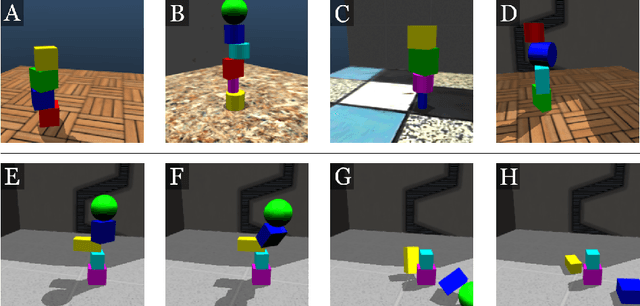
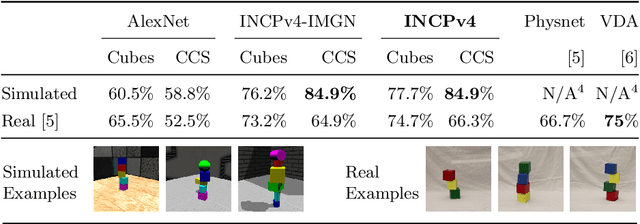
Physical intuition is pivotal for intelligent agents to perform complex tasks. In this paper we investigate the passive acquisition of an intuitive understanding of physical principles as well as the active utilisation of this intuition in the context of generalised object stacking. To this end, we provide: a simulation-based dataset featuring 20,000 stack configurations composed of a variety of elementary geometric primitives richly annotated regarding semantics and structural stability. We train visual classifiers for binary stability prediction on the ShapeStacks data and scrutinise their learned physical intuition. Due to the richness of the training data our approach also generalises favourably to real-world scenarios achieving state-of-the-art stability prediction on a publicly available benchmark of block towers. We then leverage the physical intuition learned by our model to actively construct stable stacks and observe the emergence of an intuitive notion of stackability - an inherent object affordance - induced by the active stacking task. Our approach performs well even in challenging conditions where it considerably exceeds the stack height observed during training or in cases where initially unstable structures must be stabilised via counterbalancing.