 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Reuse in Pipeline-Aware Hyperparameter Tuning
Mar 12, 2019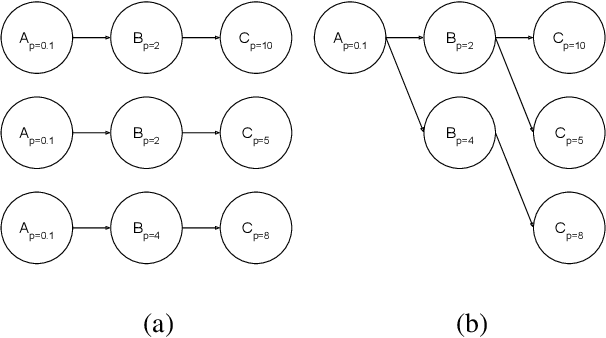
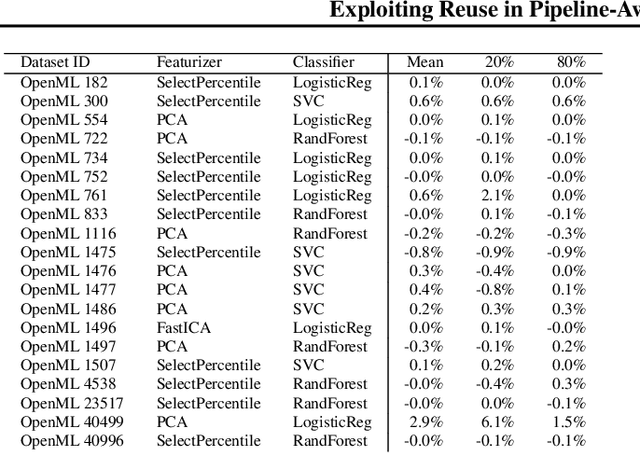
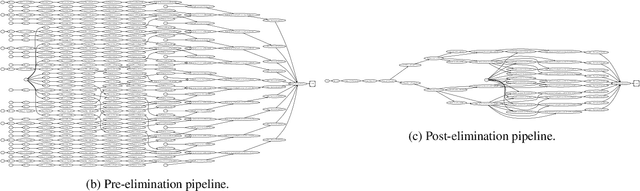
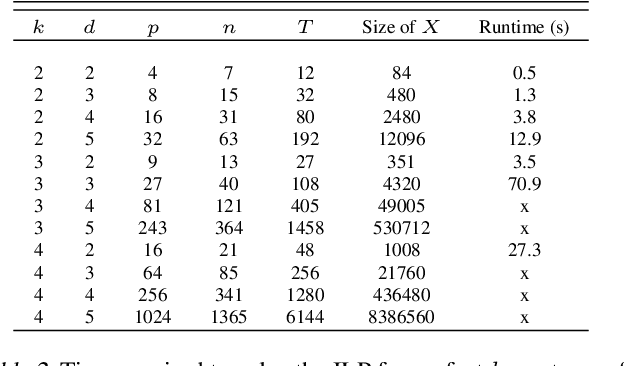
Hyperparameter tuning of multi-stage pipelines introduces a significant computational burden. Motivated by the observation that work can be reused across pipelines if the intermediate computations are the same, we propose a pipeline-aware approach to hyperparameter tuning. Our approach optimizes both the design and execution of pipelines to maximize reuse. We design pipelines amenable for reuse by (i) introducing a novel hybrid hyperparameter tuning method called gridded random search, and (ii) reducing the average training time in pipelines by adapting early-stopping hyperparameter tuning approaches. We then realize the potential for reuse during execution by introducing a novel caching problem for ML workloads which we pose as a mixed integer linear program (ILP), and subsequently evaluating various caching heuristics relative to the optimal solution of the ILP. We conduct experiments on simulated and real-world machine learning pipelines to show that a pipeline-aware approach to hyperparameter tuning can offer over an order-of-magnitude speedup over independently evaluating pipeline configurations.
One-Shot Federated Learning
Mar 05, 2019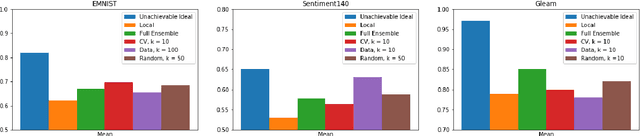

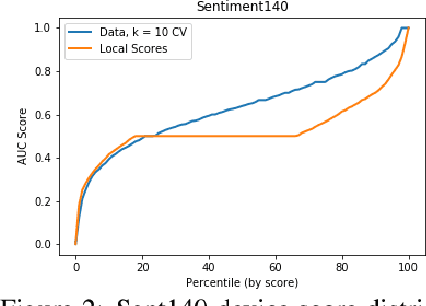
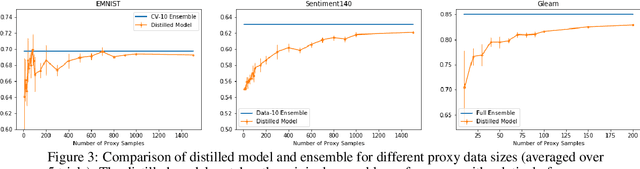
We present one-shot federated learning, where a central server learns a global model over a network of federated devices in a single round of communication. Our approach - drawing on ensemble learning and knowledge aggregation - achieves an average relative gain of 51.5% in AUC over local baselines and comes within 90.1% of the (unattainable) global ideal. We discuss these methods and identify several promising directions of future work.
Provable Guarantees for Gradient-Based Meta-Learning
Feb 27, 2019
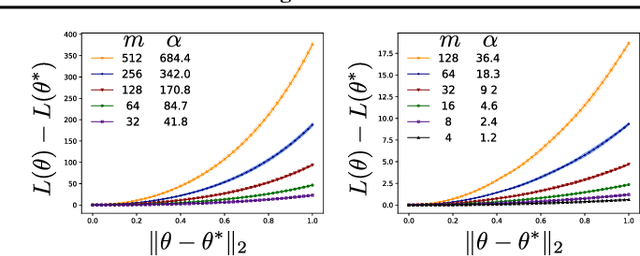
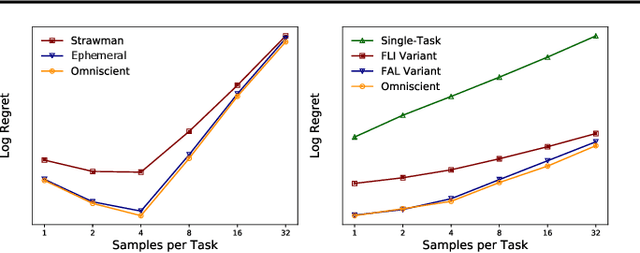
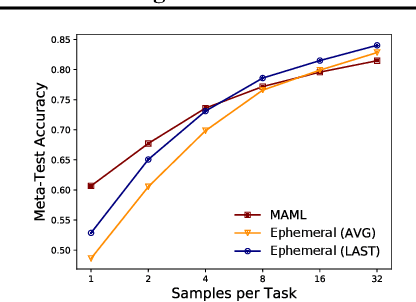
We study the problem of meta-learning through the lens of online convex optimization, developing a meta-algorithm bridging the gap between popular gradient-based meta-learning and classical regularization-based multi-task transfer methods. Our method is the first to simultaneously satisfy good sample efficiency guarantees in the convex setting, with generalization bounds that improve with task-similarity, while also being computationally scalable to modern deep learning architectures and the many-task setting. Despite its simplicity, the algorithm matches, up to a constant factor, a lower bound on the performance of any such parameter-transfer method under natural task similarity assumptions. We use experiments in both convex and deep learning settings to verify and demonstrate the applicability of our theory.
Random Search and Reproducibility for Neural Architecture Search
Feb 20, 2019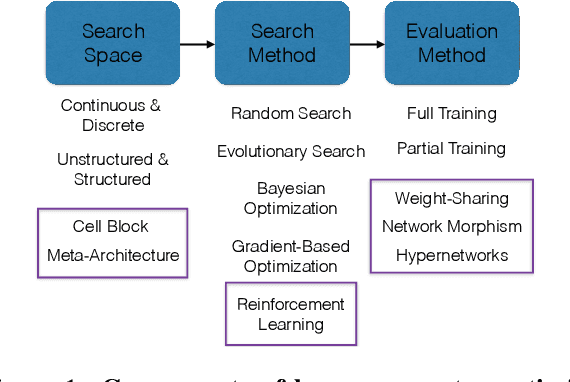
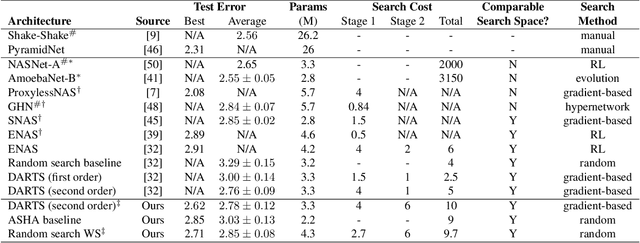
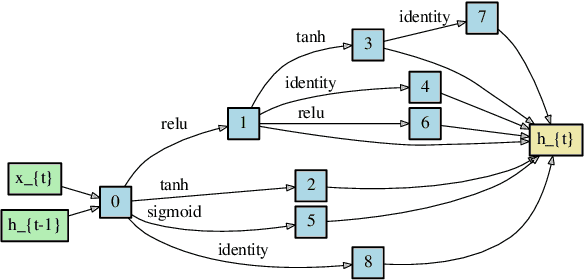
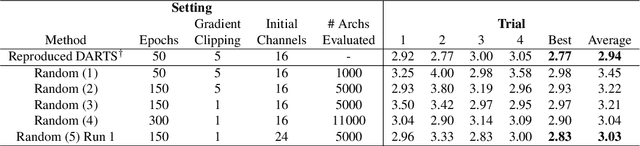
Neural architecture search (NAS) is a promising research direction that has the potential to replace expert-designed networks with learned, task-specific architectures. In this work, in order to help ground the empirical results in this field, we propose new NAS baselines that build off the following observations: (i) NAS is a specialized hyperparameter optimization problem; and (ii) random search is a competitive baseline for hyperparameter optimization. Leveraging these observations, we evaluate both random search with early-stopping and a novel random search with weight-sharing algorithm on two standard NAS benchmarks---PTB and CIFAR-10. Our results show that random search with early-stopping is a competitive NAS baseline, e.g., it performs at least as well as ENAS, a leading NAS method, on both benchmarks. Additionally, random search with weight-sharing outperforms random search with early-stopping, achieving a state-of-the-art NAS result on PTB and a highly competitive result on CIFAR-10. Finally, we explore the existing reproducibility issues of published NAS results. We note the lack of source material needed to exactly reproduce these results, and further discuss the robustness of published results given the various sources of variability in NAS experimental setups. Relatedly, we provide all information (code, random seeds, documentation) needed to exactly reproduce our results, and report our random search with weight-sharing results for each benchmark on two independent experimental runs.
Regularizing Black-box Models for Improved Interpretability
Feb 18, 2019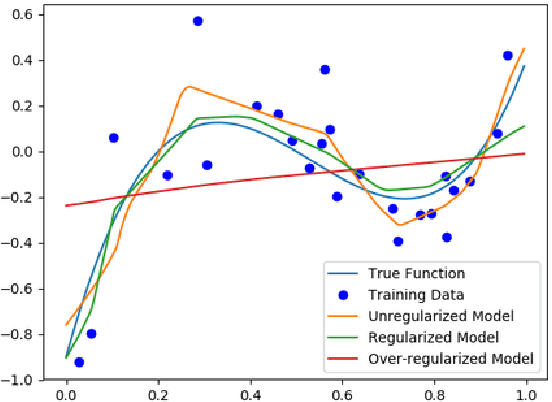
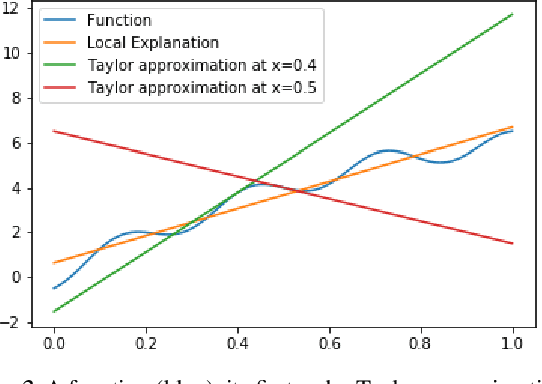
Most work on interpretability in machine learning has focused on designing either inherently interpretable models, that typically trade-off interpretability for accuracy, or post-hoc explanation systems, that lack guarantees about their explanation quality. We propose an alternative to these approaches by directly regularizing a black-box model for interpretability at training time. Our approach explicitly connects three key aspects of interpretable machine learning: the model's innate explainability, the explanation system used at test time, and the metrics that measure explanation quality. Our regularization results in substantial (up to orders of magnitude) improvement in terms of explanation fidelity and stability metrics across a range of datasets, models, and black-box explanation systems. Remarkably, our regularizers also slightly improve predictive accuracy on average across the nine datasets we consider. Further, we show that the benefits of our novel regularizers on explanation quality provably generalize to unseen test points.
LEAF: A Benchmark for Federated Settings
Jan 09, 2019
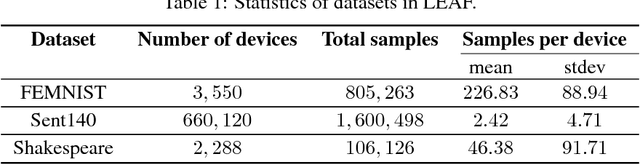
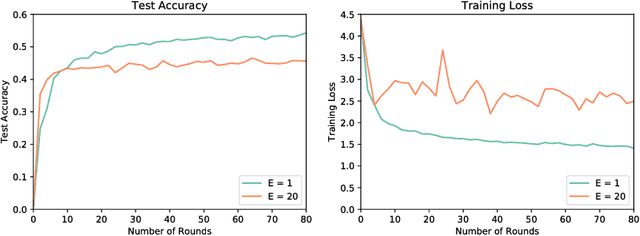
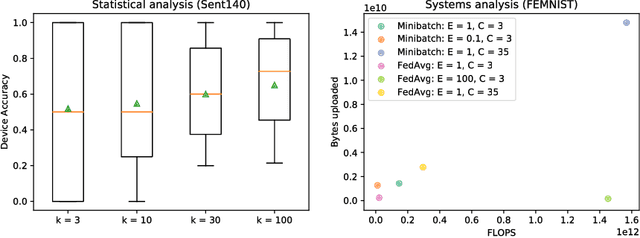
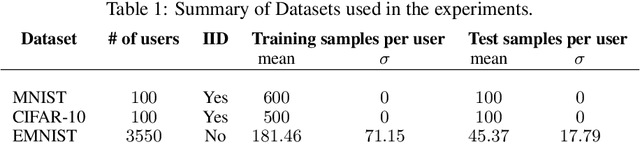
Modern federated networks, such as those comprised of wearable devices, mobile phones, or autonomous vehicles, generate massive amounts of data each day. This wealth of data can help to learn models that can improve the user experience on each device. However, learning in federated settings presents new challenges at all stages of the machine learning pipeline. As the machine learning community begins to tackle these challenges, we are at a critical time to ensure that developments made in this area are grounded in real-world assumptions. To this end, we propose LEAF, a modular benchmarking framework for learning in federated settings. LEAF includes a suite of open-source federated datasets, a rigorous evaluation framework, and a set of reference implementations, all geared toward capturing the obstacles and intricacies of practical federated environments.
Expanding the Reach of Federated Learning by Reducing Client Resource Requirements
Jan 08, 2019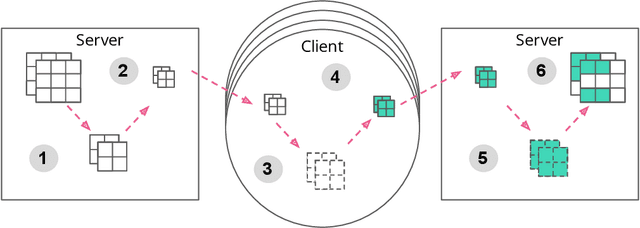
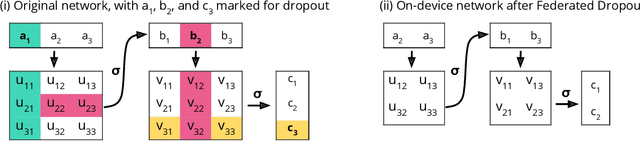

Communication on heterogeneous edge networks is a fundamental bottleneck in Federated Learning (FL), restricting both model capacity and user participation. To address this issue, we introduce two novel strategies to reduce communication costs: (1) the use of lossy compression on the global model sent server-to-client; and (2) Federated Dropout, which allows users to efficiently train locally on smaller subsets of the global model and also provides a reduction in both client-to-server communication and local computation. We empirically show that these strategies, combined with existing compression approaches for client-to-server communication, collectively provide up to a $14\times$ reduction in server-to-client communication, a $1.7\times$ reduction in local computation, and a $28\times$ reduction in upload communication, all without degrading the quality of the final model. We thus comprehensively reduce FL's impact on client device resources, allowing higher capacity models to be trained, and a more diverse set of users to be reached.
On the Convergence of Federated Optimization in Heterogeneous Networks
Dec 14, 2018
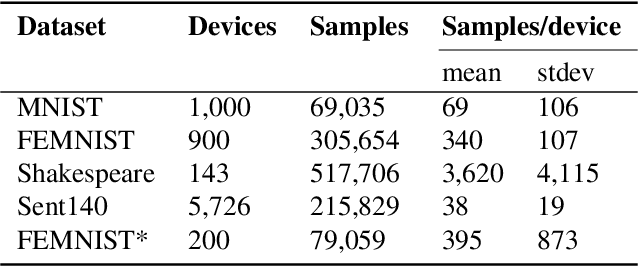
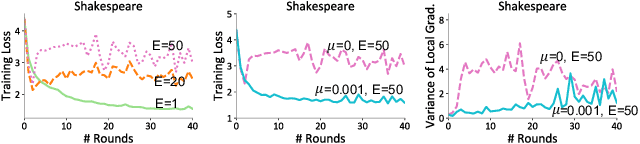
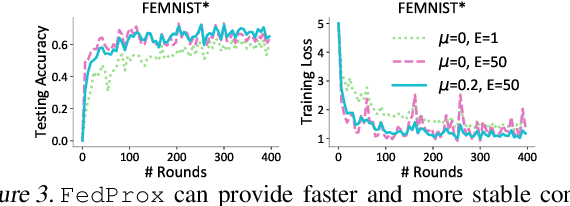
The burgeoning field of federated learning involves training machine learning models in massively distributed networks, and requires the development of novel distributed optimization techniques. Federated averaging~(\fedavg) is the leading optimization method for training non-convex models in this setting, exhibiting impressive empirical performance. However, the behavior of \fedavg is not well understood, particularly when considering data heterogeneity across devices in terms of sample sizes and underlying data distributions. In this work, we ask the following two questions: (1) Can we gain a principled understanding of \fedavg in realistic federated settings? (2) Given our improved understanding, can we devise an improved federated optimization algorithm? To this end, we propose and introduce \fedprox, which is similar in spirit to \fedavg, but more amenable to theoretical analysis. We characterize the convergence of \fedprox under a novel \textit{device similarity} assumption.
Model Agnostic Supervised Local Explanations
Oct 27, 2018
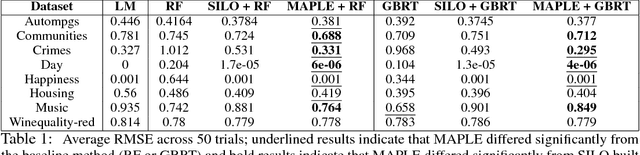
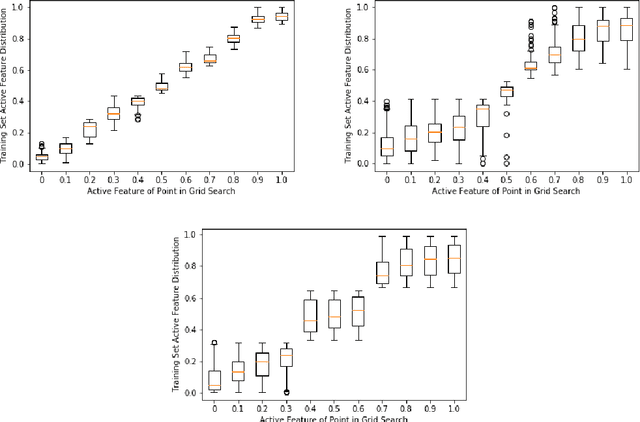
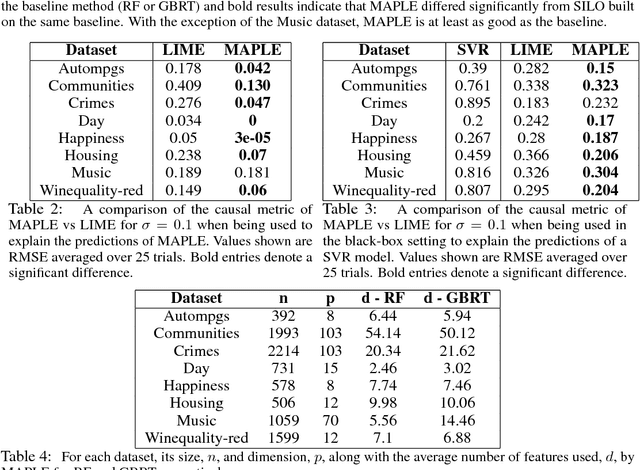
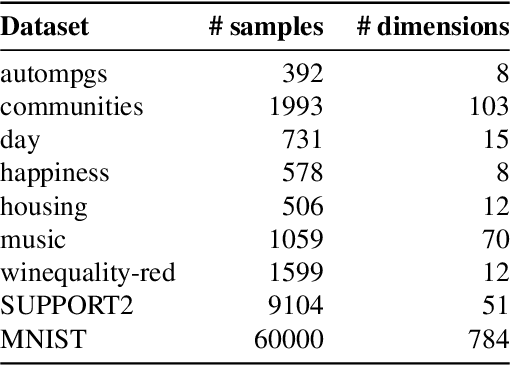
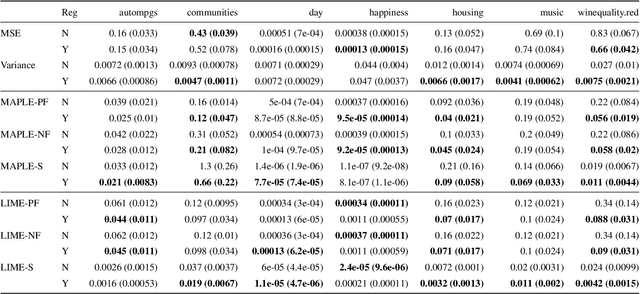
Model interpretability is an increasingly important component of practical machine learning. Some of the most common forms of interpretability systems are example-based, local, and global explanations. One of the main challenges in interpretability is designing explanation systems that can capture aspects of each of these explanation types, in order to develop a more thorough understanding of the model. We address this challenge in a novel model called MAPLE that uses local linear modeling techniques along with a dual interpretation of random forests (both as a supervised neighborhood approach and as a feature selection method). MAPLE has two fundamental advantages over existing interpretability systems. First, while it is effective as a black-box explanation system, MAPLE itself is a highly accurate predictive model that provides faithful self explanations, and thus sidesteps the typical accuracy-interpretability trade-off. Specifically, we demonstrate, on several UCI datasets, that MAPLE is at least as accurate as random forests and that it produces more faithful local explanations than LIME, a popular interpretability system. Second, MAPLE provides both example-based and local explanations and can detect global patterns, which allows it to diagnose limitations in its local explanations.
Massively Parallel Hyperparameter Tuning
Oct 17, 2018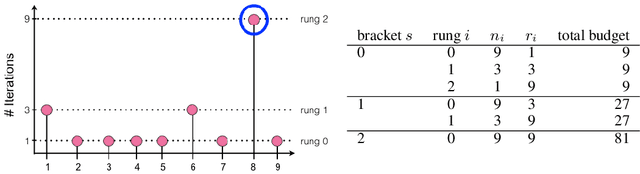

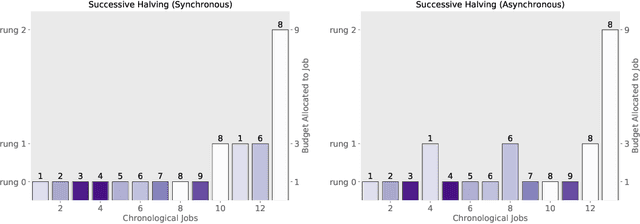
Modern learning models are characterized by large hyperparameter spaces. In order to adequately explore these large spaces, we must evaluate a large number of configurations, typically orders of magnitude more configurations than available parallel workers. Given the growing costs of model training, we would ideally like to perform this search in roughly the same wall-clock time needed to train a single model. In this work, we tackle this challenge by introducing ASHA, a simple and robust hyperparameter tuning algorithm with solid theoretical underpinnings that exploits parallelism and aggressive early-stopping. Our extensive empirical results show that ASHA slightly outperforms Fabolas and Population Based Tuning, state-of-the hyperparameter tuning methods; scales linearly with the number of workers in distributed settings; converges to a high quality configuration in half the time taken by Vizier (Google's internal hyperparameter tuning service) in an experiment with 500 workers; and beats the published result for a near state-of-the-art LSTM architecture in under 2x the time to train a single model.