 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Speech Recognition
May 24, 2021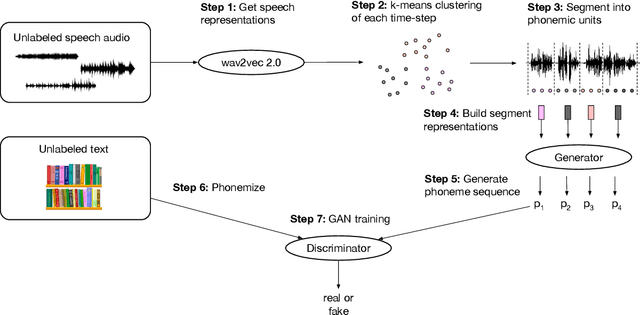

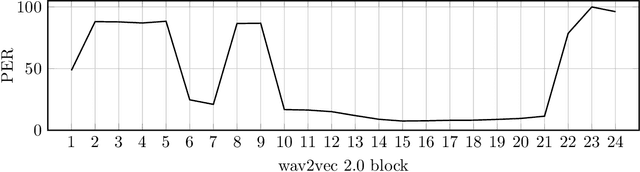
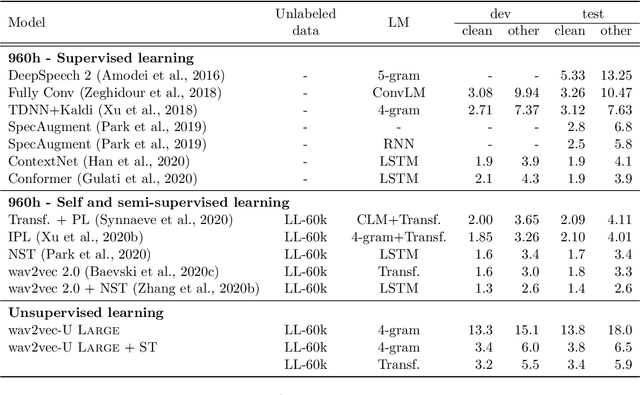
Despite rapid progress in the recent past, current speech recognition systems still require labeled training data which limits this technology to a small fraction of the languages spoken around the globe. This paper describes wav2vec-U, short for wav2vec Unsupervised, a method to train speech recognition models without any labeled data. We leverage self-supervised speech representations to segment unlabeled audio and learn a mapping from these representations to phonemes via adversarial training. The right representations are key to the success of our method. Compared to the best previous unsupervised work, wav2vec-U reduces the phoneme error rate on the TIMIT benchmark from 26.1 to 11.3. On the larger English Librispeech benchmark, wav2vec-U achieves a word error rate of 5.9 on test-other, rivaling some of the best published systems trained on 960 hours of labeled data from only two years ago. We also experiment on nine other languages, including low-resource languages such as Kyrgyz, Swahili and Tatar.
Large-Scale Self- and Semi-Supervised Learning for Speech Translation
Apr 14, 2021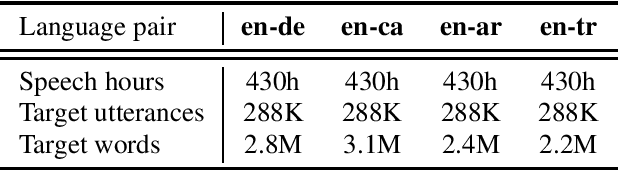
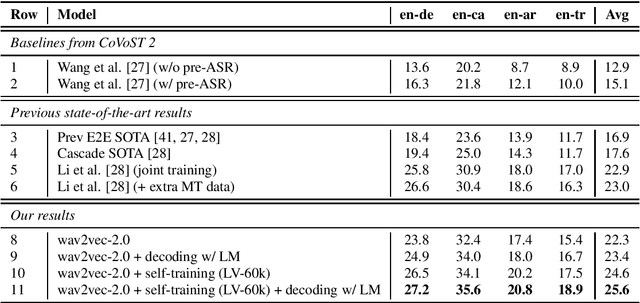

In this paper, we improve speech translation (ST) through effectively leveraging large quantities of unlabeled speech and text data in different and complementary ways. We explore both pretraining and self-training by using the large Libri-Light speech audio corpus and language modeling with CommonCrawl. Our experiments improve over the previous state of the art by 2.6 BLEU on average on all four considered CoVoST 2 language pairs via a simple recipe of combining wav2vec 2.0 pretraining, a single iteration of self-training and decoding with a language model. Different to existing work, our approach does not leverage any other supervision than ST data. Code and models will be publicly released.
Robust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-Training
Apr 02, 2021
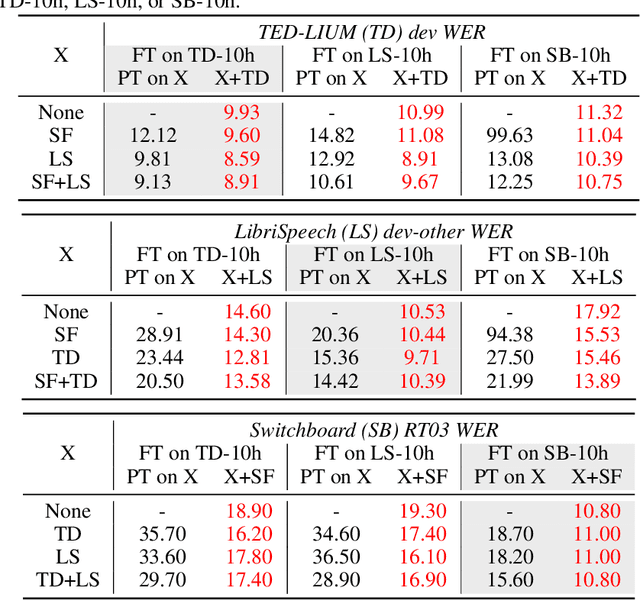
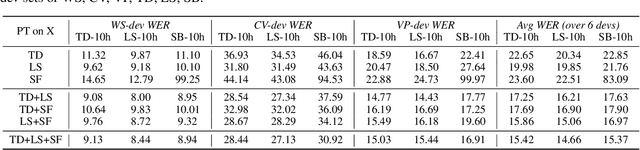
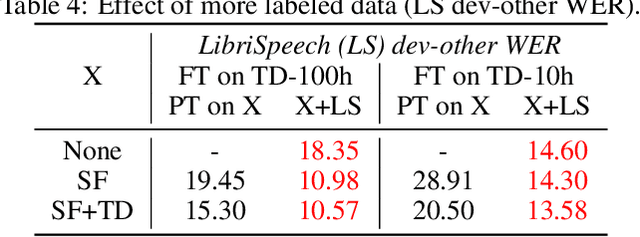
Self-supervised learning of speech representations has been a very active research area but most work is focused on a single domain such as read audio books for which there exist large quantities of labeled and unlabeled data. In this paper, we explore more general setups where the domain of the unlabeled data for pre-training data differs from the domain of the labeled data for fine-tuning, which in turn may differ from the test data domain. Our experiments show that using target domain data during pre-training leads to large performance improvements across a variety of setups. On a large-scale competitive setup, we show that pre-training on unlabeled in-domain data reduces the gap between models trained on in-domain and out-of-domain labeled data by 66%-73%. This has obvious practical implications since it is much easier to obtain unlabeled target domain data than labeled data. Moreover, we find that pre-training on multiple domains improves generalization performance on domains not seen during training. Code and models will be made available at https://github.com/pytorch/fairseq.
Generative Spoken Language Modeling from Raw Audio
Feb 01, 2021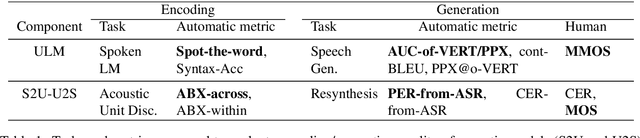
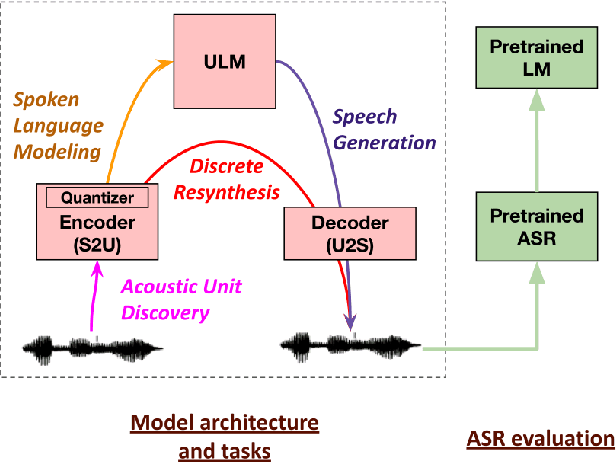
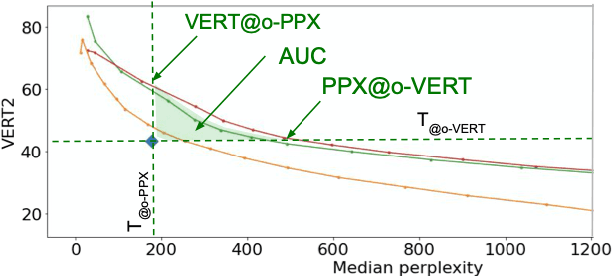
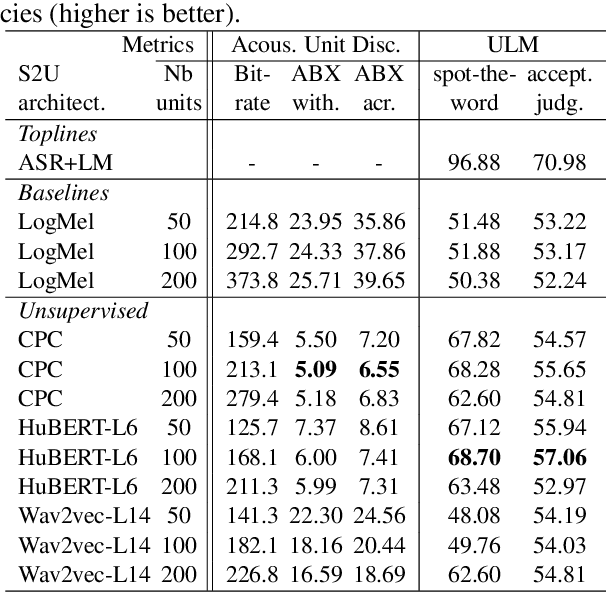
Generative spoken language modeling involves learning jointly the acoustic and linguistic characteristics of a language from raw audio only (without text or labels). We introduce metrics to automatically evaluate the generated output in terms of acoustic and linguistic quality in two associated end-to-end tasks, respectively: speech resynthesis (repeating the speech input using the system's own voice), and speech generation (producing novel speech outputs conditional on a spoken prompt, or unconditionally), and validate these metrics with human judgment. We test baseline systems consisting of a discrete speech encoder (returning discrete, low bitrate, pseudo-text units), a generative language model (trained on pseudo-text units), and a speech decoder (generating a waveform from pseudo-text). By comparing three state-of-the-art unsupervised speech encoders (Contrastive Predictive Coding (CPC), wav2vec 2.0, HuBERT), and varying the number of discrete units (50, 100, 200), we investigate how the generative performance depends on the quality of the learned units as measured by unsupervised metrics (zero-shot probe tasks). We will open source our evaluation stack and baseline models.
Reservoir Transformer
Dec 30, 2020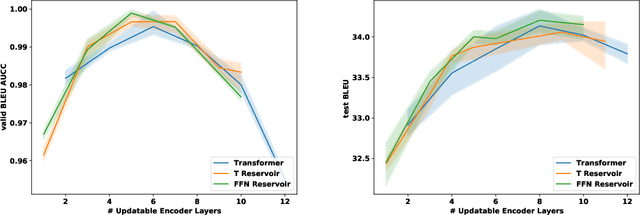
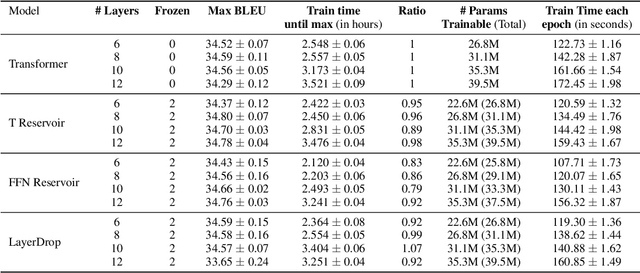
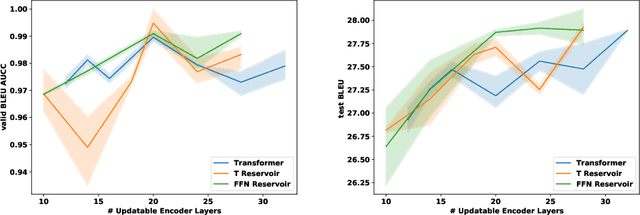
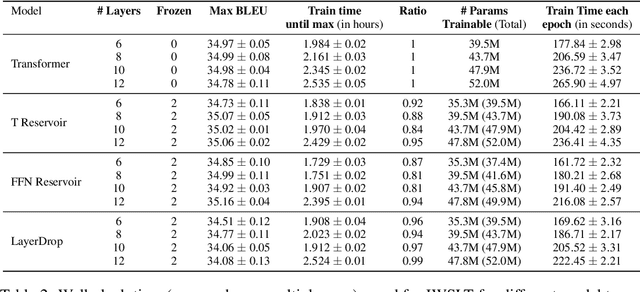
We demonstrate that transformers obtain impressive performance even when some of the layers are randomly initialized and never updated. Inspired by old and well-established ideas in machine learning, we explore a variety of non-linear "reservoir" layers interspersed with regular transformer layers, and show improvements in wall-clock compute time until convergence, as well as overall performance, on various machine translation and (masked) language modelling tasks.
The Zero Resource Speech Benchmark 2021: Metrics and baselines for unsupervised spoken language modeling
Dec 01, 2020


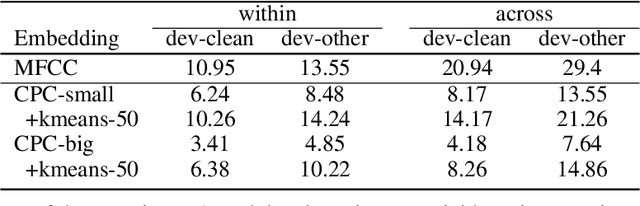
We introduce a new unsupervised task, spoken language modeling: the learning of linguistic representations from raw audio signals without any labels, along with the Zero Resource Speech Benchmark 2021: a suite of 4 black-box, zero-shot metrics probing for the quality of the learned models at 4 linguistic levels: phonetics, lexicon, syntax and semantics. We present the results and analyses of a composite baseline made of the concatenation of three unsupervised systems: self-supervised contrastive representation learning (CPC), clustering (k-means) and language modeling (LSTM or BERT). The language models learn on the basis of the pseudo-text derived from clustering the learned representations. This simple pipeline shows better than chance performance on all four metrics, demonstrating the feasibility of spoken language modeling from raw speech. It also yields worse performance compared to text-based 'topline' systems trained on the same data, delineating the space to be explored by more sophisticated end-to-end models.
A Comparison of Discrete Latent Variable Models for Speech Representation Learning
Oct 24, 2020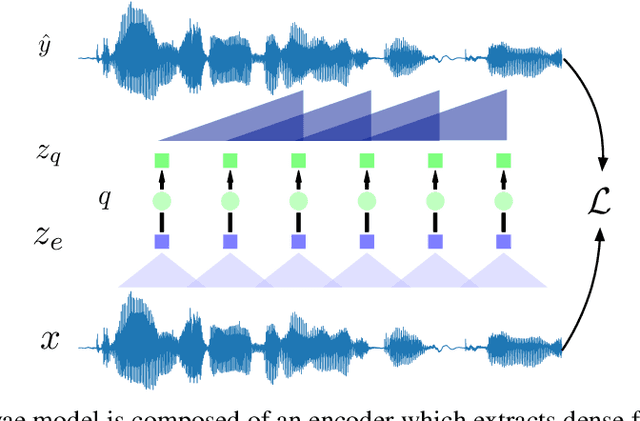
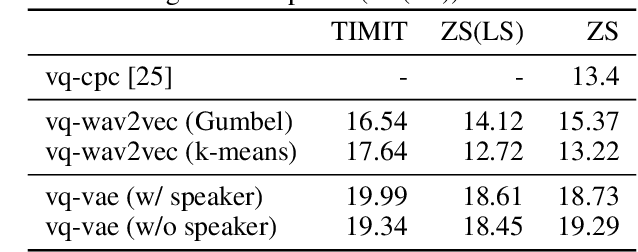
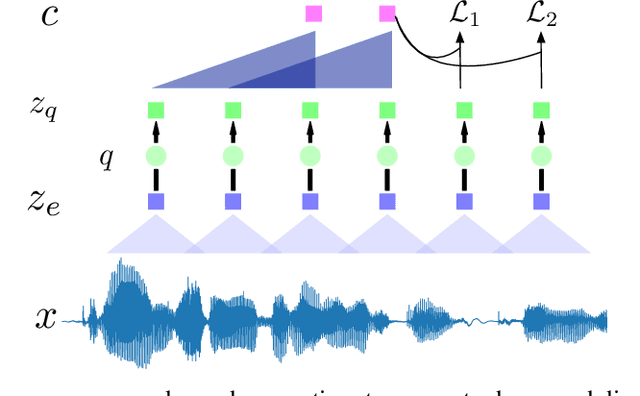
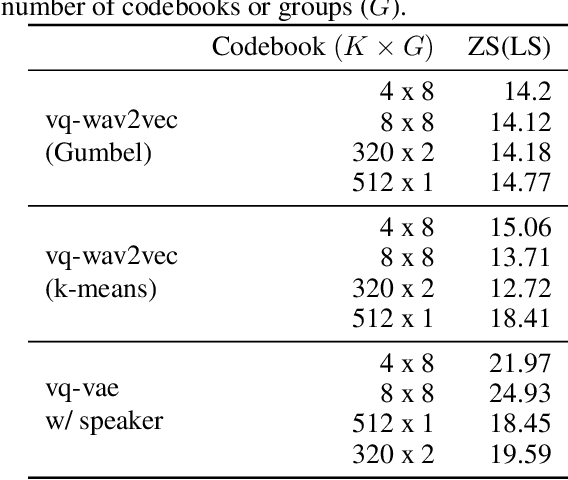
Neural latent variable models enable the discovery of interesting structure in speech audio data. This paper presents a comparison of two different approaches which are broadly based on predicting future time-steps or auto-encoding the input signal. Our study compares the representations learned by vq-vae and vq-wav2vec in terms of sub-word unit discovery and phoneme recognition performance. Results show that future time-step prediction with vq-wav2vec achieves better performance. The best system achieves an error rate of 13.22 on the ZeroSpeech 2019 ABX phoneme discrimination challenge
Self-training and Pre-training are Complementary for Speech Recognition
Oct 22, 2020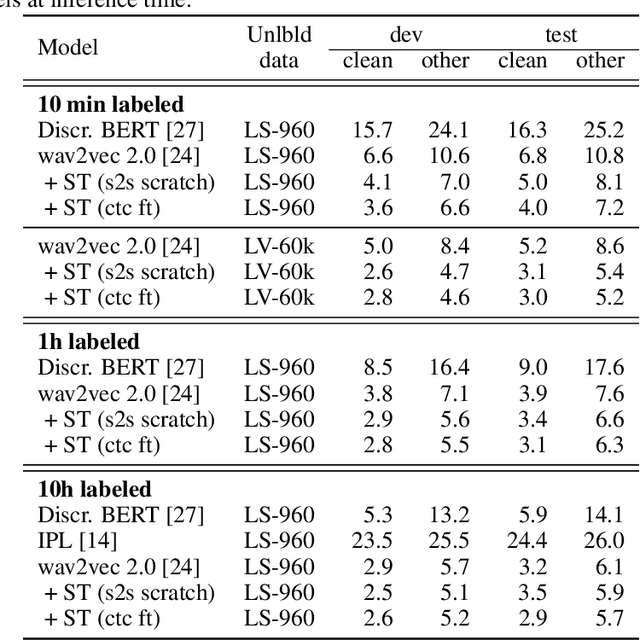
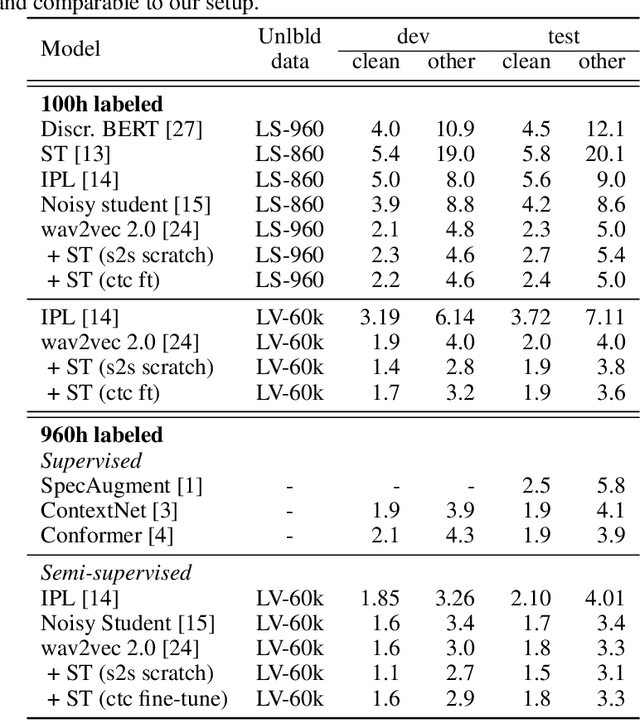
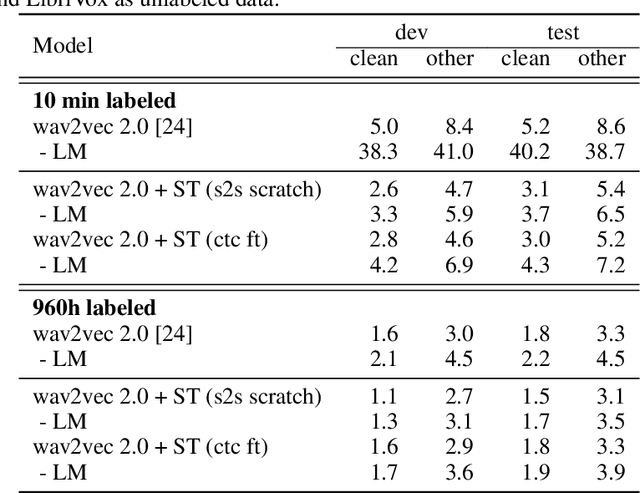
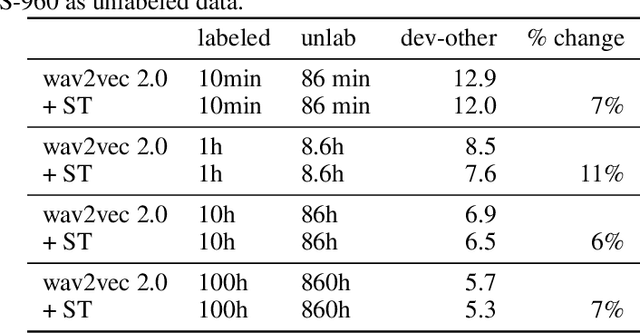
Self-training and unsupervised pre-training have emerged as effective approaches to improve speech recognition systems using unlabeled data. However, it is not clear whether they learn similar patterns or if they can be effectively combined. In this paper, we show that pseudo-labeling and pre-training with wav2vec 2.0 are complementary in a variety of labeled data setups. Using just 10 minutes of labeled data from Libri-light as well as 53k hours of unlabeled data from LibriVox achieves WERs of 3.0%/5.2% on the clean and other test sets of Librispeech - rivaling the best published systems trained on 960 hours of labeled data only a year ago. Training on all labeled data of Librispeech achieves WERs of 1.5%/3.1%.
Unsupervised Cross-lingual Representation Learning for Speech Recognition
Jun 24, 2020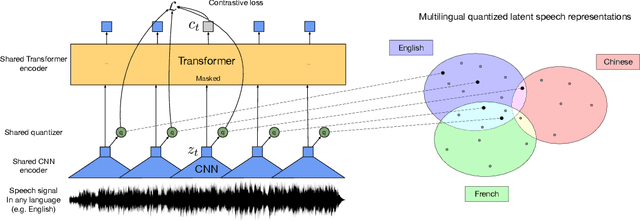
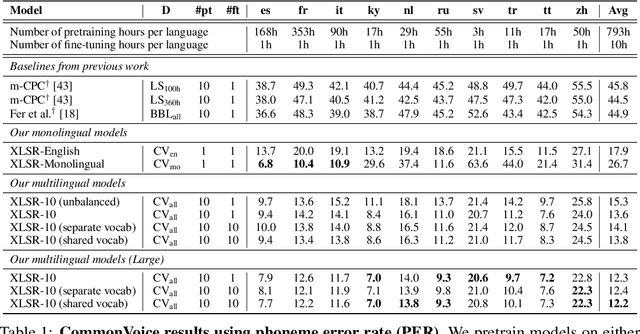
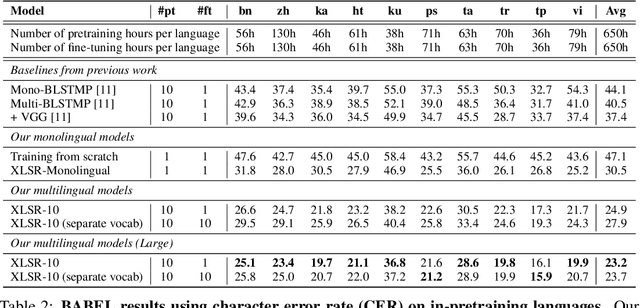
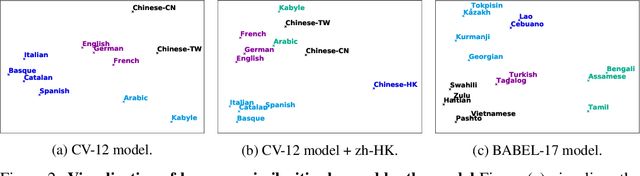
This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw waveform of speech in multiple languages. We build on a concurrently introduced self-supervised model which is trained by solving a contrastive task over masked latent speech representations and jointly learns a quantization of the latents shared across languages. The resulting model is fine-tuned on labeled data and experiments show that cross-lingual pretraining significantly outperforms monolingual pretraining. On the CommonVoice benchmark, XLSR shows a relative phoneme error rate reduction of 72% compared to the best known results. On BABEL, our approach improves word error rate by 16% relative compared to the strongest comparable system. Our approach enables a single multilingual speech recognition model which is competitive to strong individual models. Analysis shows that the latent discrete speech representations are shared across languages with increased sharing for related languages.
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
Jun 20, 2020
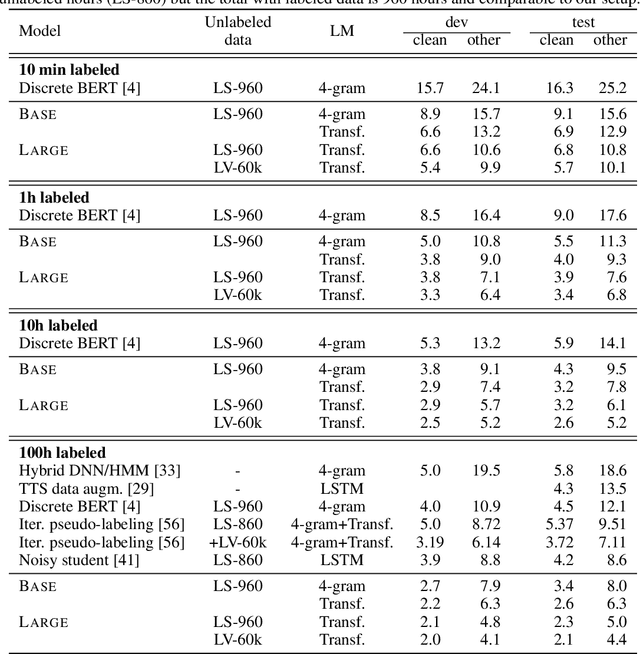
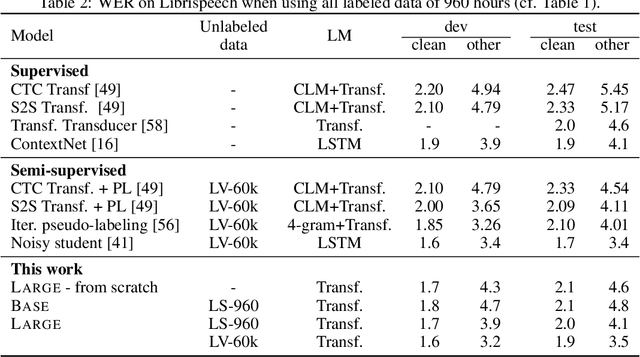
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. We set a new state of the art on both the 100 hour subset of Librispeech as well as on TIMIT phoneme recognition. When lowering the amount of labeled data to one hour, our model outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 5.7/10.1 WER on the noisy/clean test sets of Librispeech. This demonstrates the feasibility of speech recognition with limited amounts of labeled data. Fine-tuning on all of Librispeech achieves 1.9/3.5 WER using a simple baseline model architecture. We will release code and models.