 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deformable 3D Graph Similarity to Track Plant Cells in Unregistered Time Lapse Images
Sep 21, 2023Tracking of plant cells in images obtained by microscope is a challenging problem due to biological phenomena such as large number of cells, non-uniform growth of different layers of the tightly packed plant cells and cell division. Moreover, images in deeper layers of the tissue being noisy and unavoidable systemic errors inherent in the imaging process further complicates the problem. In this paper, we propose a novel learning-based method that exploits the tightly packed three-dimensional cell structure of plant cells to create a three-dimensional graph in order to perform accurate cell tracking. We further propose novel algorithms for cell division detection and effective three-dimensional registration, which improve upon the state-of-the-art algorithms. We demonstrate the efficacy of our algorithm in terms of tracking accuracy and inference-time on a benchmark dataset.
Prior-guided Source-free Domain Adaptation for Human Pose Estimation
Aug 26, 2023



Domain adaptation methods for 2D human pose estimation typically require continuous access to the source data during adaptation, which can be challenging due to privacy, memory, or computational constraints. To address this limitation, we focus on the task of source-free domain adaptation for pose estimation, where a source model must adapt to a new target domain using only unlabeled target data. Although recent advances have introduced source-free methods for classification tasks, extending them to the regression task of pose estimation is non-trivial. In this paper, we present Prior-guided Self-training (POST), a pseudo-labeling approach that builds on the popular Mean Teacher framework to compensate for the distribution shift. POST leverages prediction-level and feature-level consistency between a student and teacher model against certain image transformations. In the absence of source data, POST utilizes a human pose prior that regularizes the adaptation process by directing the model to generate more accurate and anatomically plausible pose pseudo-labels. Despite being simple and intuitive, our framework can deliver significant performance gains compared to applying the source model directly to the target data, as demonstrated in our extensive experiments and ablation studies. In fact, our approach achieves comparable performance to recent state-of-the-art methods that use source data for adaptation.
SUMMIT: Source-Free Adaptation of Uni-Modal Models to Multi-Modal Targets
Aug 23, 2023



Scene understanding using multi-modal data is necessary in many applications, e.g., autonomous navigation. To achieve this in a variety of situations, existing models must be able to adapt to shifting data distributions without arduous data annotation. Current approaches assume that the source data is available during adaptation and that the source consists of paired multi-modal data. Both these assumptions may be problematic for many applications. Source data may not be available due to privacy, security, or economic concerns. Assuming the existence of paired multi-modal data for training also entails significant data collection costs and fails to take advantage of widely available freely distributed pre-trained uni-modal models. In this work, we relax both of these assumptions by addressing the problem of adapting a set of models trained independently on uni-modal data to a target domain consisting of unlabeled multi-modal data, without having access to the original source dataset. Our proposed approach solves this problem through a switching framework which automatically chooses between two complementary methods of cross-modal pseudo-label fusion -- agreement filtering and entropy weighting -- based on the estimated domain gap. We demonstrate our work on the semantic segmentation problem. Experiments across seven challenging adaptation scenarios verify the efficacy of our approach, achieving results comparable to, and in some cases outperforming, methods which assume access to source data. Our method achieves an improvement in mIoU of up to 12% over competing baselines. Our code is publicly available at https://github.com/csimo005/SUMMIT.
Efficient Controllable Multi-Task Architectures
Aug 22, 2023



We aim to train a multi-task model such that users can adjust the desired compute budget and relative importance of task performances after deployment, without retraining. This enables optimizing performance for dynamically varying user needs, without heavy computational overhead to train and save models for various scenarios. To this end, we propose a multi-task model consisting of a shared encoder and task-specific decoders where both encoder and decoder channel widths are slimmable. Our key idea is to control the task importance by varying the capacities of task-specific decoders, while controlling the total computational cost by jointly adjusting the encoder capacity. This improves overall accuracy by allowing a stronger encoder for a given budget, increases control over computational cost, and delivers high-quality slimmed sub-architectures based on user's constraints. Our training strategy involves a novel 'Configuration-Invariant Knowledge Distillation' loss that enforces backbone representations to be invariant under different runtime width configurations to enhance accuracy. Further, we present a simple but effective search algorithm that translates user constraints to runtime width configurations of both the shared encoder and task decoders, for sampling the sub-architectures. The key rule for the search algorithm is to provide a larger computational budget to the higher preferred task decoder, while searching a shared encoder configuration that enhances the overall MTL performance. Various experiments on three multi-task benchmarks (PASCALContext, NYUDv2, and CIFAR100-MTL) with diverse backbone architectures demonstrate the advantage of our approach. For example, our method shows a higher controllability by ~33.5% in the NYUD-v2 dataset over prior methods, while incurring much less compute cost.
FedYolo: Augmenting Federated Learning with Pretrained Transformers
Jul 10, 2023



The growth and diversity of machine learning applications motivate a rethinking of learning with mobile and edge devices. How can we address diverse client goals and learn with scarce heterogeneous data? While federated learning aims to address these issues, it has challenges hindering a unified solution. Large transformer models have been shown to work across a variety of tasks achieving remarkable few-shot adaptation. This raises the question: Can clients use a single general-purpose model, rather than custom models for each task, while obeying device and network constraints? In this work, we investigate pretrained transformers (PTF) to achieve these on-device learning goals and thoroughly explore the roles of model size and modularity, where the latter refers to adaptation through modules such as prompts or adapters. Focusing on federated learning, we demonstrate that: (1) Larger scale shrinks the accuracy gaps between alternative approaches and improves heterogeneity robustness. Scale allows clients to run more local SGD epochs which can significantly reduce the number of communication rounds. At the extreme, clients can achieve respectable accuracy locally highlighting the potential of fully-local learning. (2) Modularity, by design, enables $>$100$\times$ less communication in bits. Surprisingly, it also boosts the generalization capability of local adaptation methods and the robustness of smaller PTFs. Finally, it enables clients to solve multiple unrelated tasks simultaneously using a single PTF, whereas full updates are prone to catastrophic forgetting. These insights on scale and modularity motivate a new federated learning approach we call "You Only Load Once" (FedYolo): The clients load a full PTF model once and all future updates are accomplished through communication-efficient modules with limited catastrophic-forgetting, where each task is assigned to its own module.
Collaborative Multi-Agent Video Fast-Forwarding
May 27, 2023Multi-agent applications have recently gained significant popularity. In many computer vision tasks, a network of agents, such as a team of robots with cameras, could work collaboratively to perceive the environment for efficient and accurate situation awareness. However, these agents often have limited computation, communication, and storage resources. Thus, reducing resource consumption while still providing an accurate perception of the environment becomes an important goal when deploying multi-agent systems. To achieve this goal, we identify and leverage the overlap among different camera views in multi-agent systems for reducing the processing, transmission and storage of redundant/unimportant video frames. Specifically, we have developed two collaborative multi-agent video fast-forwarding frameworks in distributed and centralized settings, respectively. In these frameworks, each individual agent can selectively process or skip video frames at adjustable paces based on multiple strategies via reinforcement learning. Multiple agents then collaboratively sense the environment via either 1) a consensus-based distributed framework called DMVF that periodically updates the fast-forwarding strategies of agents by establishing communication and consensus among connected neighbors, or 2) a centralized framework called MFFNet that utilizes a central controller to decide the fast-forwarding strategies for agents based on collected data. We demonstrate the efficacy and efficiency of our proposed frameworks on a real-world surveillance video dataset VideoWeb and a new simulated driving dataset CarlaSim, through extensive simulations and deployment on an embedded platform with TCP communication. We show that compared with other approaches in the literature, our frameworks achieve better coverage of important frames, while significantly reducing the number of frames processed at each agent.
Cross-Domain Video Anomaly Detection without Target Domain Adaptation
Dec 14, 2022Most cross-domain unsupervised Video Anomaly Detection (VAD) works assume that at least few task-relevant target domain training data are available for adaptation from the source to the target domain. However, this requires laborious model-tuning by the end-user who may prefer to have a system that works ``out-of-the-box." To address such practical scenarios, we identify a novel target domain (inference-time) VAD task where no target domain training data are available. To this end, we propose a new `Zero-shot Cross-domain Video Anomaly Detection (zxvad)' framework that includes a future-frame prediction generative model setup. Different from prior future-frame prediction models, our model uses a novel Normalcy Classifier module to learn the features of normal event videos by learning how such features are different ``relatively" to features in pseudo-abnormal examples. A novel Untrained Convolutional Neural Network based Anomaly Synthesis module crafts these pseudo-abnormal examples by adding foreign objects in normal video frames with no extra training cost. With our novel relative normalcy feature learning strategy, zxvad generalizes and learns to distinguish between normal and abnormal frames in a new target domain without adaptation during inference. Through evaluations on common datasets, we show that zxvad outperforms the state-of-the-art (SOTA), regardless of whether task-relevant (i.e., VAD) source training data are available or not. Lastly, zxvad also beats the SOTA methods in inference-time efficiency metrics including the model size, total parameters, GPU energy consumption, and GMACs.
AVLEN: Audio-Visual-Language Embodied Navigation in 3D Environments
Oct 14, 2022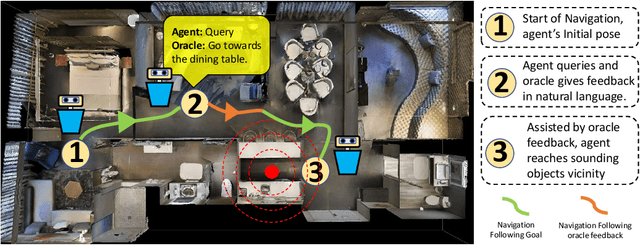
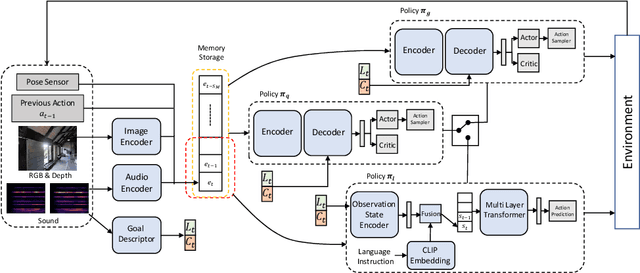
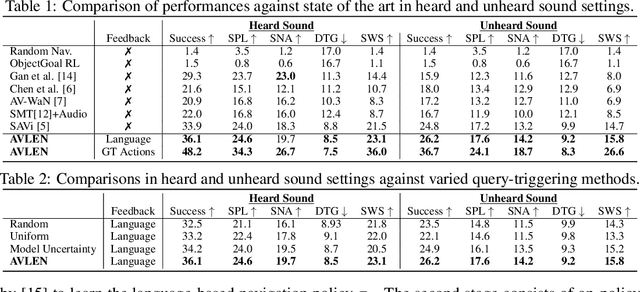

Recent years have seen embodied visual navigation advance in two distinct directions: (i) in equipping the AI agent to follow natural language instructions, and (ii) in making the navigable world multimodal, e.g., audio-visual navigation. However, the real world is not only multimodal, but also often complex, and thus in spite of these advances, agents still need to understand the uncertainty in their actions and seek instructions to navigate. To this end, we present AVLEN~ -- an interactive agent for Audio-Visual-Language Embodied Navigation. Similar to audio-visual navigation tasks, the goal of our embodied agent is to localize an audio event via navigating the 3D visual world; however, the agent may also seek help from a human (oracle), where the assistance is provided in free-form natural language. To realize these abilities, AVLEN uses a multimodal hierarchical reinforcement learning backbone that learns: (a) high-level policies to choose either audio-cues for navigation or to query the oracle, and (b) lower-level policies to select navigation actions based on its audio-visual and language inputs. The policies are trained via rewarding for the success on the navigation task while minimizing the number of queries to the oracle. To empirically evaluate AVLEN, we present experiments on the SoundSpaces framework for semantic audio-visual navigation tasks. Our results show that equipping the agent to ask for help leads to a clear improvement in performance, especially in challenging cases, e.g., when the sound is unheard during training or in the presence of distractor sounds.
Centroid Distance Keypoint Detector for Colored Point Clouds
Oct 04, 2022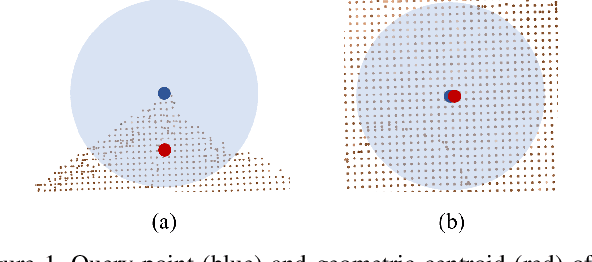
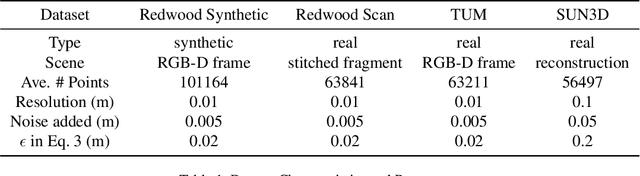
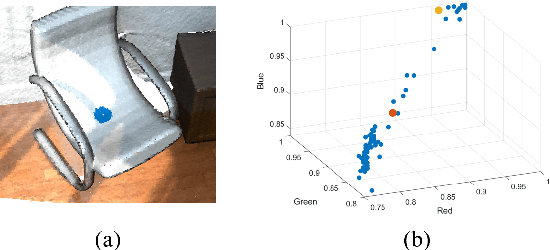
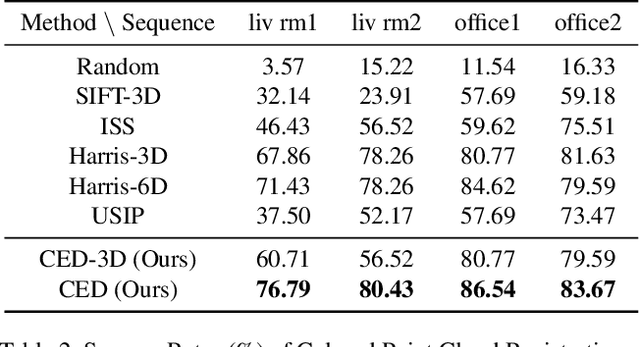
Keypoint detection serves as the basis for many computer vision and robotics applications. Despite the fact that colored point clouds can be readily obtained, most existing keypoint detectors extract only geometry-salient keypoints, which can impede the overall performance of systems that intend to (or have the potential to) leverage color information. To promote advances in such systems, we propose an efficient multi-modal keypoint detector that can extract both geometry-salient and color-salient keypoints in colored point clouds. The proposed CEntroid Distance (CED) keypoint detector comprises an intuitive and effective saliency measure, the centroid distance, that can be used in both 3D space and color space, and a multi-modal non-maximum suppression algorithm that can select keypoints with high saliency in two or more modalities. The proposed saliency measure leverages directly the distribution of points in a local neighborhood and does not require normal estimation or eigenvalue decomposition. We evaluate the proposed method in terms of repeatability and computational efficiency (i.e. running time) against state-of-the-art keypoint detectors on both synthetic and real-world datasets. Results demonstrate that our proposed CED keypoint detector requires minimal computational time while attaining high repeatability. To showcase one of the potential applications of the proposed method, we further investigate the task of colored point cloud registration. Results suggest that our proposed CED detector outperforms state-of-the-art handcrafted and learning-based keypoint detectors in the evaluated scenes. The C++ implementation of the proposed method is made publicly available at https://github.com/UCR-Robotics/CED_Detector.
Leveraging Local Patch Differences in Multi-Object Scenes for Generative Adversarial Attacks
Oct 03, 2022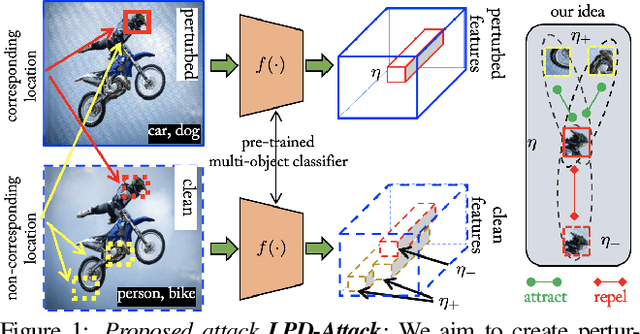

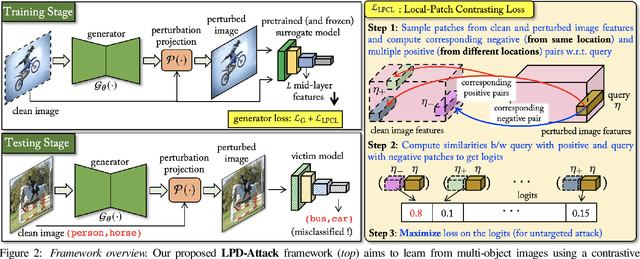
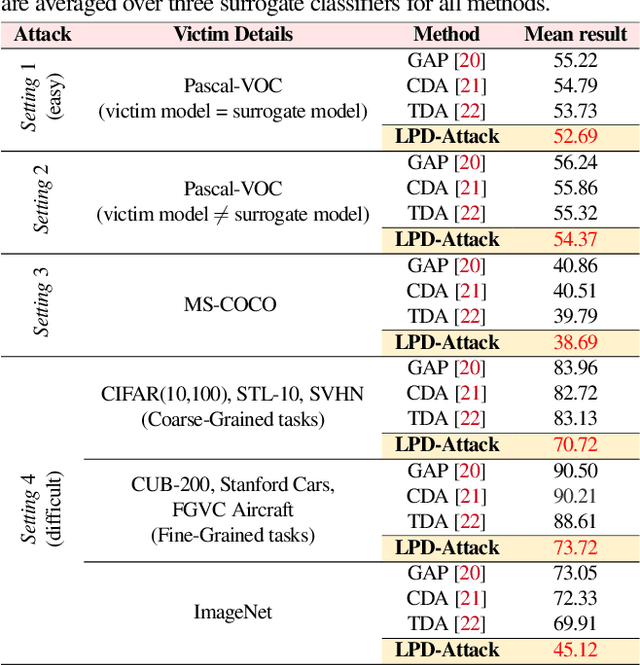
State-of-the-art generative model-based attacks against image classifiers overwhelmingly focus on single-object (i.e., single dominant object) images. Different from such settings, we tackle a more practical problem of generating adversarial perturbations using multi-object (i.e., multiple dominant objects) images as they are representative of most real-world scenes. Our goal is to design an attack strategy that can learn from such natural scenes by leveraging the local patch differences that occur inherently in such images (e.g. difference between the local patch on the object `person' and the object `bike' in a traffic scene). Our key idea is to misclassify an adversarial multi-object image by confusing the victim classifier for each local patch in the image. Based on this, we propose a novel generative attack (called Local Patch Difference or LPD-Attack) where a novel contrastive loss function uses the aforesaid local differences in feature space of multi-object scenes to optimize the perturbation generator. Through various experiments across diverse victim convolutional neural networks, we show that our approach outperforms baseline generative attacks with highly transferable perturbations when evaluated under different white-box and black-box settings.