 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple but Hard-to-Beat Baseline for Session-based Recommendations
Aug 30, 2018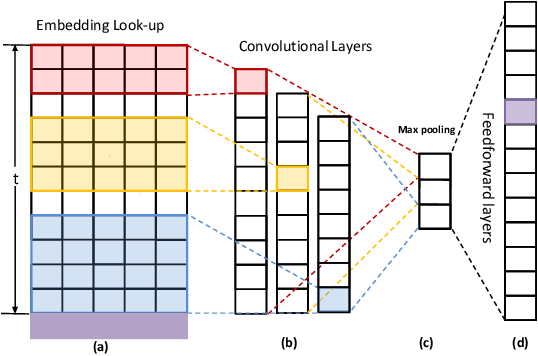

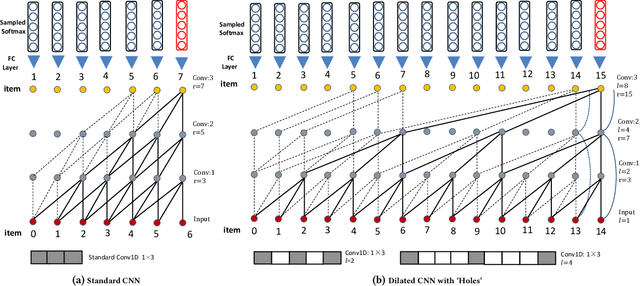
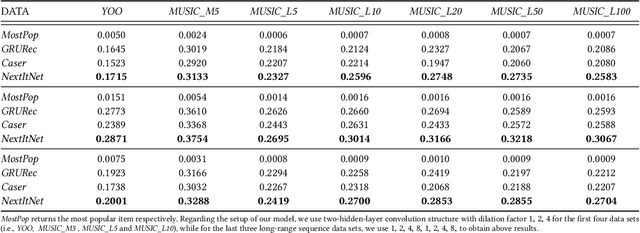
Convolutional Neural Networks (CNNs) models have been recently introduced in the domain of top-$N$ session-based recommendations. An ordered collection of past items the user has interacted with in a session (or sequence) are embedded into a 2-dimensional latent matrix, and treated as an image. The convolution and pooling operations are then applied to the mapped item embeddings. In this paper, we first examine the typical session-based CNN recommender and show that both the generative model and network architecture are suboptimal when modeling long-range dependencies in the item sequence. To address the issues, we propose a simple, but very effective generative model that is capable of learning high-level representation from both short- and long-range dependencies. The network architecture of the proposed model is formed of a stack of holed convolutional layers, which can efficiently increase the receptive fields without relying on the pooling operation. Another contribution is the effective use of residual block structure in recommender systems, which can ease the optimization for much deeper networks. The proposed generative model attains state-of-the-art accuracy with less training time in the session-based recommendation task. It accordingly can be used as a powerful session-based recommendation baseline to beat in future, especially when there are long sequences of user feedback.
Recurrent Neural Networks with Top-k Gains for Session-based Recommendations
Aug 28, 2018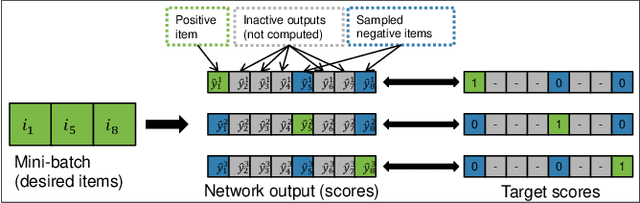
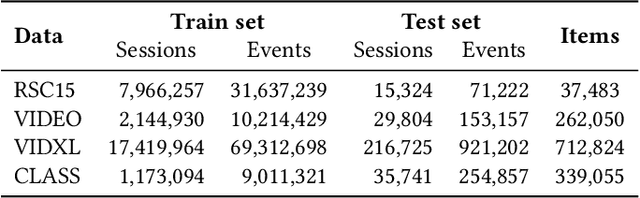
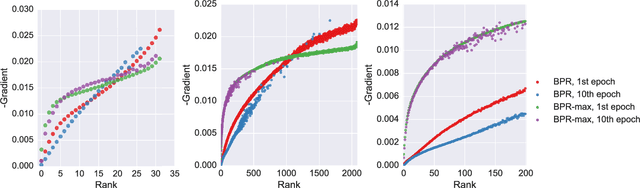
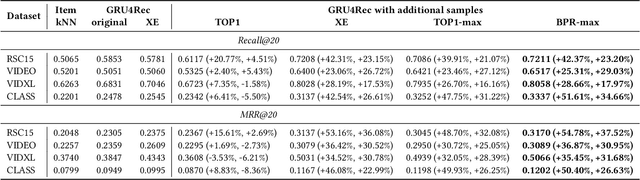
RNNs have been shown to be excellent models for sequential data and in particular for data that is generated by users in an session-based manner. The use of RNNs provides impressive performance benefits over classical methods in session-based recommendations. In this work we introduce novel ranking loss functions tailored to RNNs in the recommendation setting. The improved performance of these losses over alternatives, along with further tricks and refinements described in this work, allow for an overall improvement of up to 35% in terms of MRR and Recall@20 over previous session-based RNN solutions and up to 53% over classical collaborative filtering approaches. Unlike data augmentation-based improvements, our method does not increase training times significantly. We further demonstrate the performance gain of the RNN over baselines in an online A/B test.
Overcoming catastrophic forgetting with hard attention to the task
May 29, 2018
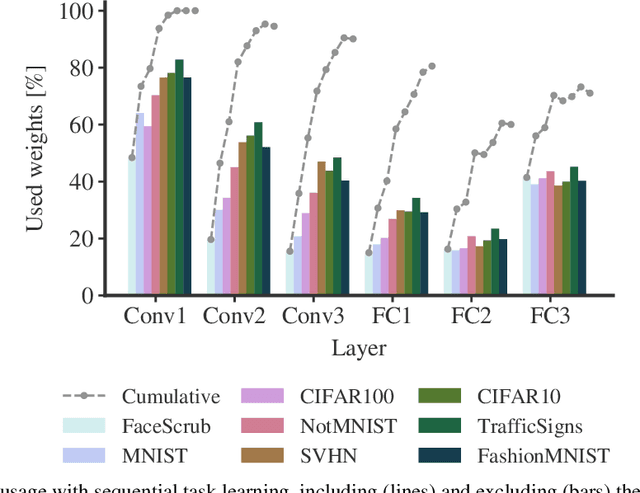
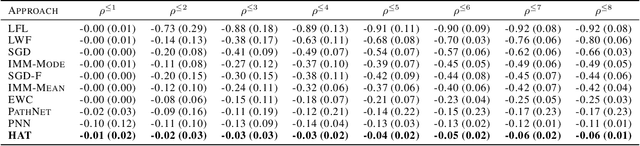
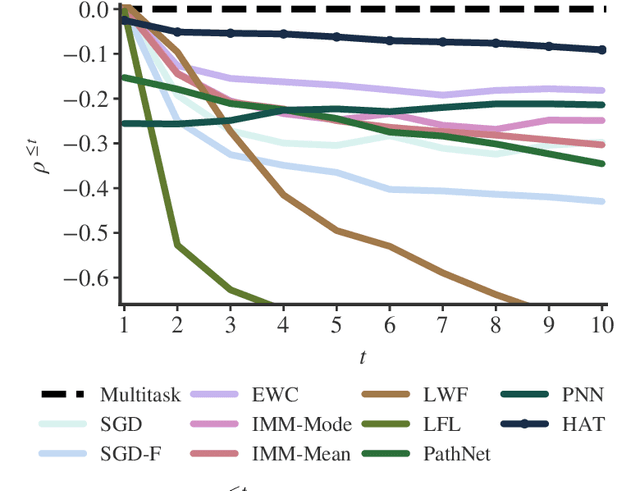
Catastrophic forgetting occurs when a neural network loses the information learned in a previous task after training on subsequent tasks. This problem remains a hurdle for artificial intelligence systems with sequential learning capabilities. In this paper, we propose a task-based hard attention mechanism that preserves previous tasks' information without affecting the current task's learning. A hard attention mask is learned concurrently to every task, through stochastic gradient descent, and previous masks are exploited to condition such learning. We show that the proposed mechanism is effective for reducing catastrophic forgetting, cutting current rates by 45 to 80%. We also show that it is robust to different hyperparameter choices, and that it offers a number of monitoring capabilities. The approach features the possibility to control both the stability and compactness of the learned knowledge, which we believe makes it also attractive for online learning or network compression applications.
Towards a universal neural network encoder for time series
May 10, 2018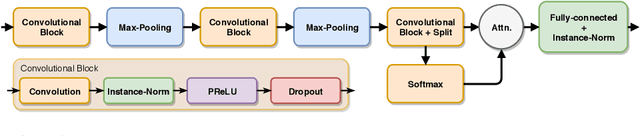
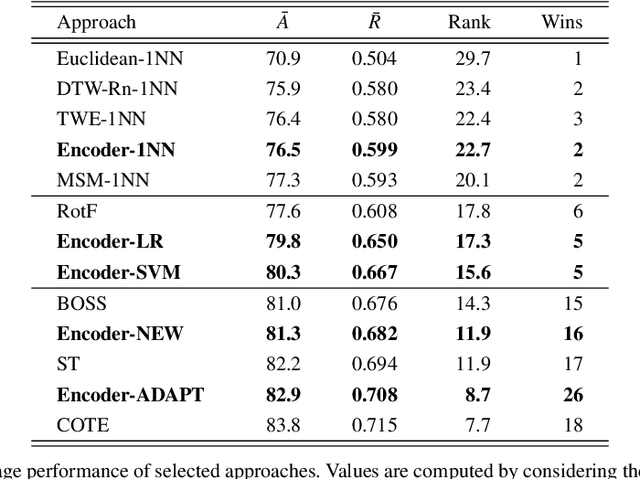
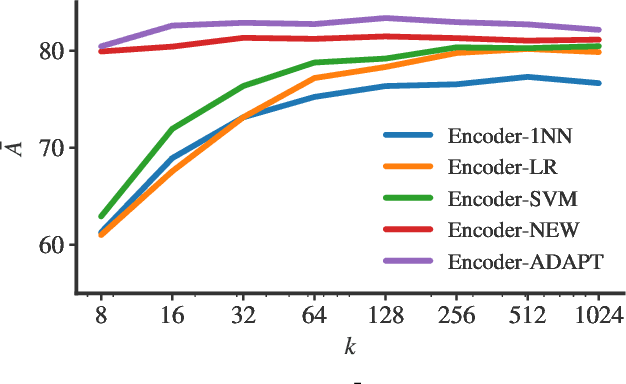
We study the use of a time series encoder to learn representations that are useful on data set types with which it has not been trained on. The encoder is formed of a convolutional neural network whose temporal output is summarized by a convolutional attention mechanism. This way, we obtain a compact, fixed-length representation from longer, variable-length time series. We evaluate the performance of the proposed approach on a well-known time series classification benchmark, considering full adaptation, partial adaptation, and no adaptation of the encoder to the new data type. Results show that such strategies are competitive with the state-of-the-art, often outperforming conceptually-matching approaches. Besides accuracy scores, the facility of adaptation and the efficiency of pre-trained encoders make them an appealing option for the processing of scarcely- or non-labeled time series.
Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks
Aug 23, 2017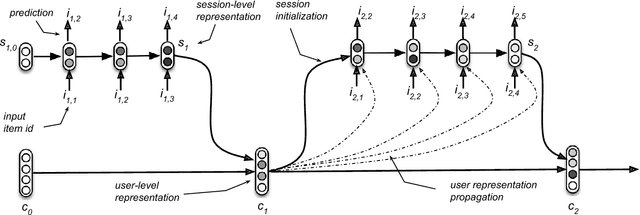
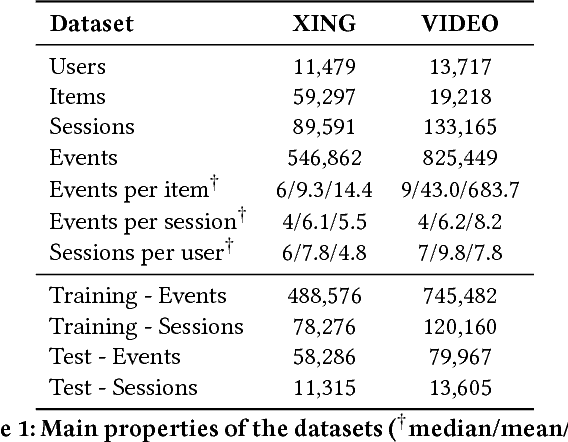
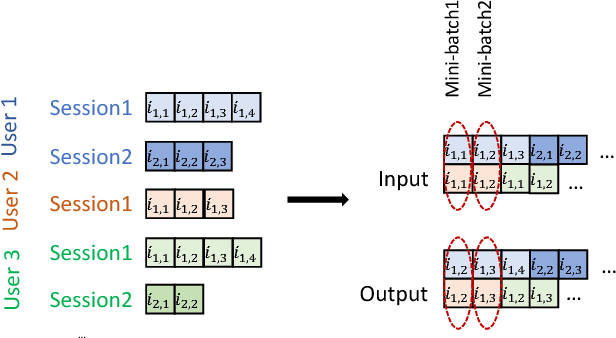
Session-based recommendations are highly relevant in many modern on-line services (e.g. e-commerce, video streaming) and recommendation settings. Recently, Recurrent Neural Networks have been shown to perform very well in session-based settings. While in many session-based recommendation domains user identifiers are hard to come by, there are also domains in which user profiles are readily available. We propose a seamless way to personalize RNN models with cross-session information transfer and devise a Hierarchical RNN model that relays end evolves latent hidden states of the RNNs across user sessions. Results on two industry datasets show large improvements over the session-only RNNs.
Getting deep recommenders fit: Bloom embeddings for sparse binary input/output networks
Jun 13, 2017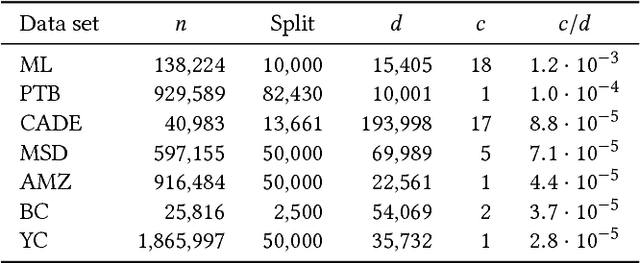
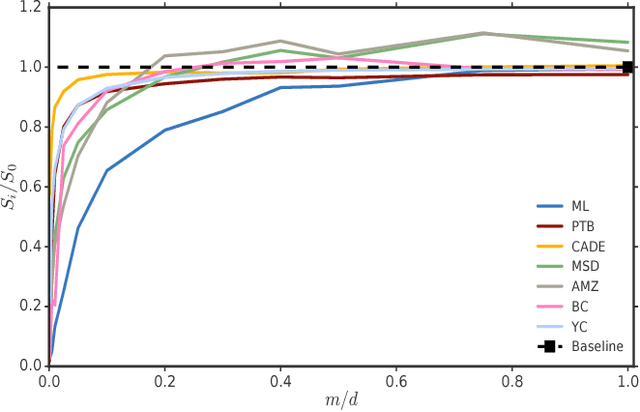
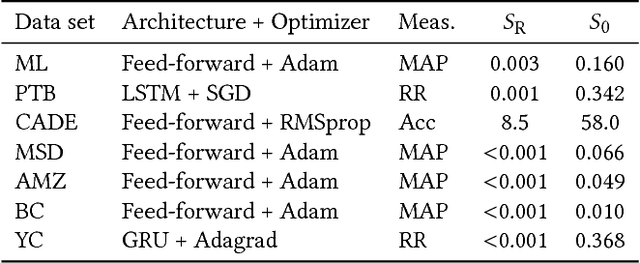
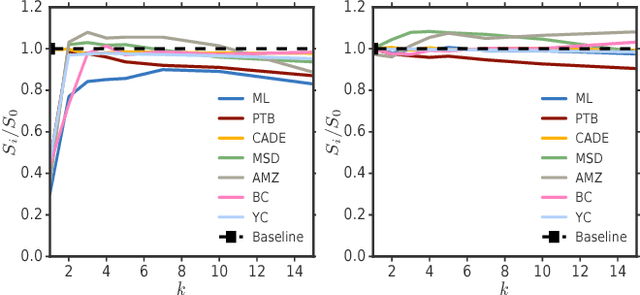
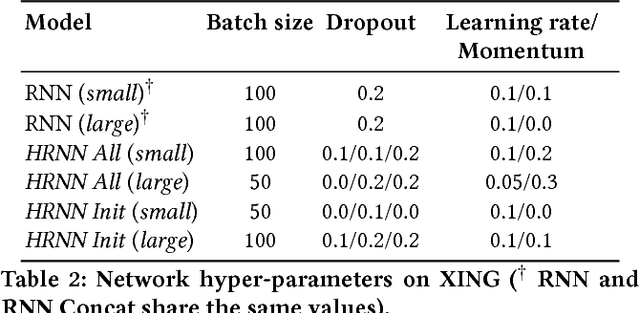
Recommendation algorithms that incorporate techniques from deep learning are becoming increasingly popular. Due to the structure of the data coming from recommendation domains (i.e., one-hot-encoded vectors of item preferences), these algorithms tend to have large input and output dimensionalities that dominate their overall size. This makes them difficult to train, due to the limited memory of graphical processing units, and difficult to deploy on mobile devices with limited hardware. To address these difficulties, we propose Bloom embeddings, a compression technique that can be applied to the input and output of neural network models dealing with sparse high-dimensional binary-coded instances. Bloom embeddings are computationally efficient, and do not seriously compromise the accuracy of the model up to 1/5 compression ratios. In some cases, they even improve over the original accuracy, with relative increases up to 12%. We evaluate Bloom embeddings on 7 data sets and compare it against 4 alternative methods, obtaining favorable results. We also discuss a number of further advantages of Bloom embeddings, such as 'on-the-fly' constant-time operation, zero or marginal space requirements, training time speedups, or the fact that they do not require any change to the core model architecture or training configuration.
Hot or not? Forecasting cellular network hot spots using sector performance indicators
Apr 18, 2017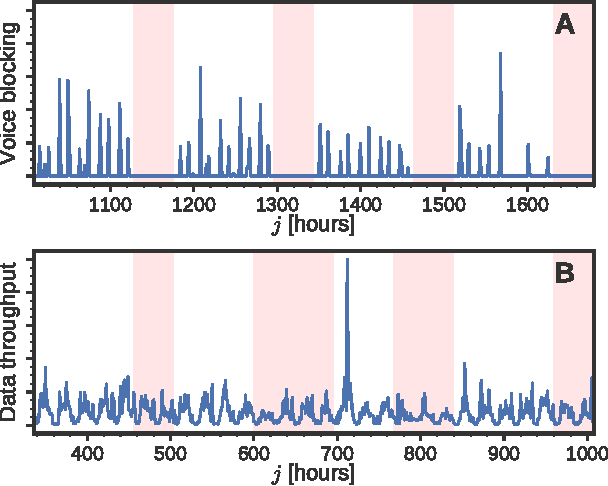
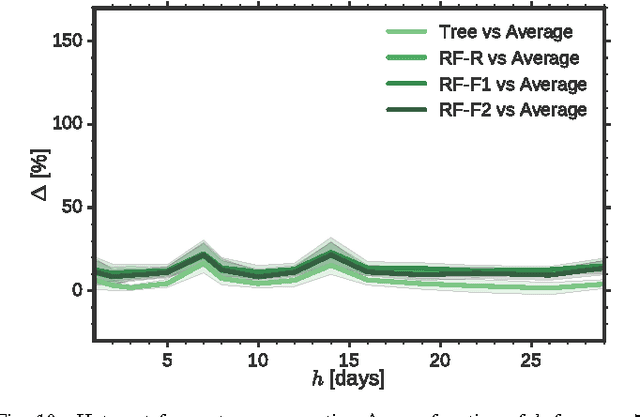
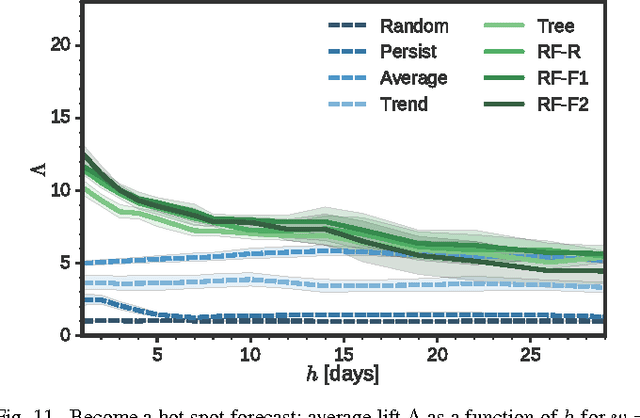
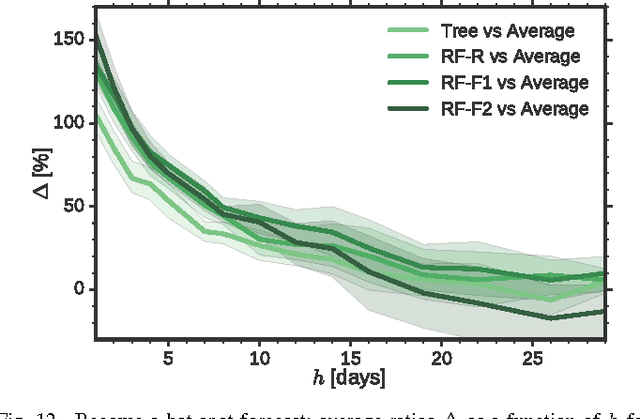
To manage and maintain large-scale cellular networks, operators need to know which sectors underperform at any given time. For this purpose, they use the so-called hot spot score, which is the result of a combination of multiple network measurements and reflects the instantaneous overall performance of individual sectors. While operators have a good understanding of the current performance of a network and its overall trend, forecasting the performance of each sector over time is a challenging task, as it is affected by both regular and non-regular events, triggered by human behavior and hardware failures. In this paper, we study the spatio-temporal patterns of the hot spot score and uncover its regularities. Based on our observations, we then explore the possibility to use recent measurements' history to predict future hot spots. To this end, we consider tree-based machine learning models, and study their performance as a function of time, amount of past data, and prediction horizon. Our results indicate that, compared to the best baseline, tree-based models can deliver up to 14% better forecasts for regular hot spots and 153% better forecasts for non-regular hot spots. The latter brings strong evidence that, for moderate horizons, forecasts can be made even for sectors exhibiting isolated, non-regular behavior. Overall, our work provides insight into the dynamics of cellular sectors and their predictability. It also paves the way for more proactive network operations with greater forecasting horizons.
On Context-Dependent Clustering of Bandits
Feb 27, 2017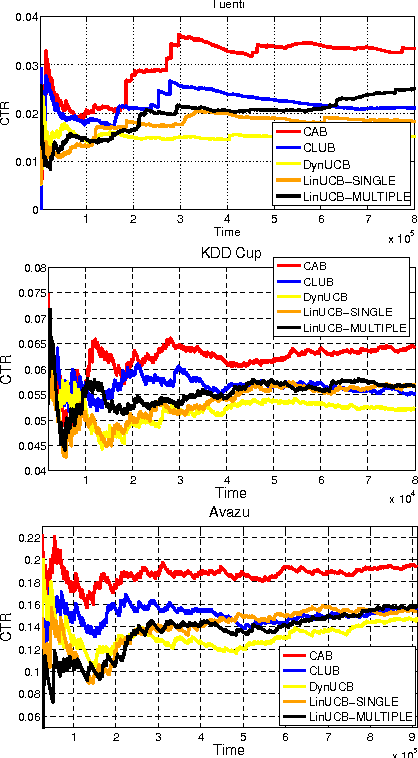
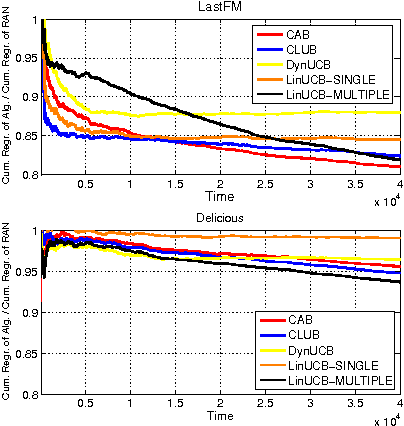
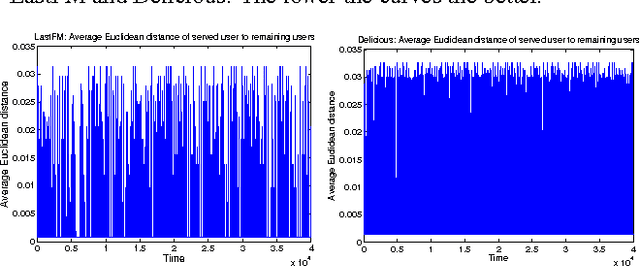
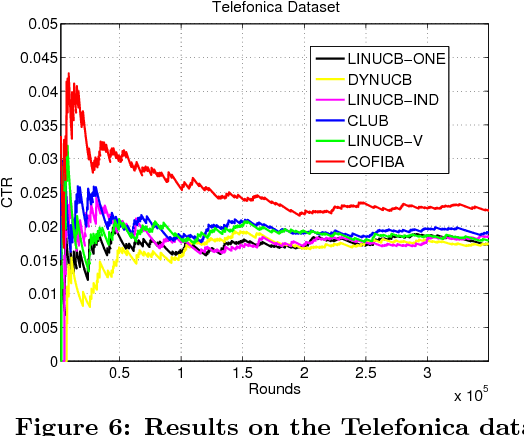
We investigate a novel cluster-of-bandit algorithm CAB for collaborative recommendation tasks that implements the underlying feedback sharing mechanism by estimating the neighborhood of users in a context-dependent manner. CAB makes sharp departures from the state of the art by incorporating collaborative effects into inference as well as learning processes in a manner that seamlessly interleaving explore-exploit tradeoffs and collaborative steps. We prove regret bounds under various assumptions on the data, which exhibit a crisp dependence on the expected number of clusters over the users, a natural measure of the statistical difficulty of the learning task. Experiments on production and real-world datasets show that CAB offers significantly increased prediction performance against a representative pool of state-of-the-art methods.
A genetic algorithm to discover flexible motifs with support
Dec 05, 2016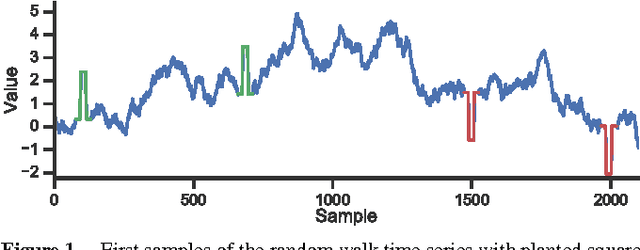
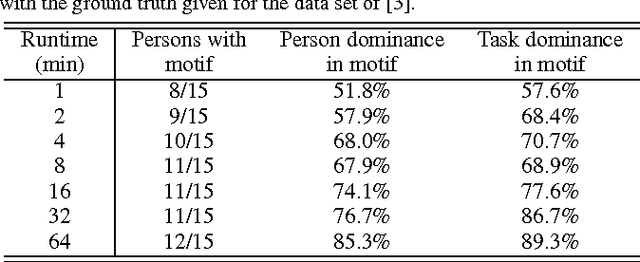
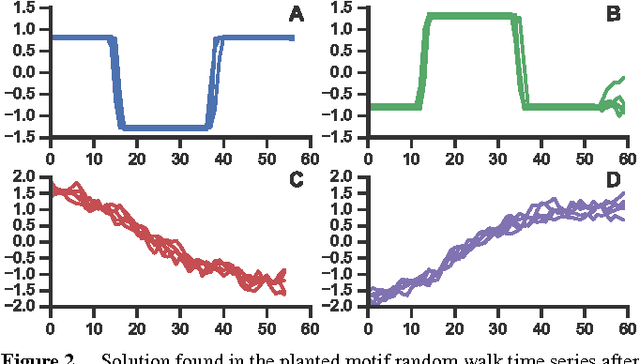
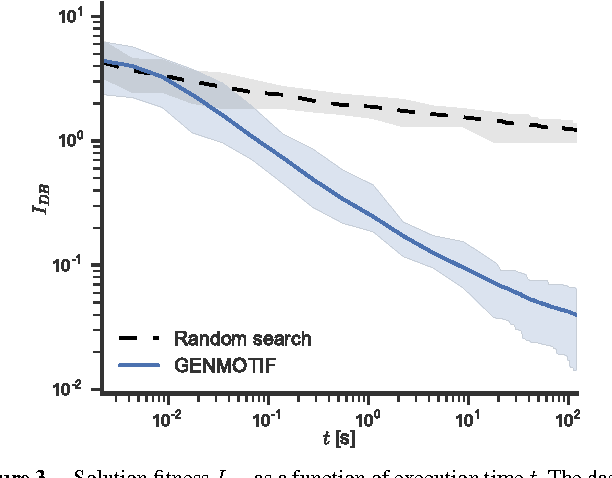
Finding repeated patterns or motifs in a time series is an important unsupervised task that has still a number of open issues, starting by the definition of motif. In this paper, we revise the notion of motif support, characterizing it as the number of patterns or repetitions that define a motif. We then propose GENMOTIF, a genetic algorithm to discover motifs with support which, at the same time, is flexible enough to accommodate other motif specifications and task characteristics. GENMOTIF is an anytime algorithm that easily adapts to many situations: searching in a range of segment lengths, applying uniform scaling, dealing with multiple dimensions, using different similarity and grouping criteria, etc. GENMOTIF is also parameter-friendly: it has only two intuitive parameters which, if set within reasonable bounds, do not substantially affect its performance. We demonstrate the value of our approach in a number of synthetic and real-world settings, considering traffic volume measurements, accelerometer signals, and telephone call records.
Collaborative Filtering Bandits
May 31, 2016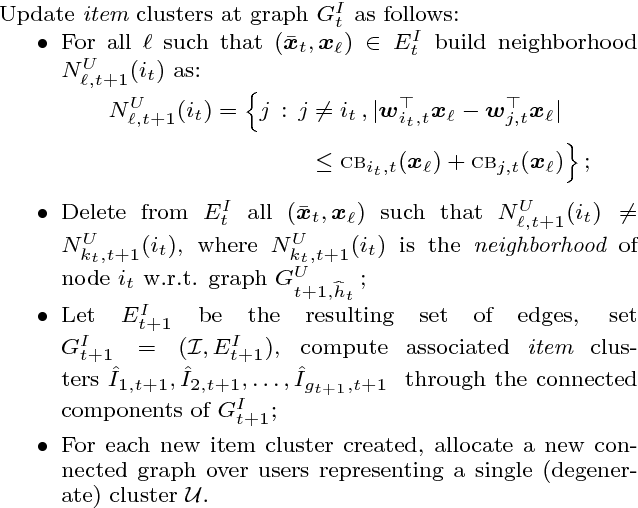
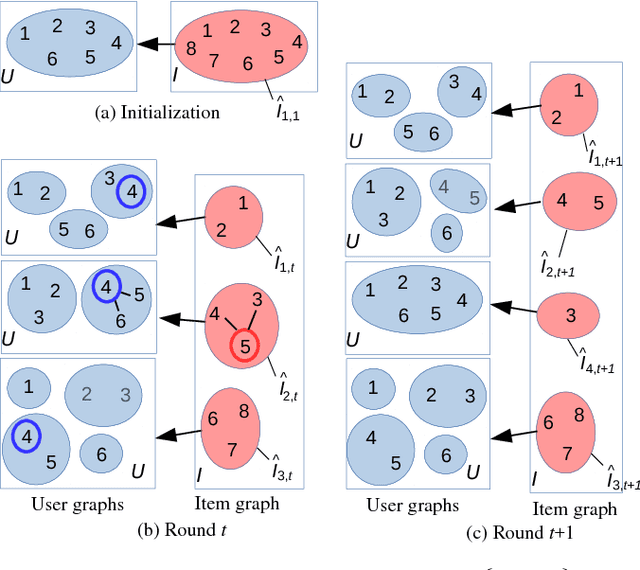
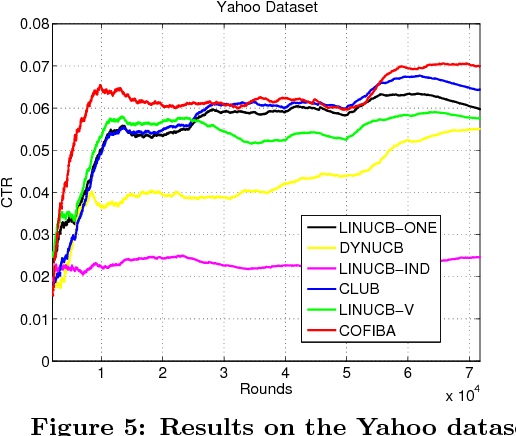
Classical collaborative filtering, and content-based filtering methods try to learn a static recommendation model given training data. These approaches are far from ideal in highly dynamic recommendation domains such as news recommendation and computational advertisement, where the set of items and users is very fluid. In this work, we investigate an adaptive clustering technique for content recommendation based on exploration-exploitation strategies in contextual multi-armed bandit settings. Our algorithm takes into account the collaborative effects that arise due to the interaction of the users with the items, by dynamically grouping users based on the items under consideration and, at the same time, grouping items based on the similarity of the clusterings induced over the users. The resulting algorithm thus takes advantage of preference patterns in the data in a way akin to collaborative filtering methods. We provide an empirical analysis on medium-size real-world datasets, showing scalability and increased prediction performance (as measured by click-through rate) over state-of-the-art methods for clustering bandits. We also provide a regret analysis within a standard linear stochastic noise setting.