 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoiding Your Teacher's Mistakes: Training Neural Networks with Controlled Weak Supervision
Dec 07, 2017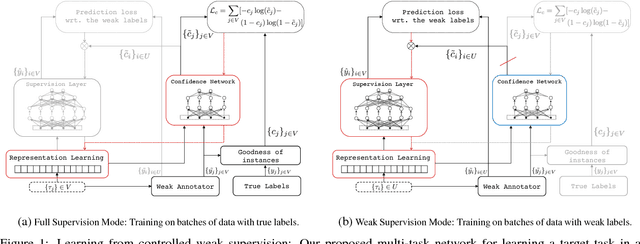
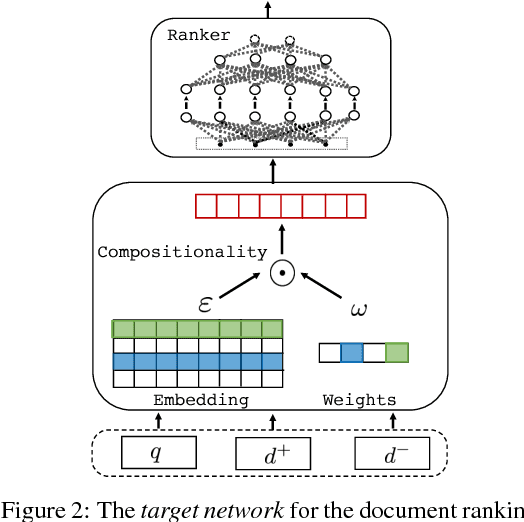
Training deep neural networks requires massive amounts of training data, but for many tasks only limited labeled data is available. This makes weak supervision attractive, using weak or noisy signals like the output of heuristic methods or user click-through data for training. In a semi-supervised setting, we can use a large set of data with weak labels to pretrain a neural network and then fine-tune the parameters with a small amount of data with true labels. This feels intuitively sub-optimal as these two independent stages leave the model unaware about the varying label quality. What if we could somehow inform the model about the label quality? In this paper, we propose a semi-supervised learning method where we train two neural networks in a multi-task fashion: a "target network" and a "confidence network". The target network is optimized to perform a given task and is trained using a large set of unlabeled data that are weakly annotated. We propose to weight the gradient updates to the target network using the scores provided by the second confidence network, which is trained on a small amount of supervised data. Thus we avoid that the weight updates computed from noisy labels harm the quality of the target network model. We evaluate our learning strategy on two different tasks: document ranking and sentiment classification. The results demonstrate that our approach not only enhances the performance compared to the baselines but also speeds up the learning process from weak labels.
Learning to Learn from Weak Supervision by Full Supervision
Nov 30, 2017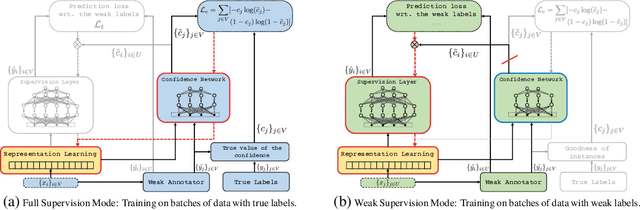
In this paper, we propose a method for training neural networks when we have a large set of data with weak labels and a small amount of data with true labels. In our proposed model, we train two neural networks: a target network, the learner and a confidence network, the meta-learner. The target network is optimized to perform a given task and is trained using a large set of unlabeled data that are weakly annotated. We propose to control the magnitude of the gradient updates to the target network using the scores provided by the second confidence network, which is trained on a small amount of supervised data. Thus we avoid that the weight updates computed from noisy labels harm the quality of the target network model.
Neural Ranking Models with Weak Supervision
May 29, 2017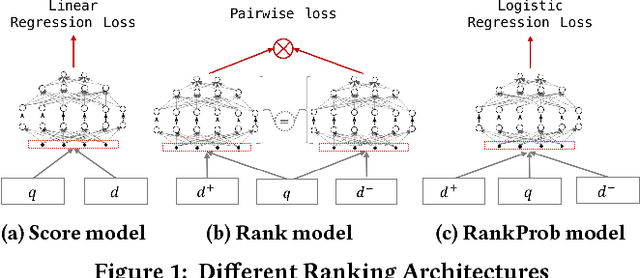
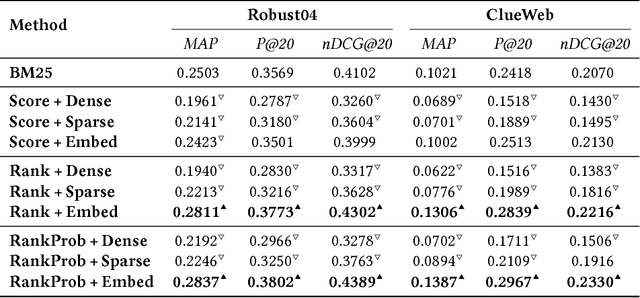
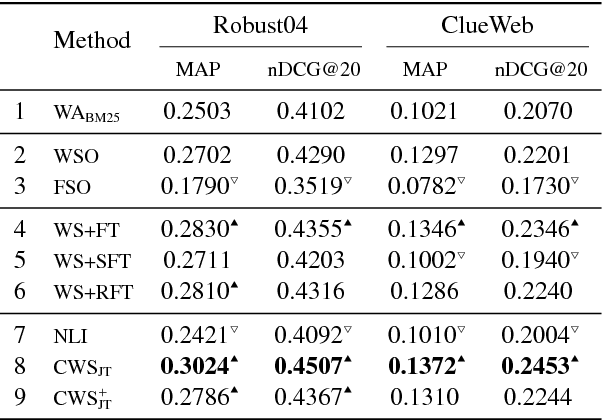
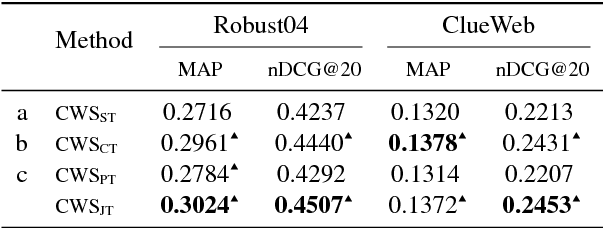
Despite the impressive improvements achieved by unsupervised deep neural networks in computer vision and NLP tasks, such improvements have not yet been observed in ranking for information retrieval. The reason may be the complexity of the ranking problem, as it is not obvious how to learn from queries and documents when no supervised signal is available. Hence, in this paper, we propose to train a neural ranking model using weak supervision, where labels are obtained automatically without human annotators or any external resources (e.g., click data). To this aim, we use the output of an unsupervised ranking model, such as BM25, as a weak supervision signal. We further train a set of simple yet effective ranking models based on feed-forward neural networks. We study their effectiveness under various learning scenarios (point-wise and pair-wise models) and using different input representations (i.e., from encoding query-document pairs into dense/sparse vectors to using word embedding representation). We train our networks using tens of millions of training instances and evaluate it on two standard collections: a homogeneous news collection(Robust) and a heterogeneous large-scale web collection (ClueWeb). Our experiments indicate that employing proper objective functions and letting the networks to learn the input representation based on weakly supervised data leads to impressive performance, with over 13% and 35% MAP improvements over the BM25 model on the Robust and the ClueWeb collections. Our findings also suggest that supervised neural ranking models can greatly benefit from pre-training on large amounts of weakly labeled data that can be easily obtained from unsupervised IR models.
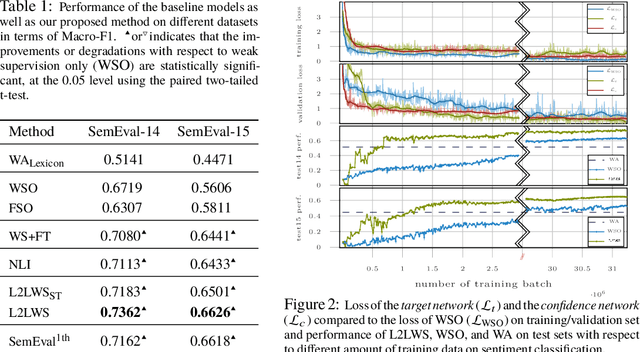
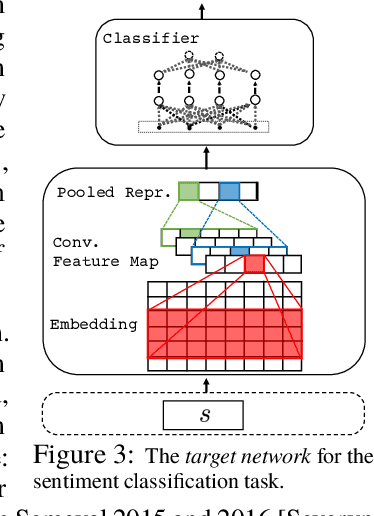
Leveraging Large Amounts of Weakly Supervised Data for Multi-Language Sentiment Classification
Mar 07, 2017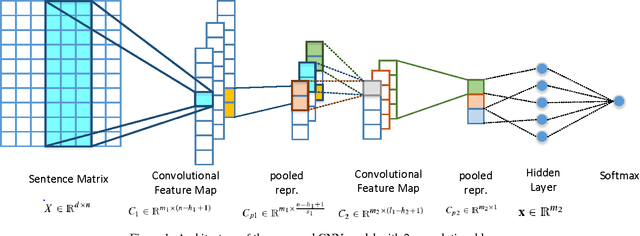
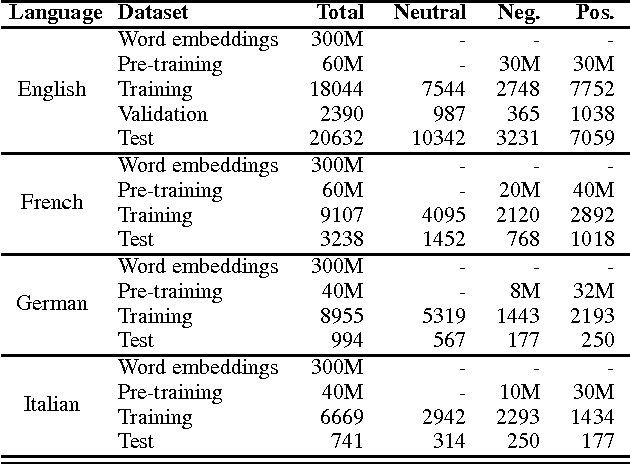
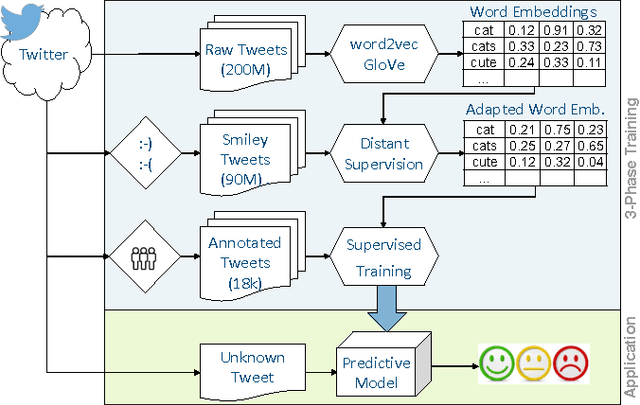
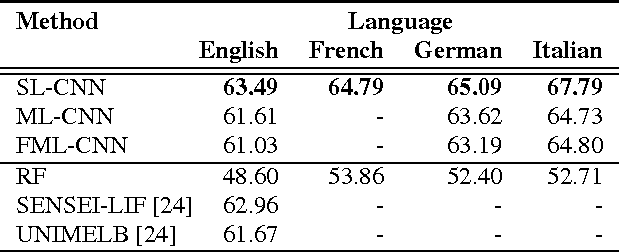
This paper presents a novel approach for multi-lingual sentiment classification in short texts. This is a challenging task as the amount of training data in languages other than English is very limited. Previously proposed multi-lingual approaches typically require to establish a correspondence to English for which powerful classifiers are already available. In contrast, our method does not require such supervision. We leverage large amounts of weakly-supervised data in various languages to train a multi-layer convolutional network and demonstrate the importance of using pre-training of such networks. We thoroughly evaluate our approach on various multi-lingual datasets, including the recent SemEval-2016 sentiment prediction benchmark (Task 4), where we achieved state-of-the-art performance. We also compare the performance of our model trained individually for each language to a variant trained for all languages at once. We show that the latter model reaches slightly worse - but still acceptable - performance when compared to the single language model, while benefiting from better generalization properties across languages.
A Hybrid Convolutional Variational Autoencoder for Text Generation
Feb 08, 2017
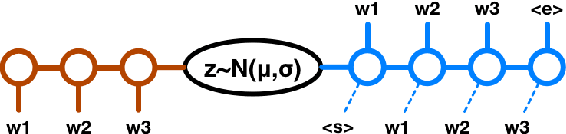
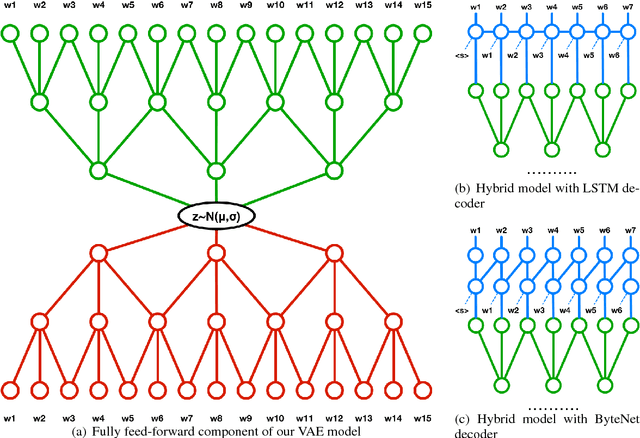

In this paper we explore the effect of architectural choices on learning a Variational Autoencoder (VAE) for text generation. In contrast to the previously introduced VAE model for text where both the encoder and decoder are RNNs, we propose a novel hybrid architecture that blends fully feed-forward convolutional and deconvolutional components with a recurrent language model. Our architecture exhibits several attractive properties such as faster run time and convergence, ability to better handle long sequences and, more importantly, it helps to avoid some of the major difficulties posed by training VAE models on textual data.
Recurrent Dropout without Memory Loss
Aug 05, 2016
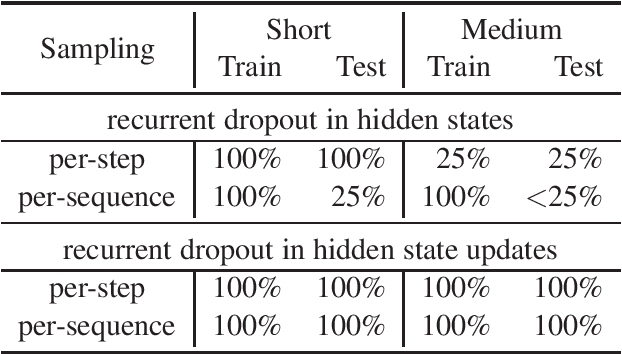
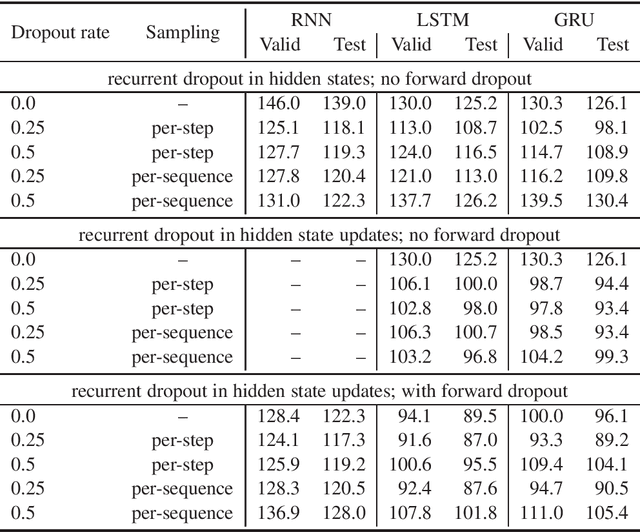
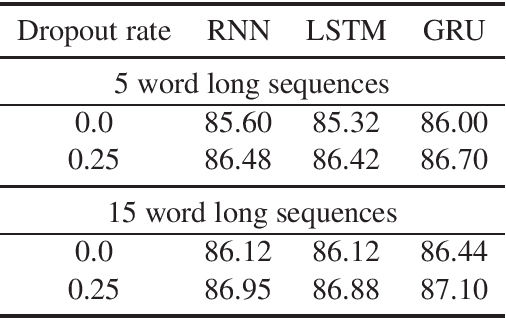
This paper presents a novel approach to recurrent neural network (RNN) regularization. Differently from the widely adopted dropout method, which is applied to \textit{forward} connections of feed-forward architectures or RNNs, we propose to drop neurons directly in \textit{recurrent} connections in a way that does not cause loss of long-term memory. Our approach is as easy to implement and apply as the regular feed-forward dropout and we demonstrate its effectiveness for Long Short-Term Memory network, the most popular type of RNN cells. Our experiments on NLP benchmarks show consistent improvements even when combined with conventional feed-forward dropout.
Globally Normalized Transition-Based Neural Networks
Jun 08, 2016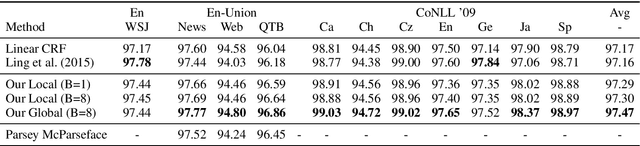
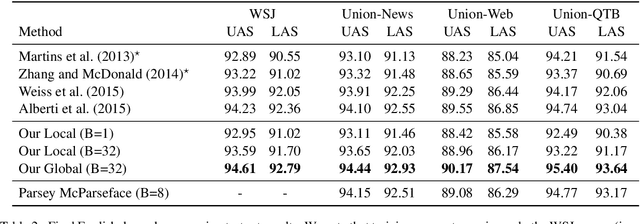
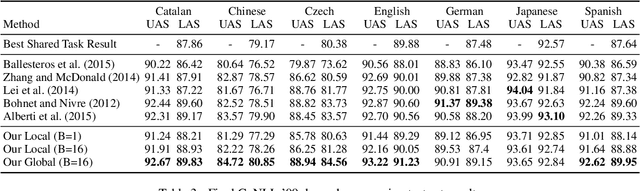
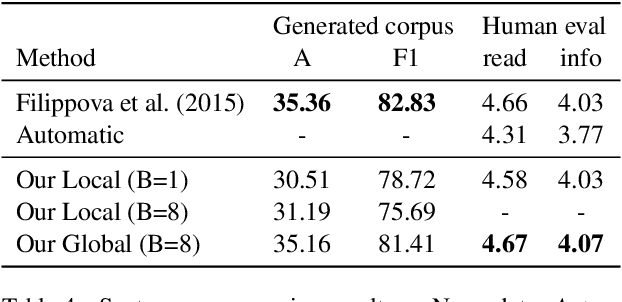
We introduce a globally normalized transition-based neural network model that achieves state-of-the-art part-of-speech tagging, dependency parsing and sentence compression results. Our model is a simple feed-forward neural network that operates on a task-specific transition system, yet achieves comparable or better accuracies than recurrent models. We discuss the importance of global as opposed to local normalization: a key insight is that the label bias problem implies that globally normalized models can be strictly more expressive than locally normalized models.
Modeling Relational Information in Question-Answer Pairs with Convolutional Neural Networks
Apr 05, 2016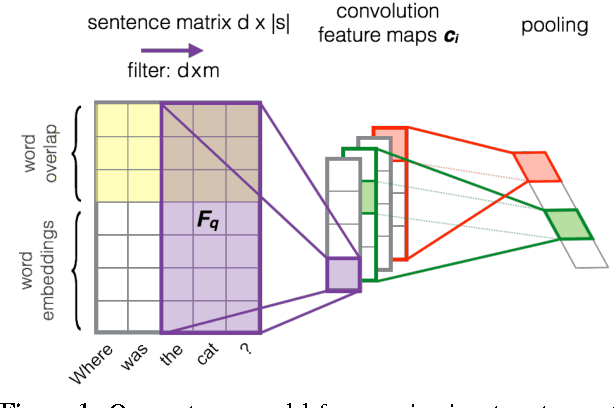
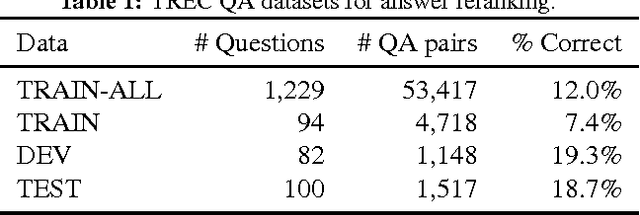
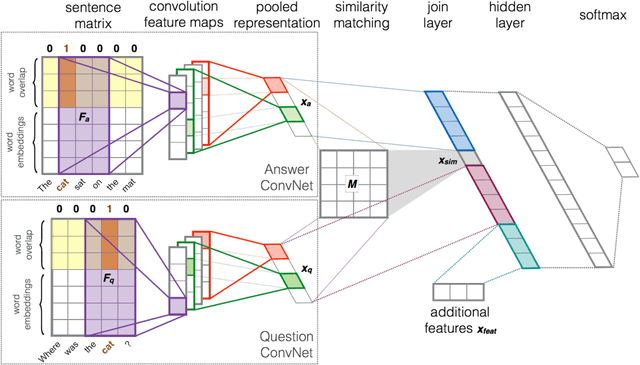
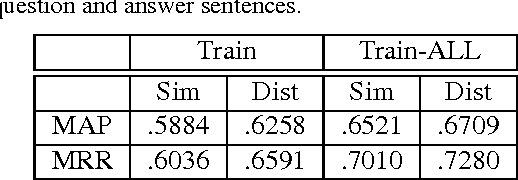
In this paper, we propose convolutional neural networks for learning an optimal representation of question and answer sentences. Their main aspect is the use of relational information given by the matches between words from the two members of the pair. The matches are encoded as embeddings with additional parameters (dimensions), which are tuned by the network. These allows for better capturing interactions between questions and answers, resulting in a significant boost in accuracy. We test our models on two widely used answer sentence selection benchmarks. The results clearly show the effectiveness of our relational information, which allows our relatively simple network to approach the state of the art.