 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndrea Madotto
Misinformation has High Perplexity
Jun 08, 2020
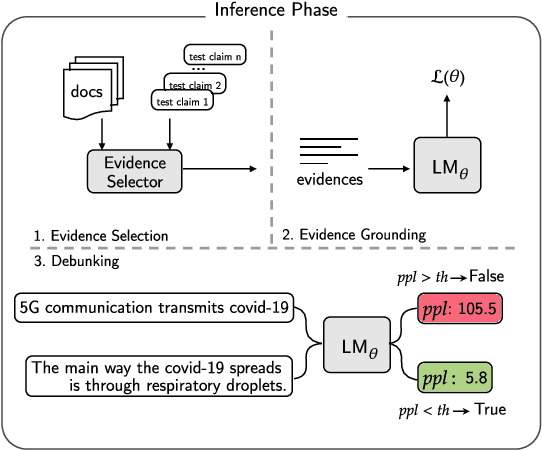


Debunking misinformation is an important and time-critical task as there could be adverse consequences when misinformation is not quashed promptly. However, the usual supervised approach to debunking via misinformation classification requires human-annotated data and is not suited to the fast time-frame of newly emerging events such as the COVID-19 outbreak. In this paper, we postulate that misinformation itself has higher perplexity compared to truthful statements, and propose to leverage the perplexity to debunk false claims in an unsupervised manner. First, we extract reliable evidence from scientific and news sources according to sentence similarity to the claims. Second, we prime a language model with the extracted evidence and finally evaluate the correctness of given claims based on the perplexity scores at debunking time. We construct two new COVID-19-related test sets, one is scientific, and another is political in content, and empirically verify that our system performs favorably compared to existing systems. We are releasing these datasets publicly to encourage more research in debunking misinformation on COVID-19 and other topics.
Exploring Fine-tuning Techniques for Pre-trained Cross-lingual Models via Continual Learning
Apr 29, 2020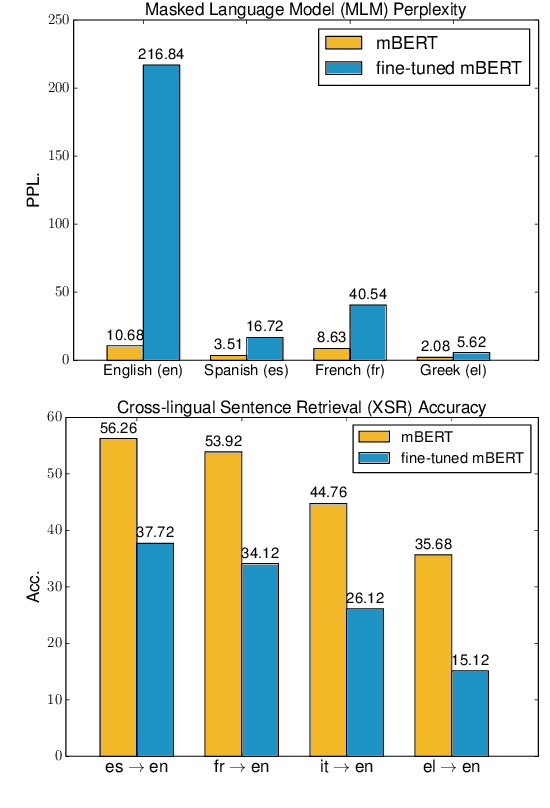
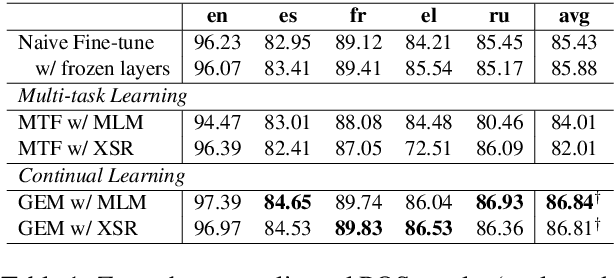
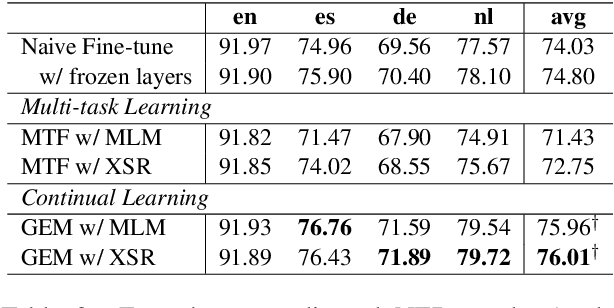
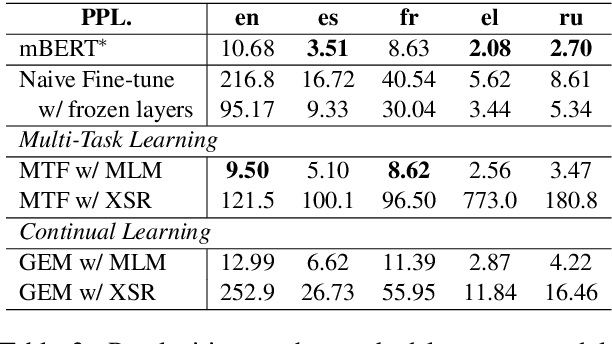
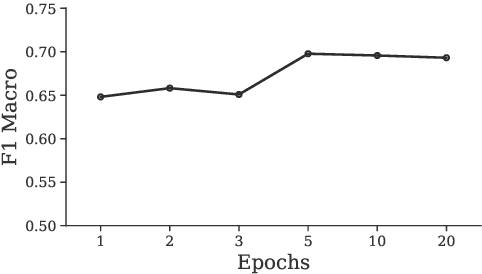
Recently, fine-tuning pre-trained cross-lingual models (e.g., multilingual BERT) to downstream cross-lingual tasks has shown promising results. However, the fine-tuning process inevitably changes the parameters of the pre-trained model and weakens its cross-lingual ability, which could lead to sub-optimal performances. To alleviate this issue, we leverage the idea of continual learning to preserve the original cross-lingual ability of the pre-trained model when we fine-tune it to downstream cross-lingual tasks. The experiment on the cross-lingual sentence retrieval task shows that our fine-tuning approach can better preserve the cross-lingual ability of the pre-trained model. In addition, our method achieves better performance than other fine-tuning baselines on zero-shot cross-lingual part-of-speech tagging and named entity recognition tasks.
XPersona: Evaluating Multilingual Personalized Chatbot
Apr 08, 2020
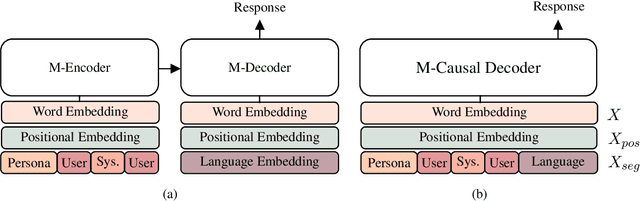
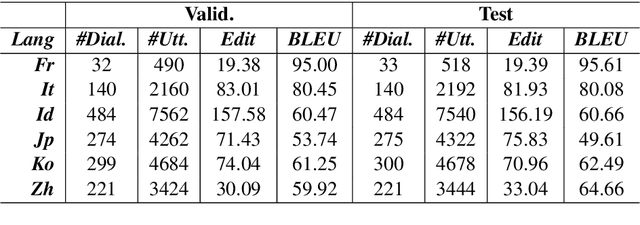
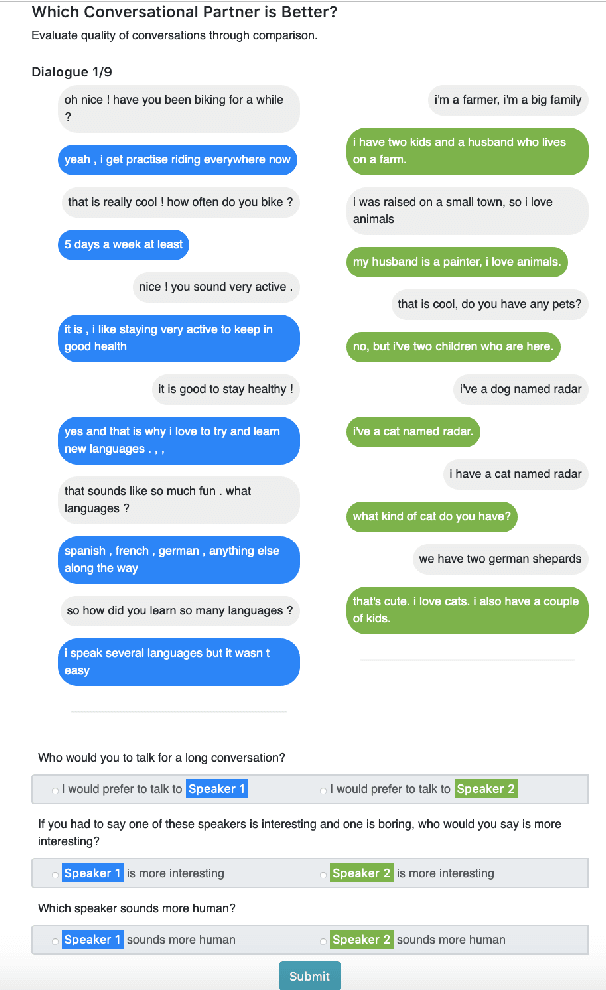
Personalized dialogue systems are an essential step toward better human-machine interaction. Existing personalized dialogue agents rely on properly designed conversational datasets, which are mostly monolingual (e.g., English), which greatly limits the usage of conversational agents in other languages. In this paper, we propose a multi-lingual extension of Persona-Chat, namely XPersona. Our dataset includes persona conversations in six different languages other than English for building and evaluating multilingual personalized agents. We experiment with both multilingual and cross-lingual trained baselines, and evaluate them against monolingual and translation-pipeline models using both automatic and human evaluation. Experimental results show that the multilingual trained models outperform the translation-pipeline and that they are on par with the monolingual models, with the advantage of having a single model across multiple languages. On the other hand, the state-of-the-art cross-lingual trained models achieve inferior performance to the other models, showing that cross-lingual conversation modeling is a challenging task. We hope that our dataset and baselines will accelerate research in multilingual dialogue systems.
Exploring Versatile Generative Language Model Via Parameter-Efficient Transfer Learning
Apr 08, 2020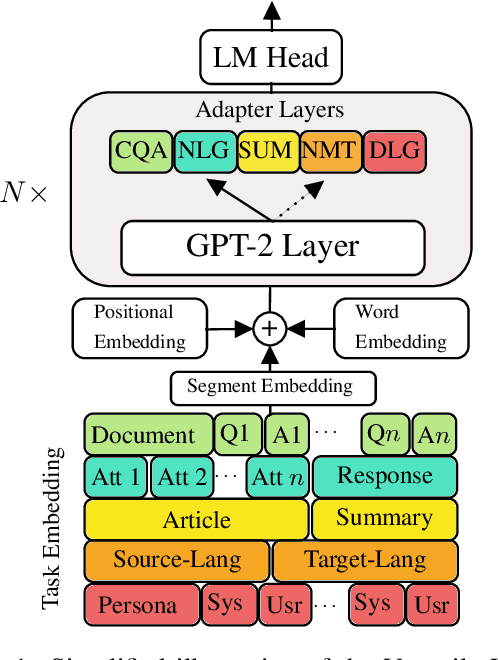
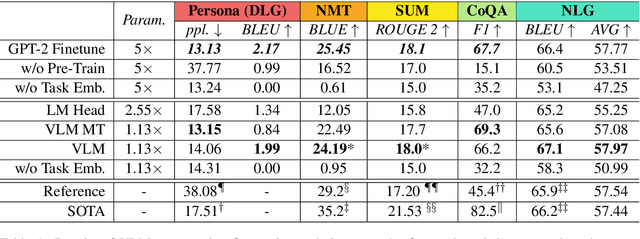
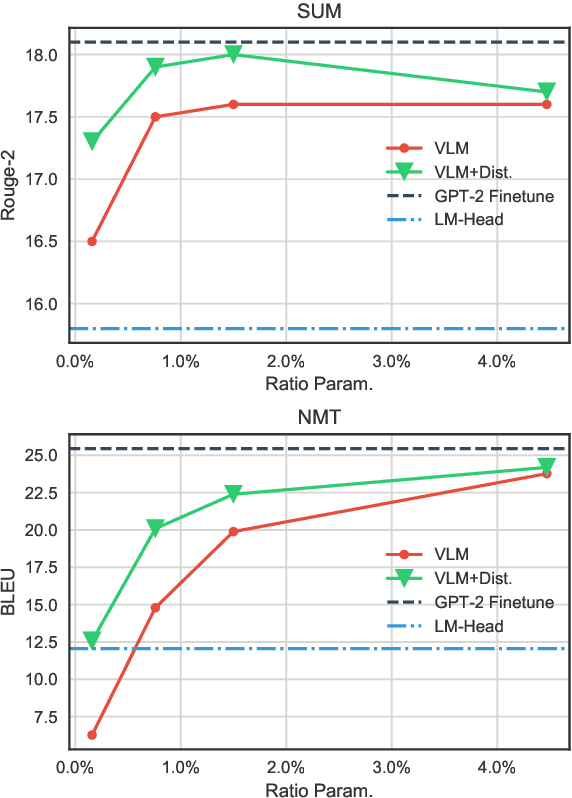
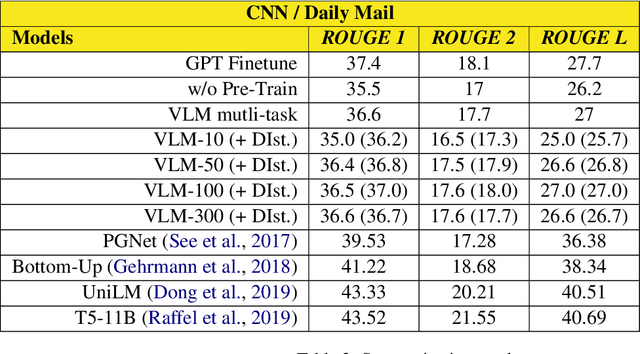
Fine-tuning pre-trained generative language models to down-stream language generation tasks has shown promising results. However, this comes with the cost of having a single, large model for each task, which is not ideal in low-memory/power scenarios (e.g., mobile). In this paper, we propose an effective way to fine-tune multiple down-stream generation tasks simultaneously using a single, large pre-trained model. The experiments on five diverse language generation tasks show that by just using an additional 2-3% parameters for each task, our model can maintain or even improve the performance of fine-tuning the whole model.
Exploration Based Language Learning for Text-Based Games
Jan 24, 2020

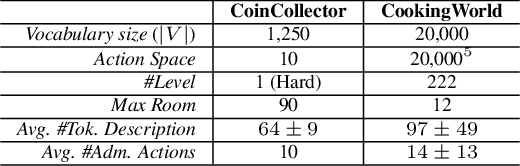
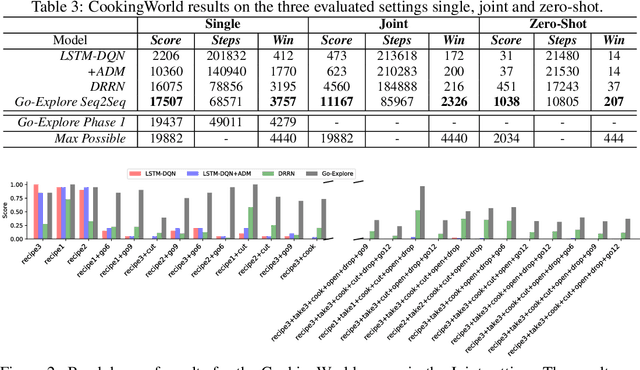
This work presents an exploration and imitation-learning-based agent capable of state-of-the-art performance in playing text-based computer games. Text-based computer games describe their world to the player through natural language and expect the player to interact with the game using text. These games are of interest as they can be seen as a testbed for language understanding, problem-solving, and language generation by artificial agents. Moreover, they provide a learning environment in which these skills can be acquired through interactions with an environment rather than using fixed corpora. One aspect that makes these games particularly challenging for learning agents is the combinatorially large action space. Existing methods for solving text-based games are limited to games that are either very simple or have an action space restricted to a predetermined set of admissible actions. In this work, we propose to use the exploration approach of Go-Explore for solving text-based games. More specifically, in an initial exploration phase, we first extract trajectories with high rewards, after which we train a policy to solve the game by imitating these trajectories. Our experiments show that this approach outperforms existing solutions in solving text-based games, and it is more sample efficient in terms of the number of interactions with the environment. Moreover, we show that the learned policy can generalize better than existing solutions to unseen games without using any restriction on the action space.
Plug and Play Language Models: A Simple Approach to Controlled Text Generation
Jan 08, 2020
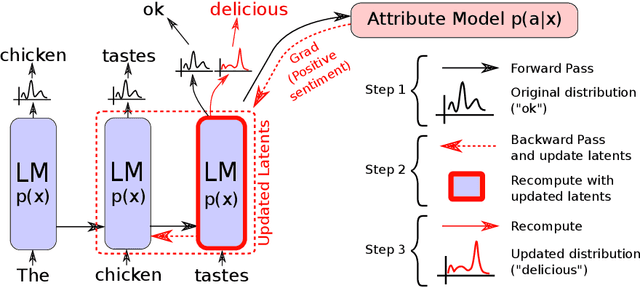
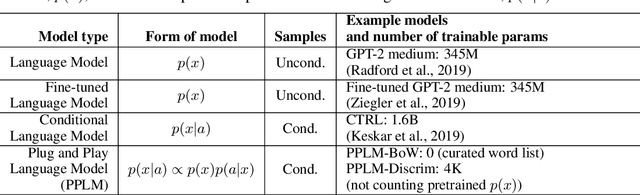
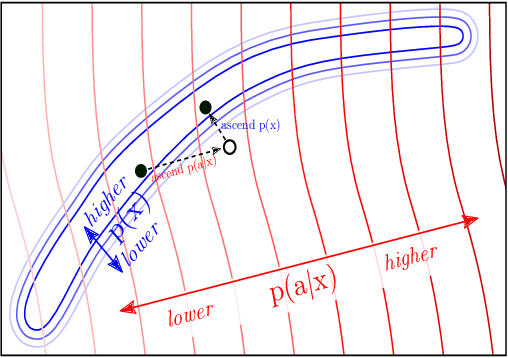
Large transformer-based language models (LMs) trained on huge text corpora have shown unparalleled generation capabilities. However, controlling attributes of the generated language (e.g. switching topic or sentiment) is difficult without modifying the model architecture or fine-tuning on attribute-specific data and entailing the significant cost of retraining. We propose a simple alternative: the Plug and Play Language Model (PPLM) for controllable language generation, which combines a pretrained LM with one or more simple attribute classifiers that guide text generation without any further training of the LM. In the canonical scenario we present, the attribute models are simple classifiers consisting of a user-specified bag of words or a single learned layer with 100,000 times fewer parameters than the LM. Sampling entails a forward and backward pass in which gradients from the attribute model push the LM's hidden activations and thus guide the generation. Model samples demonstrate control over a range of topics and sentiment styles, and extensive automated and human annotated evaluations show attribute alignment and fluency. PPLMs are flexible in that any combination of differentiable attribute models may be used to steer text generation, which will allow for diverse and creative applications beyond the examples given in this paper.
Attention over Parameters for Dialogue Systems
Jan 07, 2020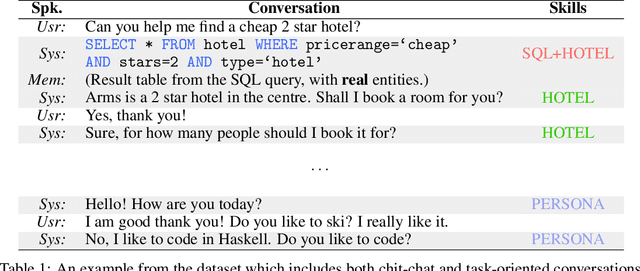
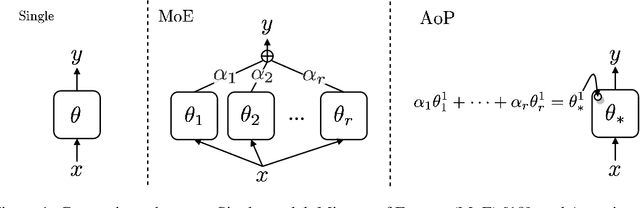
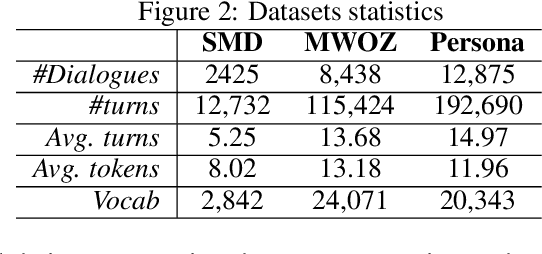
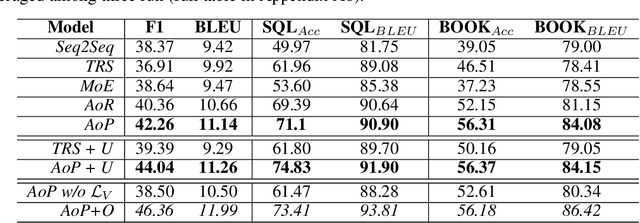
Dialogue systems require a great deal of different but complementary expertise to assist, inform, and entertain humans. For example, different domains (e.g., restaurant reservation, train ticket booking) of goal-oriented dialogue systems can be viewed as different skills, and so does ordinary chatting abilities of chit-chat dialogue systems. In this paper, we propose to learn a dialogue system that independently parameterizes different dialogue skills, and learns to select and combine each of them through Attention over Parameters (AoP). The experimental results show that this approach achieves competitive performance on a combined dataset of MultiWOZ, In-Car Assistant, and Persona-Chat. Finally, we demonstrate that each dialogue skill is effectively learned and can be combined with other skills to produce selective responses.
Plug and Play Language Models: a Simple Approach to Controlled Text Generation
Dec 04, 2019Large transformer-based language models (LMs) trained on huge text corpora have shown unparalleled generation capabilities. However, controlling attributes of the generated language (e.g. switching topic or sentiment) is difficult without modifying the model architecture or fine-tuning on attribute-specific data and entailing the significant cost of retraining. We propose a simple alternative: the Plug and Play Language Model (PPLM) for controllable language generation, which combines a pretrained LM with one or more simple attribute classifiers that guide text generation without any further training of the LM. In the canonical scenario we present, the attribute models are simple classifiers consisting of a user-specified bag of words or a single learned layer with 100,000 times fewer parameters than the LM. Sampling entails a forward and backward pass in which gradients from the attribute model push the LM's hidden activations and thus guide the generation. Model samples demonstrate control over a range of topics and sentiment styles, and extensive automated and human annotated evaluations show attribute alignment and fluency. PPLMs are flexible in that any combination of differentiable attribute models may be used to steer text generation, which will allow for diverse and creative applications beyond the examples given in this paper.