 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabEmb: Joint Semantic-Structure Embedding for Table Annotation
Apr 21, 2026Table annotation is crucial for making web and enterprise tables usable in downstream NLP applications. Unlike textual data where learning semantically rich token or sentence embeddings often suffice, tables are structured combinations of columns wherein useful representations must jointly capture column's semantics and the inter-column relationships. Existing models learn by linearizing the 2D table into a 1D token sequence and encoding it with pretrained language models (PLMs) such as BERT. However, this leads to limited semantic quality and weaker generalization to unseen or rare values compared to modern LLMs, and degraded structural modeling due to 2D-to-1D flattening and context-length constraints. We propose TabEmb, which directly targets these limitations by decoupling semantic encoding from structural modeling. An LLM first produces semantically rich embeddings for each column, and a graph-based module over columns then injects relationships into the embeddings, yielding joint semantic-tructural representations for table annotation. Experiments show that TabEmb consistently outperforms strong baselines on different table annotation tasks. Source code and datasets are available at https://github.com/hoseinzadeehsan/TabEmb
HiFloat4 Format for Language Model Pre-training on Ascend NPUs
Apr 09, 2026Large foundation models have become central to modern machine learning, with performance scaling predictably with model size and data. However, training and deploying such models incur substantial computational and memory costs, motivating the development of low-precision training techniques. Recent work has demonstrated that 4-bit floating-point (FP4) formats--such as MXFP4 and NVFP4--can be successfully applied to linear GEMM operations in large language models (LLMs), achieving up to 4x improvements in compute throughput and memory efficiency compared to higher-precision baselines. In this work, we investigate the recently proposed HiFloat4 FP4 format for Huawei Ascend NPUs and systematically compare it with MXFP4 in large-scale training settings. All experiments are conducted on Ascend NPU clusters, with linear and expert GEMM operations performed entirely in FP4 precision. We evaluate both dense architectures (e.g., Pangu and LLaMA-style models) and mixture-of-experts (MoE) models, where both standard linear layers and expert-specific GEMMs operate in FP4. Furthermore, we explore stabilization techniques tailored to FP4 training that significantly reduce numerical degradation, maintaining relative error within 1% of full-precision baselines while preserving the efficiency benefits of 4-bit computation. Our results provide a comprehensive empirical study of FP4 training on NPUs and highlight the practical trade-offs between FP4 formats in large-scale dense and MoE models.
On building machine learning pipelines for Android malware detection: a procedural survey of practices, challenges and opportunities
Jun 12, 2023As the smartphone market leader, Android has been a prominent target for malware attacks. The number of malicious applications (apps) identified for it has increased continually over the past decade, creating an immense challenge for all parties involved. For market holders and researchers, in particular, the large number of samples has made manual malware detection unfeasible, leading to an influx of research that investigate Machine Learning (ML) approaches to automate this process. However, while some of the proposed approaches achieve high performance, rapidly evolving Android malware has made them unable to maintain their accuracy over time. This has created a need in the community to conduct further research, and build more flexible ML pipelines. Doing so, however, is currently hindered by a lack of systematic overview of the existing literature, to learn from and improve upon the existing solutions. Existing survey papers often focus only on parts of the ML process (e.g., data collection or model deployment), while omitting other important stages, such as model evaluation and explanation. In this paper, we address this problem with a review of 42 highly-cited papers, spanning a decade of research (from 2011 to 2021). We introduce a novel procedural taxonomy of the published literature, covering how they have used ML algorithms, what features they have engineered, which dimensionality reduction techniques they have employed, what datasets they have employed for training, and what their evaluation and explanation strategies are. Drawing from this taxonomy, we also identify gaps in knowledge and provide ideas for improvement and future work.
* file:///C:/Users/ibrahim_abualhaol/Downloads/s42400-022-00119-8.pdf
A Survey on Cross-Architectural IoT Malware Threat Hunting
Jun 09, 2023



In recent years, the increase in non-Windows malware threats had turned the focus of the cybersecurity community. Research works on hunting Windows PE-based malwares are maturing, whereas the developments on Linux malware threat hunting are relatively scarce. With the advent of the Internet of Things (IoT) era, smart devices that are getting integrated into human life have become a hackers highway for their malicious activities. The IoT devices employ various Unix-based architectures that follow ELF (Executable and Linkable Format) as their standard binary file specification. This study aims at providing a comprehensive survey on the latest developments in cross-architectural IoT malware detection and classification approaches. Aided by a modern taxonomy, we discuss the feature representations, feature extraction techniques, and machine learning models employed in the surveyed works. We further provide more insights on the practical challenges involved in cross-architectural IoT malware threat hunting and discuss various avenues to instill potential future research.
* https://ieeexplore.ieee.org/abstract/document/9462110
Echelon: Two-Tier Malware Detection for Raw Executables to Reduce False Alarms
Jan 04, 2021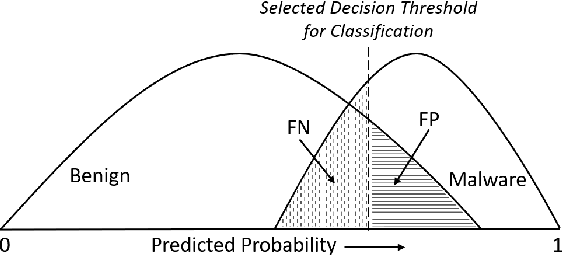
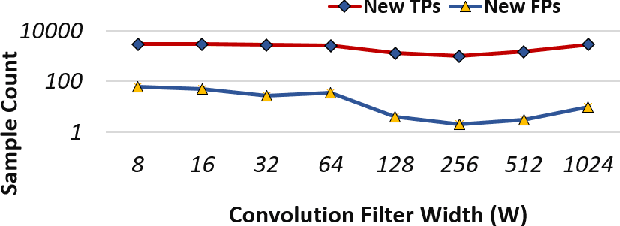
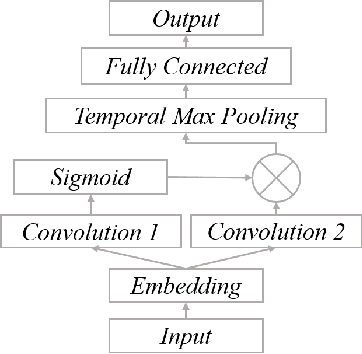
Existing malware detection approaches suffer from a simplistic trade-off between false positive rate (FPR) and true positive rate (TPR) due to a single tier classification approach, where the two measures adversely affect one another. The practical implication for malware detection is that FPR must be kept at an acceptably low level while TPR remains high. To this end, we propose a two-tiered learning, called ``Echelon", from raw byte data with no need for hand-crafted features. The first tier locks FPR at a specified target level, whereas the second tier improves TPR while maintaining the locked FPR. The core of Echelon lies at extracting activation information of the hidden layers of first tier model for constructing a stronger second tier model. Echelon is a framework in that it allows any existing CNN based model to be adapted in both tiers. We present experimental results of evaluating Echelon by adapting the state-of-the-art malware detection model ``Malconv" in the first and second tiers.