 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransport Novelty Distance: A Distributional Metric for Evaluating Material Generative Models
Dec 10, 2025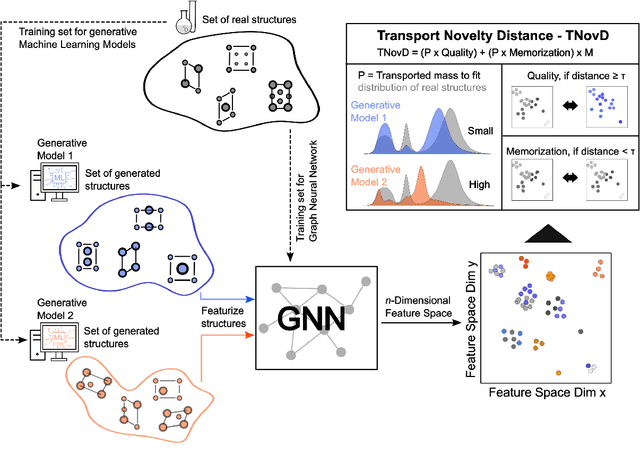
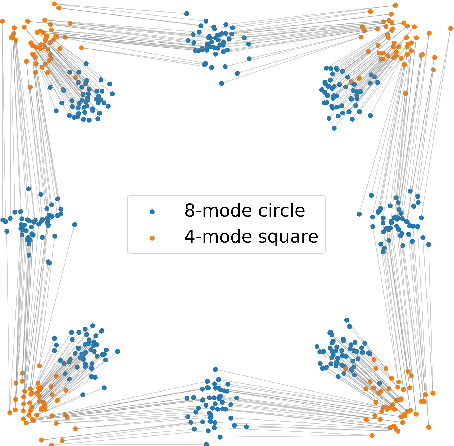
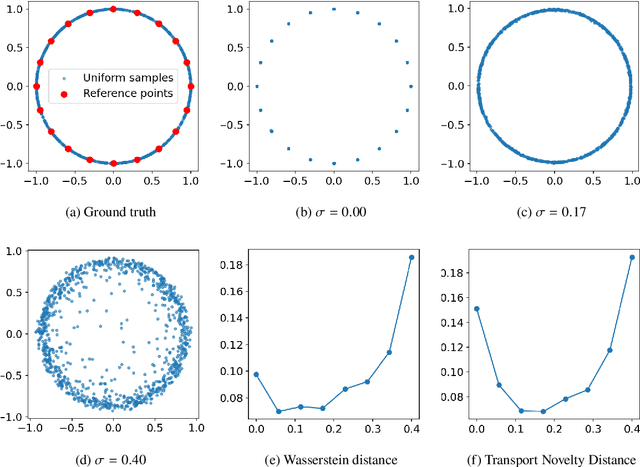
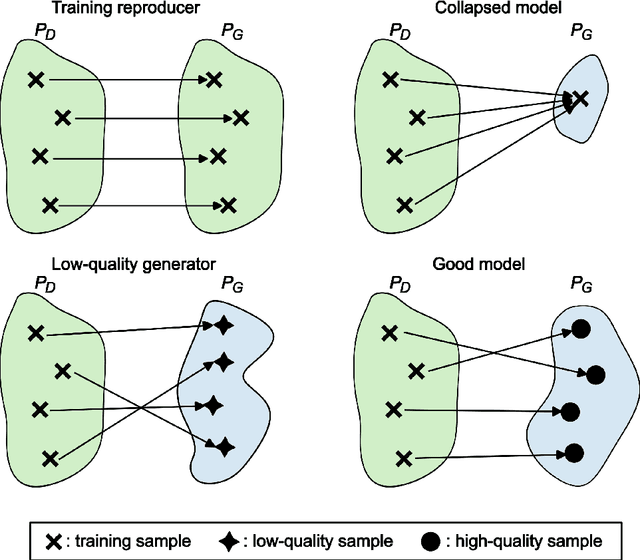
Recent advances in generative machine learning have opened new possibilities for the discovery and design of novel materials. However, as these models become more sophisticated, the need for rigorous and meaningful evaluation metrics has grown. Existing evaluation approaches often fail to capture both the quality and novelty of generated structures, limiting our ability to assess true generative performance. In this paper, we introduce the Transport Novelty Distance (TNovD) to judge generative models used for materials discovery jointly by the quality and novelty of the generated materials. Based on ideas from Optimal Transport theory, TNovD uses a coupling between the features of the training and generated sets, which is refined into a quality and memorization regime by a threshold. The features are generated from crystal structures using a graph neural network that is trained to distinguish between materials, their augmented counterparts, and differently sized supercells using contrastive learning. We evaluate our proposed metric on typical toy experiments relevant for crystal structure prediction, including memorization, noise injection and lattice deformations. Additionally, we validate the TNovD on the MP20 validation set and the WBM substitution dataset, demonstrating that it is capable of detecting both memorized and low-quality material data. We also benchmark the performance of several popular material generative models. While introduced for materials, our TNovD framework is domain-agnostic and can be adapted for other areas, such as images and molecules.
Leveraging Large Amounts of Weakly Supervised Data for Multi-Language Sentiment Classification
Mar 07, 2017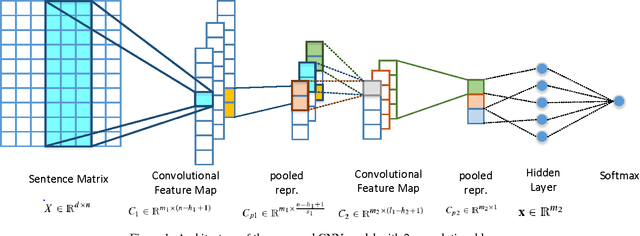
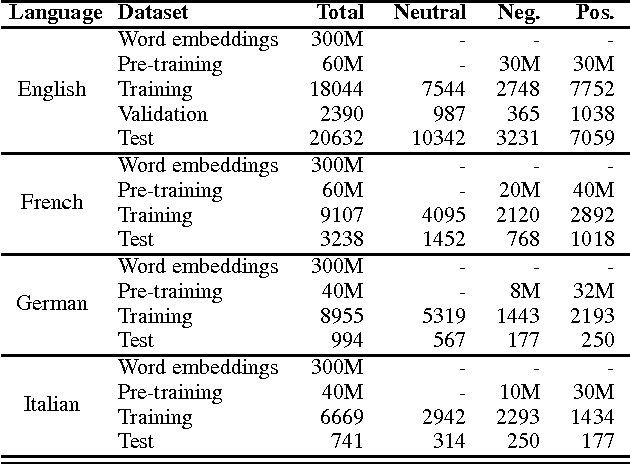
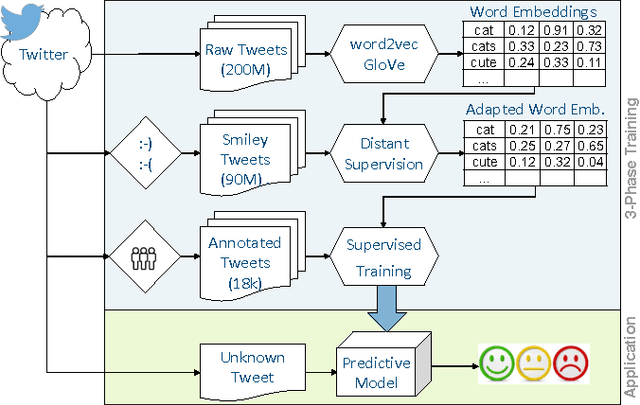
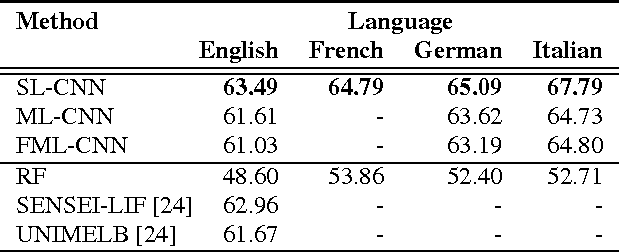
This paper presents a novel approach for multi-lingual sentiment classification in short texts. This is a challenging task as the amount of training data in languages other than English is very limited. Previously proposed multi-lingual approaches typically require to establish a correspondence to English for which powerful classifiers are already available. In contrast, our method does not require such supervision. We leverage large amounts of weakly-supervised data in various languages to train a multi-layer convolutional network and demonstrate the importance of using pre-training of such networks. We thoroughly evaluate our approach on various multi-lingual datasets, including the recent SemEval-2016 sentiment prediction benchmark (Task 4), where we achieved state-of-the-art performance. We also compare the performance of our model trained individually for each language to a variant trained for all languages at once. We show that the latter model reaches slightly worse - but still acceptable - performance when compared to the single language model, while benefiting from better generalization properties across languages.