 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmrita Saha
Scene Graph based Image Retrieval -- A case study on the CLEVR Dataset
Nov 03, 2019
With the prolification of multimodal interaction in various domains, recently there has been much interest in text based image retrieval in the computer vision community. However most of the state of the art techniques model this problem in a purely neural way, which makes it difficult to incorporate pragmatic strategies in searching a large scale catalog especially when the search requirements are insufficient and the model needs to resort to an interactive retrieval process through multiple iterations of question-answering. Motivated by this, we propose a neural-symbolic approach for a one-shot retrieval of images from a large scale catalog, given the caption description. To facilitate this, we represent the catalog and caption as scene-graphs and model the retrieval task as a learnable graph matching problem, trained end-to-end with a REINFORCE algorithm. Further, we briefly describe an extension of this pipeline to an iterative retrieval framework, based on interactive questioning and answering.
DuoRC: Towards Complex Language Understanding with Paraphrased Reading Comprehension
Oct 10, 2018
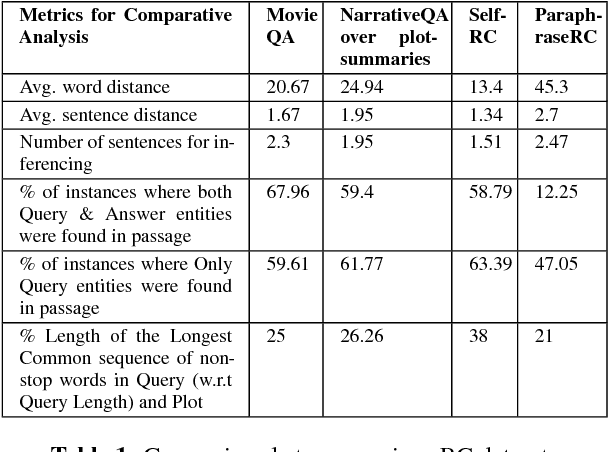
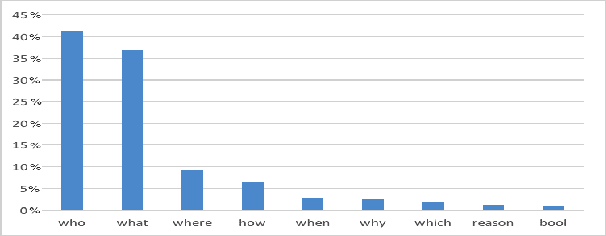
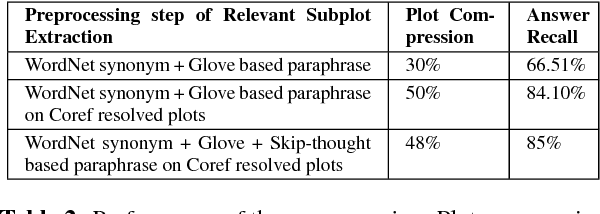
We propose DuoRC, a novel dataset for Reading Comprehension (RC) that motivates several new challenges for neural approaches in language understanding beyond those offered by existing RC datasets. DuoRC contains 186,089 unique question-answer pairs created from a collection of 7680 pairs of movie plots where each pair in the collection reflects two versions of the same movie - one from Wikipedia and the other from IMDb - written by two different authors. We asked crowdsourced workers to create questions from one version of the plot and a different set of workers to extract or synthesize answers from the other version. This unique characteristic of DuoRC where questions and answers are created from different versions of a document narrating the same underlying story, ensures by design, that there is very little lexical overlap between the questions created from one version and the segments containing the answer in the other version. Further, since the two versions have different levels of plot detail, narration style, vocabulary, etc., answering questions from the second version requires deeper language understanding and incorporating external background knowledge. Additionally, the narrative style of passages arising from movie plots (as opposed to typical descriptive passages in existing datasets) exhibits the need to perform complex reasoning over events across multiple sentences. Indeed, we observe that state-of-the-art neural RC models which have achieved near human performance on the SQuAD dataset, even when coupled with traditional NLP techniques to address the challenges presented in DuoRC exhibit very poor performance (F1 score of 37.42% on DuoRC v/s 86% on SQuAD dataset). This opens up several interesting research avenues wherein DuoRC could complement other RC datasets to explore novel neural approaches for studying language understanding.
Complex Sequential Question Answering: Towards Learning to Converse Over Linked Question Answer Pairs with a Knowledge Graph
Oct 04, 2018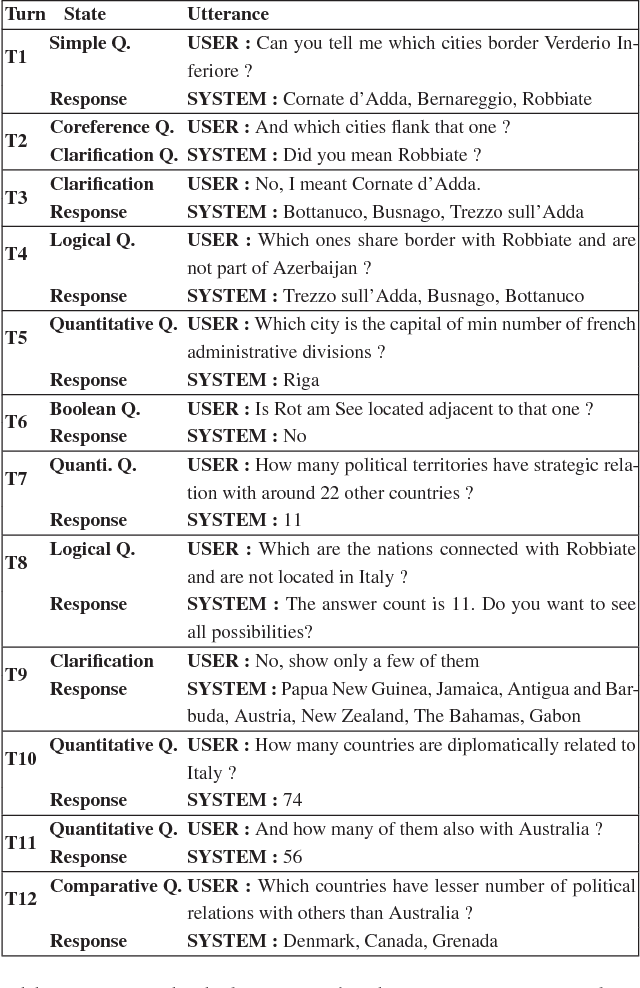
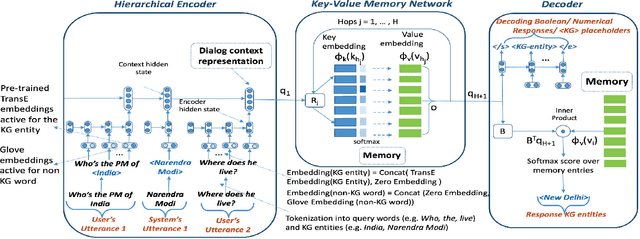
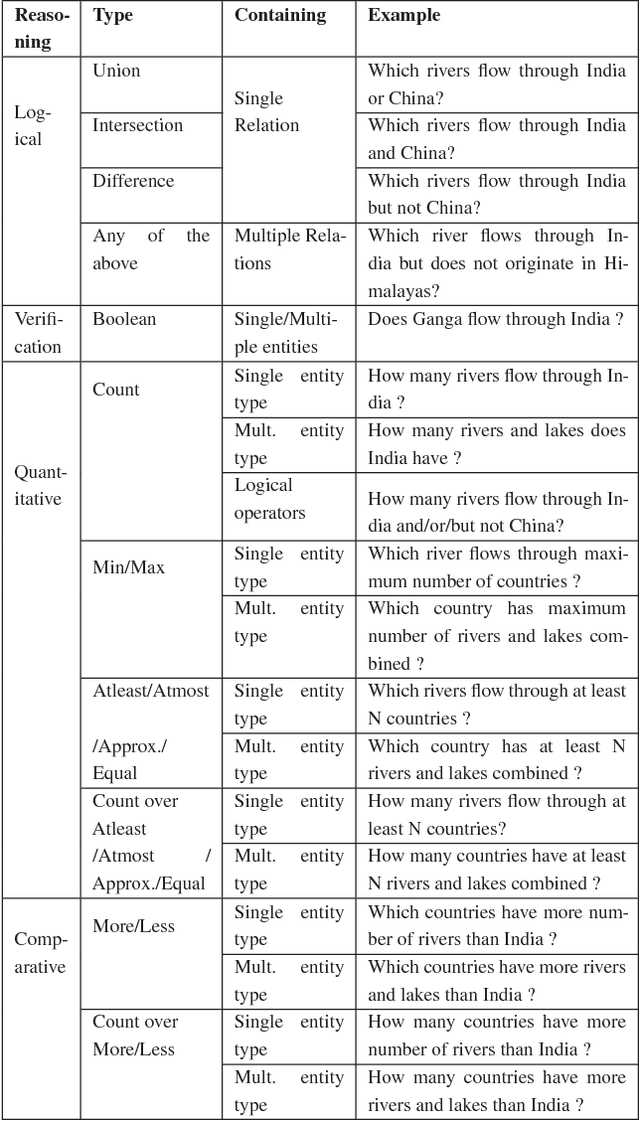
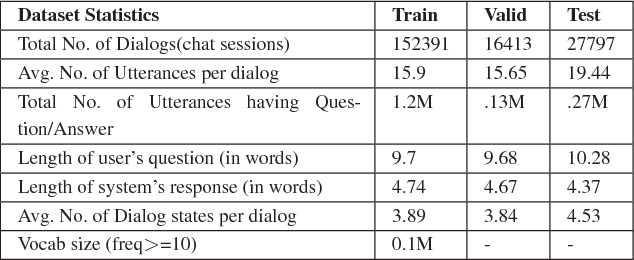
While conversing with chatbots, humans typically tend to ask many questions, a significant portion of which can be answered by referring to large-scale knowledge graphs (KG). While Question Answering (QA) and dialog systems have been studied independently, there is a need to study them closely to evaluate such real-world scenarios faced by bots involving both these tasks. Towards this end, we introduce the task of Complex Sequential QA which combines the two tasks of (i) answering factual questions through complex inferencing over a realistic-sized KG of millions of entities, and (ii) learning to converse through a series of coherently linked QA pairs. Through a labor intensive semi-automatic process, involving in-house and crowdsourced workers, we created a dataset containing around 200K dialogs with a total of 1.6M turns. Further, unlike existing large scale QA datasets which contain simple questions that can be answered from a single tuple, the questions in our dialogs require a larger subgraph of the KG. Specifically, our dataset has questions which require logical, quantitative, and comparative reasoning as well as their combinations. This calls for models which can: (i) parse complex natural language questions, (ii) use conversation context to resolve coreferences and ellipsis in utterances, (iii) ask for clarifications for ambiguous queries, and finally (iv) retrieve relevant subgraphs of the KG to answer such questions. However, our experiments with a combination of state of the art dialog and QA models show that they clearly do not achieve the above objectives and are inadequate for dealing with such complex real world settings. We believe that this new dataset coupled with the limitations of existing models as reported in this paper should encourage further research in Complex Sequential QA.
Towards Building Large Scale Multimodal Domain-Aware Conversation Systems
Jan 31, 2018
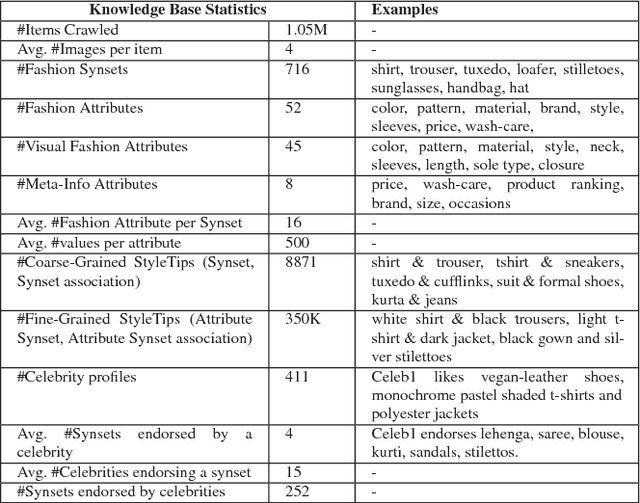
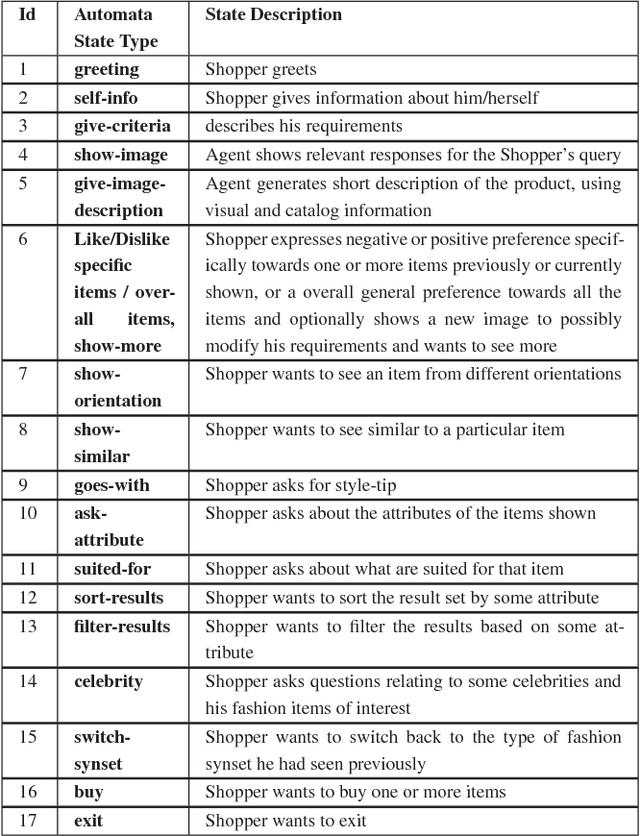
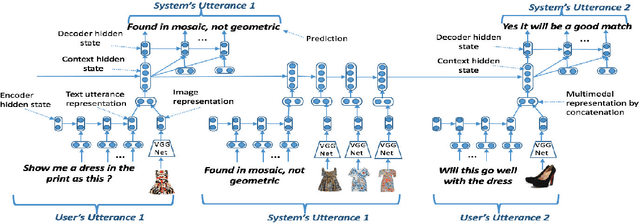
While multimodal conversation agents are gaining importance in several domains such as retail, travel etc., deep learning research in this area has been limited primarily due to the lack of availability of large-scale, open chatlogs. To overcome this bottleneck, in this paper we introduce the task of multimodal, domain-aware conversations, and propose the MMD benchmark dataset. This dataset was gathered by working in close coordination with large number of domain experts in the retail domain. These experts suggested various conversations flows and dialog states which are typically seen in multimodal conversations in the fashion domain. Keeping these flows and states in mind, we created a dataset consisting of over 150K conversation sessions between shoppers and sales agents, with the help of in-house annotators using a semi-automated manually intense iterative process. With this dataset, we propose 5 new sub-tasks for multimodal conversations along with their evaluation methodology. We also propose two multimodal neural models in the encode-attend-decode paradigm and demonstrate their performance on two of the sub-tasks, namely text response generation and best image response selection. These experiments serve to establish baseline performance and open new research directions for each of these sub-tasks. Further, for each of the sub-tasks, we present a `per-state evaluation' of 9 most significant dialog states, which would enable more focused research into understanding the challenges and complexities involved in each of these states.
A Correlational Encoder Decoder Architecture for Pivot Based Sequence Generation
Jun 15, 2016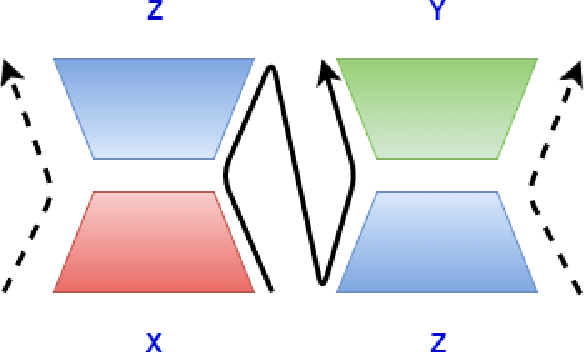
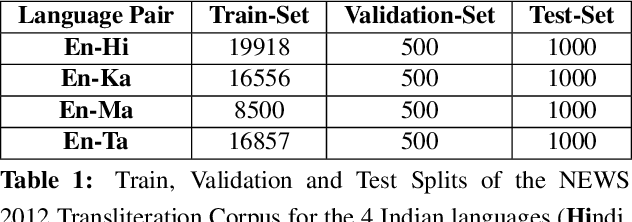
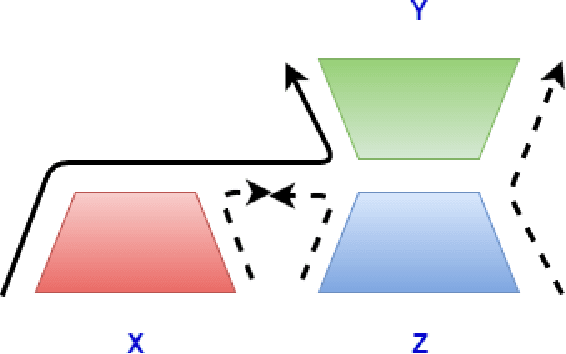

Interlingua based Machine Translation (MT) aims to encode multiple languages into a common linguistic representation and then decode sentences in multiple target languages from this representation. In this work we explore this idea in the context of neural encoder decoder architectures, albeit on a smaller scale and without MT as the end goal. Specifically, we consider the case of three languages or modalities X, Z and Y wherein we are interested in generating sequences in Y starting from information available in X. However, there is no parallel training data available between X and Y but, training data is available between X & Z and Z & Y (as is often the case in many real world applications). Z thus acts as a pivot/bridge. An obvious solution, which is perhaps less elegant but works very well in practice is to train a two stage model which first converts from X to Z and then from Z to Y. Instead we explore an interlingua inspired solution which jointly learns to do the following (i) encode X and Z to a common representation and (ii) decode Y from this common representation. We evaluate our model on two tasks: (i) bridge transliteration and (ii) bridge captioning. We report promising results in both these applications and believe that this is a right step towards truly interlingua inspired encoder decoder architectures.
Taxonomy grounded aggregation of classifiers with different label sets
Dec 01, 2015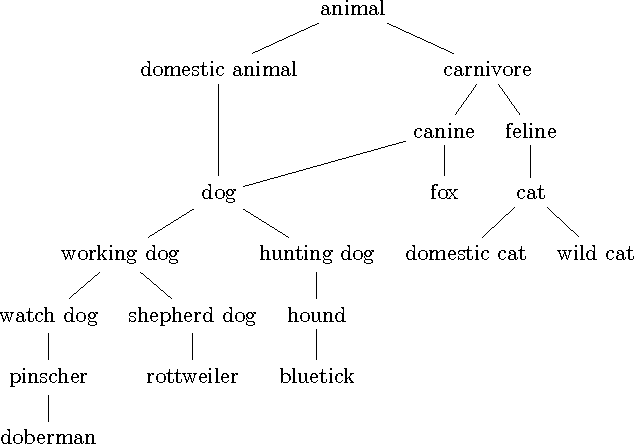
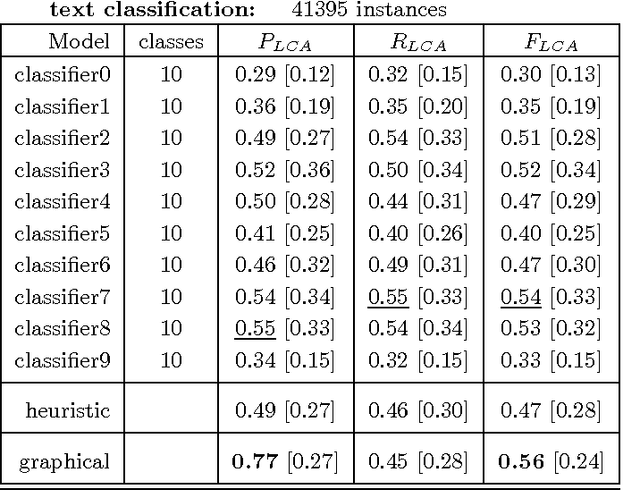
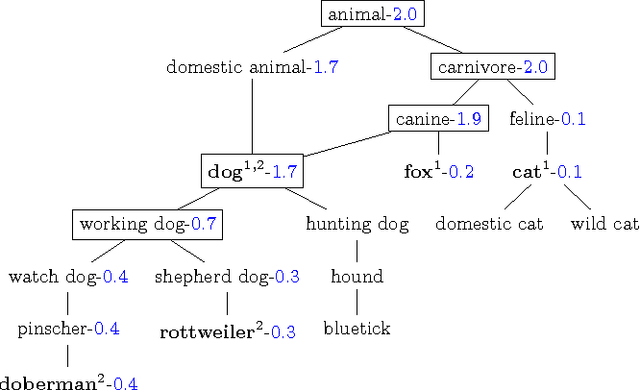
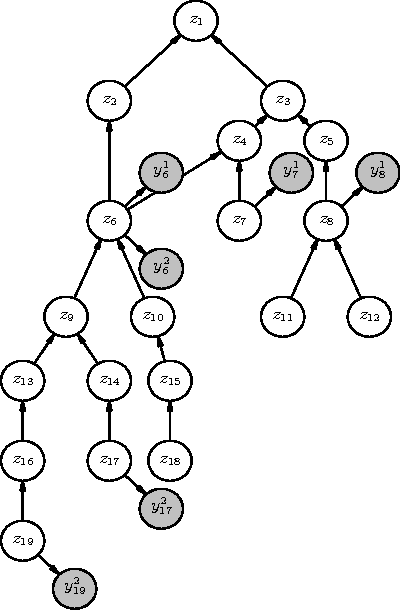
We describe the problem of aggregating the label predictions of diverse classifiers using a class taxonomy. Such a taxonomy may not have been available or referenced when the individual classifiers were designed and trained, yet mapping the output labels into the taxonomy is desirable to integrate the effort spent in training the constituent classifiers. A hierarchical taxonomy representing some domain knowledge may be different from, but partially mappable to, the label sets of the individual classifiers. We present a heuristic approach and a principled graphical model to aggregate the label predictions by grounding them into the available taxonomy. Our model aggregates the labels using the taxonomy structure as constraints to find the most likely hierarchically consistent class. We experimentally validate our proposed method on image and text classification tasks.
An Autoencoder Approach to Learning Bilingual Word Representations
Feb 06, 2014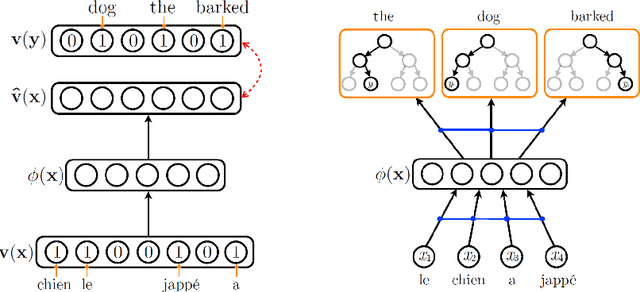
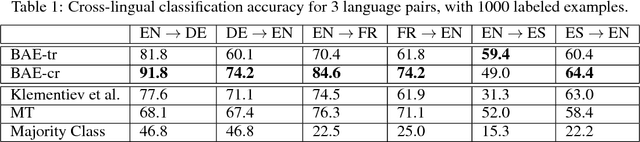

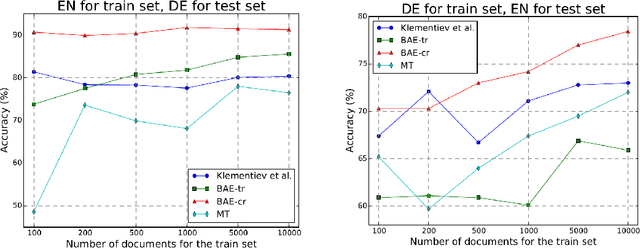
Cross-language learning allows us to use training data from one language to build models for a different language. Many approaches to bilingual learning require that we have word-level alignment of sentences from parallel corpora. In this work we explore the use of autoencoder-based methods for cross-language learning of vectorial word representations that are aligned between two languages, while not relying on word-level alignments. We show that by simply learning to reconstruct the bag-of-words representations of aligned sentences, within and between languages, we can in fact learn high-quality representations and do without word alignments. Since training autoencoders on word observations presents certain computational issues, we propose and compare different variations adapted to this setting. We also propose an explicit correlation maximizing regularizer that leads to significant improvement in the performance. We empirically investigate the success of our approach on the problem of cross-language test classification, where a classifier trained on a given language (e.g., English) must learn to generalize to a different language (e.g., German). These experiments demonstrate that our approaches are competitive with the state-of-the-art, achieving up to 10-14 percentage point improvements over the best reported results on this task.