 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Replicability of Combining Word Embeddings and Retrieval Models
Jan 13, 2020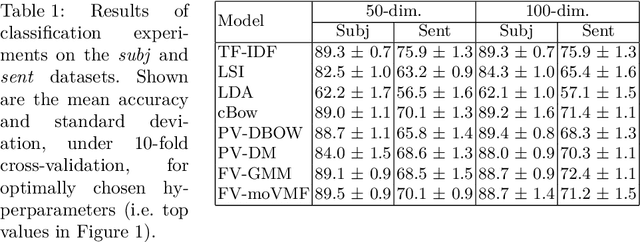
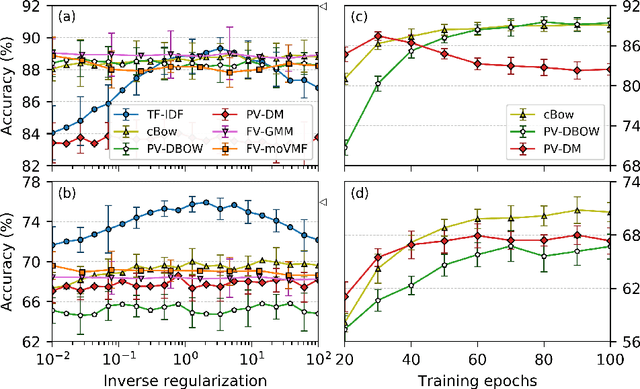
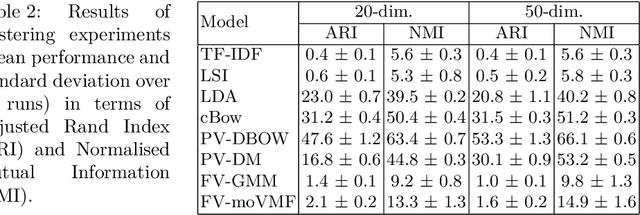
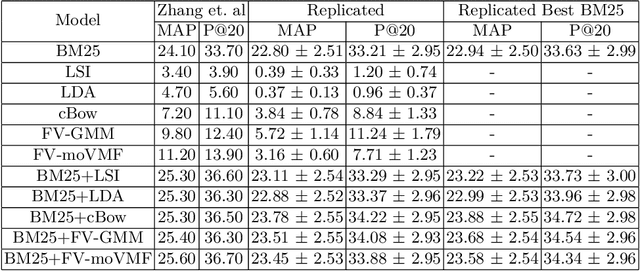
We replicate recent experiments attempting to demonstrate an attractive hypothesis about the use of the Fisher kernel framework and mixture models for aggregating word embeddings towards document representations and the use of these representations in document classification, clustering, and retrieval. Specifically, the hypothesis was that the use of a mixture model of von Mises-Fisher (VMF) distributions instead of Gaussian distributions would be beneficial because of the focus on cosine distances of both VMF and the vector space model traditionally used in information retrieval. Previous experiments had validated this hypothesis. Our replication was not able to validate it, despite a large parameter scan space.
Toward Incorporation of Relevant Documents in word2vec
Apr 04, 2018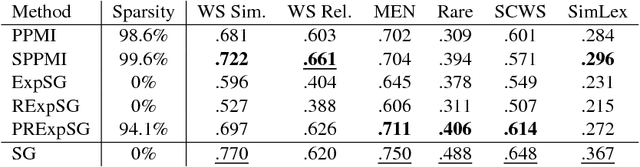
Recent advances in neural word embedding provide significant benefit to various information retrieval tasks. However as shown by recent studies, adapting the embedding models for the needs of IR tasks can bring considerable further improvements. The embedding models in general define the term relatedness by exploiting the terms' co-occurrences in short-window contexts. An alternative (and well-studied) approach in IR for related terms to a query is using local information i.e. a set of top-retrieved documents. In view of these two methods of term relatedness, in this work, we report our study on incorporating the local information of the query in the word embeddings. One main challenge in this direction is that the dense vectors of word embeddings and their estimation of term-to-term relatedness remain difficult to interpret and hard to analyze. As an alternative, explicit word representations propose vectors whose dimensions are easily interpretable, and recent methods show competitive performance to the dense vectors. We introduce a neural-based explicit representation, rooted in the conceptual ideas of the word2vec Skip-Gram model. The method provides interpretable explicit vectors while keeping the effectiveness of the Skip-Gram model. The evaluation of various explicit representations on word association collections shows that the newly proposed method out- performs the state-of-the-art explicit representations when tasked with ranking highly similar terms. Based on the introduced ex- plicit representation, we discuss our approaches on integrating local documents in globally-trained embedding models and discuss the preliminary results.
Uncertainty in Neural Network Word Embedding: Exploration of Threshold for Similarity
Apr 04, 2018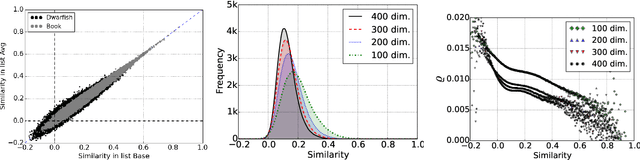
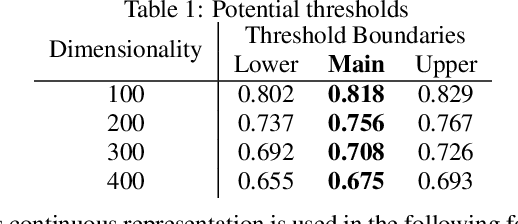
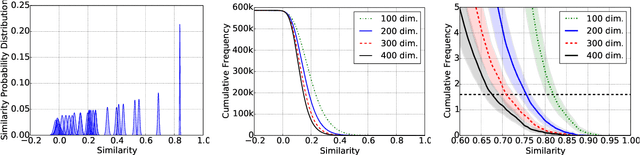

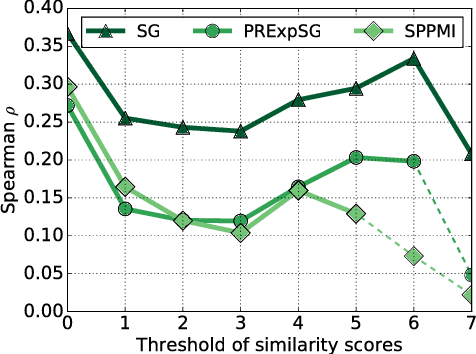
Word embedding, specially with its recent developments, promises a quantification of the similarity between terms. However, it is not clear to which extent this similarity value can be genuinely meaningful and useful for subsequent tasks. We explore how the similarity score obtained from the models is really indicative of term relatedness. We first observe and quantify the uncertainty factor of the word embedding models regarding to the similarity value. Based on this factor, we introduce a general threshold on various dimensions which effectively filters the highly related terms. Our evaluation on four information retrieval collections supports the effectiveness of our approach as the results of the introduced threshold are significantly better than the baseline while being equal to or statistically indistinguishable from the optimal results.
Addressing Cross-Lingual Word Sense Disambiguation on Low-Density Languages: Application to Persian
Mar 21, 2018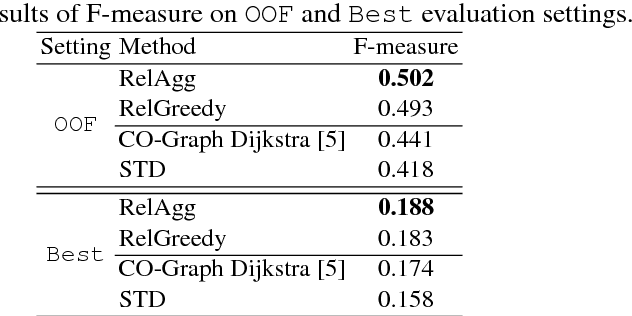
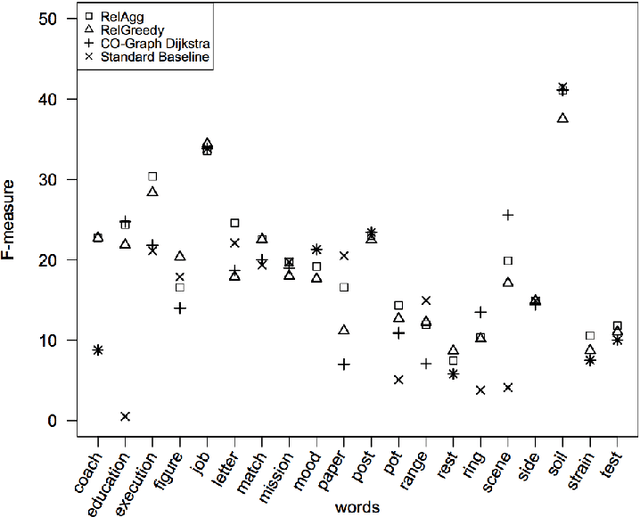
We explore the use of unsupervised methods in Cross-Lingual Word Sense Disambiguation (CL-WSD) with the application of English to Persian. Our proposed approach targets the languages with scarce resources (low-density) by exploiting word embedding and semantic similarity of the words in context. We evaluate the approach on a recent evaluation benchmark and compare it with the state-of-the-art unsupervised system (CO-Graph). The results show that our approach outperforms both the standard baseline and the CO-Graph system in both of the task evaluation metrics (Out-Of-Five and Best result).
Character-based Neural Embeddings for Tweet Clustering
Mar 16, 2017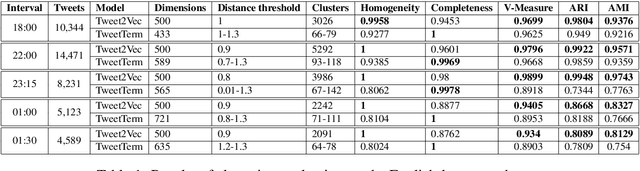
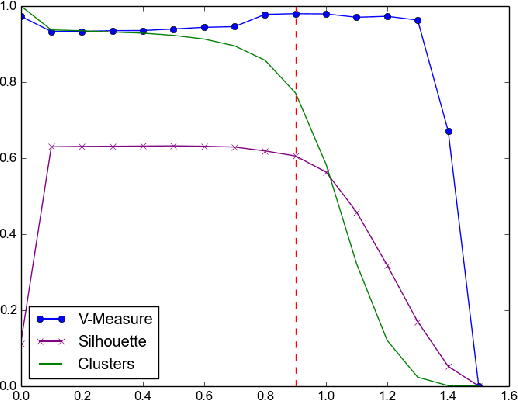


In this paper we show how the performance of tweet clustering can be improved by leveraging character-based neural networks. The proposed approach overcomes the limitations related to the vocabulary explosion in the word-based models and allows for the seamless processing of the multilingual content. Our evaluation results and code are available on-line at https://github.com/vendi12/tweet2vec_clustering