 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnecting Algorithmic Research and Usage Contexts: A Perspective of Contextualized Evaluation for Explainable AI
Jun 22, 2022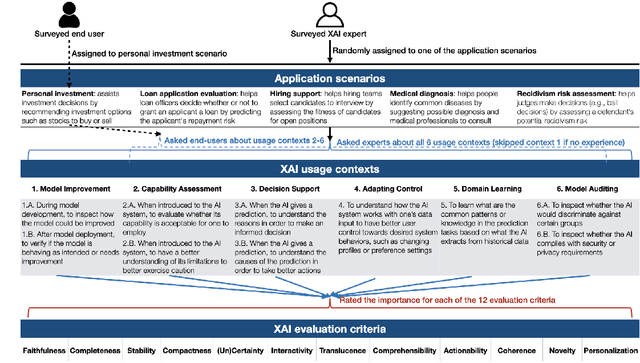
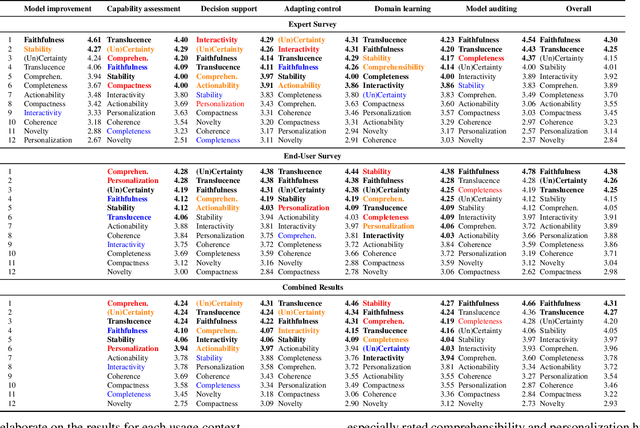

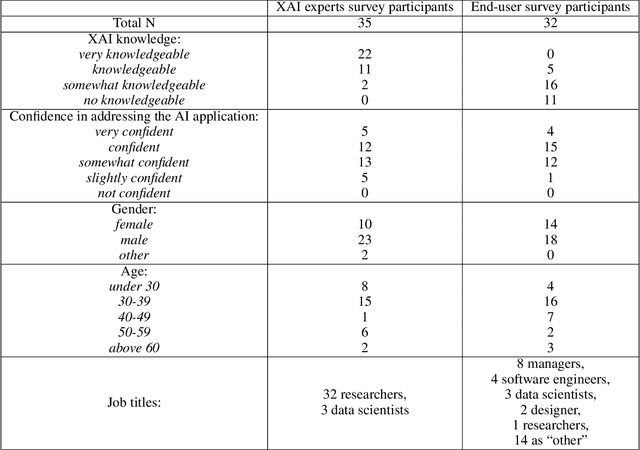
Recent years have seen a surge of interest in the field of explainable AI (XAI), with a plethora of algorithms proposed in the literature. However, a lack of consensus on how to evaluate XAI hinders the advancement of the field. We highlight that XAI is not a monolithic set of technologies -- researchers and practitioners have begun to leverage XAI algorithms to build XAI systems that serve different usage contexts, such as model debugging and decision-support. Algorithmic research of XAI, however, often does not account for these diverse downstream usage contexts, resulting in limited effectiveness or even unintended consequences for actual users, as well as difficulties for practitioners to make technical choices. We argue that one way to close the gap is to develop evaluation methods that account for different user requirements in these usage contexts. Towards this goal, we introduce a perspective of contextualized XAI evaluation by considering the relative importance of XAI evaluation criteria for prototypical usage contexts of XAI. To explore the context-dependency of XAI evaluation criteria, we conduct two survey studies, one with XAI topical experts and another with crowd workers. Our results urge for responsible AI research with usage-informed evaluation practices, and provide a nuanced understanding of user requirements for XAI in different usage contexts.
Local Explanations for Reinforcement Learning
Feb 08, 2022Many works in explainable AI have focused on explaining black-box classification models. Explaining deep reinforcement learning (RL) policies in a manner that could be understood by domain users has received much less attention. In this paper, we propose a novel perspective to understanding RL policies based on identifying important states from automatically learned meta-states. The key conceptual difference between our approach and many previous ones is that we form meta-states based on locality governed by the expert policy dynamics rather than based on similarity of actions, and that we do not assume any particular knowledge of the underlying topology of the state space. Theoretically, we show that our algorithm to find meta-states converges and the objective that selects important states from each meta-state is submodular leading to efficient high quality greedy selection. Experiments on four domains (four rooms, door-key, minipacman, and pong) and a carefully conducted user study illustrate that our perspective leads to better understanding of the policy. We conjecture that this is a result of our meta-states being more intuitive in that the corresponding important states are strong indicators of tractable intermediate goals that are easier for humans to interpret and follow.
Auto-Transfer: Learning to Route Transferrable Representations
Feb 04, 2022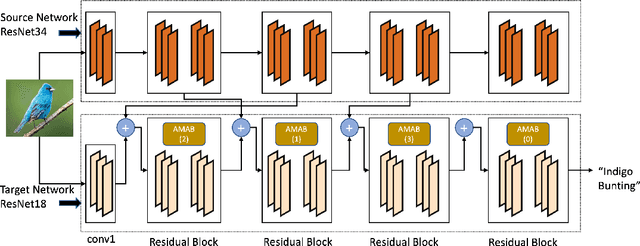
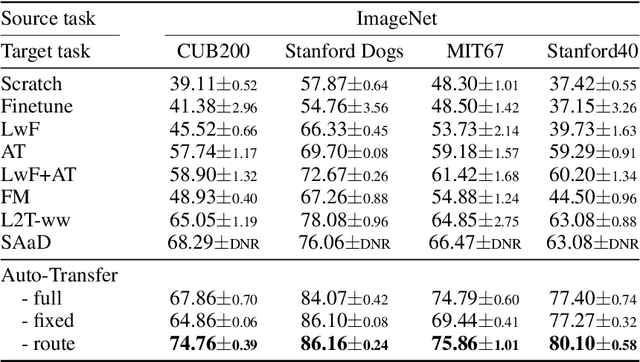
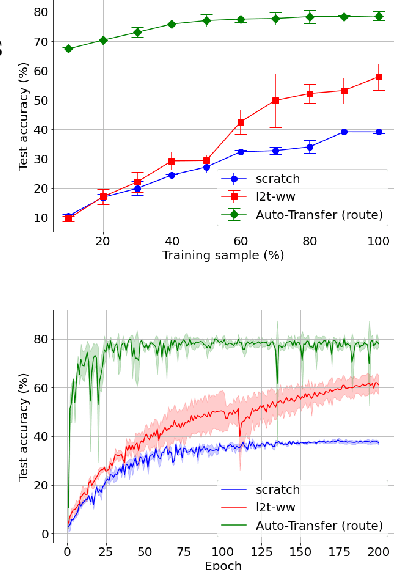

Knowledge transfer between heterogeneous source and target networks and tasks has received a lot of attention in recent times as large amounts of quality labelled data can be difficult to obtain in many applications. Existing approaches typically constrain the target deep neural network (DNN) feature representations to be close to the source DNNs feature representations, which can be limiting. We, in this paper, propose a novel adversarial multi-armed bandit approach which automatically learns to route source representations to appropriate target representations following which they are combined in meaningful ways to produce accurate target models. We see upwards of 5% accuracy improvements compared with the state-of-the-art knowledge transfer methods on four benchmark (target) image datasets CUB200, Stanford Dogs, MIT67, and Stanford40 where the source dataset is ImageNet. We qualitatively analyze the goodness of our transfer scheme by showing individual examples of the important features our target network focuses on in different layers compared with the (closest) competitors. We also observe that our improvement over other methods is higher for smaller target datasets making it an effective tool for small data applications that may benefit from transfer learning.
Analogies and Feature Attributions for Model Agnostic Explanation of Similarity Learners
Feb 02, 2022

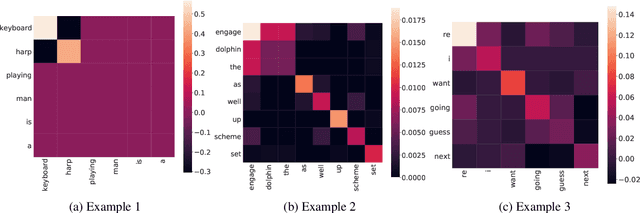

Post-hoc explanations for black box models have been studied extensively in classification and regression settings. However, explanations for models that output similarity between two inputs have received comparatively lesser attention. In this paper, we provide model agnostic local explanations for similarity learners applicable to tabular and text data. We first propose a method that provides feature attributions to explain the similarity between a pair of inputs as determined by a black box similarity learner. We then propose analogies as a new form of explanation in machine learning. Here the goal is to identify diverse analogous pairs of examples that share the same level of similarity as the input pair and provide insight into (latent) factors underlying the model's prediction. The selection of analogies can optionally leverage feature attributions, thus connecting the two forms of explanation while still maintaining complementarity. We prove that our analogy objective function is submodular, making the search for good-quality analogies efficient. We apply the proposed approaches to explain similarities between sentences as predicted by a state-of-the-art sentence encoder, and between patients in a healthcare utilization application. Efficacy is measured through quantitative evaluations, a careful user study, and examples of explanations.
Locally Invariant Explanations: Towards Stable and Unidirectional Explanations through Local Invariant Learning
Jan 28, 2022Locally interpretable model agnostic explanations (LIME) method is one of the most popular methods used to explain black-box models at a per example level. Although many variants have been proposed, few provide a simple way to produce high fidelity explanations that are also stable and intuitive. In this work, we provide a novel perspective by proposing a model agnostic local explanation method inspired by the invariant risk minimization (IRM) principle -- originally proposed for (global) out-of-distribution generalization -- to provide such high fidelity explanations that are also stable and unidirectional across nearby examples. Our method is based on a game theoretic formulation where we theoretically show that our approach has a strong tendency to eliminate features where the gradient of the black-box function abruptly changes sign in the locality of the example we want to explain, while in other cases it is more careful and will choose a more conservative (feature) attribution, a behavior which can be highly desirable for recourse. Empirically, we show on tabular, image and text data that the quality of our explanations with neighborhoods formed using random perturbations are much better than LIME and in some cases even comparable to other methods that use realistic neighbors sampled from the data manifold. This is desirable given that learning a manifold to either create realistic neighbors or to project explanations is typically expensive or may even be impossible. Moreover, our algorithm is simple and efficient to train, and can ascertain stable input features for local decisions of a black-box without access to side information such as a (partial) causal graph as has been seen in some recent works.
AI Explainability 360: Impact and Design
Sep 24, 2021
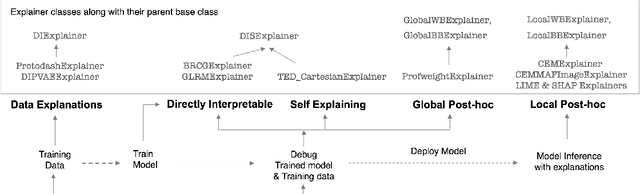

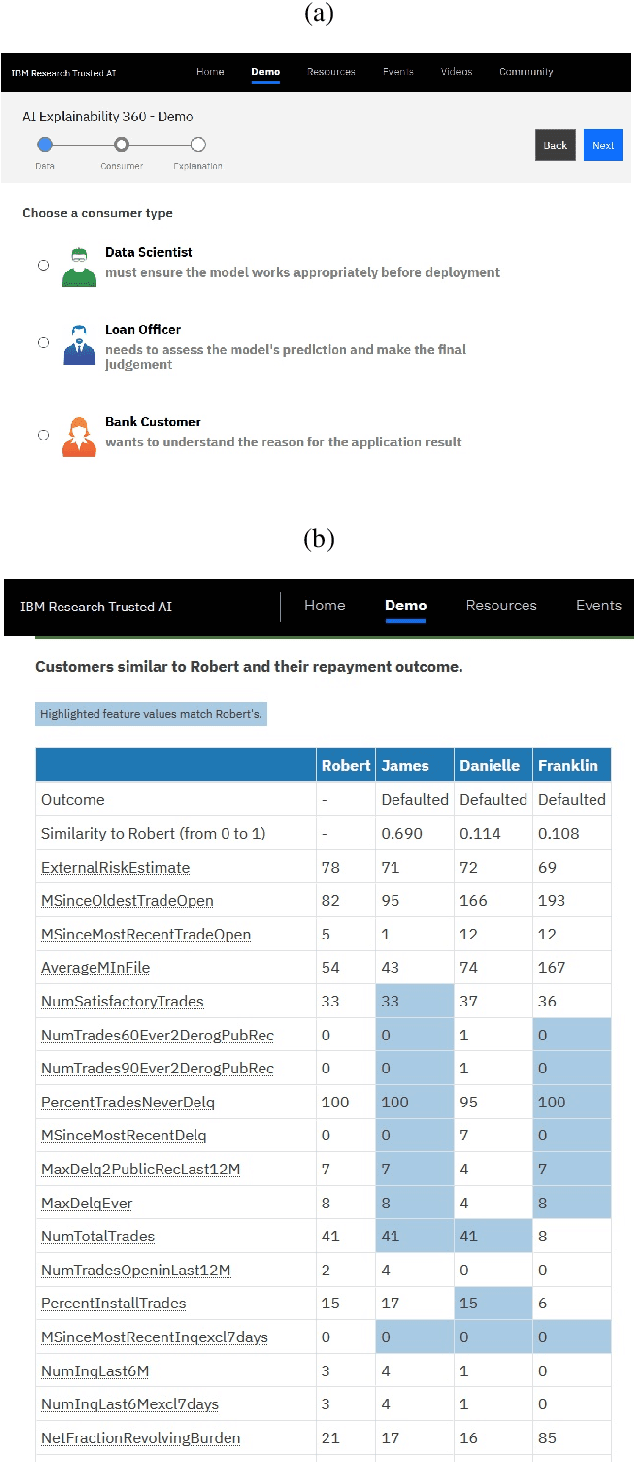
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.
Let the CAT out of the bag: Contrastive Attributed explanations for Text
Sep 16, 2021
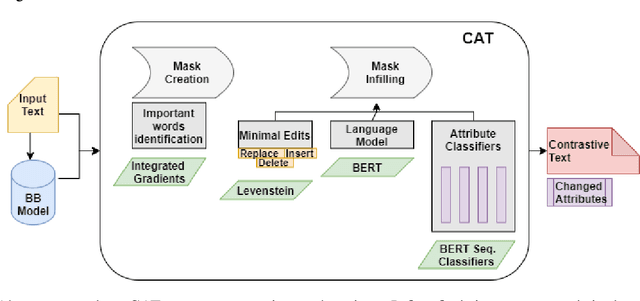
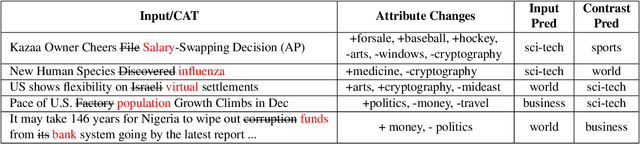
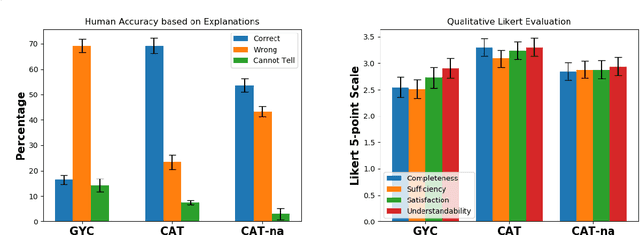
Contrastive explanations for understanding the behavior of black box models has gained a lot of attention recently as they provide potential for recourse. In this paper, we propose a method Contrastive Attributed explanations for Text (CAT) which provides contrastive explanations for natural language text data with a novel twist as we build and exploit attribute classifiers leading to more semantically meaningful explanations. To ensure that our contrastive generated text has the fewest possible edits with respect to the original text, while also being fluent and close to a human generated contrastive, we resort to a minimal perturbation approach regularized using a BERT language model and attribute classifiers trained on available attributes. We show through qualitative examples and a user study that our method not only conveys more insight because of these attributes, but also leads to better quality (contrastive) text. Moreover, quantitatively we show that our method is more efficient than other state-of-the-art methods with it also scoring higher on benchmark metrics such as flip rate, (normalized) Levenstein distance, fluency and content preservation.
Building Accurate Simple Models with Multihop
Sep 14, 2021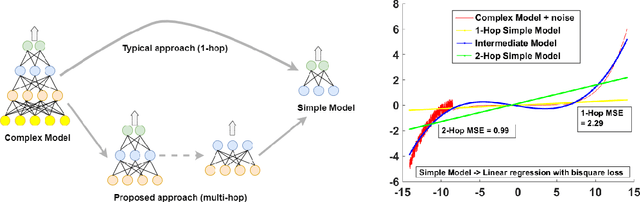
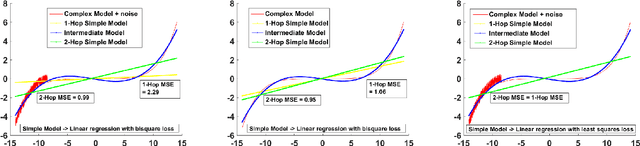
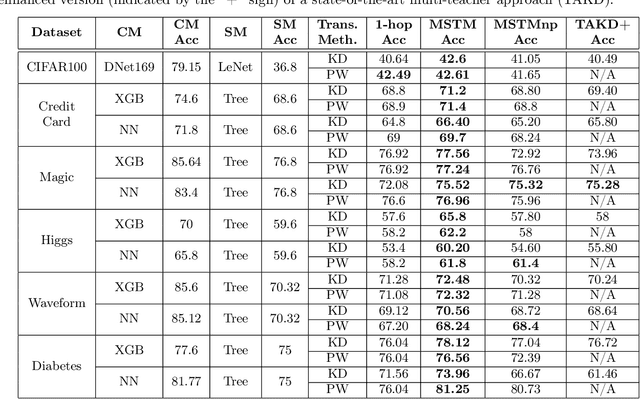
Knowledge transfer from a complex high performing model to a simpler and potentially low performing one in order to enhance its performance has been of great interest over the last few years as it finds applications in important problems such as explainable artificial intelligence, model compression, robust model building and learning from small data. Known approaches to this problem (viz. Knowledge Distillation, Model compression, ProfWeight, etc.) typically transfer information directly (i.e. in a single/one hop) from the complex model to the chosen simple model through schemes that modify the target or reweight training examples on which the simple model is trained. In this paper, we propose a meta-approach where we transfer information from the complex model to the simple model by dynamically selecting and/or constructing a sequence of intermediate models of decreasing complexity that are less intricate than the original complex model. Our approach can transfer information between consecutive models in the sequence using any of the previously mentioned approaches as well as work in 1-hop fashion, thus generalizing these approaches. In the experiments on real data, we observe that we get consistent gains for different choices of models over 1-hop, which on average is more than 2\% and reaches up to 8\% in a particular case. We also empirically analyze conditions under which the multi-hop approach is likely to be beneficial over the traditional 1-hop approach, and report other interesting insights. To the best of our knowledge, this is the first work that proposes such a multi-hop approach to perform knowledge transfer given a single high performing complex model, making it in our opinion, an important methodological contribution.
Towards Better Model Understanding with Path-Sufficient Explanations
Sep 13, 2021

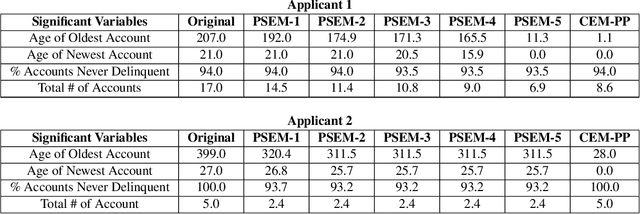

Feature based local attribution methods are amongst the most prevalent in explainable artificial intelligence (XAI) literature. Going beyond standard correlation, recently, methods have been proposed that highlight what should be minimally sufficient to justify the classification of an input (viz. pertinent positives). While minimal sufficiency is an attractive property, the resulting explanations are often too sparse for a human to understand and evaluate the local behavior of the model, thus making it difficult to judge its overall quality. To overcome these limitations, we propose a novel method called Path-Sufficient Explanations Method (PSEM) that outputs a sequence of sufficient explanations for a given input of strictly decreasing size (or value) -- from original input to a minimally sufficient explanation -- which can be thought to trace the local boundary of the model in a smooth manner, thus providing better intuition about the local model behavior for the specific input. We validate these claims, both qualitatively and quantitatively, with experiments that show the benefit of PSEM across all three modalities (image, tabular and text). A user study depicts the strength of the method in communicating the local behavior, where (many) users are able to correctly determine the prediction made by a model.
Treatment Effect Estimation using Invariant Risk Minimization
Mar 13, 2021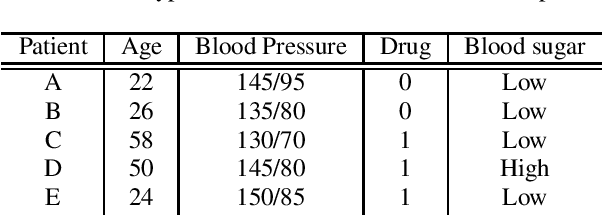
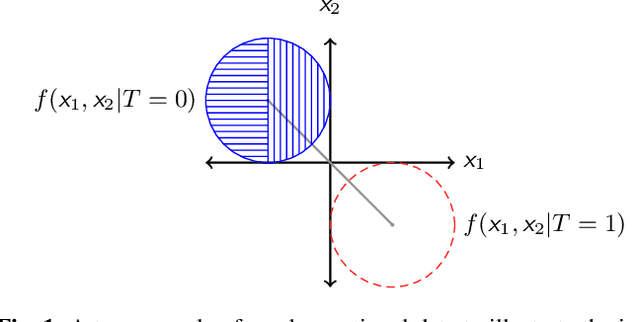
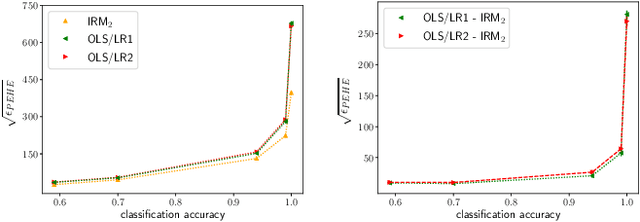
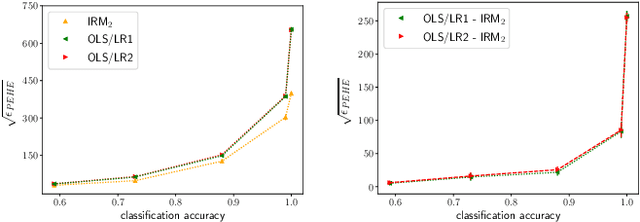
Inferring causal individual treatment effect (ITE) from observational data is a challenging problem whose difficulty is exacerbated by the presence of treatment assignment bias. In this work, we propose a new way to estimate the ITE using the domain generalization framework of invariant risk minimization (IRM). IRM uses data from multiple domains, learns predictors that do not exploit spurious domain-dependent factors, and generalizes better to unseen domains. We propose an IRM-based ITE estimator aimed at tackling treatment assignment bias when there is little support overlap between the control group and the treatment group. We accomplish this by creating diversity: given a single dataset, we split the data into multiple domains artificially. These diverse domains are then exploited by IRM to more effectively generalize regression-based models to data regions that lack support overlap. We show gains over classical regression approaches to ITE estimation in settings when support mismatch is more pronounced.