 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig Little Transformer Decoder
Feb 15, 2023The recent emergence of Large Language Models based on the Transformer architecture has enabled dramatic advancements in the field of Natural Language Processing. However, these models have long inference latency, which limits their deployment, and which makes them prohibitively expensive for various real-time applications. The inference latency is further exacerbated by autoregressive generative tasks, as models need to run iteratively to generate tokens sequentially without leveraging token-level parallelization. To address this, we propose Big Little Decoder (BiLD), a framework that can improve inference efficiency and latency for a wide range of text generation applications. The BiLD framework contains two models with different sizes that collaboratively generate text. The small model runs autoregressively to generate text with a low inference cost, and the large model is only invoked occasionally to refine the small model's inaccurate predictions in a non-autoregressive manner. To coordinate the small and large models, BiLD introduces two simple yet effective policies: (1) the fallback policy that determines when to hand control over to the large model; and (2) the rollback policy that determines when the large model needs to review and correct the small model's inaccurate predictions. To evaluate our framework across different tasks and models, we apply BiLD to various text generation scenarios encompassing machine translation on IWSLT 2017 De-En and WMT 2014 De-En, summarization on CNN/DailyMail, and language modeling on WikiText-2. On an NVIDIA Titan Xp GPU, our framework achieves a speedup of up to 2.13x without any performance drop, and it achieves up to 2.38x speedup with only ~1 point degradation. Furthermore, our framework is fully plug-and-play as it does not require any training or modifications to model architectures. Our code will be open-sourced.
Adaptive Self-supervision Algorithms for Physics-informed Neural Networks
Jul 08, 2022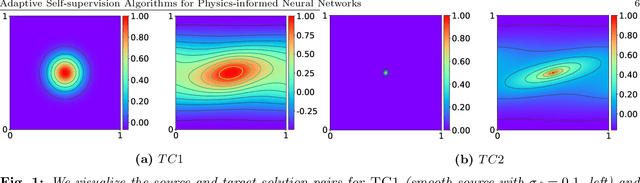

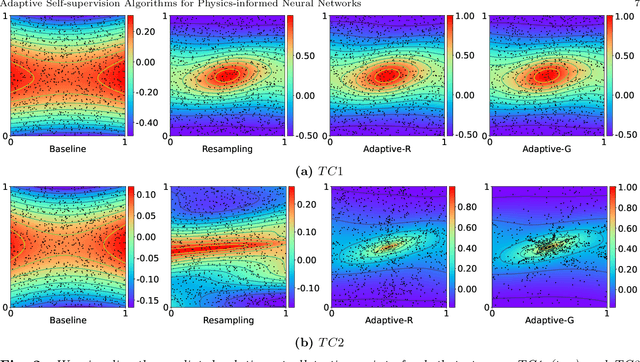

Physics-informed neural networks (PINNs) incorporate physical knowledge from the problem domain as a soft constraint on the loss function, but recent work has shown that this can lead to optimization difficulties. Here, we study the impact of the location of the collocation points on the trainability of these models. We find that the vanilla PINN performance can be significantly boosted by adapting the location of the collocation points as training proceeds. Specifically, we propose a novel adaptive collocation scheme which progressively allocates more collocation points (without increasing their number) to areas where the model is making higher errors (based on the gradient of the loss function in the domain). This, coupled with a judicious restarting of the training during any optimization stalls (by simply resampling the collocation points in order to adjust the loss landscape) leads to better estimates for the prediction error. We present results for several problems, including a 2D Poisson and diffusion-advection system with different forcing functions. We find that training vanilla PINNs for these problems can result in up to 70% prediction error in the solution, especially in the regime of low collocation points. In contrast, our adaptive schemes can achieve up to an order of magnitude smaller error, with similar computational complexity as the baseline. Furthermore, we find that the adaptive methods consistently perform on-par or slightly better than vanilla PINN method, even for large collocation point regimes. The code for all the experiments has been open sourced.
Squeezeformer: An Efficient Transformer for Automatic Speech Recognition
Jun 02, 2022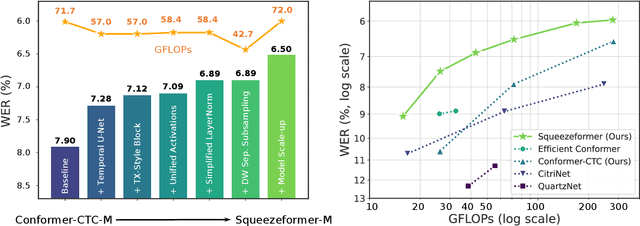
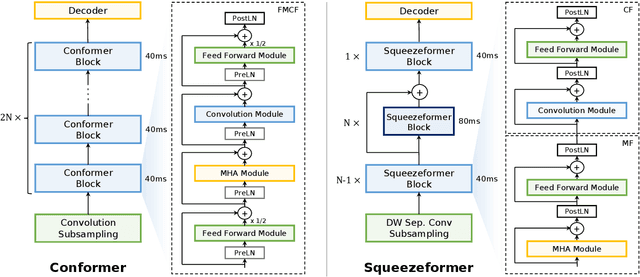
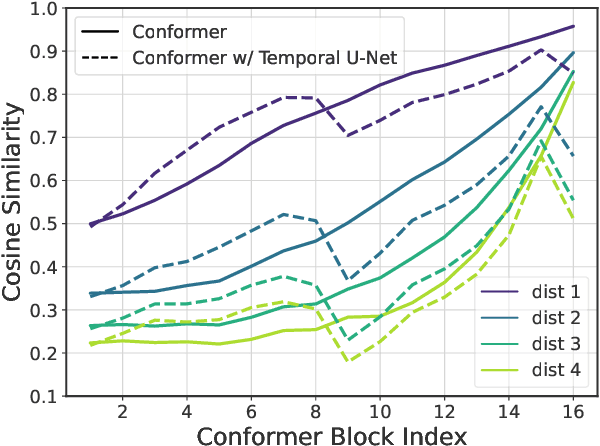
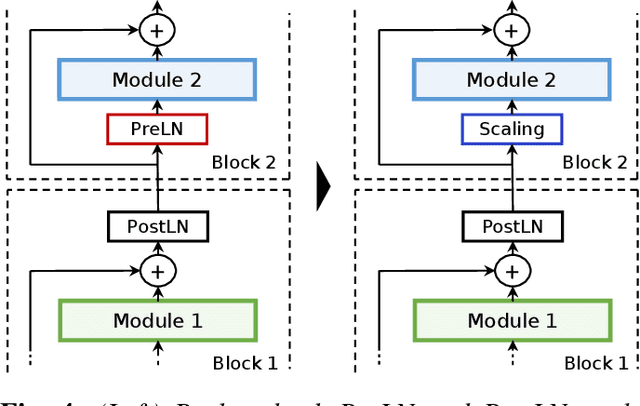
The recently proposed Conformer model has become the de facto backbone model for various downstream speech tasks based on its hybrid attention-convolution architecture that captures both local and global features. However, through a series of systematic studies, we find that the Conformer architecture's design choices are not optimal. After reexamining the design choices for both the macro and micro-architecture of Conformer, we propose the Squeezeformer model, which consistently outperforms the state-of-the-art ASR models under the same training schemes. In particular, for the macro-architecture, Squeezeformer incorporates (i) the Temporal U-Net structure, which reduces the cost of the multi-head attention modules on long sequences, and (ii) a simpler block structure of feed-forward module, followed up by multi-head attention or convolution modules, instead of the Macaron structure proposed in Conformer. Furthermore, for the micro-architecture, Squeezeformer (i) simplifies the activations in the convolutional block, (ii) removes redundant Layer Normalization operations, and (iii) incorporates an efficient depth-wise downsampling layer to efficiently sub-sample the input signal. Squeezeformer achieves state-of-the-art results of 7.5%, 6.5%, and 6.0% word-error-rate on Librispeech test-other without external language models. This is 3.1%, 1.4%, and 0.6% better than Conformer-CTC with the same number of FLOPs. Our code is open-sourced and available online.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021
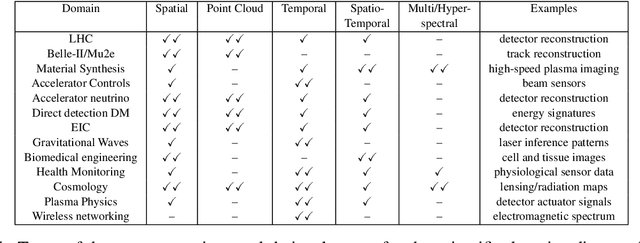
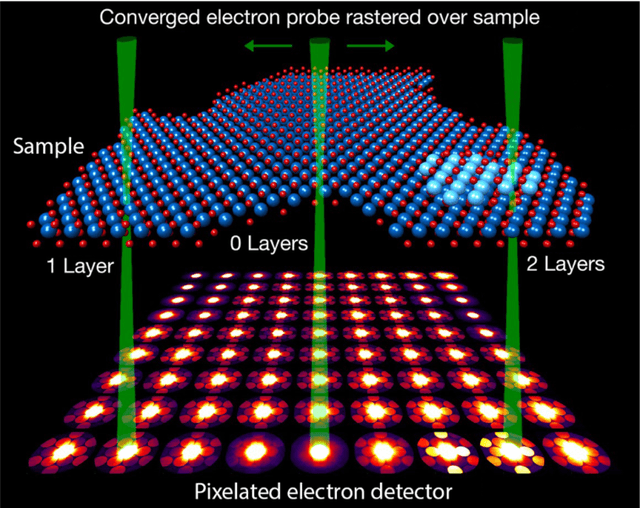
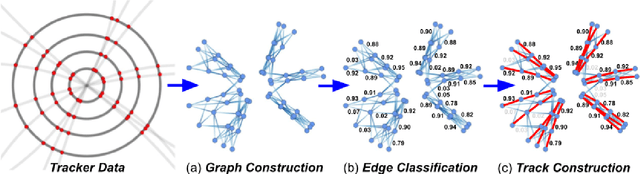
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
Characterizing possible failure modes in physics-informed neural networks
Sep 02, 2021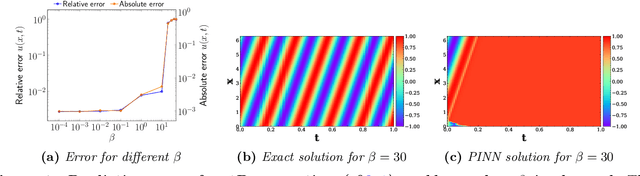
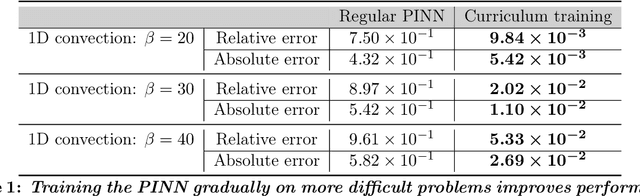
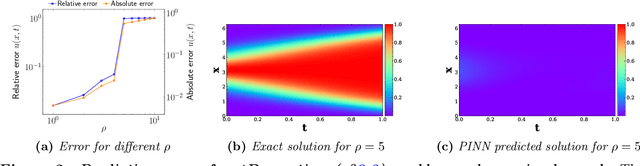
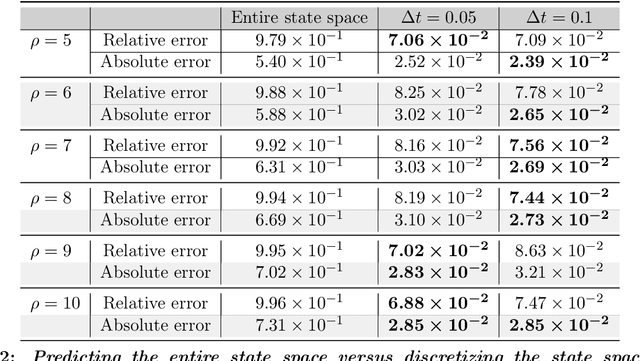
Recent work in scientific machine learning has developed so-called physics-informed neural network (PINN) models. The typical approach is to incorporate physical domain knowledge as soft constraints on an empirical loss function and use existing machine learning methodologies to train the model. We demonstrate that, while existing PINN methodologies can learn good models for relatively trivial problems, they can easily fail to learn relevant physical phenomena even for simple PDEs. In particular, we analyze several distinct situations of widespread physical interest, including learning differential equations with convection, reaction, and diffusion operators. We provide evidence that the soft regularization in PINNs, which involves differential operators, can introduce a number of subtle problems, including making the problem ill-conditioned. Importantly, we show that these possible failure modes are not due to the lack of expressivity in the NN architecture, but that the PINN's setup makes the loss landscape very hard to optimize. We then describe two promising solutions to address these failure modes. The first approach is to use curriculum regularization, where the PINN's loss term starts from a simple PDE regularization, and becomes progressively more complex as the NN gets trained. The second approach is to pose the problem as a sequence-to-sequence learning task, rather than learning to predict the entire space-time at once. Extensive testing shows that we can achieve up to 1-2 orders of magnitude lower error with these methods as compared to regular PINN training.
Learned Token Pruning for Transformers
Jul 02, 2021
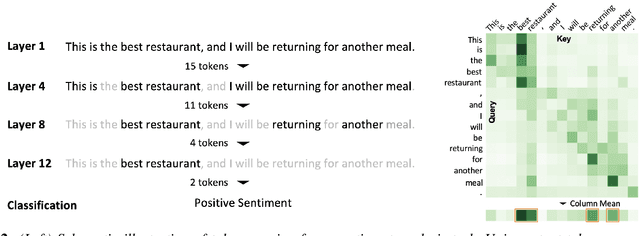
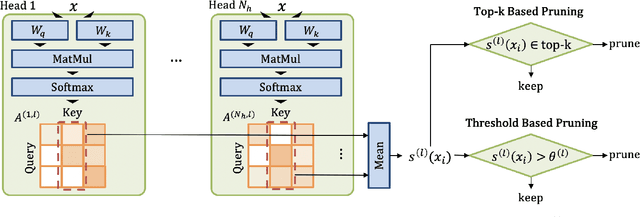
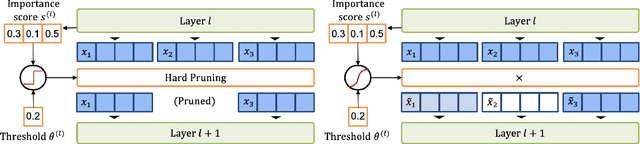
A major challenge in deploying transformer models is their prohibitive inference cost, which quadratically scales with the input sequence length. This makes it especially difficult to use transformers for processing long sequences. To address this, we present a novel Learned Token Pruning (LTP) method that reduces redundant tokens as the data passes through the different layers of the transformer. In particular, LTP prunes tokens with an attention score below a threshold value, which is learned during training. Importantly, our threshold based method avoids algorithmically expensive operations such as top-k token selection which are used in prior token pruning methods, and also leads to structured pruning. We extensively test the performance of our approach on multiple GLUE tasks and show that our learned threshold based method consistently outperforms the prior state-of-the-art top-k token based method by up to ~2% higher accuracy with the same amount of FLOPs. Furthermore, our preliminary results show up to 1.4x and 1.9x throughput improvement on Tesla T4 GPU and Intel Haswell CPU, respectively, with less than 1% of accuracy drop (and up to 2.1x FLOPs reduction). Our code has been developed in PyTorch and has been open-sourced.
Q-ASR: Integer-only Zero-shot Quantization for Efficient Speech Recognition
Mar 31, 2021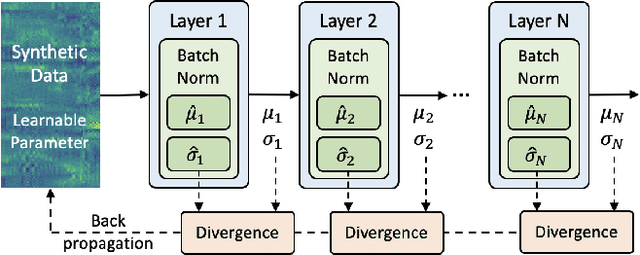
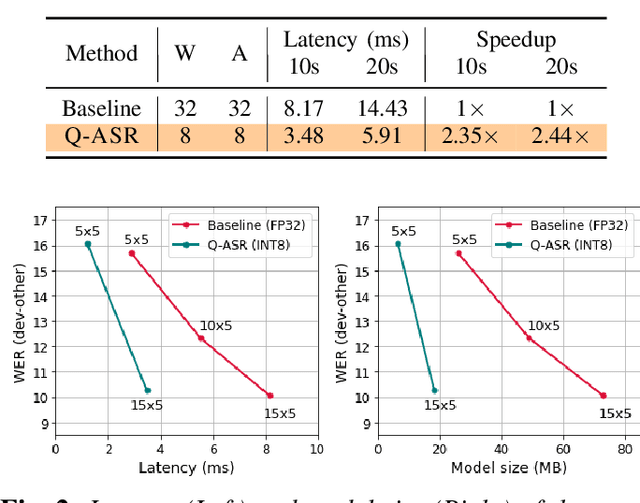
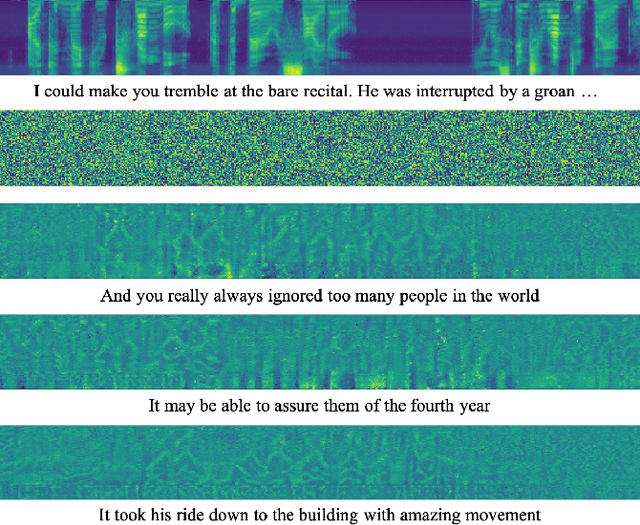
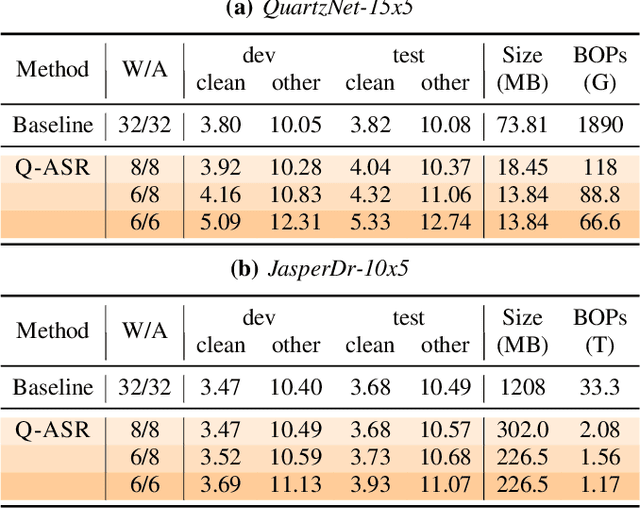
End-to-end neural network models achieve improved performance on various automatic speech recognition (ASR) tasks. However, these models perform poorly on edge hardware due to large memory and computation requirements. While quantizing model weights and/or activations to low-precision can be a promising solution, previous research on quantizing ASR models is limited. Most quantization approaches use floating-point arithmetic during inference; and thus they cannot fully exploit integer processing units, which use less power than their floating-point counterparts. Moreover, they require training/validation data during quantization for finetuning or calibration; however, this data may not be available due to security/privacy concerns. To address these limitations, we propose Q-ASR, an integer-only, zero-shot quantization scheme for ASR models. In particular, we generate synthetic data whose runtime statistics resemble the real data, and we use it to calibrate models during quantization. We then apply Q-ASR to quantize QuartzNet-15x5 and JasperDR-10x5 without any training data, and we show negligible WER change as compared to the full-precision baseline models. For INT8-only quantization, we observe a very modest WER degradation of up to 0.29%, while we achieve up to 2.44x speedup on a T4 GPU. Furthermore, Q-ASR exhibits a large compression rate of more than 4x with small WER degradation.
A Survey of Quantization Methods for Efficient Neural Network Inference
Mar 25, 2021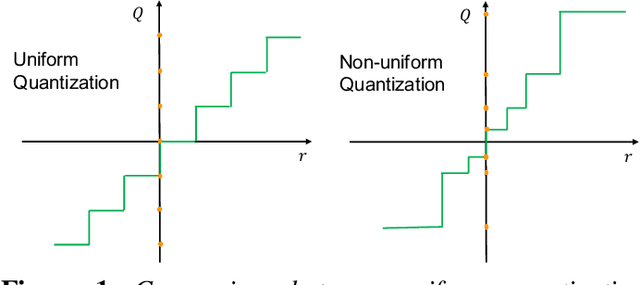
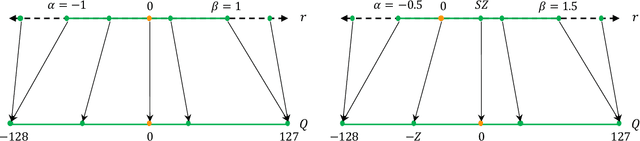
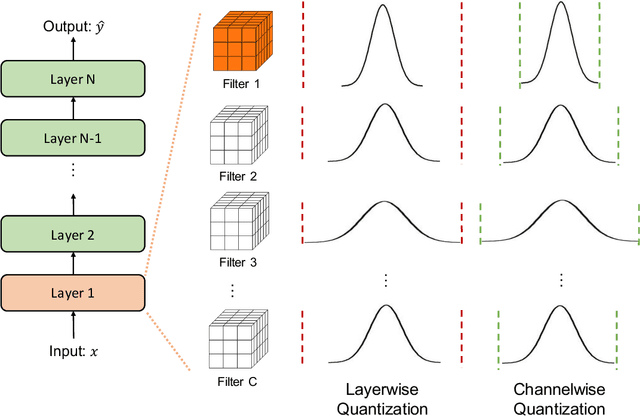
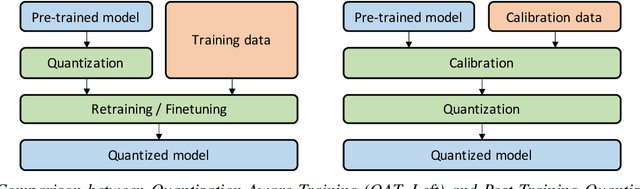
As soon as abstract mathematical computations were adapted to computation on digital computers, the problem of efficient representation, manipulation, and communication of the numerical values in those computations arose. Strongly related to the problem of numerical representation is the problem of quantization: in what manner should a set of continuous real-valued numbers be distributed over a fixed discrete set of numbers to minimize the number of bits required and also to maximize the accuracy of the attendant computations? This perennial problem of quantization is particularly relevant whenever memory and/or computational resources are severely restricted, and it has come to the forefront in recent years due to the remarkable performance of Neural Network models in computer vision, natural language processing, and related areas. Moving from floating-point representations to low-precision fixed integer values represented in four bits or less holds the potential to reduce the memory footprint and latency by a factor of 16x; and, in fact, reductions of 4x to 8x are often realized in practice in these applications. Thus, it is not surprising that quantization has emerged recently as an important and very active sub-area of research in the efficient implementation of computations associated with Neural Networks. In this article, we survey approaches to the problem of quantizing the numerical values in deep Neural Network computations, covering the advantages/disadvantages of current methods. With this survey and its organization, we hope to have presented a useful snapshot of the current research in quantization for Neural Networks and to have given an intelligent organization to ease the evaluation of future research in this area.
I-BERT: Integer-only BERT Quantization
Feb 11, 2021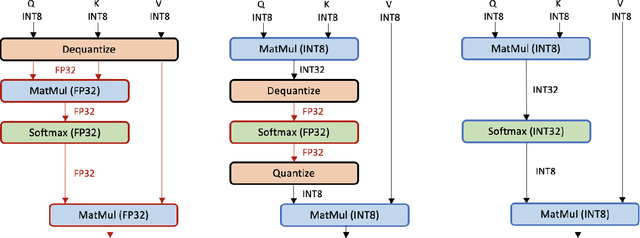
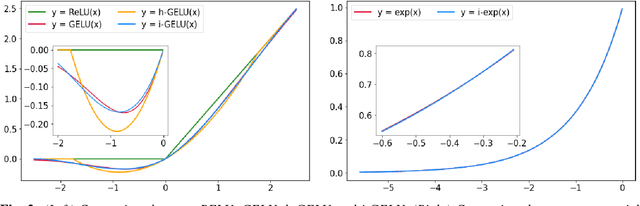
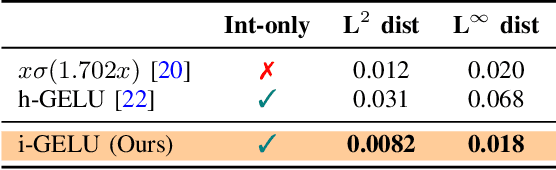
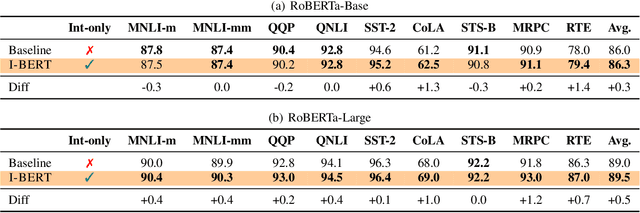
Transformer based models, like BERT and RoBERTa, have achieved state-of-the-art results in many Natural Language Processing tasks. However, their memory footprint, inference latency, and power consumption are prohibitive for efficient inference at the edge, and even at the data center. While quantization can be a viable solution for this, previous work on quantizing Transformer based models use floating-point arithmetic during inference, which cannot efficiently utilize integer-only logical units such as the recent Turing Tensor Cores, or traditional integer-only ARM processors. In this work, we propose I-BERT, a novel quantization scheme for Transformer based models that quantizes the entire inference with integer-only arithmetic. Based on lightweight integer-only approximation methods for nonlinear operations, e.g., GELU, Softmax, and Layer Normalization, I-BERT performs an end-to-end integer-only BERT inference without any floating point calculation. We evaluate our approach on GLUE downstream tasks using RoBERTa-Base/Large. We show that for both cases, I-BERT achieves similar (and slightly higher) accuracy as compared to the full-precision baseline. Furthermore, our preliminary implementation of I-BERT shows a speedup of 2.4 - 4.0x for INT8 inference on a T4 GPU system as compared to FP32 inference. The framework has been developed in PyTorch and has been open-sourced.
Hessian-Aware Pruning and Optimal Neural Implant
Feb 06, 2021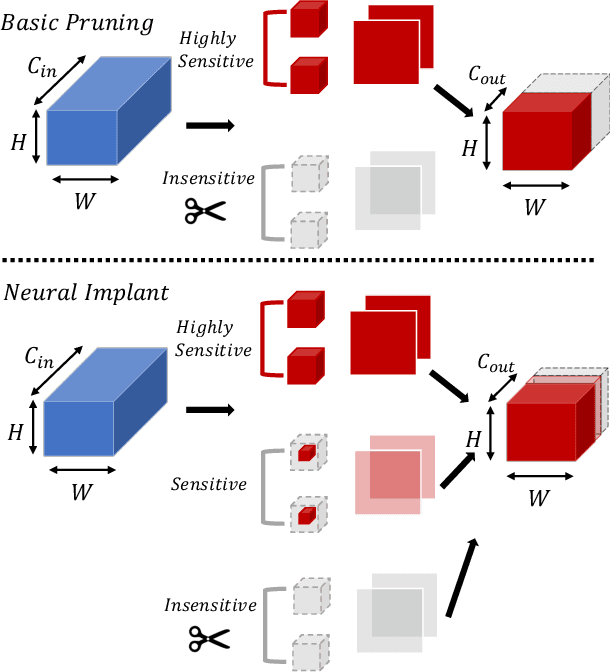
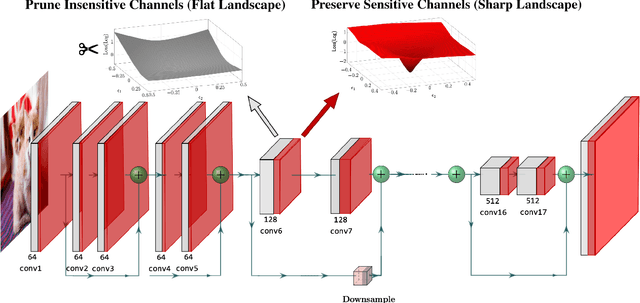
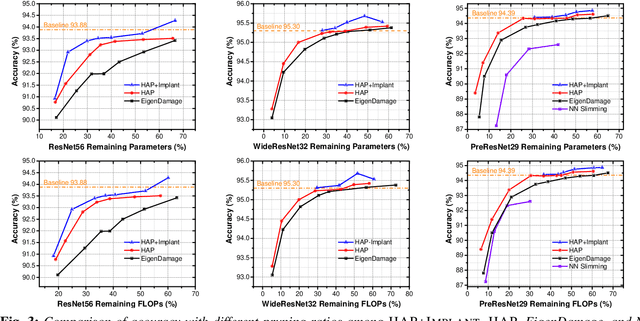
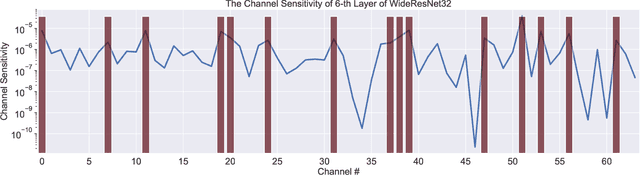
Pruning is an effective method to reduce the memory footprint and FLOPs associated with neural network models. However, existing structured-pruning methods often result in significant accuracy degradation for moderate pruning levels. To address this problem, we introduce a new Hessian Aware Pruning (HAP) method coupled with a Neural Implant approach that uses second-order sensitivity as a metric for structured pruning. The basic idea is to prune insensitive components and to use a Neural Implant for moderately sensitive components, instead of completely pruning them. For the latter approach, the moderately sensitive components are replaced with with a low rank implant that is smaller and less computationally expensive than the original component. We use the relative Hessian trace to measure sensitivity, as opposed to the magnitude based sensitivity metric commonly used in the literature. We test HAP on multiple models on CIFAR-10/ImageNet, and we achieve new state-of-the-art results. Specifically, HAP achieves 94.3\% accuracy ($<0.1\%$ degradation) on PreResNet29 (CIFAR-10), with more than 70\% of parameters pruned. Moreover, for ResNet50 HAP achieves 75.1\% top-1 accuracy (0.5\% degradation) on ImageNet, after pruning more than half of the parameters. The framework has been open sourced and available online.