 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimal-Dual Block Frank-Wolfe
Jun 06, 2019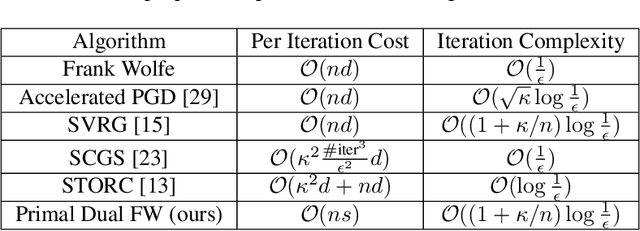
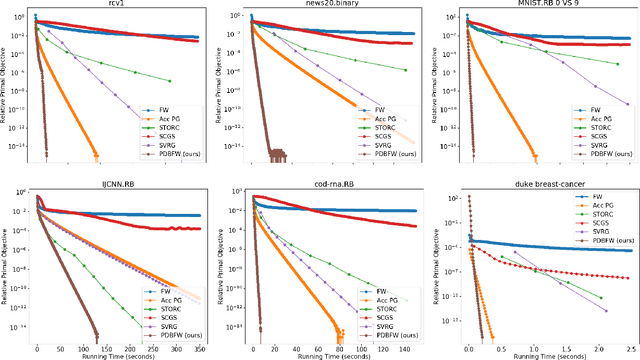
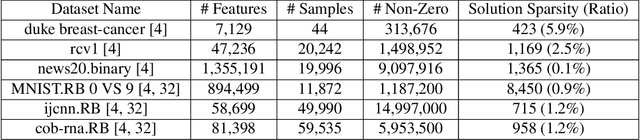
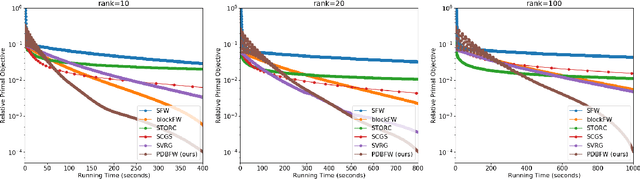
We propose a variant of the Frank-Wolfe algorithm for solving a class of sparse/low-rank optimization problems. Our formulation includes Elastic Net, regularized SVMs and phase retrieval as special cases. The proposed Primal-Dual Block Frank-Wolfe algorithm reduces the per-iteration cost while maintaining linear convergence rate. The per iteration cost of our method depends on the structural complexity of the solution (i.e. sparsity/low-rank) instead of the ambient dimension. We empirically show that our algorithm outperforms the state-of-the-art methods on (multi-class) classification tasks.
One-dimensional Deep Image Prior for Time Series Inverse Problems
Apr 18, 2019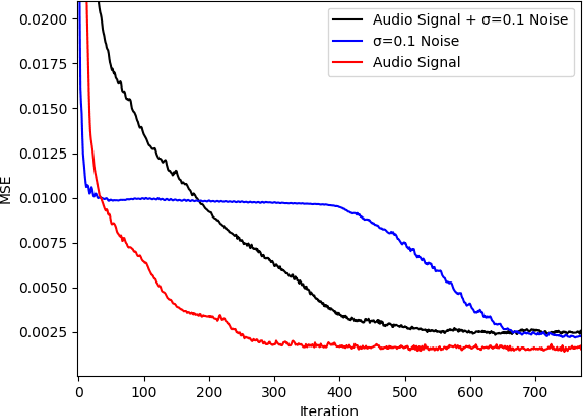
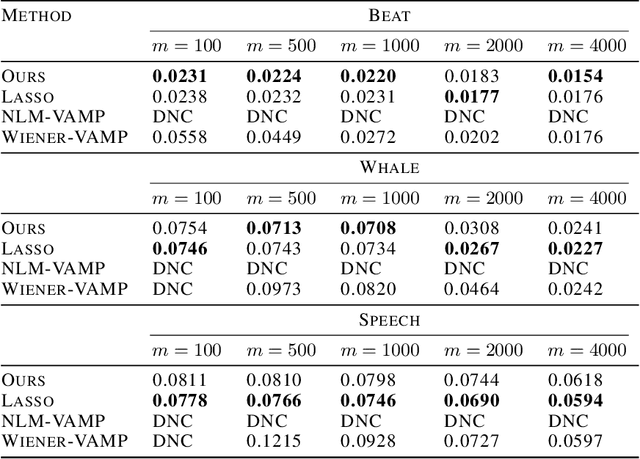
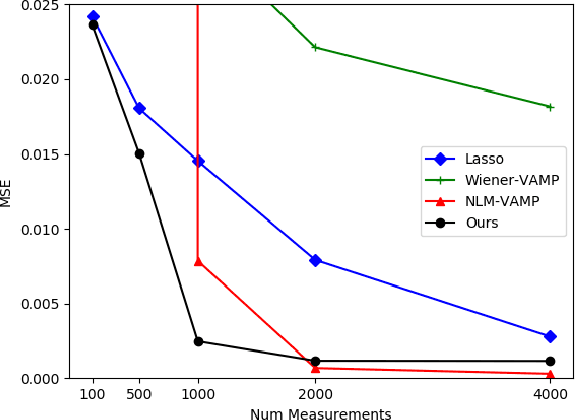

We extend the Deep Image Prior (DIP) framework to one-dimensional signals. DIP is using a randomly initialized convolutional neural network (CNN) to solve linear inverse problems by optimizing over weights to fit the observed measurements. Our main finding is that properly tuned one-dimensional convolutional architectures provide an excellent Deep Image Prior for various types of temporal signals including audio, biological signals, and sensor measurements. We show that our network can be used in a variety of recovery tasks including missing value imputation, blind denoising, and compressed sensing from random Gaussian projections. The key challenge is how to avoid overfitting by carefully tuning early stopping, total variation, and weight decay regularization. Our method requires up to 4 times fewer measurements than Lasso and outperforms NLM-VAMP for random Gaussian measurements on audio signals, has similar imputation performance to a Kalman state-space model on a variety of data, and outperforms wavelet filtering in removing additive noise from air-quality sensor readings.
Provable Certificates for Adversarial Examples: Fitting a Ball in the Union of Polytopes
Mar 20, 2019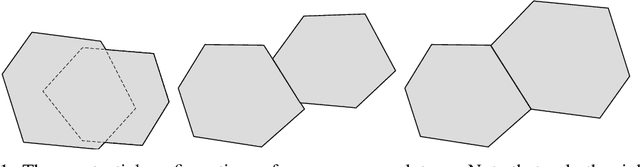
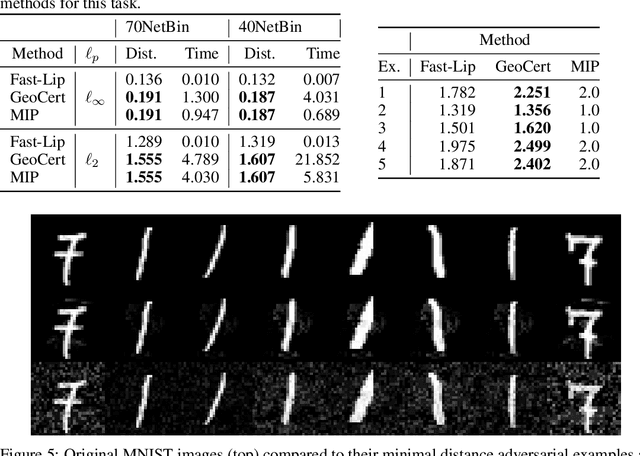
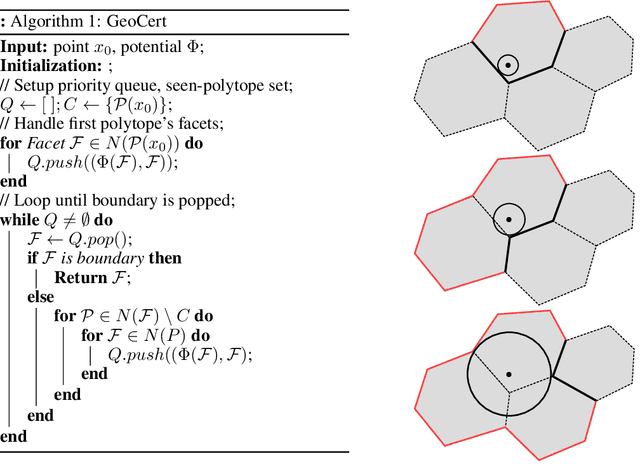
We propose a novel method for computing exact pointwise robustness of deep neural networks for a number of $\ell_p$ norms. Our algorithm, GeoCert, finds the largest $\ell_p$ ball centered at an input point $x_0$, within which the output class of a given neural network with ReLU nonlinearities remains unchanged. We relate the problem of computing pointwise robustness of these networks to that of growing a norm ball inside a non-convex polytope. This is a challenging problem in general, as we discuss; however, we prove a useful structural result about the geometry of the piecewise linear components of ReLU networks. This result allows for an efficient convex decomposition of the problem. Specifically we show that if polytopes satisfy a technical condition that we call being 'perfectly-glued', then we can find the largest ball inside their union in polynomial time. Our method is efficient and can certify pointwise robustness for any norm where p is greater or equal to 1.
Quantifying Perceptual Distortion of Adversarial Examples
Feb 21, 2019

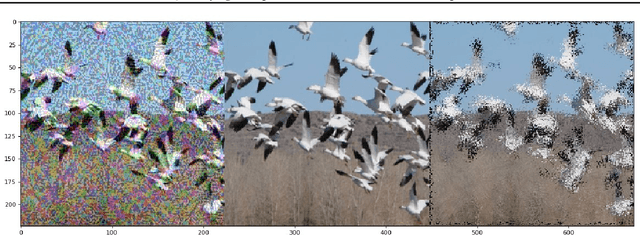
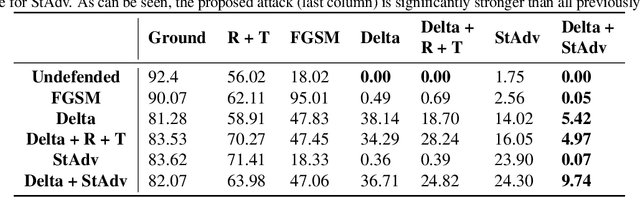
Recent work has shown that additive threat models, which only permit the addition of bounded noise to the pixels of an image, are insufficient for fully capturing the space of imperceivable adversarial examples. For example, small rotations and spatial transformations can fool classifiers, remain imperceivable to humans, but have large additive distance from the original images. In this work, we leverage quantitative perceptual metrics like LPIPS and SSIM to define a novel threat model for adversarial attacks. To demonstrate the value of quantifying the perceptual distortion of adversarial examples, we present and employ a unifying framework fusing different attack styles. We first prove that our framework results in images that are unattainable by attack styles in isolation. We then perform adversarial training using attacks generated by our framework to demonstrate that networks are only robust to classes of adversarial perturbations they have been trained against, and combination attacks are stronger than any of their individual components. Finally, we experimentally demonstrate that our combined attacks retain the same perceptual distortion but induce far higher misclassification rates when compared against individual attacks.
Discrete Attacks and Submodular Optimization with Applications to Text Classification
Dec 01, 2018

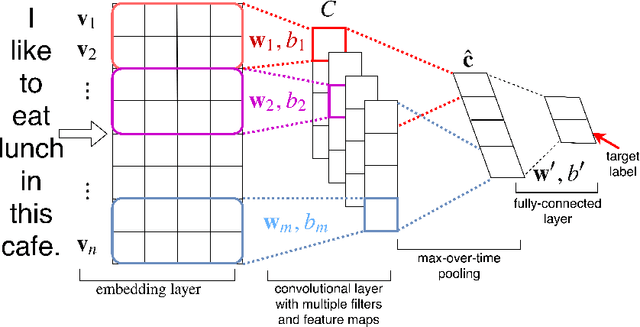
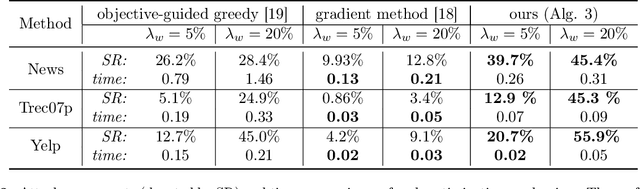
Adversarial examples are carefully constructed modifications to an input that completely change the output of a classifier but are imperceptible to humans. Despite these successful attacks for continuous data (such as image and audio samples), generating adversarial examples for discrete structures such as text has proven significantly more challenging. In this paper we formulate the attacks with discrete input on a set function as an optimization task. We prove that this set function is submodular for some popular neural network text classifiers under simplifying assumption. This finding guarantees a $1-1/e$ approximation factor for attacks that use the greedy algorithm. Meanwhile, we show how to use the gradient of the attacked classifier to guide the greedy search. Empirical studies with our proposed optimization scheme show significantly improved attack ability and efficiency, on three different text classification tasks over various baselines. We also use a joint sentence and word paraphrasing technique to maintain the original semantics and syntax of the text. This is validated by a human subject evaluation in subjective metrics on the quality and semantic coherence of our generated adversarial text.
Adversarial Video Compression Guided by Soft Edge Detection
Nov 26, 2018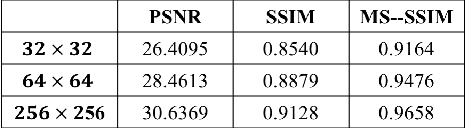
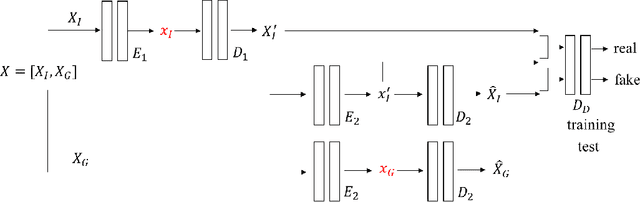
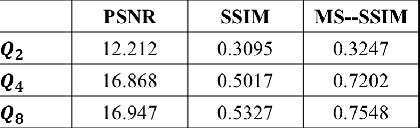
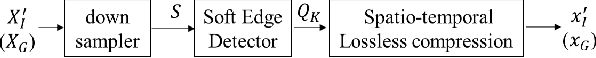
We propose a video compression framework using conditional Generative Adversarial Networks (GANs). We rely on two encoders: one that deploys a standard video codec and another which generates low-level maps via a pipeline of down-sampling, a newly devised soft edge detector, and a novel lossless compression scheme. For decoding, we use a standard video decoder as well as a neural network based one, which is trained using a conditional GAN. Recent "deep" approaches to video compression require multiple videos to pre-train generative networks to conduct interpolation. In contrast to this prior work, our scheme trains a generative decoder on pairs of a very limited number of key frames taken from a single video and corresponding low-level maps. The trained decoder produces reconstructed frames relying on a guidance of low-level maps, without any interpolation. Experiments on a diverse set of 131 videos demonstrate that our proposed GAN-based compression engine achieves much higher quality reconstructions at very low bitrates than prevailing standard codecs such as H.264 or HEVC.
Sparse Logistic Regression Learns All Discrete Pairwise Graphical Models
Oct 28, 2018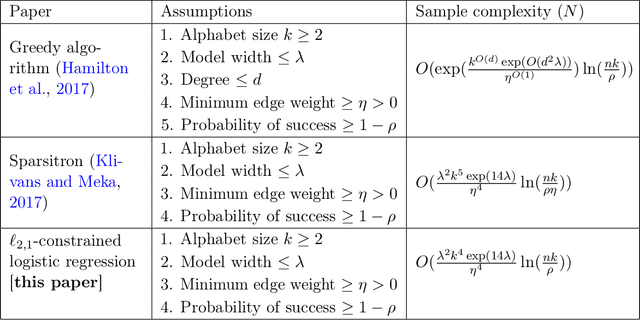
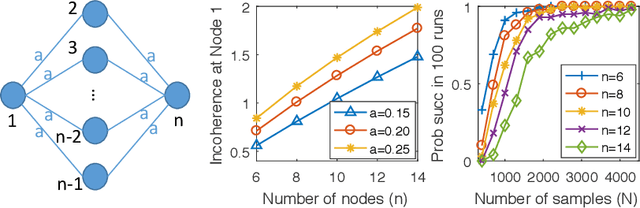
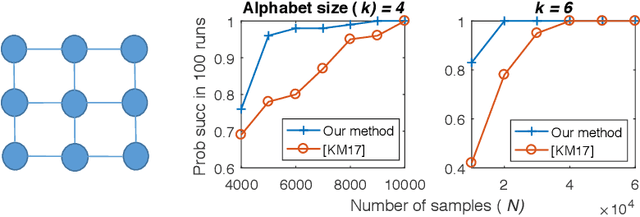

We characterize the effectiveness of a natural and classic algorithm for recovering the Markov graph of a general discrete pairwise graphical model from i.i.d. samples. The algorithm is (appropriately regularized) conditional maximum likelihood, which involves solving a convex program for each node; for Ising models this is $\ell_1$-constrained logistic regression, while for more alphabets an $\ell_{2,1}$ group-norm constraint needs to be used. We show that this algorithm can recover any arbitrary discrete pairwise graphical model, and also characterize its sample complexity as a function of model width, alphabet size, edge parameter accuracy, and the number of variables. We show that along every one of these axes, it matches or improves on all existing results and algorithms for this problem. Our analysis applies a sharp generalization error bound for logistic regression when the weight vector has an $\ell_1$ constraint (or $\ell_{2,1}$ constraint) and the sample vector has an $\ell_{\infty}$ constraint (or $\ell_{2, \infty}$ constraint). We also show that the proposed convex programs can be efficiently optimized in $\tilde{O}(n^2)$ running time (where $n$ is the number of variables) under the same statistical guarantee. Our experimental results verify our analysis.
Experimental Design for Cost-Aware Learning of Causal Graphs
Oct 28, 2018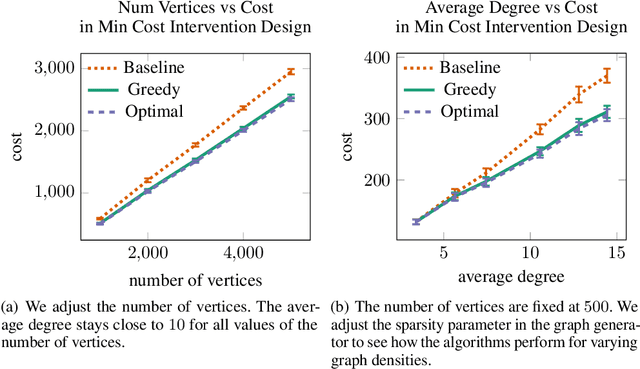
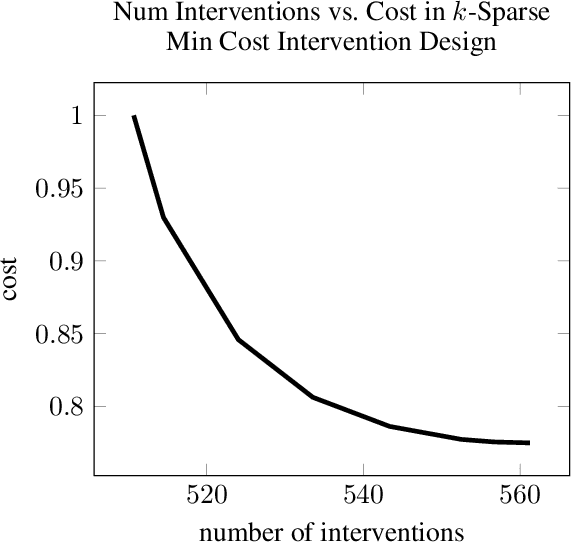

We consider the minimum cost intervention design problem: Given the essential graph of a causal graph and a cost to intervene on a variable, identify the set of interventions with minimum total cost that can learn any causal graph with the given essential graph. We first show that this problem is NP-hard. We then prove that we can achieve a constant factor approximation to this problem with a greedy algorithm. We then constrain the sparsity of each intervention. We develop an algorithm that returns an intervention design that is nearly optimal in terms of size for sparse graphs with sparse interventions and we discuss how to use it when there are costs on the vertices.
Gradient Coding from Cyclic MDS Codes and Expander Graphs
Sep 18, 2018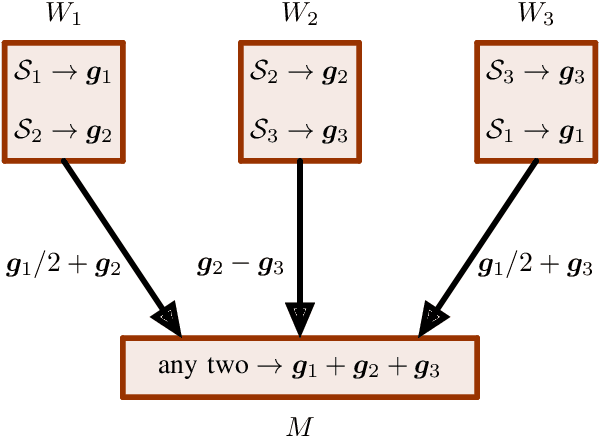
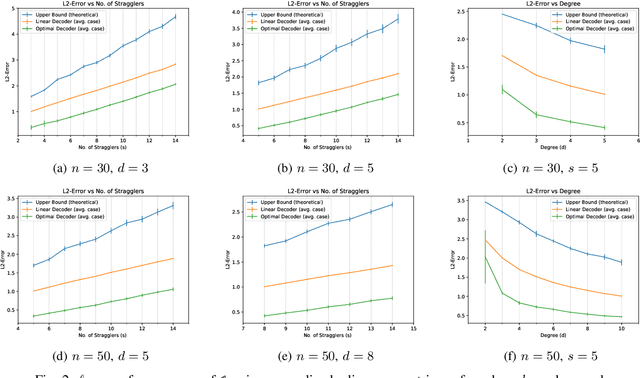
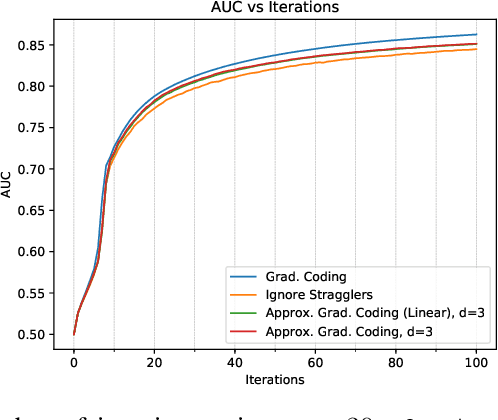
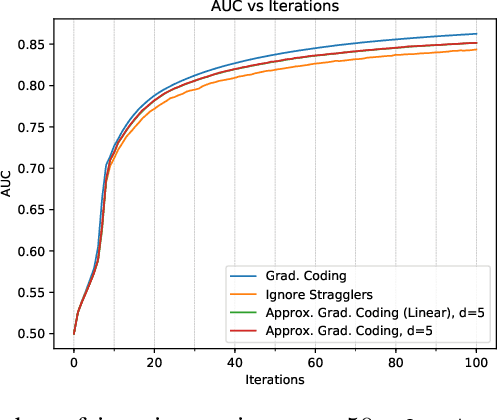
Gradient coding is a technique for straggler mitigation in distributed learning. In this paper we design novel gradient codes using tools from classical coding theory, namely, cyclic MDS codes, which compare favourably with existing solutions, both in the applicable range of parameters and in the complexity of the involved algorithms. Second, we introduce an approximate variant of the gradient coding problem, in which we settle for approximate gradient computation instead of the exact one. This approach enables graceful degradation, i.e., the $\ell_2$ error of the approximate gradient is a decreasing function of the number of stragglers. Our main result is that the normalized adjacency matrix of an expander graph can yield excellent approximate gradient codes, and that this approach allows us to perform significantly less computation compared to exact gradient coding. We experimentally test our approach on Amazon EC2, and show that the generalization error of approximate gradient coding is very close to the full gradient while requiring significantly less computation from the workers.
Entropic Latent Variable Discovery
Jul 26, 2018
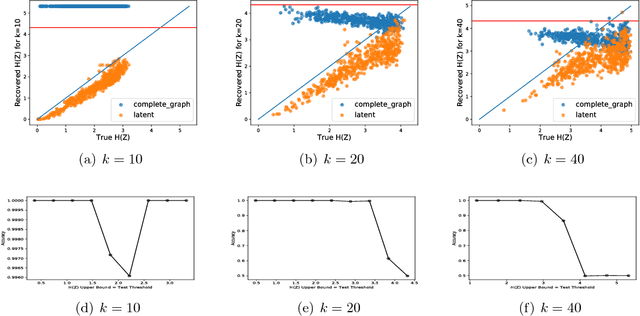
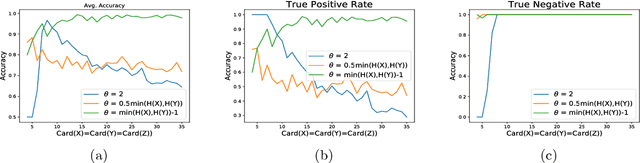
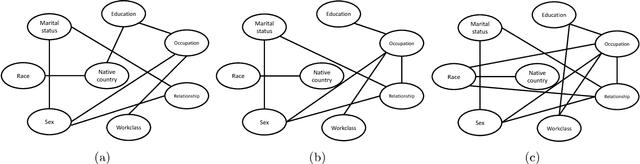
We consider the problem of discovering the simplest latent variable that can make two observed discrete variables conditionally independent. This problem has appeared in the literature as probabilistic latent semantic analysis (pLSA), and has connections to non-negative matrix factorization. When the simplicity of the variable is measured through its cardinality, we show that a solution to this latent variable discovery problem can be used to distinguish direct causal relations from spurious correlations among almost all joint distributions on simple causal graphs with two observed variables. Conjecturing a similar identifiability result holds with Shannon entropy, we study a loss function that trades-off between entropy of the latent variable and the conditional mutual information of the observed variables. We then propose a latent variable discovery algorithm -- LatentSearch -- and show that its stationary points are the stationary points of our loss function. We experimentally show that LatentSearch can indeed be used to distinguish direct causal relations from spurious correlations.