 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Where It Matters: High-Resolution Crops Retrieval for Efficient VLMs
Mar 14, 2026Vision-language models (VLMs) typically process images at a native high-resolution, forcing a trade-off between accuracy and computational efficiency: high-resolution inputs capture fine details but incur significant computational costs, while low-resolution inputs advocate for efficiency, they potentially miss critical visual information, like small text. We present AwaRes, a spatial-on-demand framework that resolves this accuracy-efficiency trade-off by operating on a low-resolution global view and using tool-calling to retrieve only high-resolution segments needed for a given query. We construct supervised data automatically: a judge compares low- vs.\ high-resolution answers to label whether cropping is needed, and an oracle grounding model localizes the evidence for the correct answer, which we map to a discrete crop set to form multi-turn tool-use trajectories. We train our framework with cold-start SFT followed by multi-turn GRPO with a composite reward that combines semantic answer correctness with explicit crop-cost penalties. Project page: https://nimrodshabtay.github.io/AwaRes
Conversational Prompt Engineering
Aug 08, 2024



Prompts are how humans communicate with LLMs. Informative prompts are essential for guiding LLMs to produce the desired output. However, prompt engineering is often tedious and time-consuming, requiring significant expertise, limiting its widespread use. We propose Conversational Prompt Engineering (CPE), a user-friendly tool that helps users create personalized prompts for their specific tasks. CPE uses a chat model to briefly interact with users, helping them articulate their output preferences and integrating these into the prompt. The process includes two main stages: first, the model uses user-provided unlabeled data to generate data-driven questions and utilize user responses to shape the initial instruction. Then, the model shares the outputs generated by the instruction and uses user feedback to further refine the instruction and the outputs. The final result is a few-shot prompt, where the outputs approved by the user serve as few-shot examples. A user study on summarization tasks demonstrates the value of CPE in creating personalized, high-performing prompts. The results suggest that the zero-shot prompt obtained is comparable to its - much longer - few-shot counterpart, indicating significant savings in scenarios involving repetitive tasks with large text volumes.
Stay Tuned: An Empirical Study of the Impact of Hyperparameters on LLM Tuning in Real-World Applications
Jul 25, 2024



Fine-tuning Large Language Models (LLMs) is an effective method to enhance their performance on downstream tasks. However, choosing the appropriate setting of tuning hyperparameters (HPs) is a labor-intensive and computationally expensive process. Here, we provide recommended HP configurations for practical use-cases that represent a better starting point for practitioners, when considering two SOTA LLMs and two commonly used tuning methods. We describe Coverage-based Search (CBS), a process for ranking HP configurations based on an offline extensive grid search, such that the top ranked configurations collectively provide a practical robust recommendation for a wide range of datasets and domains. We focus our experiments on Llama-3-8B and Mistral-7B, as well as full fine-tuning and LoRa, conducting a total of > 10,000 tuning experiments. Our results suggest that, in general, Llama-3-8B and LoRA should be preferred, when possible. Moreover, we show that for both models and tuning methods, exploring only a few HP configurations, as recommended by our analysis, can provide excellent results in practice, making this work a valuable resource for practitioners.
Fortunately, Discourse Markers Can Enhance Language Models for Sentiment Analysis
Jan 06, 2022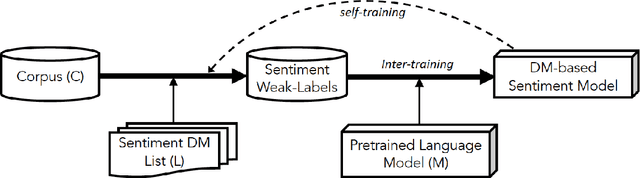

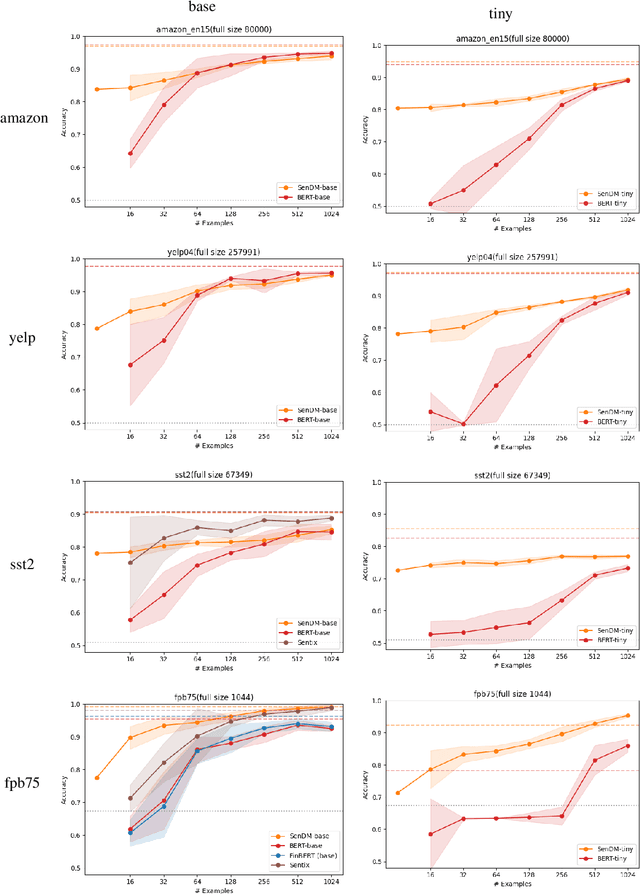
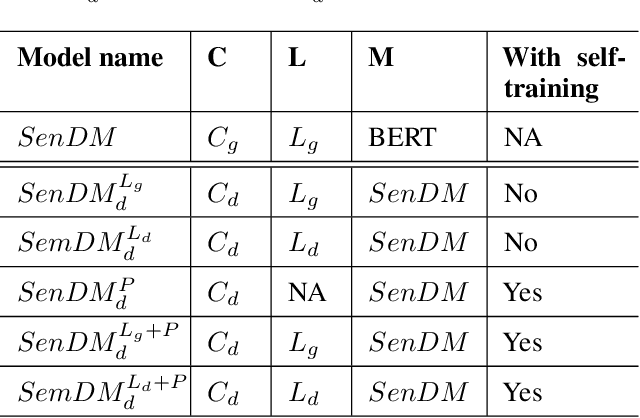
In recent years, pretrained language models have revolutionized the NLP world, while achieving state of the art performance in various downstream tasks. However, in many cases, these models do not perform well when labeled data is scarce and the model is expected to perform in the zero or few shot setting. Recently, several works have shown that continual pretraining or performing a second phase of pretraining (inter-training) which is better aligned with the downstream task, can lead to improved results, especially in the scarce data setting. Here, we propose to leverage sentiment-carrying discourse markers to generate large-scale weakly-labeled data, which in turn can be used to adapt language models for sentiment analysis. Extensive experimental results show the value of our approach on various benchmark datasets, including the finance domain. Code, models and data are available at https://github.com/ibm/tslm-discourse-markers.
YASO: A New Benchmark for Targeted Sentiment Analysis
Dec 29, 2020


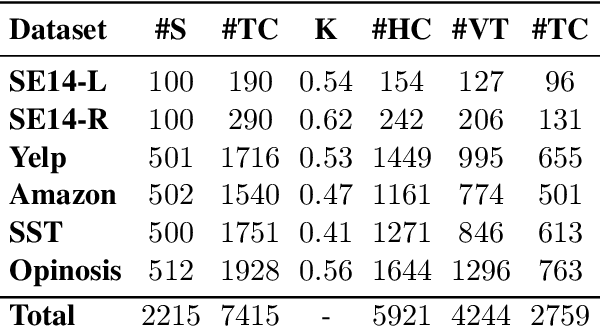
Sentiment analysis research has shifted over the years from the analysis of full documents or single sentences to a finer-level of detail -- identifying the sentiment towards single words or phrases -- with the task of Targeted Sentiment Analysis (TSA). While this problem is attracting a plethora of works focusing on algorithmic aspects, they are typically evaluated on a selection from a handful of datasets, and little effort, if any, is dedicated to the expansion of the available evaluation data. In this work, we present YASO -- a new crowd-sourced TSA evaluation dataset, collected using a new annotation scheme for labeling targets and their sentiments. The dataset contains 2,215 English sentences from movie, business and product reviews, and 7,415 terms and their corresponding sentiments annotated within these sentences. Our analysis verifies the reliability of our annotations, and explores the characteristics of the collected data. Lastly, benchmark results using five contemporary TSA systems lay the foundation for future work, and show there is ample room for improvement on this challenging new dataset.
Multilingual Argument Mining: Datasets and Analysis
Oct 13, 2020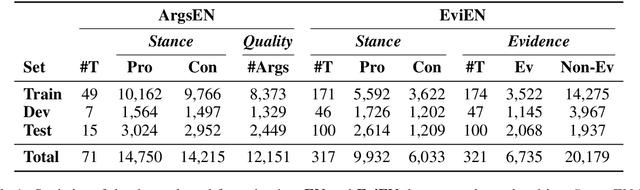
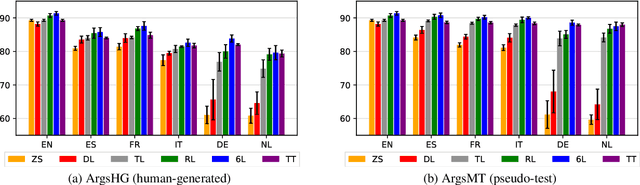
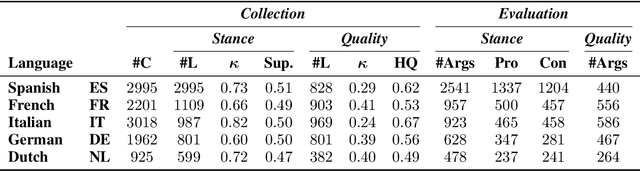
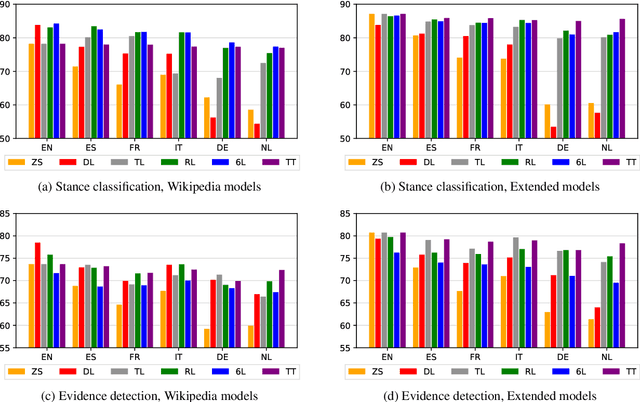
The growing interest in argument mining and computational argumentation brings with it a plethora of Natural Language Understanding (NLU) tasks and corresponding datasets. However, as with many other NLU tasks, the dominant language is English, with resources in other languages being few and far between. In this work, we explore the potential of transfer learning using the multilingual BERT model to address argument mining tasks in non-English languages, based on English datasets and the use of machine translation. We show that such methods are well suited for classifying the stance of arguments and detecting evidence, but less so for assessing the quality of arguments, presumably because quality is harder to preserve under translation. In addition, focusing on the translate-train approach, we show how the choice of languages for translation, and the relations among them, affect the accuracy of the resultant model. Finally, to facilitate evaluation of transfer learning on argument mining tasks, we provide a human-generated dataset with more than 10k arguments in multiple languages, as well as machine translation of the English datasets.
Fast End-to-End Wikification
Aug 19, 2019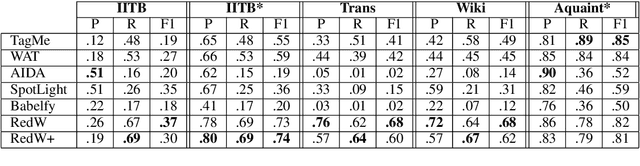
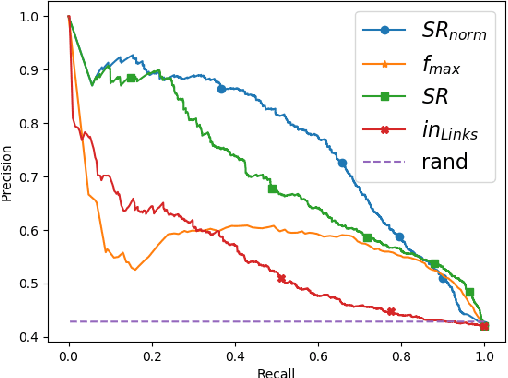
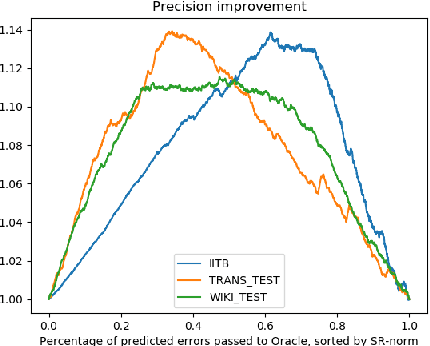

Wikification of large corpora is beneficial for various NLP applications. Existing methods focus on quality performance rather than run-time, and are therefore non-feasible for large data. Here, we introduce RedW, a run-time oriented Wikification solution, based on Wikipedia redirects, that can Wikify massive corpora with competitive performance. We further propose an efficient method for estimating RedW confidence, opening the door for applying more demanding methods only on top of RedW lower-confidence results. Our experimental results support the validity of the proposed approach.
Learning Concept Abstractness Using Weak Supervision
Sep 05, 2018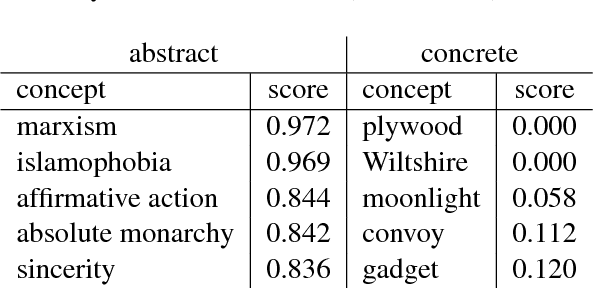
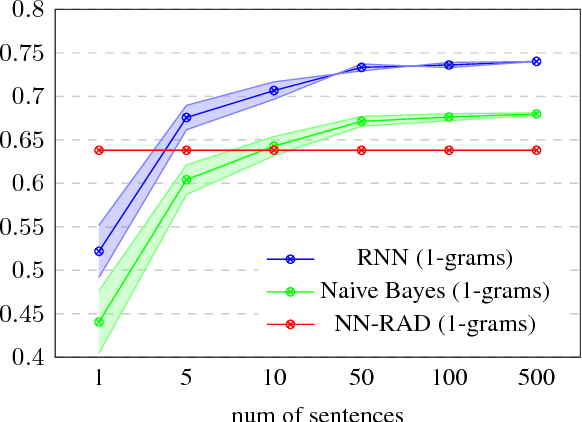
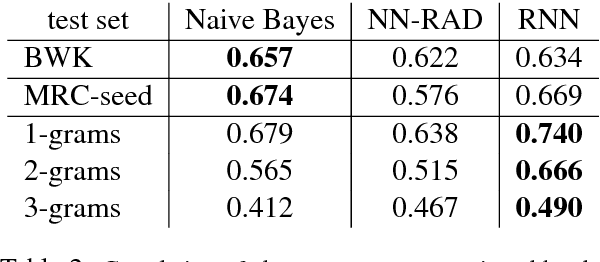
We introduce a weakly supervised approach for inferring the property of abstractness of words and expressions in the complete absence of labeled data. Exploiting only minimal linguistic clues and the contextual usage of a concept as manifested in textual data, we train sufficiently powerful classifiers, obtaining high correlation with human labels. The results imply the applicability of this approach to additional properties of concepts, additional languages, and resource-scarce scenarios.