 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabEmb: Joint Semantic-Structure Embedding for Table Annotation
Apr 21, 2026Table annotation is crucial for making web and enterprise tables usable in downstream NLP applications. Unlike textual data where learning semantically rich token or sentence embeddings often suffice, tables are structured combinations of columns wherein useful representations must jointly capture column's semantics and the inter-column relationships. Existing models learn by linearizing the 2D table into a 1D token sequence and encoding it with pretrained language models (PLMs) such as BERT. However, this leads to limited semantic quality and weaker generalization to unseen or rare values compared to modern LLMs, and degraded structural modeling due to 2D-to-1D flattening and context-length constraints. We propose TabEmb, which directly targets these limitations by decoupling semantic encoding from structural modeling. An LLM first produces semantically rich embeddings for each column, and a graph-based module over columns then injects relationships into the embeddings, yielding joint semantic-tructural representations for table annotation. Experiments show that TabEmb consistently outperforms strong baselines on different table annotation tasks. Source code and datasets are available at https://github.com/hoseinzadeehsan/TabEmb
ZTab: Domain-based Zero-shot Annotation for Table Columns
Mar 12, 2026This study addresses the challenge of automatically detecting semantic column types in relational tables, a key task in many real-world applications. Zero-shot modeling eliminates the need for user-provided labeled training data, making it ideal for scenarios where data collection is costly or restricted due to privacy concerns. However, existing zero-shot models suffer from poor performance when the number of semantic column types is large, limited understanding of tabular structure, and privacy risks arising from dependence on high-performance closed-source LLMs. We introduce ZTab, a domain-based zero-shot framework that addresses both performance and zero-shot requirements. Given a domain configuration consisting of a set of predefined semantic types and sample table schemas, ZTab generates pseudo-tables for the sample schemas and fine-tunes an annotation LLM on them. ZTab is domain-based zero-shot in that it does not depend on user-specific labeled training data; therefore, no retraining is needed for a test table from a similar domain. We describe three cases of domain-based zero-shot. The domain configuration of ZTab provides a trade-off between the extent of zero-shot and annotation performance: a "universal domain" that contains all semantic types approaches "pure" zero-shot, while a "specialized domain" that contains semantic types for a specific application enables better zero-shot performance within that domain. Source code and datasets are available at https://github.com/hoseinzadeehsan/ZTab
Graph Neural Network Approach to Semantic Type Detection in Tables
Apr 30, 2024This study addresses the challenge of detecting semantic column types in relational tables, a key task in many real-world applications. While language models like BERT have improved prediction accuracy, their token input constraints limit the simultaneous processing of intra-table and inter-table information. We propose a novel approach using Graph Neural Networks (GNNs) to model intra-table dependencies, allowing language models to focus on inter-table information. Our proposed method not only outperforms existing state-of-the-art algorithms but also offers novel insights into the utility and functionality of various GNN types for semantic type detection. The code is available at https://github.com/hoseinzadeehsan/GAIT
Representation Extraction and Deep Neural Recommendation for Collaborative Filtering
Dec 09, 2020
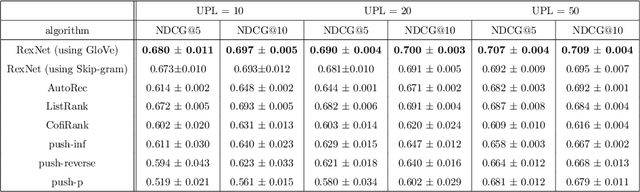
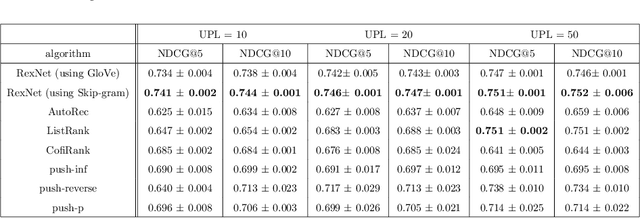
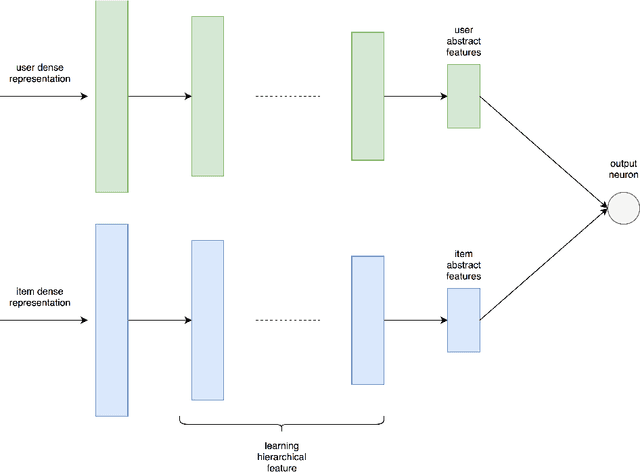
Many Deep Learning approaches solve complicated classification and regression problems by hierarchically constructing complex features from the raw input data. Although a few works have investigated the application of deep neural networks in recommendation domain, they mostly extract entity features by exploiting unstructured auxiliary data such as visual and textual information, and when it comes to using user-item rating matrix, feature extraction is done by using matrix factorization. As matrix factorization has some limitations, some works have been done to replace it with deep neural network. but these works either need to exploit unstructured data such item's reviews or images, or are specially designed to use implicit data and don't take user-item rating matrix into account. In this paper, we investigate the usage of novel representation learning algorithms to extract users and items representations from rating matrix, and offer a deep neural network for Collaborative Filtering. Our proposed approach is a modular algorithm consisted of two main phases: REpresentation eXtraction and a deep neural NETwork (RexNet). Using two joint and parallel neural networks in RexNet enables it to extract a hierarchy of features for each entity in order to predict the degree of interest of users to items. The resulted predictions are then used for the final recommendation. Unlike other deep learning recommendation approaches, RexNet is not dependent to unstructured auxiliary data such as visual and textual information, instead, it uses only the user-item rate matrix as its input. We evaluated RexNet in an extensive set of experiments against state of the art recommendation methods. The results show that RexNet significantly outperforms the baseline algorithms in a variety of data sets with different degrees of density.
U-CNNpred: A Universal CNN-based Predictor for Stock Markets
Nov 28, 2019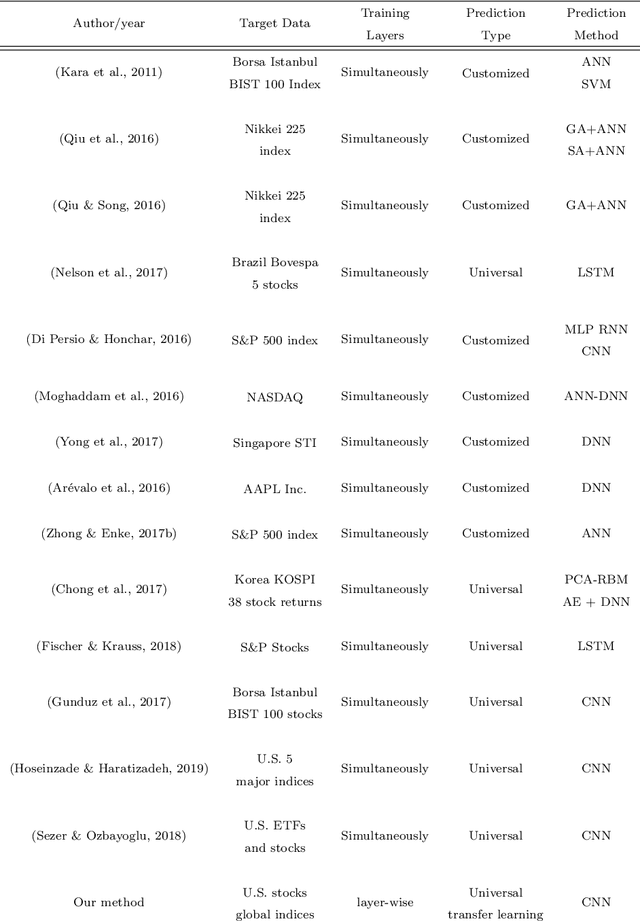
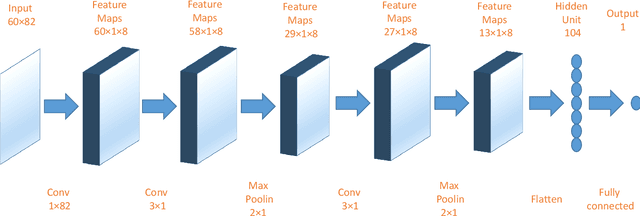
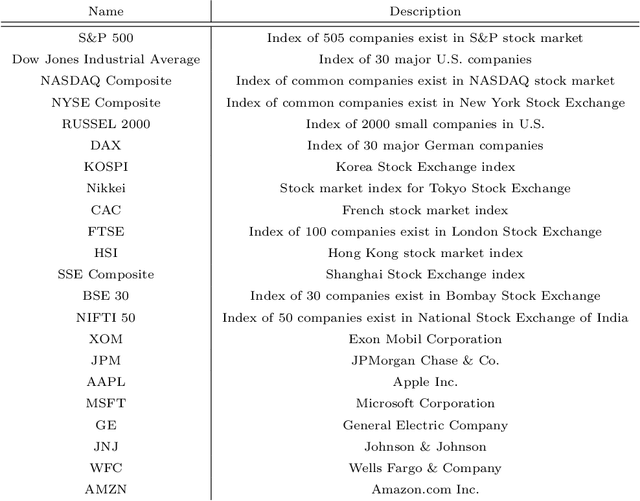
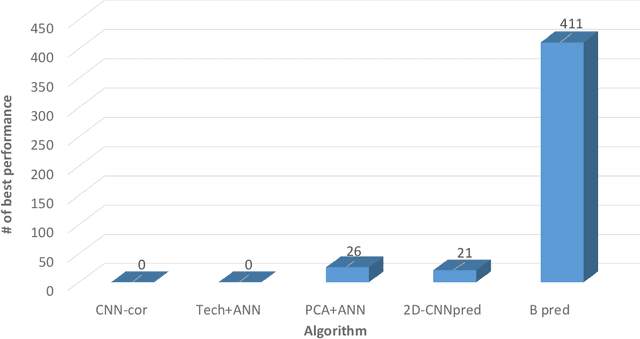
The performance of financial market prediction systems depends heavily on the quality of features it is using. While researchers have used various techniques for enhancing the stock specific features, less attention has been paid to extracting features that represent general mechanism of financial markets. In this paper, we investigate the importance of extracting such general features in stock market prediction domain and show how it can improve the performance of financial market prediction. We present a framework called U-CNNpred, that uses a CNN-based structure. A base model is trained in a specially designed layer-wise training procedure over a pool of historical data from many financial markets, in order to extract the common patterns from different markets. Our experiments, in which we have used hundreds of stocks in S\&P 500 as well as 14 famous indices around the world, show that this model can outperform baseline algorithms when predicting the directional movement of the markets for which it has been trained for. We also show that the base model can be fine-tuned for predicting new markets and achieve a better performance compared to the state of the art baseline algorithms that focus on constructing market-specific models from scratch.
CNNPred: CNN-based stock market prediction using several data sources
Oct 21, 2018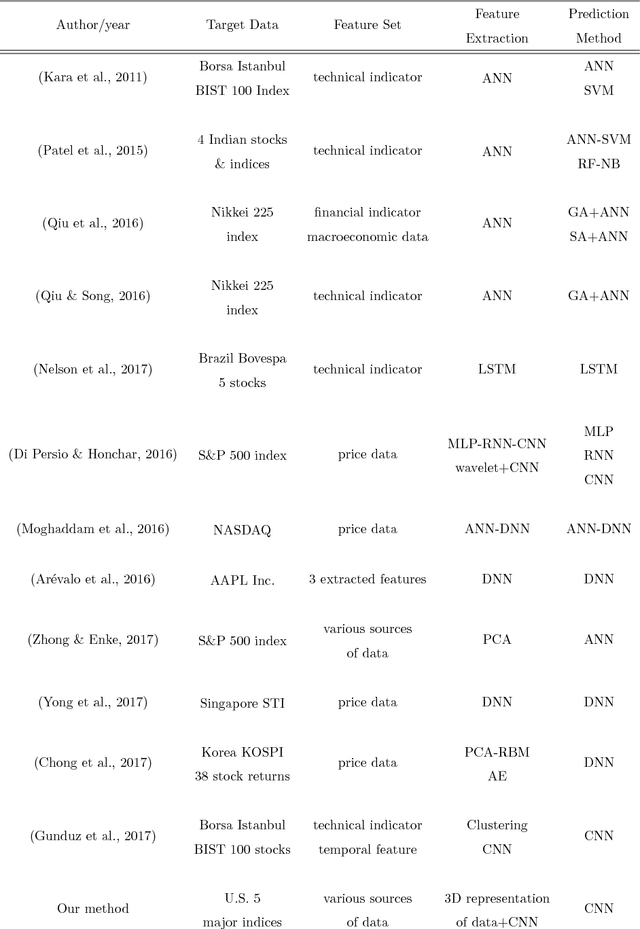
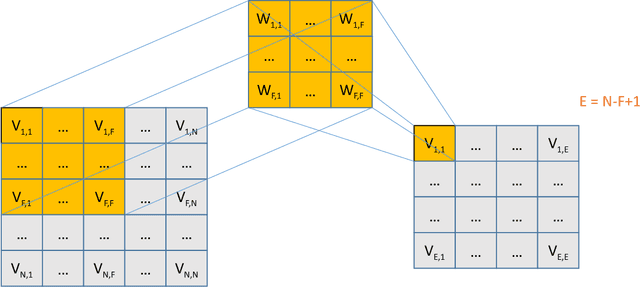
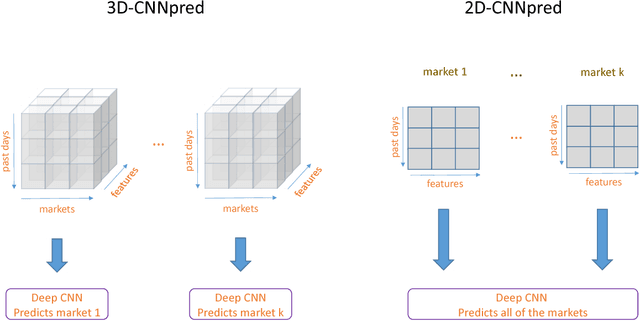

Feature extraction from financial data is one of the most important problems in market prediction domain for which many approaches have been suggested. Among other modern tools, convolutional neural networks (CNN) have recently been applied for automatic feature selection and market prediction. However, in experiments reported so far, less attention has been paid to the correlation among different markets as a possible source of information for extracting features. In this paper, we suggest a CNN-based framework with specially designed CNNs, that can be applied on a collection of data from a variety of sources, including different markets, in order to extract features for predicting the future of those markets. The suggested framework has been applied for predicting the next day's direction of movement for the indices of S&P 500, NASDAQ, DJI, NYSE, and RUSSELL markets based on various sets of initial features. The evaluations show a significant improvement in prediction's performance compared to the state of the art baseline algorithms.