 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Planning with Model Predictive Control for Obstacle Avoidance Considering Prediction Uncertainty
Apr 27, 2025



This paper introduces a novel trajectory planner for autonomous robots, specifically designed to enhance navigation by incorporating dynamic obstacle avoidance within the Robot Operating System 2 (ROS2) and Navigation 2 (Nav2) framework. The proposed method utilizes Model Predictive Control (MPC) with a focus on handling the uncertainties associated with the movement prediction of dynamic obstacles. Unlike existing Nav2 trajectory planners which primarily deal with static obstacles or react to the current position of dynamic obstacles, this planner predicts future obstacle positions using a stochastic Vector Auto-Regressive Model (VAR). The obstacles' future positions are represented by probability distributions, and collision avoidance is achieved through constraints based on the Mahalanobis distance, ensuring the robot avoids regions where obstacles are likely to be. This approach considers the robot's kinodynamic constraints, enabling it to track a reference path while adapting to real-time changes in the environment. The paper details the implementation, including obstacle prediction, tracking, and the construction of feasible sets for MPC. Simulation results in a Gazebo environment demonstrate the effectiveness of this method in scenarios where robots must navigate around each other, showing improved collision avoidance capabilities.
Fine-Grained Relevance Annotations for Multi-Task Document Ranking and Question Answering
Aug 12, 2020
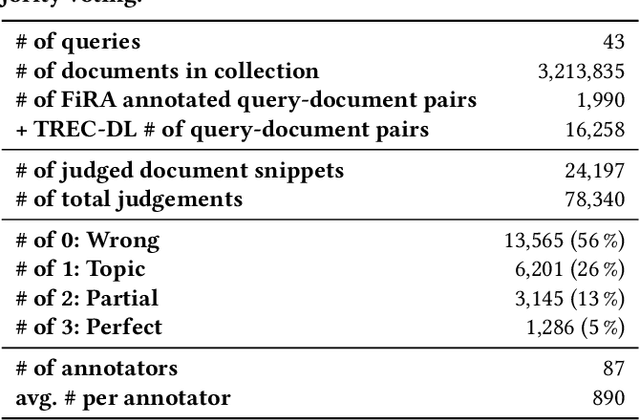
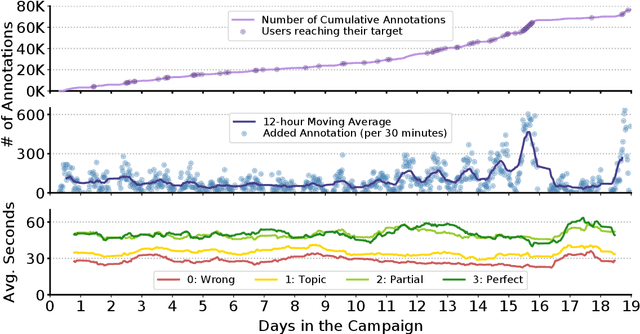

There are many existing retrieval and question answering datasets. However, most of them either focus on ranked list evaluation or single-candidate question answering. This divide makes it challenging to properly evaluate approaches concerned with ranking documents and providing snippets or answers for a given query. In this work, we present FiRA: a novel dataset of Fine-Grained Relevance Annotations. We extend the ranked retrieval annotations of the Deep Learning track of TREC 2019 with passage and word level graded relevance annotations for all relevant documents. We use our newly created data to study the distribution of relevance in long documents, as well as the attention of annotators to specific positions of the text. As an example, we evaluate the recently introduced TKL document ranking model. We find that although TKL exhibits state-of-the-art retrieval results for long documents, it misses many relevant passages.