 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecTr: Fast Speculative Decoding via Optimal Transport
Oct 23, 2023



Autoregressive sampling from large language models has led to state-of-the-art results in several natural language tasks. However, autoregressive sampling generates tokens one at a time making it slow, and even prohibitive in certain tasks. One way to speed up sampling is $\textit{speculative decoding}$: use a small model to sample a $\textit{draft}$ (block or sequence of tokens), and then score all tokens in the draft by the large language model in parallel. A subset of the tokens in the draft are accepted (and the rest rejected) based on a statistical method to guarantee that the final output follows the distribution of the large model. In this work, we provide a principled understanding of speculative decoding through the lens of optimal transport (OT) with $\textit{membership cost}$. This framework can be viewed as an extension of the well-known $\textit{maximal-coupling}$ problem. This new formulation enables us to generalize the speculative decoding method to allow for a set of $k$ candidates at the token-level, which leads to an improved optimal membership cost. We show that the optimal draft selection algorithm (transport plan) can be computed via linear programming, whose best-known runtime is exponential in $k$. We then propose a valid draft selection algorithm whose acceptance probability is $(1-1/e)$-optimal multiplicatively. Moreover, it can be computed in time almost linear with size of domain of a single token. Using this $new draft selection$ algorithm, we develop a new autoregressive sampling algorithm called $\textit{SpecTr}$, which provides speedup in decoding while ensuring that there is no quality degradation in the decoded output. We experimentally demonstrate that for state-of-the-art large language models, the proposed approach achieves a wall clock speedup of 2.13X, a further 1.37X speedup over speculative decoding on standard benchmarks.
The importance of feature preprocessing for differentially private linear optimization
Jul 19, 2023

Training machine learning models with differential privacy (DP) has received increasing interest in recent years. One of the most popular algorithms for training differentially private models is differentially private stochastic gradient descent (DPSGD) and its variants, where at each step gradients are clipped and combined with some noise. Given the increasing usage of DPSGD, we ask the question: is DPSGD alone sufficient to find a good minimizer for every dataset under privacy constraints? As a first step towards answering this question, we show that even for the simple case of linear classification, unlike non-private optimization, (private) feature preprocessing is vital for differentially private optimization. In detail, we first show theoretically that there exists an example where without feature preprocessing, DPSGD incurs a privacy error proportional to the maximum norm of features over all samples. We then propose an algorithm called DPSGD-F, which combines DPSGD with feature preprocessing and prove that for classification tasks, it incurs a privacy error proportional to the diameter of the features $\max_{x, x' \in D} \|x - x'\|_2$. We then demonstrate the practicality of our algorithm on image classification benchmarks.
FedYolo: Augmenting Federated Learning with Pretrained Transformers
Jul 10, 2023



The growth and diversity of machine learning applications motivate a rethinking of learning with mobile and edge devices. How can we address diverse client goals and learn with scarce heterogeneous data? While federated learning aims to address these issues, it has challenges hindering a unified solution. Large transformer models have been shown to work across a variety of tasks achieving remarkable few-shot adaptation. This raises the question: Can clients use a single general-purpose model, rather than custom models for each task, while obeying device and network constraints? In this work, we investigate pretrained transformers (PTF) to achieve these on-device learning goals and thoroughly explore the roles of model size and modularity, where the latter refers to adaptation through modules such as prompts or adapters. Focusing on federated learning, we demonstrate that: (1) Larger scale shrinks the accuracy gaps between alternative approaches and improves heterogeneity robustness. Scale allows clients to run more local SGD epochs which can significantly reduce the number of communication rounds. At the extreme, clients can achieve respectable accuracy locally highlighting the potential of fully-local learning. (2) Modularity, by design, enables $>$100$\times$ less communication in bits. Surprisingly, it also boosts the generalization capability of local adaptation methods and the robustness of smaller PTFs. Finally, it enables clients to solve multiple unrelated tasks simultaneously using a single PTF, whereas full updates are prone to catastrophic forgetting. These insights on scale and modularity motivate a new federated learning approach we call "You Only Load Once" (FedYolo): The clients load a full PTF model once and all future updates are accomplished through communication-efficient modules with limited catastrophic-forgetting, where each task is assigned to its own module.
Subset-Based Instance Optimality in Private Estimation
Mar 01, 2023

We propose a new definition of instance optimality for differentially private estimation algorithms. Our definition requires an optimal algorithm to compete, simultaneously for every dataset $D$, with the best private benchmark algorithm that (a) knows $D$ in advance and (b) is evaluated by its worst-case performance on large subsets of $D$. That is, the benchmark algorithm need not perform well when potentially extreme points are added to $D$; it only has to handle the removal of a small number of real data points that already exist. This makes our benchmark significantly stronger than those proposed in prior work. We nevertheless show, for real-valued datasets, how to construct private algorithms that achieve our notion of instance optimality when estimating a broad class of dataset properties, including means, quantiles, and $\ell_p$-norm minimizers. For means in particular, we provide a detailed analysis and show that our algorithm simultaneously matches or exceeds the asymptotic performance of existing algorithms under a range of distributional assumptions.
Concentration Bounds for Discrete Distribution Estimation in KL Divergence
Feb 14, 2023We study the problem of discrete distribution estimation in KL divergence and provide concentration bounds for the Laplace estimator. We show that the deviation from mean scales as $\sqrt{k}/n$ when $n \ge k$, improving upon the best prior result of $k/n$. We also establish a matching lower bound that shows that our bounds are tight up to polylogarithmic factors.
Private Domain Adaptation from a Public Source
Aug 12, 2022
A key problem in a variety of applications is that of domain adaptation from a public source domain, for which a relatively large amount of labeled data with no privacy constraints is at one's disposal, to a private target domain, for which a private sample is available with very few or no labeled data. In regression problems with no privacy constraints on the source or target data, a discrepancy minimization algorithm based on several theoretical guarantees was shown to outperform a number of other adaptation algorithm baselines. Building on that approach, we design differentially private discrepancy-based algorithms for adaptation from a source domain with public labeled data to a target domain with unlabeled private data. The design and analysis of our private algorithms critically hinge upon several key properties we prove for a smooth approximation of the weighted discrepancy, such as its smoothness with respect to the $\ell_1$-norm and the sensitivity of its gradient. Our solutions are based on private variants of Frank-Wolfe and Mirror-Descent algorithms. We show that our adaptation algorithms benefit from strong generalization and privacy guarantees and report the results of experiments demonstrating their effectiveness.
Histogram Estimation under User-level Privacy with Heterogeneous Data
Jun 07, 2022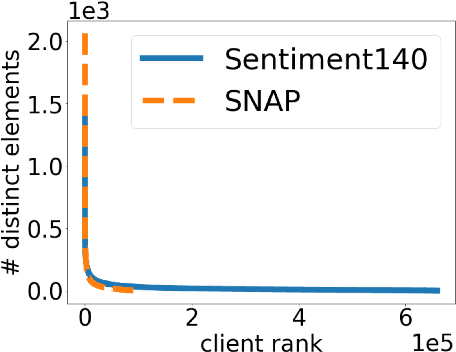
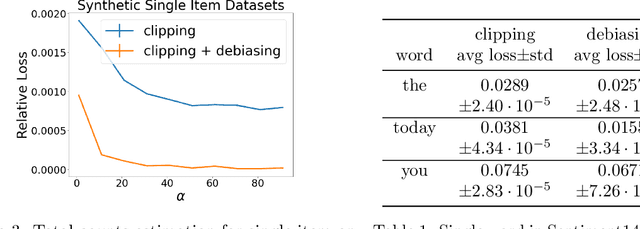
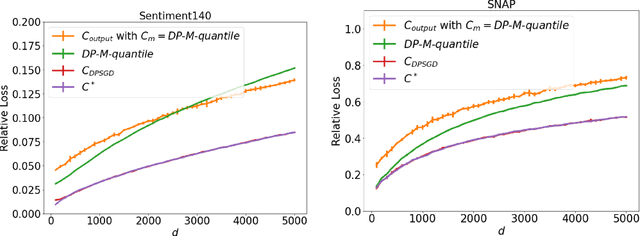
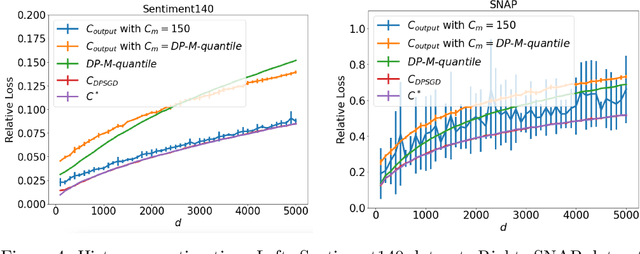
We study the problem of histogram estimation under user-level differential privacy, where the goal is to preserve the privacy of all entries of any single user. While there is abundant literature on this classical problem under the item-level privacy setup where each user contributes only one data point, little has been known for the user-level counterpart. We consider the heterogeneous scenario where both the quantity and distribution of data can be different for each user. We propose an algorithm based on a clipping strategy that almost achieves a two-approximation with respect to the best clipping threshold in hindsight. This result holds without any distribution assumptions on the data. We also prove that the clipping bias can be significantly reduced when the counts are from non-i.i.d. Poisson distributions and show empirically that our debiasing method provides improvements even without such constraints. Experiments on both real and synthetic datasets verify our theoretical findings and demonstrate the effectiveness of our algorithms.
Differentially Private Learning with Margin Guarantees
Apr 21, 2022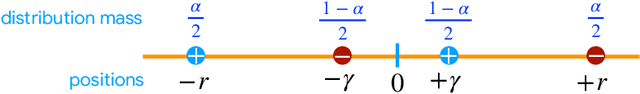
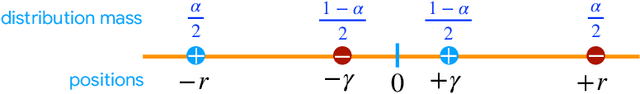
We present a series of new differentially private (DP) algorithms with dimension-independent margin guarantees. For the family of linear hypotheses, we give a pure DP learning algorithm that benefits from relative deviation margin guarantees, as well as an efficient DP learning algorithm with margin guarantees. We also present a new efficient DP learning algorithm with margin guarantees for kernel-based hypotheses with shift-invariant kernels, such as Gaussian kernels, and point out how our results can be extended to other kernels using oblivious sketching techniques. We further give a pure DP learning algorithm for a family of feed-forward neural networks for which we prove margin guarantees that are independent of the input dimension. Additionally, we describe a general label DP learning algorithm, which benefits from relative deviation margin bounds and is applicable to a broad family of hypothesis sets, including that of neural networks. Finally, we show how our DP learning algorithms can be augmented in a general way to include model selection, to select the best confidence margin parameter.
Correlated quantization for distributed mean estimation and optimization
Mar 09, 2022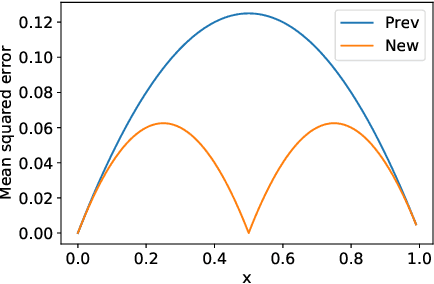
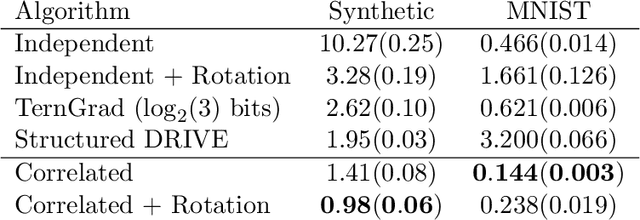
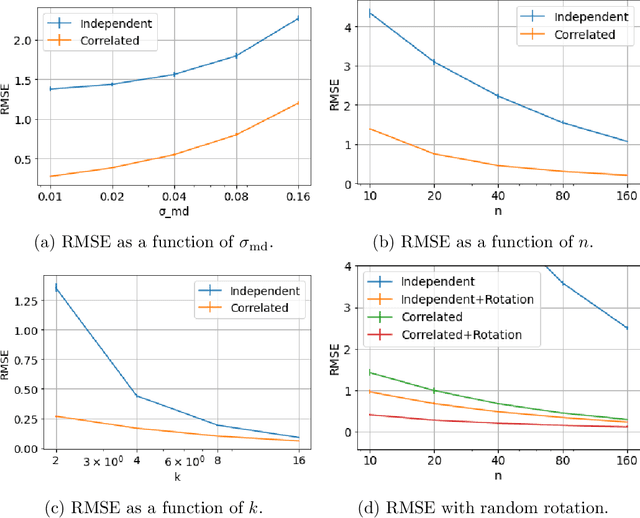
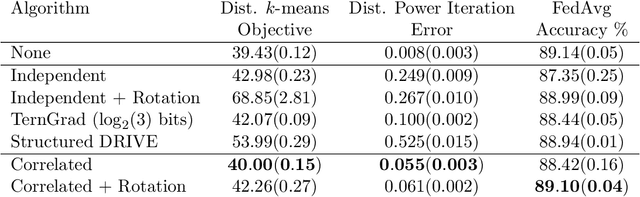
We study the problem of distributed mean estimation and optimization under communication constraints. We propose a correlated quantization protocol whose error guarantee depends on the deviation of data points instead of their absolute range. The design doesn't need any prior knowledge on the concentration property of the dataset, which is required to get such dependence in previous works. We show that applying the proposed protocol as sub-routine in distributed optimization algorithms leads to better convergence rates. We also prove the optimality of our protocol under mild assumptions. Experimental results show that our proposed algorithm outperforms existing mean estimation protocols on a diverse set of tasks.
The Fundamental Price of Secure Aggregation in Differentially Private Federated Learning
Mar 07, 2022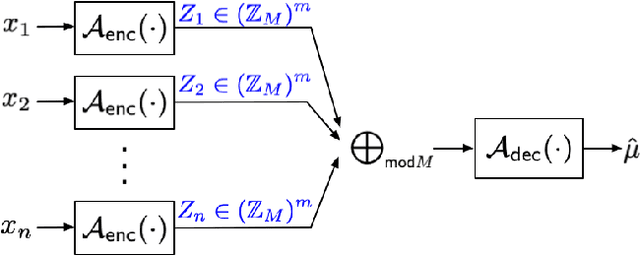
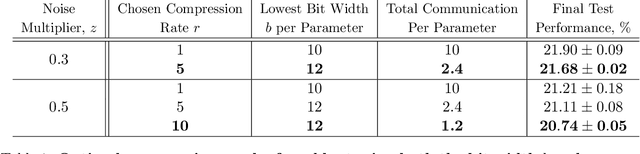
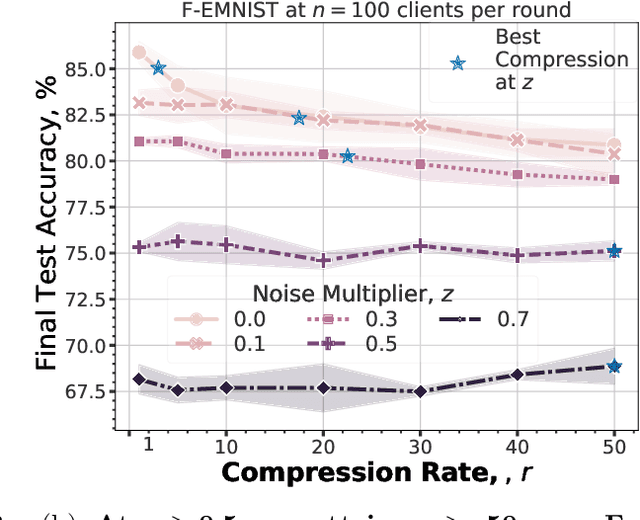
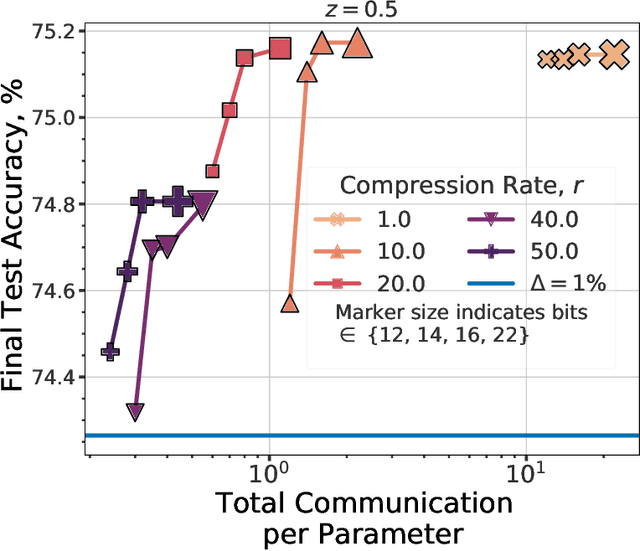
We consider the problem of training a $d$ dimensional model with distributed differential privacy (DP) where secure aggregation (SecAgg) is used to ensure that the server only sees the noisy sum of $n$ model updates in every training round. Taking into account the constraints imposed by SecAgg, we characterize the fundamental communication cost required to obtain the best accuracy achievable under $\varepsilon$ central DP (i.e. under a fully trusted server and no communication constraints). Our results show that $\tilde{O}\left( \min(n^2\varepsilon^2, d) \right)$ bits per client are both sufficient and necessary, and this fundamental limit can be achieved by a linear scheme based on sparse random projections. This provides a significant improvement relative to state-of-the-art SecAgg distributed DP schemes which use $\tilde{O}(d\log(d/\varepsilon^2))$ bits per client. Empirically, we evaluate our proposed scheme on real-world federated learning tasks. We find that our theoretical analysis is well matched in practice. In particular, we show that we can reduce the communication cost significantly to under $1.2$ bits per parameter in realistic privacy settings without decreasing test-time performance. Our work hence theoretically and empirically specifies the fundamental price of using SecAgg.