 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Manufacturers with Privacy-Preserving AI Tools: A Case Study in Privacy-Preserving Machine Learning to Solve Real-World Problems
Jul 02, 2025Small- and medium-sized manufacturers need innovative data tools but, because of competition and privacy concerns, often do not want to share their proprietary data with researchers who might be interested in helping. This paper introduces a privacy-preserving platform by which manufacturers may safely share their data with researchers through secure methods, so that those researchers then create innovative tools to solve the manufacturers' real-world problems, and then provide tools that execute solutions back onto the platform for others to use with privacy and confidentiality guarantees. We illustrate this problem through a particular use case which addresses an important problem in the large-scale manufacturing of food crystals, which is that quality control relies on image analysis tools. Previous to our research, food crystals in the images were manually counted, which required substantial and time-consuming human efforts, but we have developed and deployed a crystal analysis tool which makes this process both more rapid and accurate. The tool enables automatic characterization of the crystal size distribution and numbers from microscope images while the natural imperfections from the sample preparation are automatically removed; a machine learning model to count high resolution translucent crystals and agglomeration of crystals was also developed to aid in these efforts. The resulting algorithm was then packaged for real-world use on the factory floor via a web-based app secured through the originating privacy-preserving platform, allowing manufacturers to use it while keeping their proprietary data secure. After demonstrating this full process, future directions are also explored.
HIME: Efficient Headshot Image Super-Resolution with Multiple Exemplars
Mar 28, 2022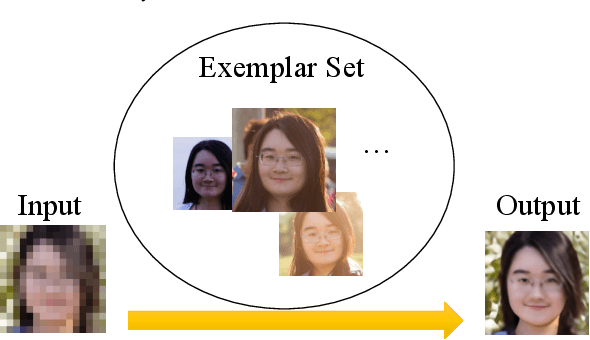
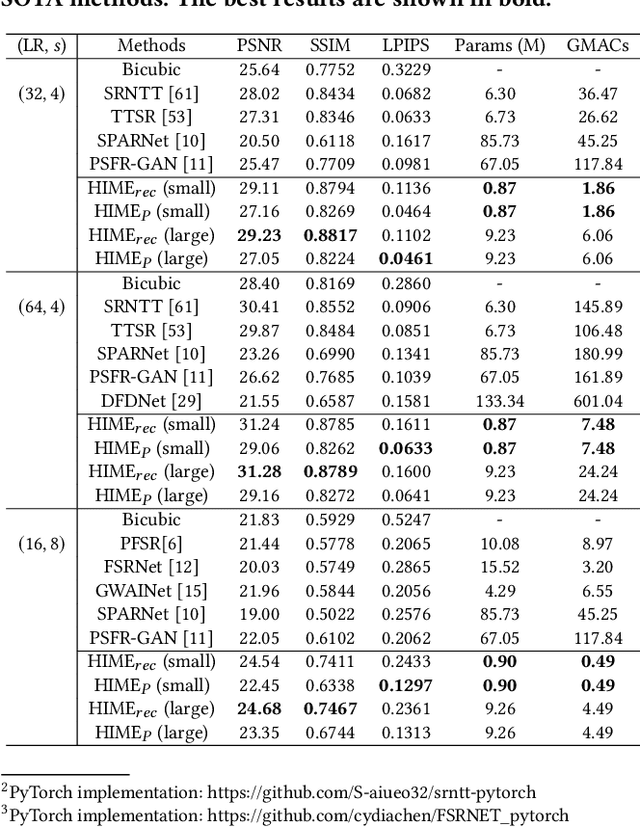
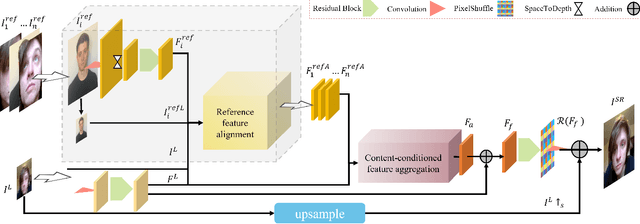
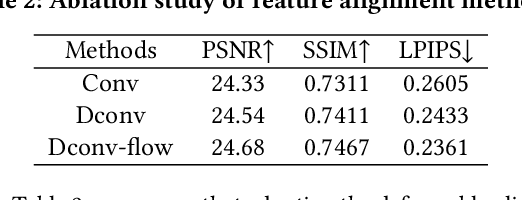
A promising direction for recovering the lost information in low-resolution headshot images is utilizing a set of high-resolution exemplars from the same identity. Complementary images in the reference set can improve the generated headshot quality across many different views and poses. However, it is challenging to make the best use of multiple exemplars: the quality and alignment of each exemplar cannot be guaranteed. Using low-quality and mismatched images as references will impair the output results. To overcome these issues, we propose an efficient Headshot Image Super-Resolution with Multiple Exemplars network (HIME) method. Compared with previous methods, our network can effectively handle the misalignment between the input and the reference without requiring facial priors and learn the aggregated reference set representation in an end-to-end manner. Furthermore, to reconstruct more detailed facial features, we propose a correlation loss that provides a rich representation of the local texture in a controllable spatial range. Experimental results demonstrate that the proposed framework not only has significantly fewer computation cost than recent exemplar-guided methods but also achieves better qualitative and quantitative performance.
The Blessing and the Curse of the Noise behind Facial Landmark Annotations
Jul 30, 2020

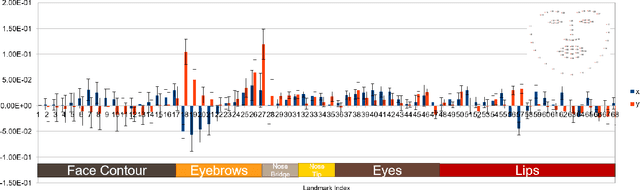
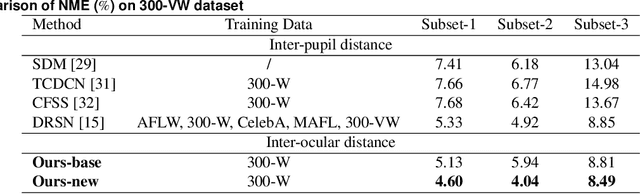
The evolving algorithms for 2D facial landmark detection empower people to recognize faces, analyze facial expressions, etc. However, existing methods still encounter problems of unstable facial landmarks when applied to videos. Because previous research shows that the instability of facial landmarks is caused by the inconsistency of labeling quality among the public datasets, we want to have a better understanding of the influence of annotation noise in them. In this paper, we make the following contributions: 1) we propose two metrics that quantitatively measure the stability of detected facial landmarks, 2) we model the annotation noise in an existing public dataset, 3) we investigate the influence of different types of noise in training face alignment neural networks, and propose corresponding solutions. Our results demonstrate improvements in both accuracy and stability of detected facial landmarks.
Blockwise Based Detection of Local Defects
Jun 06, 2019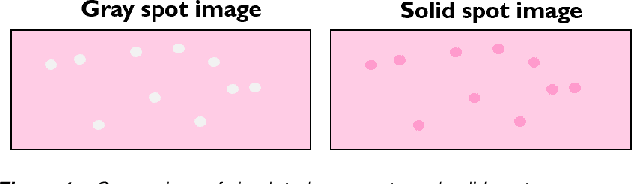
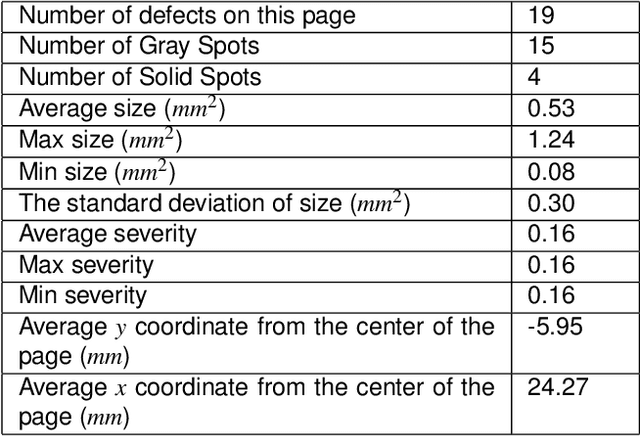
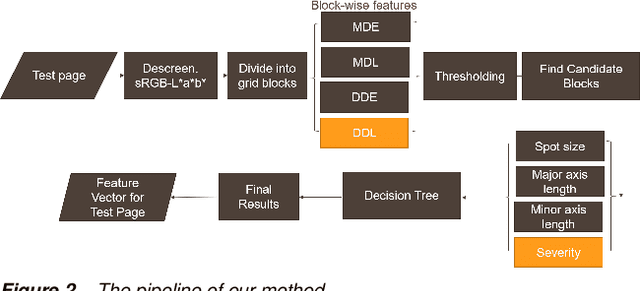
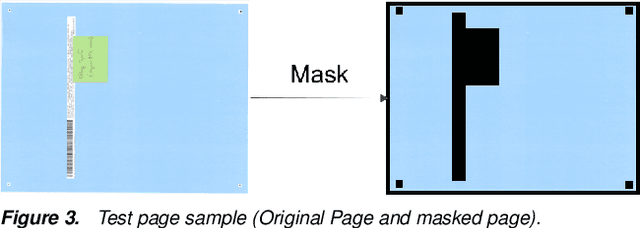
Print quality is an important criterion for a printer's performance. The detection, classification, and assessment of printing defects can reflect the printer's working status and help to locate mechanical problems inside. To handle all these questions, an efficient algorithm is needed to replace the traditionally visual checking method. In this paper, we focus on pages with local defects including gray spots and solid spots. We propose a coarse-to-fine method to detect local defects in a block-wise manner, and aggregate the blockwise attributes to generate the feature vector of the whole test page for a further ranking task. In the detection part, we first select candidate regions by thresholding a single feature. Then more detailed features of candidate blocks are calculated and sent to a decision tree that is previously trained on our training dataset. The final result is given by the decision tree model to control the false alarm rate while maintaining the required miss rate. Our algorithm is proved to be effective in detecting and classifying local defects compared with previous methods.
* 7 pages, 13 figures, IS&T Electronic Imaging 2019 Proceedings
Three Efficient, Low-Complexity Algorithms for Automatic Color Trapping
Aug 21, 2018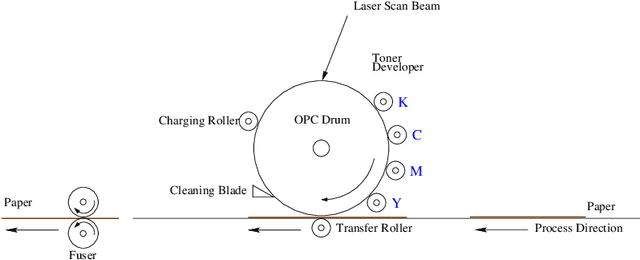
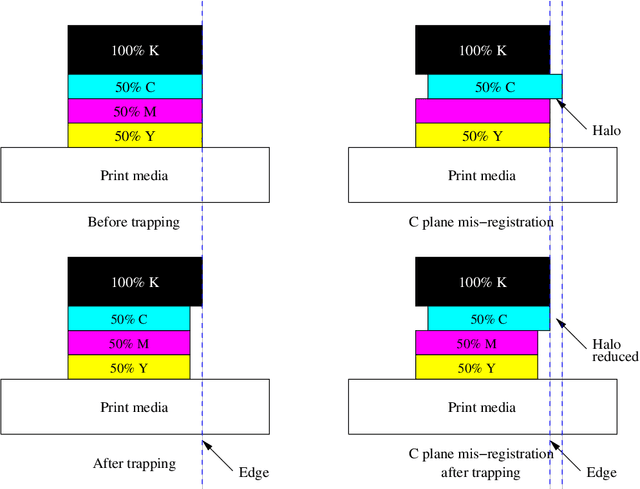
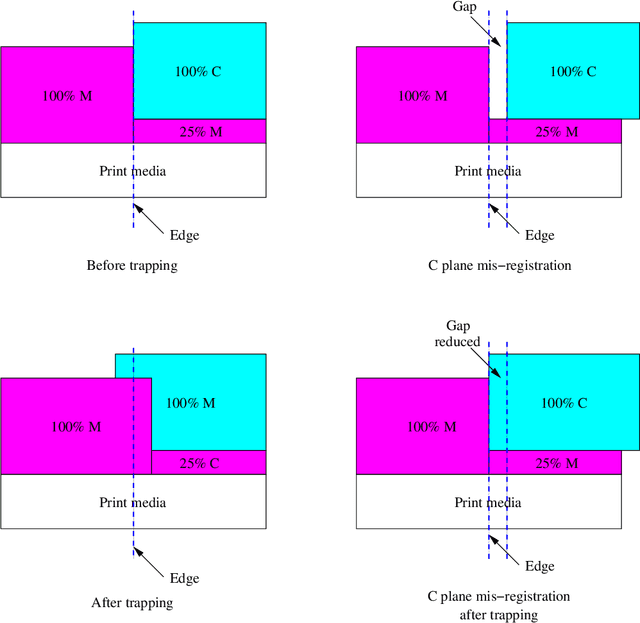
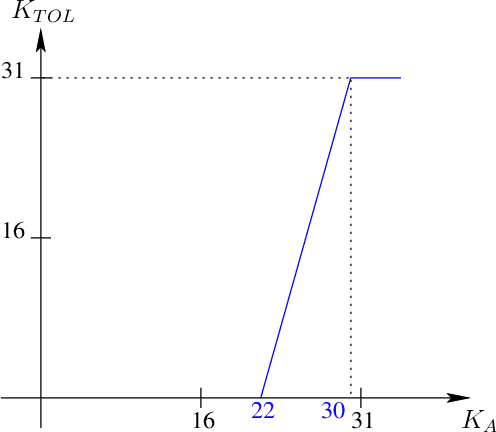
Color separations (most often cyan, magenta, yellow, and black) are commonly used in printing to reproduce multi-color images. For mechanical reasons, these color separations are generally not perfectly aligned with respect to each other when they are rendered by their respective imaging stations. This phenomenon, called color plane misregistration, causes gap and halo artifacts in the printed image. Color trapping is an image processing technique that aims to reduce these artifacts by modifying the susceptible edge boundaries to create small, unnoticeable overlaps between the color planes. We propose three low-complexity algorithms for automatic color trapping which hide the effects of small color plane mis-registrations. Our algorithms are designed for software or embedded firmware implementation. The trapping method they follow is based on a hardware-friendly technique proposed by J. Trask (JTHBCT03) which is too computationally expensive for software or firmware implementation. The first two algorithms are based on the use of look-up tables (LUTs). The first LUT-based algorithm corrects all registration errors of one pixel in extent and reduces several cases of misregistration errors of two pixels in extent using only 727 Kbytes of storage space. This algorithm is particularly attractive for implementation in the embedded firmware of low-cost formatter-based printers. The second LUT-based algorithm corrects all types of misregistration errors of up to two pixels in extent using 3.7 Mbytes of storage space. The third algorithm is a hybrid one that combines LUTs and feature extraction to minimize the storage requirements (724 Kbytes) while still correcting all misregistration errors of up to two pixels in extent. This algorithm is suitable for both embedded firmware implementation on low-cost formatter-based printers and software implementation on host-based printers.