 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Prompt Engineering
Aug 08, 2024



Prompts are how humans communicate with LLMs. Informative prompts are essential for guiding LLMs to produce the desired output. However, prompt engineering is often tedious and time-consuming, requiring significant expertise, limiting its widespread use. We propose Conversational Prompt Engineering (CPE), a user-friendly tool that helps users create personalized prompts for their specific tasks. CPE uses a chat model to briefly interact with users, helping them articulate their output preferences and integrating these into the prompt. The process includes two main stages: first, the model uses user-provided unlabeled data to generate data-driven questions and utilize user responses to shape the initial instruction. Then, the model shares the outputs generated by the instruction and uses user feedback to further refine the instruction and the outputs. The final result is a few-shot prompt, where the outputs approved by the user serve as few-shot examples. A user study on summarization tasks demonstrates the value of CPE in creating personalized, high-performing prompts. The results suggest that the zero-shot prompt obtained is comparable to its - much longer - few-shot counterpart, indicating significant savings in scenarios involving repetitive tasks with large text volumes.
Stay Tuned: An Empirical Study of the Impact of Hyperparameters on LLM Tuning in Real-World Applications
Jul 25, 2024



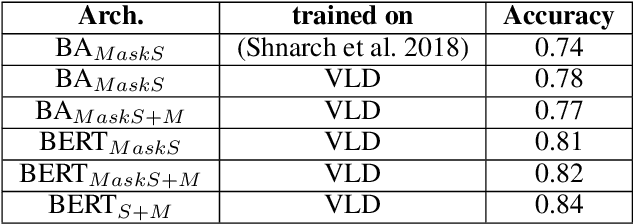
Fine-tuning Large Language Models (LLMs) is an effective method to enhance their performance on downstream tasks. However, choosing the appropriate setting of tuning hyperparameters (HPs) is a labor-intensive and computationally expensive process. Here, we provide recommended HP configurations for practical use-cases that represent a better starting point for practitioners, when considering two SOTA LLMs and two commonly used tuning methods. We describe Coverage-based Search (CBS), a process for ranking HP configurations based on an offline extensive grid search, such that the top ranked configurations collectively provide a practical robust recommendation for a wide range of datasets and domains. We focus our experiments on Llama-3-8B and Mistral-7B, as well as full fine-tuning and LoRa, conducting a total of > 10,000 tuning experiments. Our results suggest that, in general, Llama-3-8B and LoRA should be preferred, when possible. Moreover, we show that for both models and tuning methods, exploring only a few HP configurations, as recommended by our analysis, can provide excellent results in practice, making this work a valuable resource for practitioners.
Zero-Shot Text Classification with Self-Training
Oct 31, 2022



Recent advances in large pretrained language models have increased attention to zero-shot text classification. In particular, models finetuned on natural language inference datasets have been widely adopted as zero-shot classifiers due to their promising results and off-the-shelf availability. However, the fact that such models are unfamiliar with the target task can lead to instability and performance issues. We propose a plug-and-play method to bridge this gap using a simple self-training approach, requiring only the class names along with an unlabeled dataset, and without the need for domain expertise or trial and error. We show that fine-tuning the zero-shot classifier on its most confident predictions leads to significant performance gains across a wide range of text classification tasks, presumably since self-training adapts the zero-shot model to the task at hand.
Label Sleuth: From Unlabeled Text to a Classifier in a Few Hours
Aug 02, 2022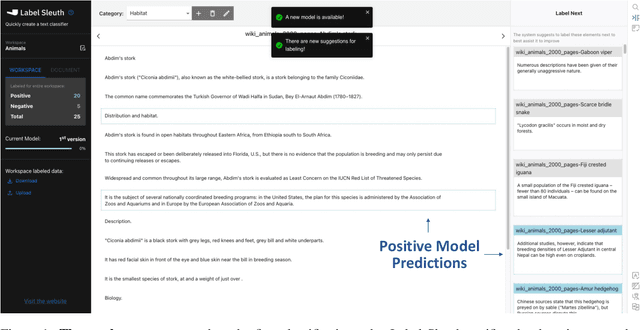


Text classification can be useful in many real-world scenarios, saving a lot of time for end users. However, building a custom classifier typically requires coding skills and ML knowledge, which poses a significant barrier for many potential users. To lift this barrier, we introduce Label Sleuth, a free open source system for labeling and creating text classifiers. This system is unique for (a) being a no-code system, making NLP accessible to non-experts, (b) guiding users through the entire labeling process until they obtain a custom classifier, making the process efficient -- from cold start to classifier in a few hours, and (c) being open for configuration and extension by developers. By open sourcing Label Sleuth we hope to build a community of users and developers that will broaden the utilization of NLP models.
Cluster & Tune: Boost Cold Start Performance in Text Classification
Mar 20, 2022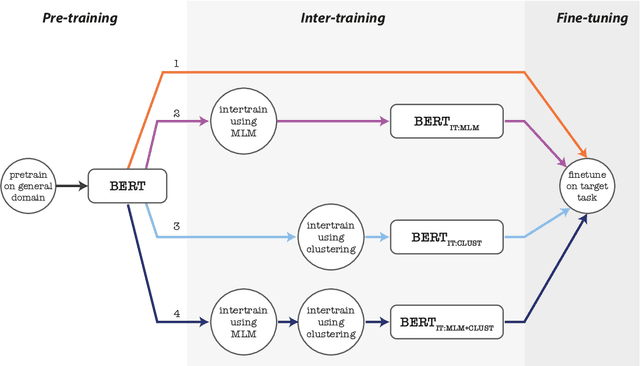
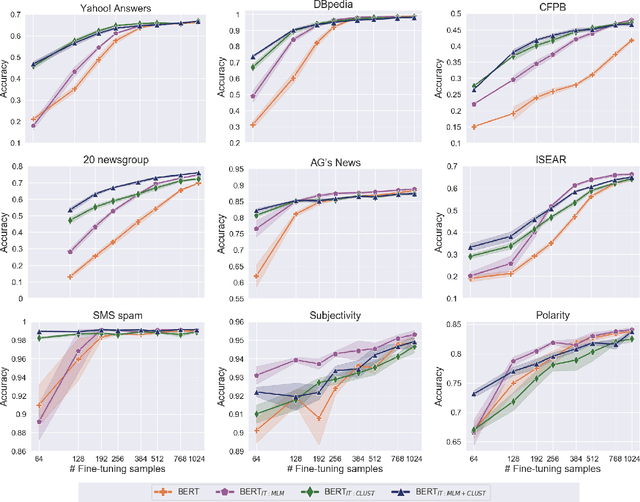
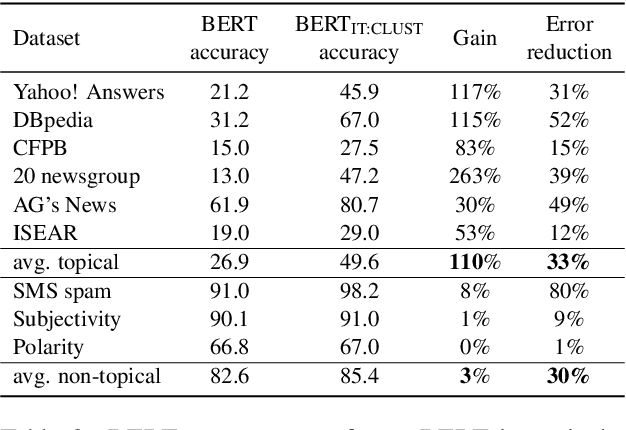
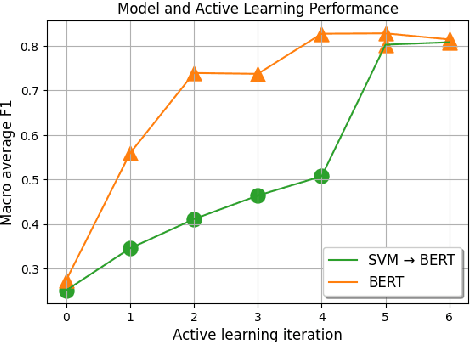
In real-world scenarios, a text classification task often begins with a cold start, when labeled data is scarce. In such cases, the common practice of fine-tuning pre-trained models, such as BERT, for a target classification task, is prone to produce poor performance. We suggest a method to boost the performance of such models by adding an intermediate unsupervised classification task, between the pre-training and fine-tuning phases. As such an intermediate task, we perform clustering and train the pre-trained model on predicting the cluster labels. We test this hypothesis on various data sets, and show that this additional classification phase can significantly improve performance, mainly for topical classification tasks, when the number of labeled instances available for fine-tuning is only a couple of dozen to a few hundred.
Financial Event Extraction Using Wikipedia-Based Weak Supervision
Nov 25, 2019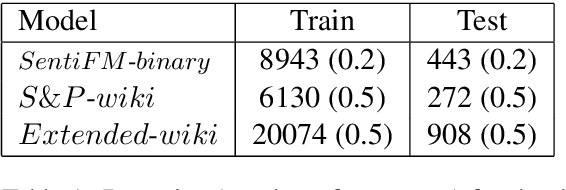
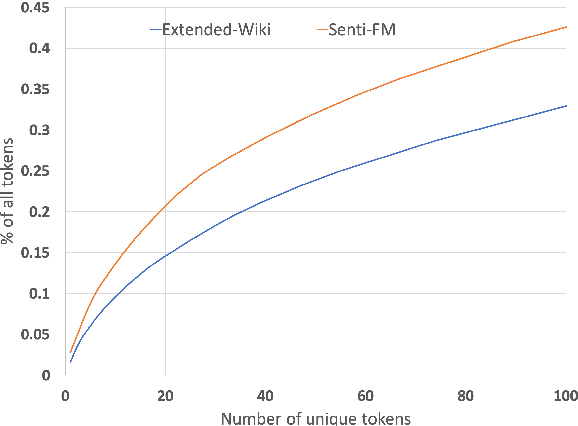
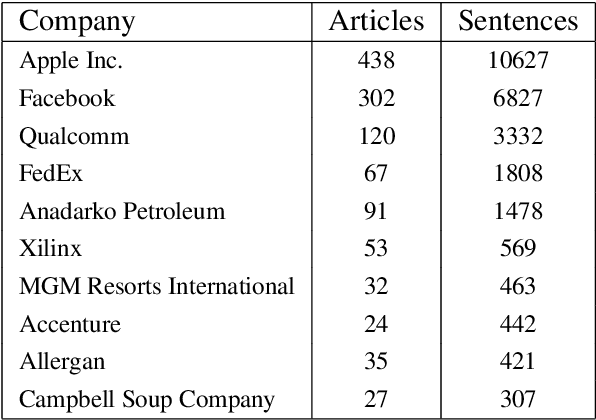
Extraction of financial and economic events from text has previously been done mostly using rule-based methods, with more recent works employing machine learning techniques. This work is in line with this latter approach, leveraging relevant Wikipedia sections to extract weak labels for sentences describing economic events. Whereas previous weakly supervised approaches required a knowledge-base of such events, or corresponding financial figures, our approach requires no such additional data, and can be employed to extract economic events related to companies which are not even mentioned in the training data.
Corpus Wide Argument Mining -- a Working Solution
Nov 25, 2019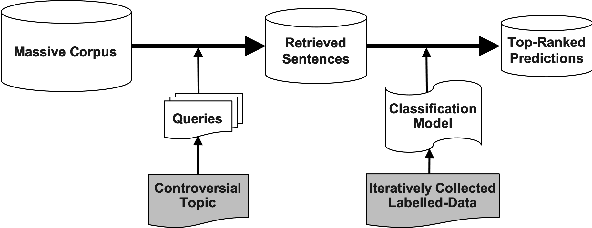
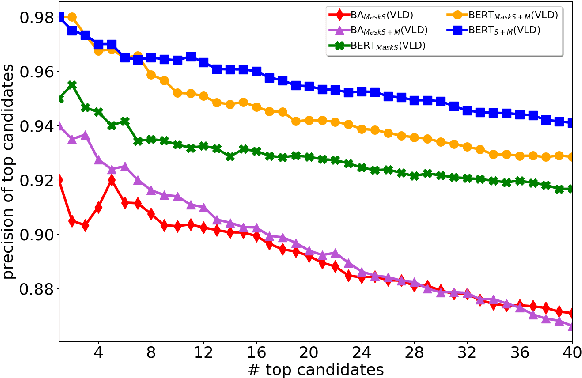
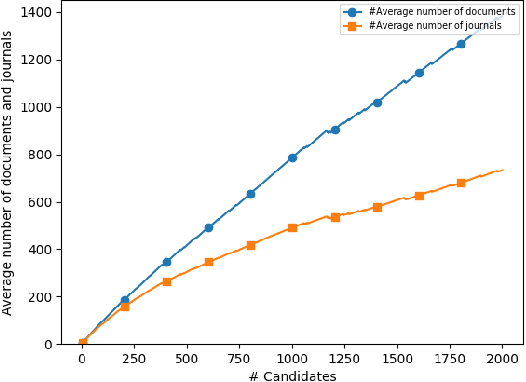
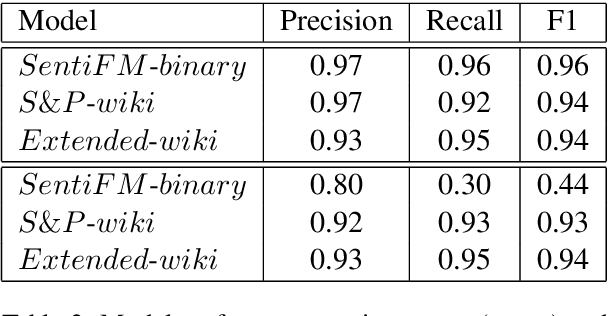
One of the main tasks in argument mining is the retrieval of argumentative content pertaining to a given topic. Most previous work addressed this task by retrieving a relatively small number of relevant documents as the initial source for such content. This line of research yielded moderate success, which is of limited use in a real-world system. Furthermore, for such a system to yield a comprehensive set of relevant arguments, over a wide range of topics, it requires leveraging a large and diverse corpus in an appropriate manner. Here we present a first end-to-end high-precision, corpus-wide argument mining system. This is made possible by combining sentence-level queries over an appropriate indexing of a very large corpus of newspaper articles, with an iterative annotation scheme. This scheme addresses the inherent label bias in the data and pinpoints the regions of the sample space whose manual labeling is required to obtain high-precision among top-ranked candidates.
Fast End-to-End Wikification
Aug 19, 2019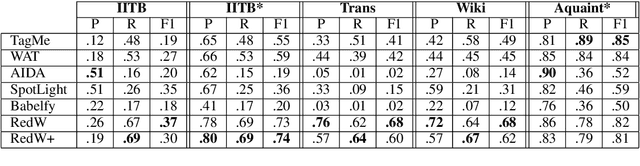
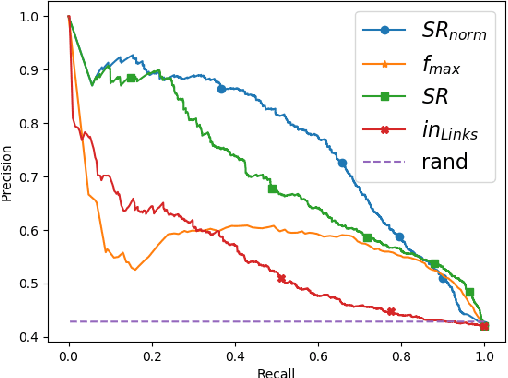
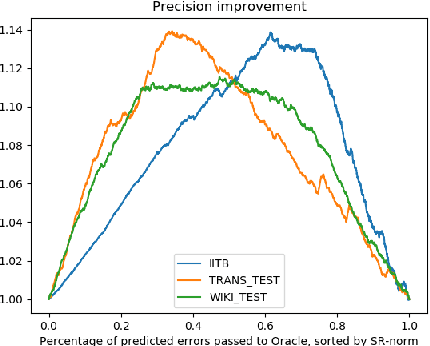

Wikification of large corpora is beneficial for various NLP applications. Existing methods focus on quality performance rather than run-time, and are therefore non-feasible for large data. Here, we introduce RedW, a run-time oriented Wikification solution, based on Wikipedia redirects, that can Wikify massive corpora with competitive performance. We further propose an efficient method for estimating RedW confidence, opening the door for applying more demanding methods only on top of RedW lower-confidence results. Our experimental results support the validity of the proposed approach.
Syntactic Interchangeability in Word Embedding Models
Apr 12, 2019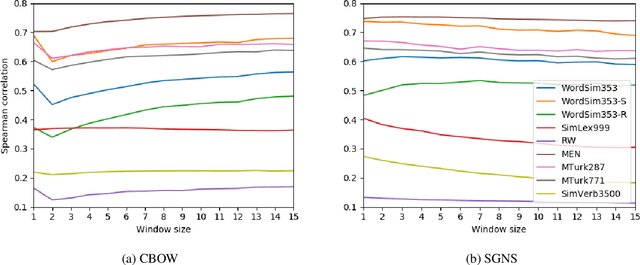
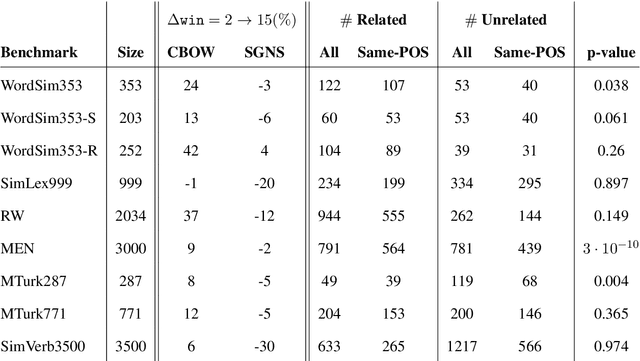
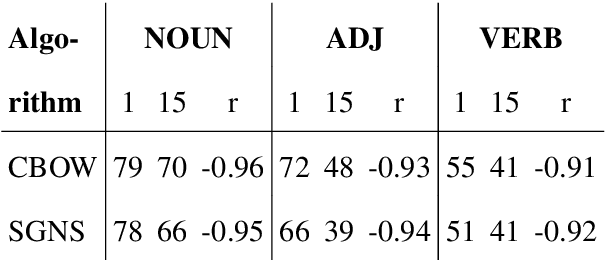
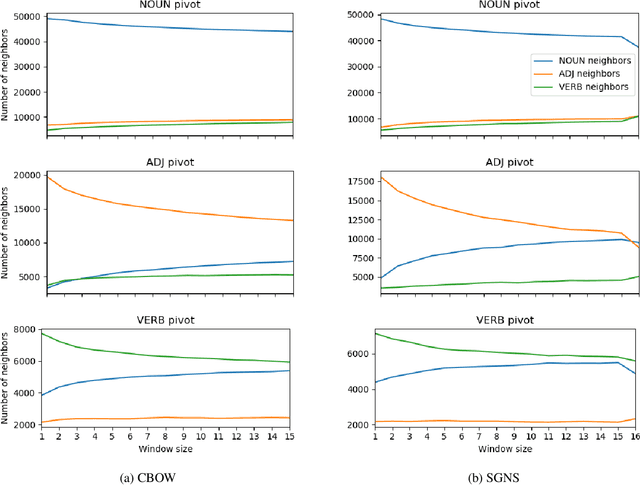
Nearest neighbors in word embedding models are commonly observed to be semantically similar, but the relations between them can vary greatly. We investigate the extent to which word embedding models preserve syntactic interchangeability, as reflected by distances between word vectors, and the effect of hyper-parameters---context window size in particular. We use part of speech (POS) as a proxy for syntactic interchangeability, as generally speaking, words with the same POS are syntactically valid in the same contexts. We also investigate the relationship between interchangeability and similarity as judged by commonly-used word similarity benchmarks, and correlate the result with the performance of word embedding models on these benchmarks. Our results will inform future research and applications in the selection of word embedding model, suggesting a principle for an appropriate selection of the context window size parameter depending on the use-case.