 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOVE: A Large-Scale Multi-Dimensional Predictions Dataset Towards Meaningful LLM Evaluation
Mar 04, 2025Recent work found that LLMs are sensitive to a wide range of arbitrary prompt dimensions, including the type of delimiters, answer enumerators, instruction wording, and more. This throws into question popular single-prompt evaluation practices. We present DOVE (Dataset Of Variation Evaluation) a large-scale dataset containing prompt perturbations of various evaluation benchmarks. In contrast to previous work, we examine LLM sensitivity from an holistic perspective, and assess the joint effects of perturbations along various dimensions, resulting in thousands of perturbations per instance. We evaluate several model families against DOVE, leading to several findings, including efficient methods for choosing well-performing prompts, observing that few-shot examples reduce sensitivity, and identifying instances which are inherently hard across all perturbations. DOVE consists of more than 250M prompt perturbations and model outputs, which we make publicly available to spur a community-wide effort toward meaningful, robust, and efficient evaluation. Browse the data, contribute, and more: https://slab-nlp.github.io/DOVE/
Stay Tuned: An Empirical Study of the Impact of Hyperparameters on LLM Tuning in Real-World Applications
Jul 25, 2024



Fine-tuning Large Language Models (LLMs) is an effective method to enhance their performance on downstream tasks. However, choosing the appropriate setting of tuning hyperparameters (HPs) is a labor-intensive and computationally expensive process. Here, we provide recommended HP configurations for practical use-cases that represent a better starting point for practitioners, when considering two SOTA LLMs and two commonly used tuning methods. We describe Coverage-based Search (CBS), a process for ranking HP configurations based on an offline extensive grid search, such that the top ranked configurations collectively provide a practical robust recommendation for a wide range of datasets and domains. We focus our experiments on Llama-3-8B and Mistral-7B, as well as full fine-tuning and LoRa, conducting a total of > 10,000 tuning experiments. Our results suggest that, in general, Llama-3-8B and LoRA should be preferred, when possible. Moreover, we show that for both models and tuning methods, exploring only a few HP configurations, as recommended by our analysis, can provide excellent results in practice, making this work a valuable resource for practitioners.
Benchmark Agreement Testing Done Right: A Guide for LLM Benchmark Evaluation
Jul 18, 2024



Recent advancements in Language Models (LMs) have catalyzed the creation of multiple benchmarks, designed to assess these models' general capabilities. A crucial task, however, is assessing the validity of the benchmarks themselves. This is most commonly done via Benchmark Agreement Testing (BAT), where new benchmarks are validated against established ones using some agreement metric (e.g., rank correlation). Despite the crucial role of BAT for benchmark builders and consumers, there are no standardized procedures for such agreement testing. This deficiency can lead to invalid conclusions, fostering mistrust in benchmarks and upending the ability to properly choose the appropriate benchmark to use. By analyzing over 40 prominent benchmarks, we demonstrate how some overlooked methodological choices can significantly influence BAT results, potentially undermining the validity of conclusions. To address these inconsistencies, we propose a set of best practices for BAT and demonstrate how utilizing these methodologies greatly improves BAT robustness and validity. To foster adoption and facilitate future research,, we introduce BenchBench, a python package for BAT, and release the BenchBench-leaderboard, a meta-benchmark designed to evaluate benchmarks using their peers. Our findings underscore the necessity for standardized BAT, ensuring the robustness and validity of benchmark evaluations in the evolving landscape of language model research. BenchBench Package: https://github.com/IBM/BenchBench Leaderboard: https://huggingface.co/spaces/per/BenchBench
Genie: Achieving Human Parity in Content-Grounded Datasets Generation
Jan 25, 2024The lack of high-quality data for content-grounded generation tasks has been identified as a major obstacle to advancing these tasks. To address this gap, we propose Genie, a novel method for automatically generating high-quality content-grounded data. It consists of three stages: (a) Content Preparation, (b) Generation: creating task-specific examples from the content (e.g., question-answer pairs or summaries). (c) Filtering mechanism aiming to ensure the quality and faithfulness of the generated data. We showcase this methodology by generating three large-scale synthetic data, making wishes, for Long-Form Question-Answering (LFQA), summarization, and information extraction. In a human evaluation, our generated data was found to be natural and of high quality. Furthermore, we compare models trained on our data with models trained on human-written data -- ELI5 and ASQA for LFQA and CNN-DailyMail for Summarization. We show that our models are on par with or outperforming models trained on human-generated data and consistently outperforming them in faithfulness. Finally, we applied our method to create LFQA data within the medical domain and compared a model trained on it with models trained on other domains.
Unitxt: Flexible, Shareable and Reusable Data Preparation and Evaluation for Generative AI
Jan 25, 2024



In the dynamic landscape of generative NLP, traditional text processing pipelines limit research flexibility and reproducibility, as they are tailored to specific dataset, task, and model combinations. The escalating complexity, involving system prompts, model-specific formats, instructions, and more, calls for a shift to a structured, modular, and customizable solution. Addressing this need, we present Unitxt, an innovative library for customizable textual data preparation and evaluation tailored to generative language models. Unitxt natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively. Join the Unitxt community at https://github.com/IBM/unitxt!
Improving Cross-Lingual Transfer through Subtree-Aware Word Reordering
Oct 20, 2023



Despite the impressive growth of the abilities of multilingual language models, such as XLM-R and mT5, it has been shown that they still face difficulties when tackling typologically-distant languages, particularly in the low-resource setting. One obstacle for effective cross-lingual transfer is variability in word-order patterns. It can be potentially mitigated via source- or target-side word reordering, and numerous approaches to reordering have been proposed. However, they rely on language-specific rules, work on the level of POS tags, or only target the main clause, leaving subordinate clauses intact. To address these limitations, we present a new powerful reordering method, defined in terms of Universal Dependencies, that is able to learn fine-grained word-order patterns conditioned on the syntactic context from a small amount of annotated data and can be applied at all levels of the syntactic tree. We conduct experiments on a diverse set of tasks and show that our method consistently outperforms strong baselines over different language pairs and model architectures. This performance advantage holds true in both zero-shot and few-shot scenarios.
Efficient Benchmarking (of Language Models)
Aug 31, 2023



The increasing versatility of language models LMs has given rise to a new class of benchmarks that comprehensively assess a broad range of capabilities. Such benchmarks are associated with massive computational costs reaching thousands of GPU hours per model. However the efficiency aspect of these evaluation efforts had raised little discussion in the literature. In this work we present the problem of Efficient Benchmarking namely intelligently reducing the computation costs of LM evaluation without compromising reliability. Using the HELM benchmark as a test case we investigate how different benchmark design choices affect the computation-reliability tradeoff. We propose to evaluate the reliability of such decisions by using a new measure Decision Impact on Reliability DIoR for short. We find for example that the current leader on HELM may change by merely removing a low-ranked model from the benchmark and observe that a handful of examples suffice to obtain the correct benchmark ranking. Conversely a slightly different choice of HELM scenarios varies ranking widely. Based on our findings we outline a set of concrete recommendations for more efficient benchmark design and utilization practices leading to dramatic cost savings with minimal loss of benchmark reliability often reducing computation by x100 or more.
The Benefits of Bad Advice: Autocontrastive Decoding across Model Layers
May 02, 2023



Applying language models to natural language processing tasks typically relies on the representations in the final model layer, as intermediate hidden layer representations are presumed to be less informative. In this work, we argue that due to the gradual improvement across model layers, additional information can be gleaned from the contrast between higher and lower layers during inference. Specifically, in choosing between the probable next token predictions of a generative model, the predictions of lower layers can be used to highlight which candidates are best avoided. We propose a novel approach that utilizes the contrast between layers to improve text generation outputs, and show that it mitigates degenerative behaviors of the model in open-ended generation, significantly improving the quality of generated texts. Furthermore, our results indicate that contrasting between model layers at inference time can yield substantial benefits to certain aspects of general language model capabilities, more effectively extracting knowledge during inference from a given set of model parameters.
On the Relation between Syntactic Divergence and Zero-Shot Performance
Oct 09, 2021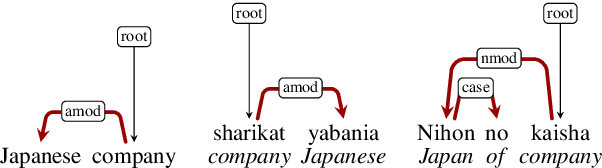
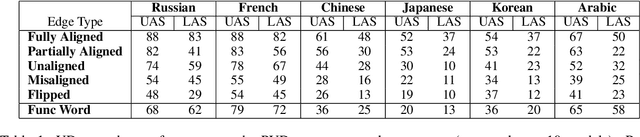

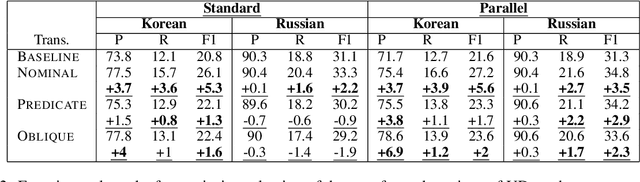
We explore the link between the extent to which syntactic relations are preserved in translation and the ease of correctly constructing a parse tree in a zero-shot setting. While previous work suggests such a relation, it tends to focus on the macro level and not on the level of individual edges-a gap we aim to address. As a test case, we take the transfer of Universal Dependencies (UD) parsing from English to a diverse set of languages and conduct two sets of experiments. In one, we analyze zero-shot performance based on the extent to which English source edges are preserved in translation. In another, we apply three linguistically motivated transformations to UD, creating more cross-lingually stable versions of it, and assess their zero-shot parsability. In order to compare parsing performance across different schemes, we perform extrinsic evaluation on the downstream task of cross-lingual relation extraction (RE) using a subset of a popular English RE benchmark translated to Russian and Korean. In both sets of experiments, our results suggest a strong relation between cross-lingual stability and zero-shot parsing performance.
HUJI-KU at MRP~2020: Two Transition-based Neural Parsers
Oct 12, 2020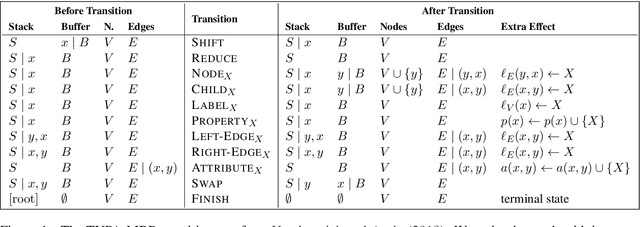
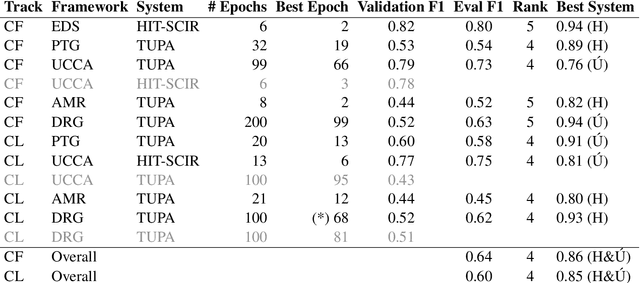

This paper describes the HUJI-KU system submission to the shared task on Cross-Framework Meaning Representation Parsing (MRP) at the 2020 Conference for Computational Language Learning (CoNLL), employing TUPA and the HIT-SCIR parser, which were, respectively, the baseline system and winning system in the 2019 MRP shared task. Both are transition-based parsers using BERT contextualized embeddings. We generalized TUPA to support the newly-added MRP frameworks and languages, and experimented with multitask learning with the HIT-SCIR parser. We reached 4th place in both the cross-framework and cross-lingual tracks.