 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntra-Document Cascading: Learning to Select Passages for Neural Document Ranking
May 20, 2021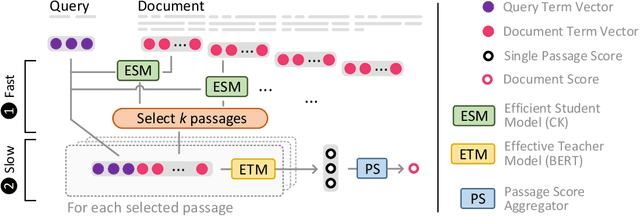
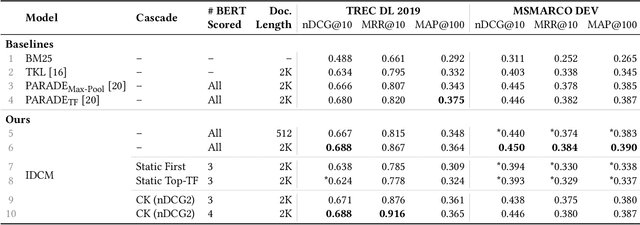
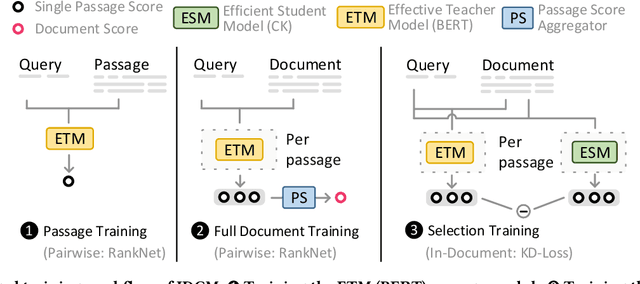
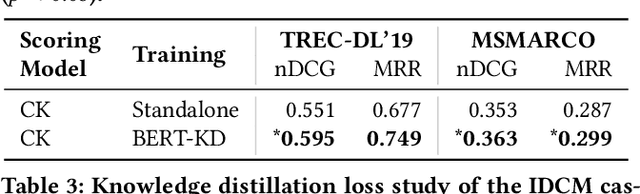
An emerging recipe for achieving state-of-the-art effectiveness in neural document re-ranking involves utilizing large pre-trained language models - e.g., BERT - to evaluate all individual passages in the document and then aggregating the outputs by pooling or additional Transformer layers. A major drawback of this approach is high query latency due to the cost of evaluating every passage in the document with BERT. To make matters worse, this high inference cost and latency varies based on the length of the document, with longer documents requiring more time and computation. To address this challenge, we adopt an intra-document cascading strategy, which prunes passages of a candidate document using a less expensive model, called ESM, before running a scoring model that is more expensive and effective, called ETM. We found it best to train ESM (short for Efficient Student Model) via knowledge distillation from the ETM (short for Effective Teacher Model) e.g., BERT. This pruning allows us to only run the ETM model on a smaller set of passages whose size does not vary by document length. Our experiments on the MS MARCO and TREC Deep Learning Track benchmarks suggest that the proposed Intra-Document Cascaded Ranking Model (IDCM) leads to over 400% lower query latency by providing essentially the same effectiveness as the state-of-the-art BERT-based document ranking models.
Efficiently Teaching an Effective Dense Retriever with Balanced Topic Aware Sampling
Apr 14, 2021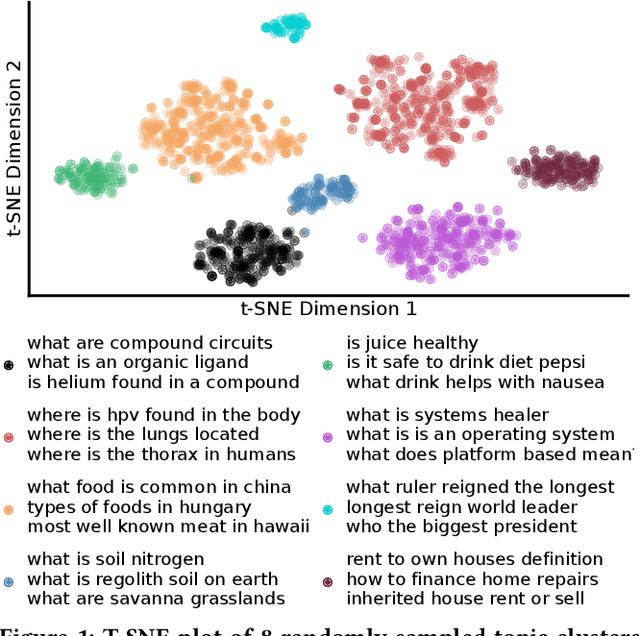
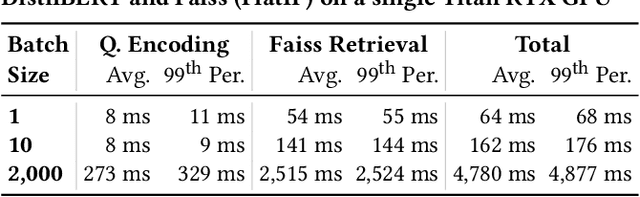
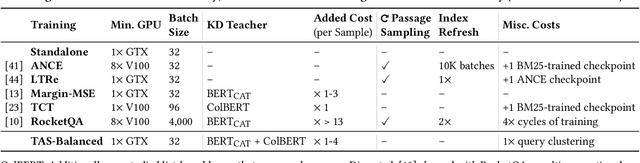
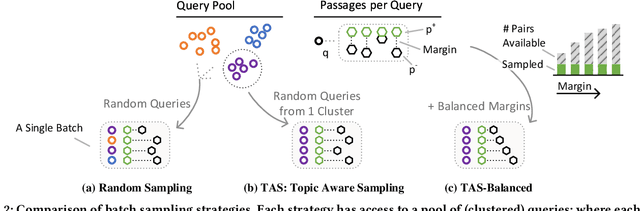
A vital step towards the widespread adoption of neural retrieval models is their resource efficiency throughout the training, indexing and query workflows. The neural IR community made great advancements in training effective dual-encoder dense retrieval (DR) models recently. A dense text retrieval model uses a single vector representation per query and passage to score a match, which enables low-latency first stage retrieval with a nearest neighbor search. Increasingly common, training approaches require enormous compute power, as they either conduct negative passage sampling out of a continuously updating refreshing index or require very large batch sizes for in-batch negative sampling. Instead of relying on more compute capability, we introduce an efficient topic-aware query and balanced margin sampling technique, called TAS-Balanced. We cluster queries once before training and sample queries out of a cluster per batch. We train our lightweight 6-layer DR model with a novel dual-teacher supervision that combines pairwise and in-batch negative teachers. Our method is trainable on a single consumer-grade GPU in under 48 hours (as opposed to a common configuration of 8x V100s). We show that our TAS-Balanced training method achieves state-of-the-art low-latency (64ms per query) results on two TREC Deep Learning Track query sets. Evaluated on NDCG@10, we outperform BM25 by 44%, a plainly trained DR by 19%, docT5query by 11%, and the previous best DR model by 5%. Additionally, TAS-Balanced produces the first dense retriever that outperforms every other method on recall at any cutoff on TREC-DL and allows more resource intensive re-ranking models to operate on fewer passages to improve results further.
Cross-domain Retrieval in the Legal and Patent Domains: a Reproducibility Study
Jan 19, 2021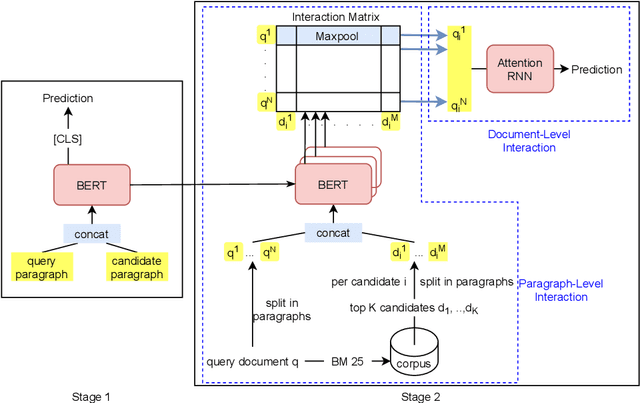

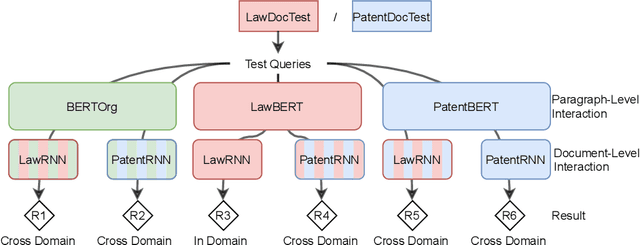
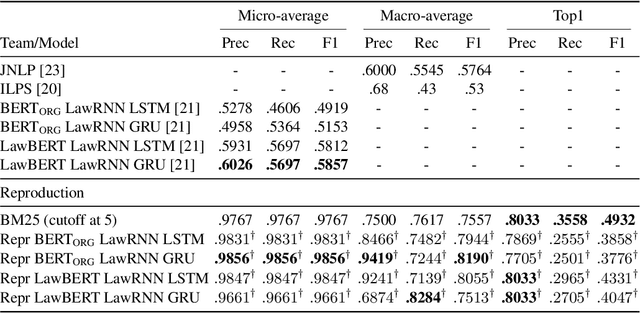
Domain specific search has always been a challenging information retrieval task due to several challenges such as the domain specific language, the unique task setting, as well as the lack of accessible queries and corresponding relevance judgements. In the last years, pretrained language models, such as BERT, revolutionized web and news search. Naturally, the community aims to adapt these advancements to cross-domain transfer of retrieval models for domain specific search. In the context of legal document retrieval, Shao et al. propose the BERT-PLI framework by modeling the Paragraph Level Interactions with the language model BERT. In this paper we reproduce the original experiments, we clarify pre-processing steps, add missing scripts for framework steps and investigate different evaluation approaches, however we are not able to reproduce the evaluation results. Contrary to the original paper, we demonstrate that the domain specific paragraph-level modelling does not appear to help the performance of the BERT-PLI model compared to paragraph-level modelling with the original BERT. In addition to our legal search reproducibility study, we investigate BERT-PLI for document retrieval in the patent domain. We find that the BERT-PLI model does not yet achieve performance improvements for patent document retrieval compared to the BM25 baseline. Furthermore, we evaluate the BERT-PLI model for cross-domain retrieval between the legal and patent domain on individual components, both on a paragraph and document-level. We find that the transfer of the BERT-PLI model on the paragraph-level leads to comparable results between both domains as well as first promising results for the cross-domain transfer on the document-level. For reproducibility and transparency as well as to benefit the community we make our source code and the trained models publicly available.
Mitigating the Position Bias of Transformer Models in Passage Re-Ranking
Jan 18, 2021
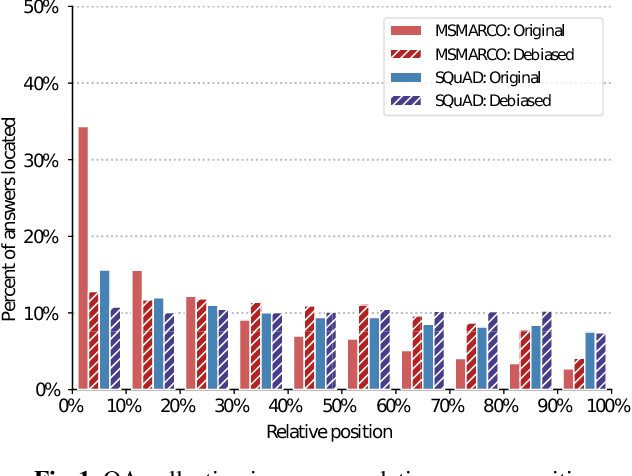

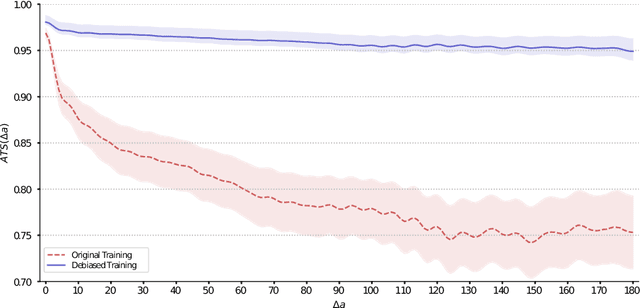
Supervised machine learning models and their evaluation strongly depends on the quality of the underlying dataset. When we search for a relevant piece of information it may appear anywhere in a given passage. However, we observe a bias in the position of the correct answer in the text in two popular Question Answering datasets used for passage re-ranking. The excessive favoring of earlier positions inside passages is an unwanted artefact. This leads to three common Transformer-based re-ranking models to ignore relevant parts in unseen passages. More concerningly, as the evaluation set is taken from the same biased distribution, the models overfitting to that bias overestimate their true effectiveness. In this work we analyze position bias on datasets, the contextualized representations, and their effect on retrieval results. We propose a debiasing method for retrieval datasets. Our results show that a model trained on a position-biased dataset exhibits a significant decrease in re-ranking effectiveness when evaluated on a debiased dataset. We demonstrate that by mitigating the position bias, Transformer-based re-ranking models are equally effective on a biased and debiased dataset, as well as more effective in a transfer-learning setting between two differently biased datasets.
Fine-Grained Relevance Annotations for Multi-Task Document Ranking and Question Answering
Aug 12, 2020
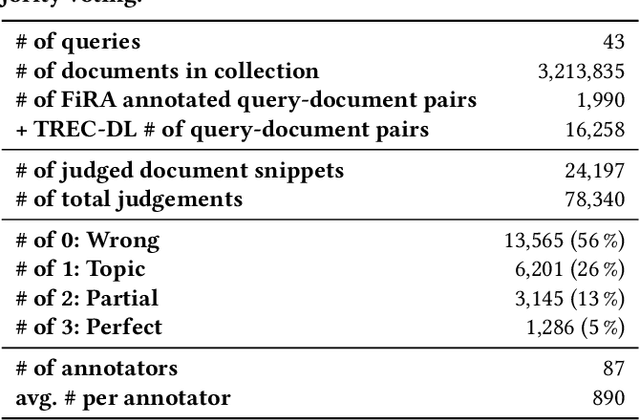
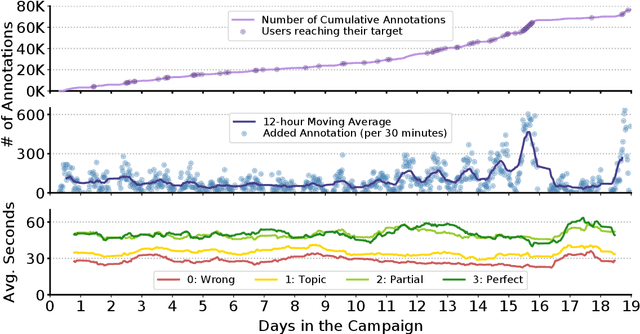

There are many existing retrieval and question answering datasets. However, most of them either focus on ranked list evaluation or single-candidate question answering. This divide makes it challenging to properly evaluate approaches concerned with ranking documents and providing snippets or answers for a given query. In this work, we present FiRA: a novel dataset of Fine-Grained Relevance Annotations. We extend the ranked retrieval annotations of the Deep Learning track of TREC 2019 with passage and word level graded relevance annotations for all relevant documents. We use our newly created data to study the distribution of relevance in long documents, as well as the attention of annotators to specific positions of the text. As an example, we evaluate the recently introduced TKL document ranking model. We find that although TKL exhibits state-of-the-art retrieval results for long documents, it misses many relevant passages.
TU Wien @ TREC Deep Learning '19 -- Simple Contextualization for Re-ranking
Dec 03, 2019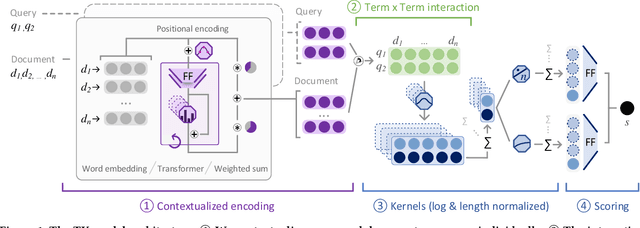
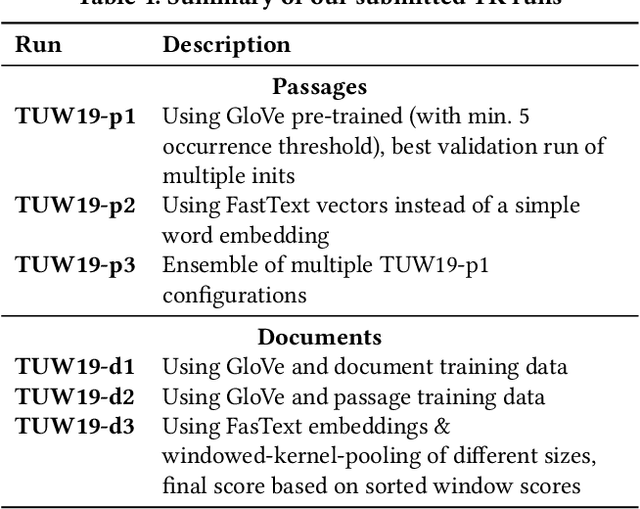
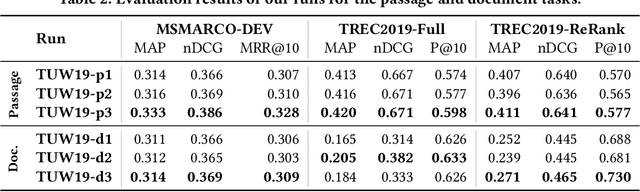
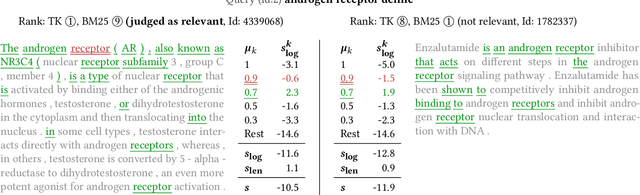
The usage of neural network models puts multiple objectives in conflict with each other: Ideally we would like to create a neural model that is effective, efficient, and interpretable at the same time. However, in most instances we have to choose which property is most important to us. We used the opportunity of the TREC 2019 Deep Learning track to evaluate the effectiveness of a balanced neural re-ranking approach. We submitted results of the TK (Transformer-Kernel) model: a neural re-ranking model for ad-hoc search using an efficient contextualization mechanism. TK employs a very small number of lightweight Transformer layers to contextualize query and document word embeddings. To score individual term interactions, we use a document-length enhanced kernel-pooling, which enables users to gain insight into the model. Our best result for the passage ranking task is: 0.420 MAP, 0.671 nDCG, 0.598 P@10 (TUW19-p3 full). Our best result for the document ranking task is: 0.271 MAP, 0.465 nDCG, 0.730 P@10 (TUW19-d3 re-ranking).
Deep Learning architectures for generalized immunofluorescence based nuclear image segmentation
Jul 30, 2019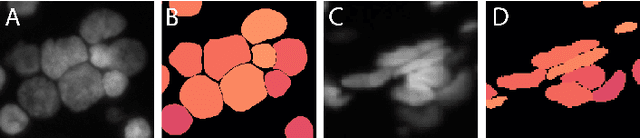
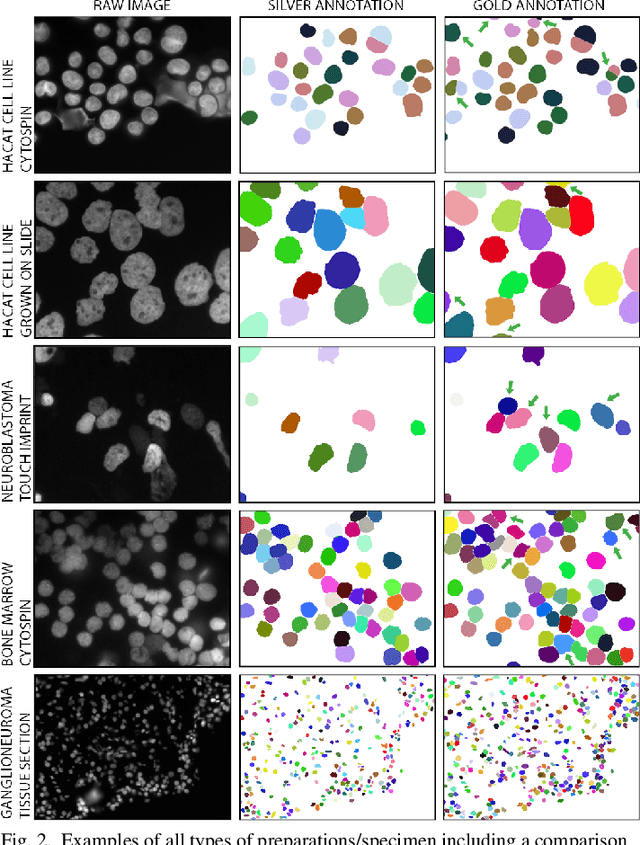
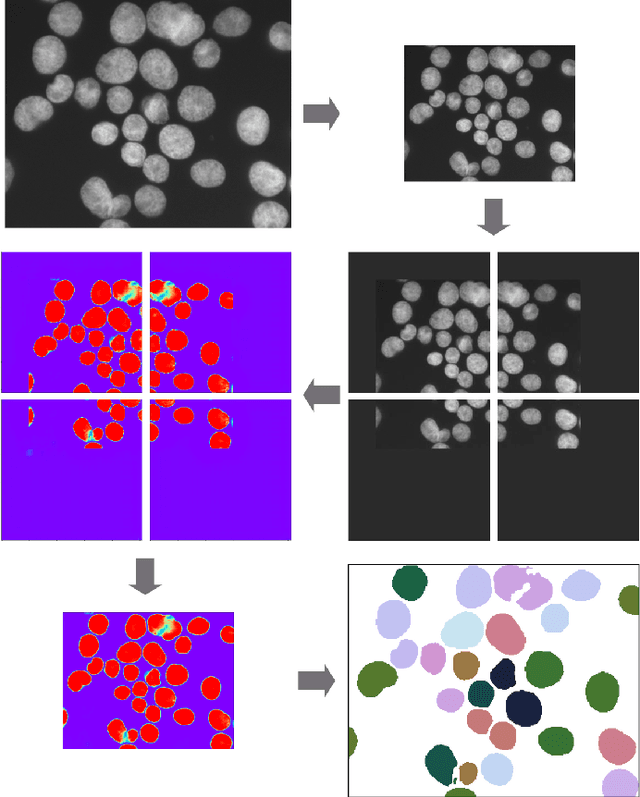

Separating and labeling each instance of a nucleus (instance-aware segmentation) is the key challenge in segmenting single cell nuclei on fluorescence microscopy images. Deep Neural Networks can learn the implicit transformation of a nuclear image into a probability map indicating the class membership of each pixel (nucleus or background), but the use of post-processing steps to turn the probability map into a labeled object mask is error-prone. This especially accounts for nuclear images of tissue sections and nuclear images across varying tissue preparations. In this work, we aim to evaluate the performance of state-of-the-art deep learning architectures to segment nuclei in fluorescence images of various tissue origins and sample preparation types without post-processing. We compare architectures that operate on pixel to pixel translation and an architecture that operates on object detection and subsequent locally applied segmentation. In addition, we propose a novel strategy to create artificial images to extend the training set. We evaluate the influence of ground truth annotation quality, image scale and segmentation complexity on segmentation performance. Results show that three out of four deep learning architectures (U-Net, U-Net with ResNet34 backbone, Mask R-CNN) can segment fluorescent nuclear images on most of the sample preparation types and tissue origins with satisfactory segmentation performance. Mask R-CNN, an architecture designed to address instance aware segmentation tasks, outperforms other architectures. Equal nuclear mean size, consistent nuclear annotations and the use of artificially generated images result in overall acceptable precision and recall across different tissues and sample preparation types.
An Unbiased Approach to Quantification of Gender Inclination using Interpretable Word Representations
Dec 13, 2018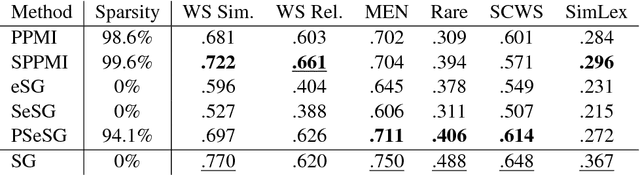
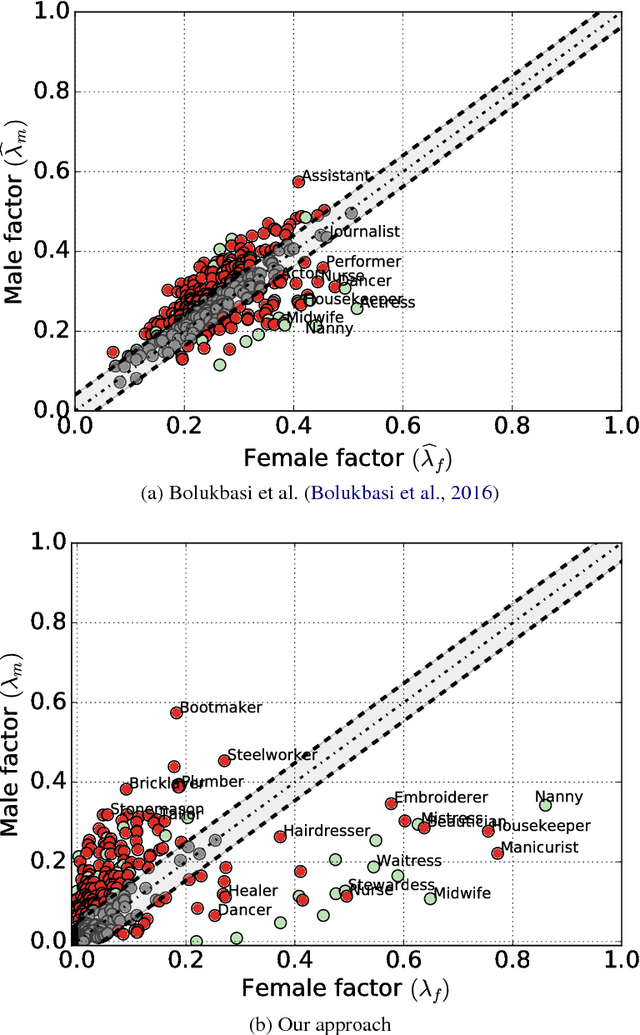
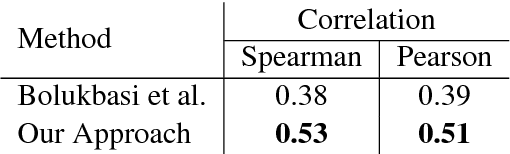
Recent advances in word embedding provide significant benefit to various information processing tasks. Yet these dense representations and their estimation of word-to-word relatedness remain difficult to interpret and hard to analyze. As an alternative, explicit word representations i.e. vectors with clearly-defined dimensions, which can be words, windows of words, or documents are easily interpretable, and recent methods show competitive performance to the dense vectors. In this work, we propose a method to transfer word2vec SkipGram embedding model to its explicit representation model. The method provides interpretable explicit vectors while keeping the effectiveness of the original model, tested by evaluating the model on several word association collections. Based on the proposed explicit representation, we propose a novel method to quantify the degree of the existence of gender bias in the English language (used in Wikipedia) with regard to a set of occupations. By measuring the bias towards explicit Female and Male factors, the work demonstrates a general tendency of the majority of the occupations to male and a strong bias in a few specific occupations (e.g. nurse) to female.
Is the winner really the best? A critical analysis of common research practice in biomedical image analysis competitions
Jun 06, 2018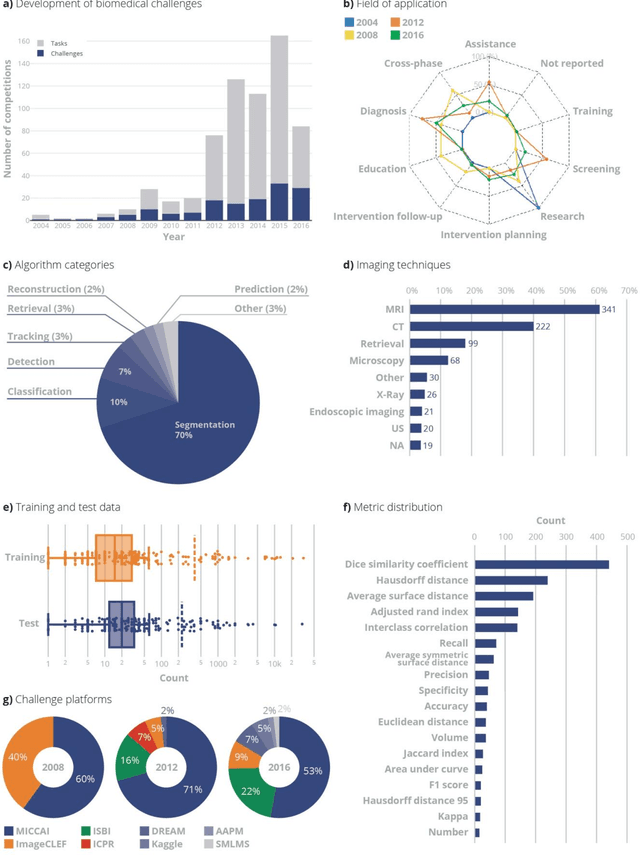
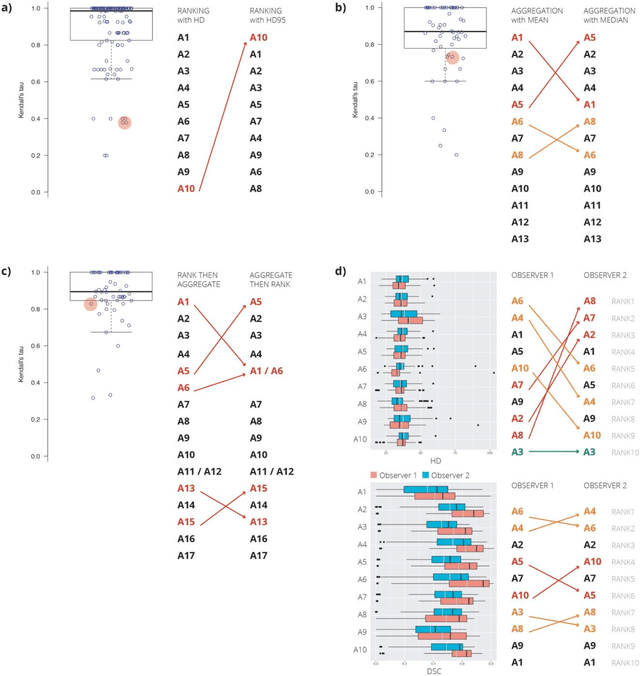
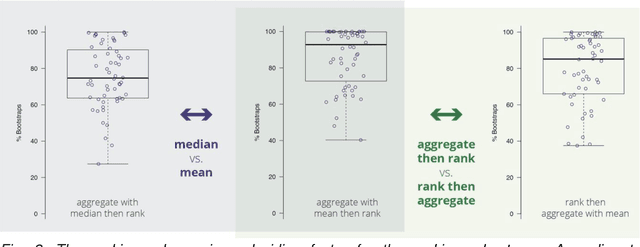
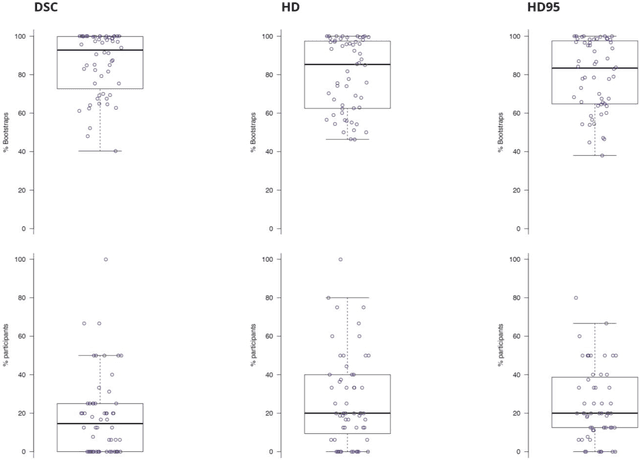
International challenges have become the standard for validation of biomedical image analysis methods. Given their scientific impact, it is surprising that a critical analysis of common practices related to the organization of challenges has not yet been performed. In this paper, we present a comprehensive analysis of biomedical image analysis challenges conducted up to now. We demonstrate the importance of challenges and show that the lack of quality control has critical consequences. First, reproducibility and interpretation of the results is often hampered as only a fraction of relevant information is typically provided. Second, the rank of an algorithm is generally not robust to a number of variables such as the test data used for validation, the ranking scheme applied and the observers that make the reference annotations. To overcome these problems, we recommend best practice guidelines and define open research questions to be addressed in the future.
Toward Incorporation of Relevant Documents in word2vec
Apr 04, 2018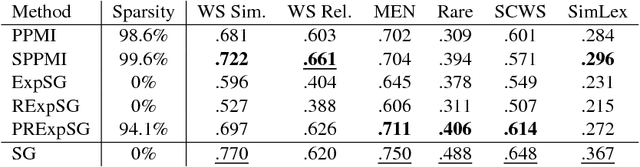
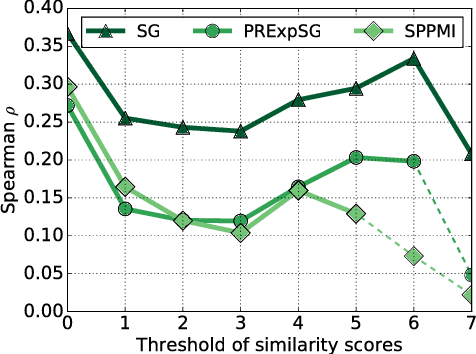
Recent advances in neural word embedding provide significant benefit to various information retrieval tasks. However as shown by recent studies, adapting the embedding models for the needs of IR tasks can bring considerable further improvements. The embedding models in general define the term relatedness by exploiting the terms' co-occurrences in short-window contexts. An alternative (and well-studied) approach in IR for related terms to a query is using local information i.e. a set of top-retrieved documents. In view of these two methods of term relatedness, in this work, we report our study on incorporating the local information of the query in the word embeddings. One main challenge in this direction is that the dense vectors of word embeddings and their estimation of term-to-term relatedness remain difficult to interpret and hard to analyze. As an alternative, explicit word representations propose vectors whose dimensions are easily interpretable, and recent methods show competitive performance to the dense vectors. We introduce a neural-based explicit representation, rooted in the conceptual ideas of the word2vec Skip-Gram model. The method provides interpretable explicit vectors while keeping the effectiveness of the Skip-Gram model. The evaluation of various explicit representations on word association collections shows that the newly proposed method out- performs the state-of-the-art explicit representations when tasked with ranking highly similar terms. Based on the introduced ex- plicit representation, we discuss our approaches on integrating local documents in globally-trained embedding models and discuss the preliminary results.