 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESAM++: Efficient Online 3D Perception on the Edge
May 28, 2026Online 3D scene perception in real time is essential for robotics, AR/VR, and autonomous systems, particularly in edge computing scenarios where computational resources are limited and privacy is crucial. Recent state-of-the-art methods like EmbodiedSAM (ESAM) demonstrate the promise of online 3D perception by leveraging the Segment Anything Model (SAM) for real-time, fine-grained, and generalized 3D instance segmentation. However, ESAM still relies on a computationally expensive 3D sparse UNet for point cloud feature extraction, which accounts for the majority of the 3D inference time, hindering its practicality on resource-constrained devices. In this paper, we propose ESAM++, a lightweight and scalable alternative for online 3D scene perception tailored to edge devices without GPU acceleration. Our method introduces a 3D Sparse Feature Pyramid Network (SFPN) that efficiently captures multi-scale geometric features from streaming 3D point clouds while significantly reducing computational overhead and model size. We evaluate our approach on four challenging segmentation benchmarks, namely ScanNet, ScanNet200, SceneNN, and 3RScan, demonstrating that our model achieves competitive accuracy with up to 3 times faster inference with a 2 times smaller model size compared to ESAM, enabling practical deployment on edge devices.
VGGRPO: Towards World-Consistent Video Generation with 4D Latent Reward
Mar 27, 2026Large-scale video diffusion models achieve impressive visual quality, yet often fail to preserve geometric consistency. Prior approaches improve consistency either by augmenting the generator with additional modules or applying geometry-aware alignment. However, architectural modifications can compromise the generalization of internet-scale pretrained models, while existing alignment methods are limited to static scenes and rely on RGB-space rewards that require repeated VAE decoding, incurring substantial compute overhead and failing to generalize to highly dynamic real-world scenes. To preserve the pretrained capacity while improving geometric consistency, we propose VGGRPO (Visual Geometry GRPO), a latent geometry-guided framework for geometry-aware video post-training. VGGRPO introduces a Latent Geometry Model (LGM) that stitches video diffusion latents to geometry foundation models, enabling direct decoding of scene geometry from the latent space. By constructing LGM from a geometry model with 4D reconstruction capability, VGGRPO naturally extends to dynamic scenes, overcoming the static-scene limitations of prior methods. Building on this, we perform latent-space Group Relative Policy Optimization with two complementary rewards: a camera motion smoothness reward that penalizes jittery trajectories, and a geometry reprojection consistency reward that enforces cross-view geometric coherence. Experiments on both static and dynamic benchmarks show that VGGRPO improves camera stability, geometry consistency, and overall quality while eliminating costly VAE decoding, making latent-space geometry-guided reinforcement an efficient and flexible approach to world-consistent video generation.
From Videos to Conversations: Egocentric Instructions for Task Assistance
Feb 01, 2026Many everyday tasks, ranging from appliance repair and cooking to car maintenance, require expert knowledge, particularly for complex, multi-step procedures. Despite growing interest in AI agents for augmented reality (AR) assistance, progress remains limited by the scarcity of large-scale multimodal conversational datasets grounded in real-world task execution, in part due to the cost and logistical complexity of human-assisted data collection. In this paper, we present a framework to automatically transform single person instructional videos into two-person multimodal task-guidance conversations. Our fully automatic pipeline, based on large language models, provides a scalable and cost efficient alternative to traditional data collection approaches. Using this framework, we introduce HowToDIV, a multimodal dataset comprising 507 conversations, 6,636 question answer pairs, and 24 hours of video spanning multiple domains. Each session consists of a multi-turn expert-novice interaction. Finally, we report baseline results using Gemma 3 and Qwen 2.5 on HowToDIV, providing an initial benchmark for multimodal procedural task assistance.
YETI (YET to Intervene) Proactive Interventions by Multimodal AI Agents in Augmented Reality Tasks
Jan 16, 2025



Multimodal AI Agents are AI models that have the capability of interactively and cooperatively assisting human users to solve day-to-day tasks. Augmented Reality (AR) head worn devices can uniquely improve the user experience of solving procedural day-to-day tasks by providing egocentric multimodal (audio and video) observational capabilities to AI Agents. Such AR capabilities can help AI Agents see and listen to actions that users take which can relate to multimodal capabilities of human users. Existing AI Agents, either Large Language Models (LLMs) or Multimodal Vision-Language Models (VLMs) are reactive in nature, which means that models cannot take an action without reading or listening to the human user's prompts. Proactivity of AI Agents on the other hand can help the human user detect and correct any mistakes in agent observed tasks, encourage users when they do tasks correctly or simply engage in conversation with the user - akin to a human teaching or assisting a user. Our proposed YET to Intervene (YETI) multimodal agent focuses on the research question of identifying circumstances that may require the agent to intervene proactively. This allows the agent to understand when it can intervene in a conversation with human users that can help the user correct mistakes on tasks, like cooking, using AR. Our YETI Agent learns scene understanding signals based on interpretable notions of Structural Similarity (SSIM) on consecutive video frames. We also define the alignment signal which the AI Agent can learn to identify if the video frames corresponding to the user's actions on the task are consistent with expected actions. These signals are used by our AI Agent to determine when it should proactively intervene. We compare our results on the instances of proactive intervention in the HoloAssist multimodal benchmark for an expert agent guiding a user to complete procedural tasks.
Geometry Fidelity for Spherical Images
Jul 25, 2024



Spherical or omni-directional images offer an immersive visual format appealing to a wide range of computer vision applications. However, geometric properties of spherical images pose a major challenge for models and metrics designed for ordinary 2D images. Here, we show that direct application of Fr\'echet Inception Distance (FID) is insufficient for quantifying geometric fidelity in spherical images. We introduce two quantitative metrics accounting for geometric constraints, namely Omnidirectional FID (OmniFID) and Discontinuity Score (DS). OmniFID is an extension of FID tailored to additionally capture field-of-view requirements of the spherical format by leveraging cubemap projections. DS is a kernel-based seam alignment score of continuity across borders of 2D representations of spherical images. In experiments, OmniFID and DS quantify geometry fidelity issues that are undetected by FID.
Augmented Object Intelligence: Making the Analog World Interactable with XR-Objects
Apr 23, 2024



Seamless integration of physical objects as interactive digital entities remains a challenge for spatial computing. This paper introduces Augmented Object Intelligence (AOI), a novel XR interaction paradigm designed to blur the lines between digital and physical by equipping real-world objects with the ability to interact as if they were digital, where every object has the potential to serve as a portal to vast digital functionalities. Our approach utilizes object segmentation and classification, combined with the power of Multimodal Large Language Models (MLLMs), to facilitate these interactions. We implement the AOI concept in the form of XR-Objects, an open-source prototype system that provides a platform for users to engage with their physical environment in rich and contextually relevant ways. This system enables analog objects to not only convey information but also to initiate digital actions, such as querying for details or executing tasks. Our contributions are threefold: (1) we define the AOI concept and detail its advantages over traditional AI assistants, (2) detail the XR-Objects system's open-source design and implementation, and (3) show its versatility through a variety of use cases and a user study.
Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion
Aug 23, 2023



Producing quality segmentation masks for images is a fundamental problem in computer vision. Recent research has explored large-scale supervised training to enable zero-shot segmentation on virtually any image style and unsupervised training to enable segmentation without dense annotations. However, constructing a model capable of segmenting anything in a zero-shot manner without any annotations is still challenging. In this paper, we propose to utilize the self-attention layers in stable diffusion models to achieve this goal because the pre-trained stable diffusion model has learned inherent concepts of objects within its attention layers. Specifically, we introduce a simple yet effective iterative merging process based on measuring KL divergence among attention maps to merge them into valid segmentation masks. The proposed method does not require any training or language dependency to extract quality segmentation for any images. On COCO-Stuff-27, our method surpasses the prior unsupervised zero-shot SOTA method by an absolute 26% in pixel accuracy and 17% in mean IoU.
HIME: Efficient Headshot Image Super-Resolution with Multiple Exemplars
Mar 28, 2022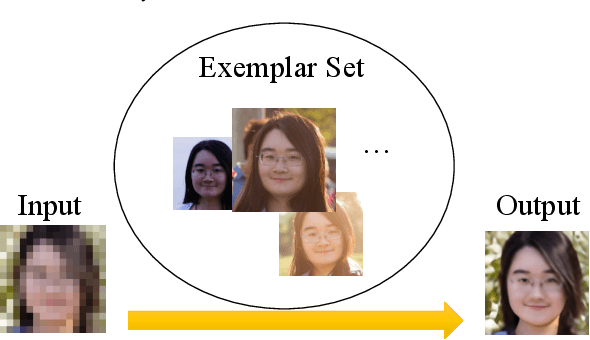
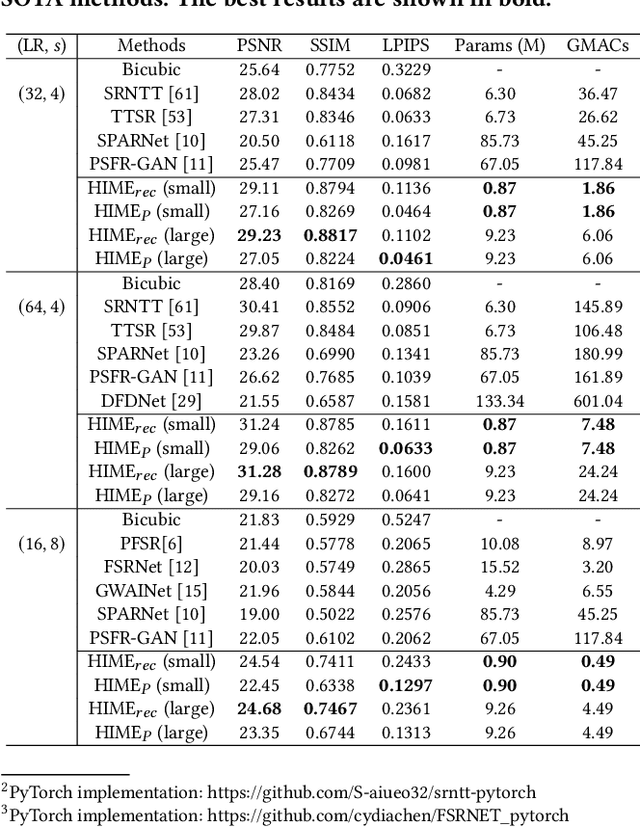
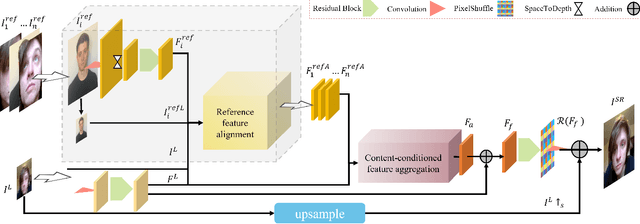
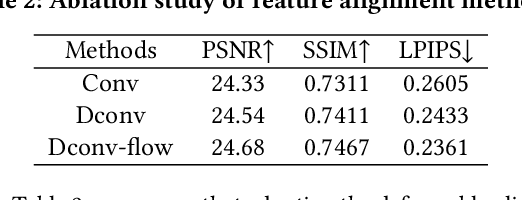
A promising direction for recovering the lost information in low-resolution headshot images is utilizing a set of high-resolution exemplars from the same identity. Complementary images in the reference set can improve the generated headshot quality across many different views and poses. However, it is challenging to make the best use of multiple exemplars: the quality and alignment of each exemplar cannot be guaranteed. Using low-quality and mismatched images as references will impair the output results. To overcome these issues, we propose an efficient Headshot Image Super-Resolution with Multiple Exemplars network (HIME) method. Compared with previous methods, our network can effectively handle the misalignment between the input and the reference without requiring facial priors and learn the aggregated reference set representation in an end-to-end manner. Furthermore, to reconstruct more detailed facial features, we propose a correlation loss that provides a rich representation of the local texture in a controllable spatial range. Experimental results demonstrate that the proposed framework not only has significantly fewer computation cost than recent exemplar-guided methods but also achieves better qualitative and quantitative performance.