 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Q-learning For Antibody Design
Sep 13, 2022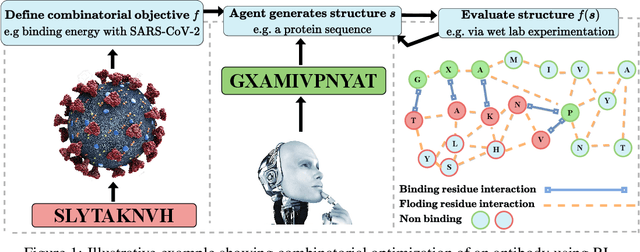
Optimizing combinatorial structures is core to many real-world problems, such as those encountered in life sciences. For example, one of the crucial steps involved in antibody design is to find an arrangement of amino acids in a protein sequence that improves its binding with a pathogen. Combinatorial optimization of antibodies is difficult due to extremely large search spaces and non-linear objectives. Even for modest antibody design problems, where proteins have a sequence length of eleven, we are faced with searching over 2.05 x 10^14 structures. Applying traditional Reinforcement Learning algorithms such as Q-learning to combinatorial optimization results in poor performance. We propose Structured Q-learning (SQL), an extension of Q-learning that incorporates structural priors for combinatorial optimization. Using a molecular docking simulator, we demonstrate that SQL finds high binding energy sequences and performs favourably against baselines on eight challenging antibody design tasks, including designing antibodies for SARS-COV.
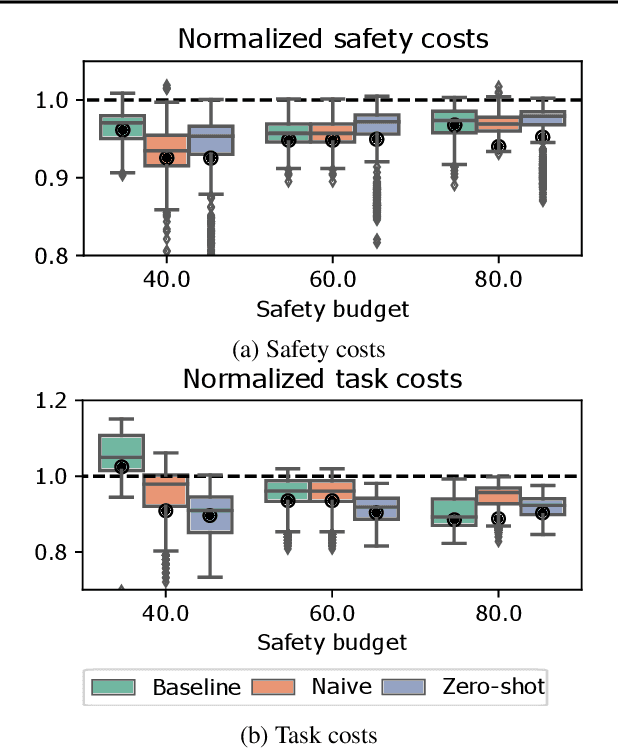
Enhancing Safe Exploration Using Safety State Augmentation
Jun 06, 2022
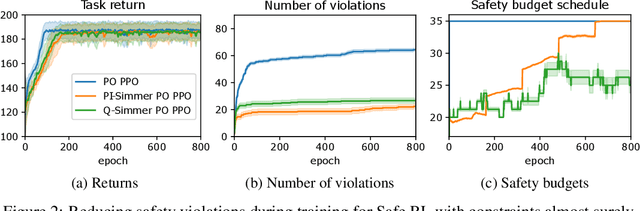
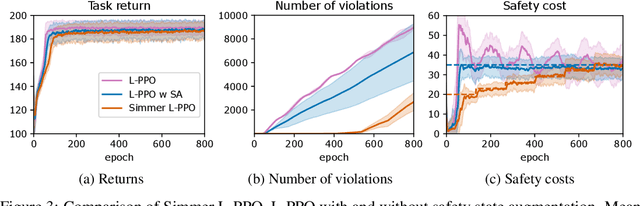
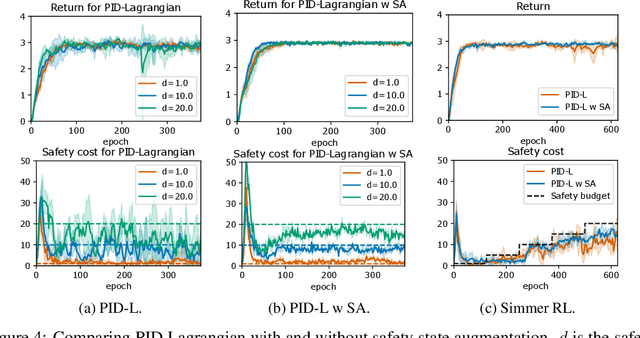
Safe exploration is a challenging and important problem in model-free reinforcement learning (RL). Often the safety cost is sparse and unknown, which unavoidably leads to constraint violations -- a phenomenon ideally to be avoided in safety-critical applications. We tackle this problem by augmenting the state-space with a safety state, which is nonnegative if and only if the constraint is satisfied. The value of this state also serves as a distance toward constraint violation, while its initial value indicates the available safety budget. This idea allows us to derive policies for scheduling the safety budget during training. We call our approach Simmer (Safe policy IMproveMEnt for RL) to reflect the careful nature of these schedules. We apply this idea to two safe RL problems: RL with constraints imposed on an average cost, and RL with constraints imposed on a cost with probability one. Our experiments suggest that simmering a safe algorithm can improve safety during training for both settings. We further show that Simmer can stabilize training and improve the performance of safe RL with average constraints.
AntBO: Towards Real-World Automated Antibody Design with Combinatorial Bayesian Optimisation
Feb 16, 2022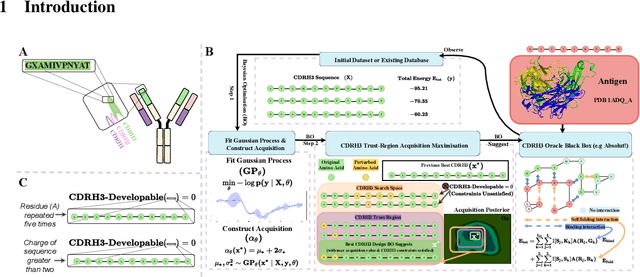
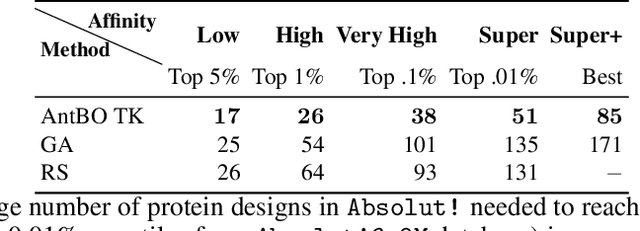
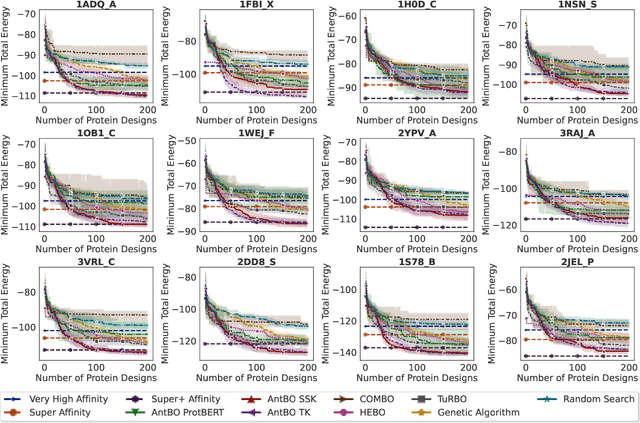
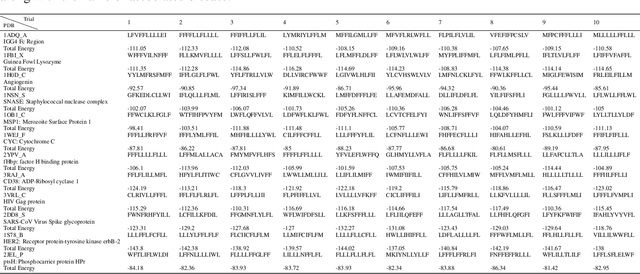
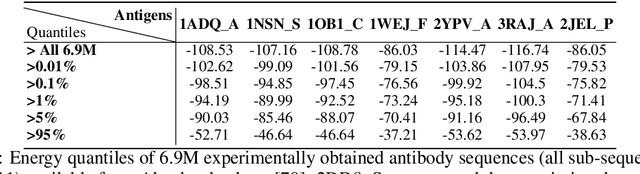
Antibodies are canonically Y-shaped multimeric proteins capable of highly specific molecular recognition. The CDRH3 region located at the tip of variable chains of an antibody dominates antigen-binding specificity. Therefore, it is a priority to design optimal antigen-specific CDRH3 regions to develop therapeutic antibodies to combat harmful pathogens. However, the combinatorial nature of CDRH3 sequence space makes it impossible to search for an optimal binding sequence exhaustively and efficiently, especially not experimentally. Here, we present AntBO: a Combinatorial Bayesian Optimisation framework enabling efficient in silico design of the CDRH3 region. Ideally, antibodies should bind to their target antigen and be free from any harmful outcomes. Therefore, we introduce the CDRH3 trust region that restricts the search to sequences with feasible developability scores. To benchmark AntBO, we use the Absolut! software suite as a black-box oracle because it can score the target specificity and affinity of designed antibodies in silico in an unconstrained fashion. The results across 188 antigens demonstrate the benefit of AntBO in designing CDRH3 regions with diverse biophysical properties. In under 200 protein designs, AntBO can suggest antibody sequences that outperform the best binding sequence drawn from 6.9 million experimentally obtained CDRH3s and a commonly used genetic algorithm baseline. Additionally, AntBO finds very-high affinity CDRH3 sequences in only 38 protein designs whilst requiring no domain knowledge. We conclude AntBO brings automated antibody design methods closer to what is practically viable for in vitro experimentation.
SAUTE RL: Almost Surely Safe Reinforcement Learning Using State Augmentation
Feb 16, 2022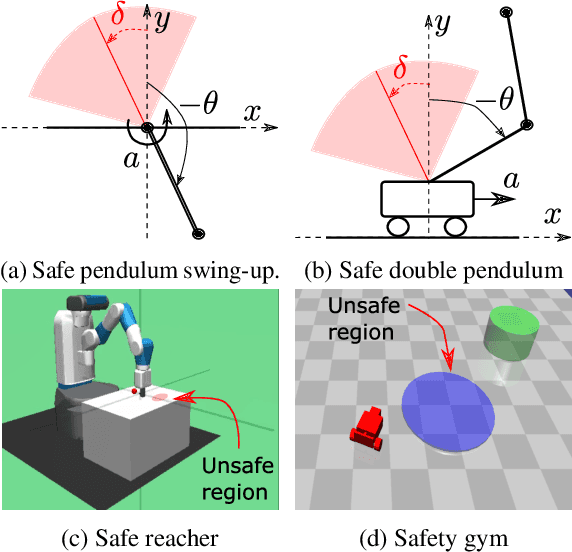
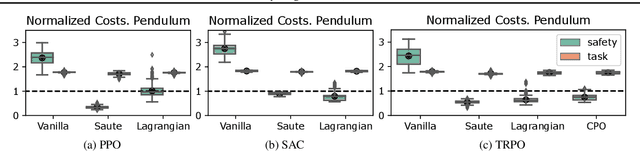
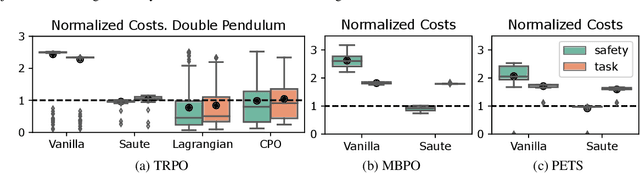
Satisfying safety constraints almost surely (or with probability one) can be critical for deployment of Reinforcement Learning (RL) in real-life applications. For example, plane landing and take-off should ideally occur with probability one. We address the problem by introducing Safety Augmented (Saute) Markov Decision Processes (MDPs), where the safety constraints are eliminated by augmenting them into the state-space and reshaping the objective. We show that Saute MDP satisfies the Bellman equation and moves us closer to solving Safe RL with constraints satisfied almost surely. We argue that Saute MDP allows to view Safe RL problem from a different perspective enabling new features. For instance, our approach has a plug-and-play nature, i.e., any RL algorithm can be "sauteed". Additionally, state augmentation allows for policy generalization across safety constraints. We finally show that Saute RL algorithms can outperform their state-of-the-art counterparts when constraint satisfaction is of high importance.
High-Dimensional Bayesian Optimisation with Variational Autoencoders and Deep Metric Learning
Jun 16, 2021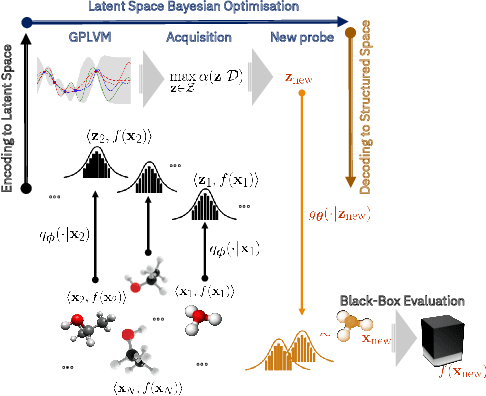

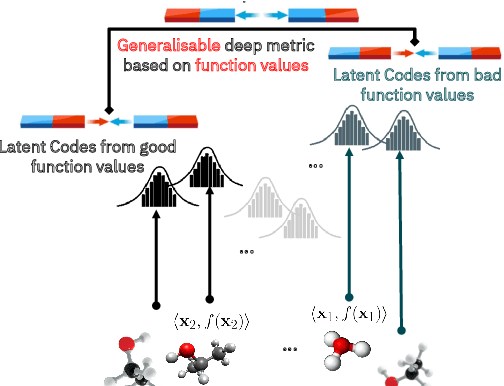

We introduce a method based on deep metric learning to perform Bayesian optimisation over high-dimensional, structured input spaces using variational autoencoders (VAEs). By extending ideas from supervised deep metric learning, we address a longstanding problem in high-dimensional VAE Bayesian optimisation, namely how to enforce a discriminative latent space as an inductive bias. Importantly, we achieve such an inductive bias using just 1% of the available labelled data relative to previous work, highlighting the sample efficiency of our approach. As a theoretical contribution, we present a proof of vanishing regret for our method. As an empirical contribution, we present state-of-the-art results on real-world high-dimensional black-box optimisation problems including property-guided molecule generation. It is the hope that the results presented in this paper can act as a guiding principle for realising effective high-dimensional Bayesian optimisation.
Are we Forgetting about Compositional Optimisers in Bayesian Optimisation?
Dec 17, 2020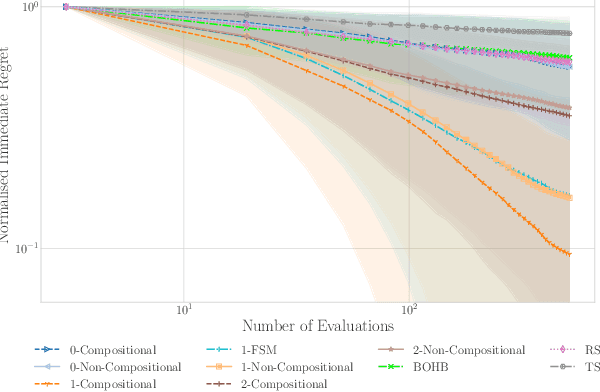
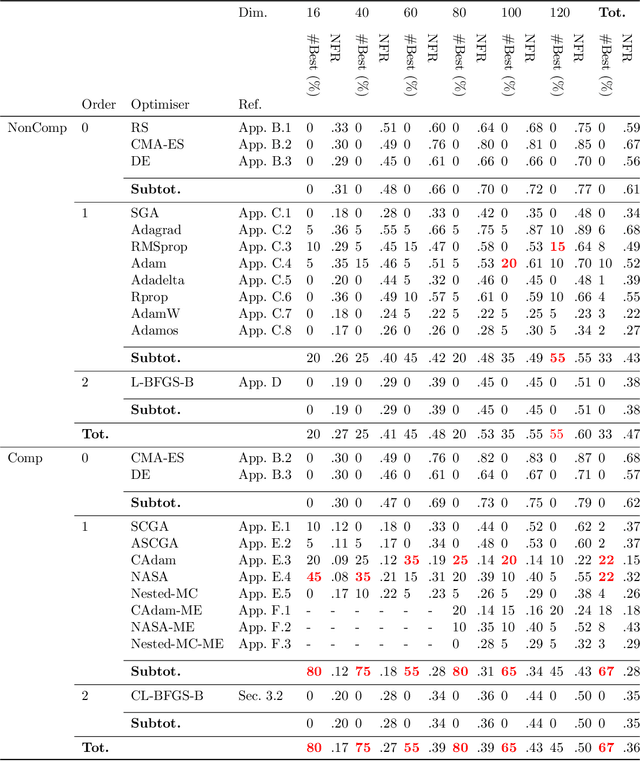
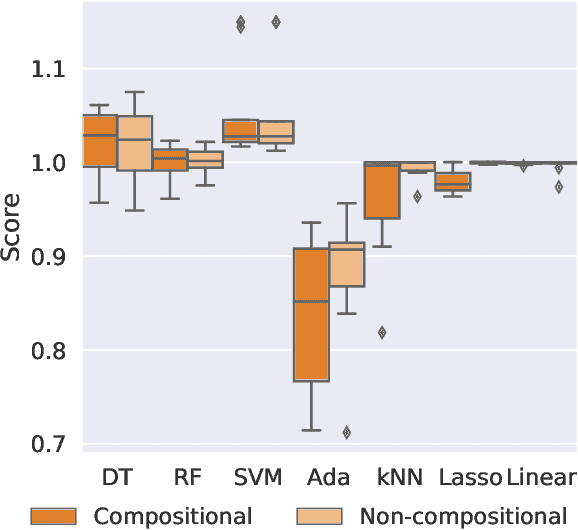
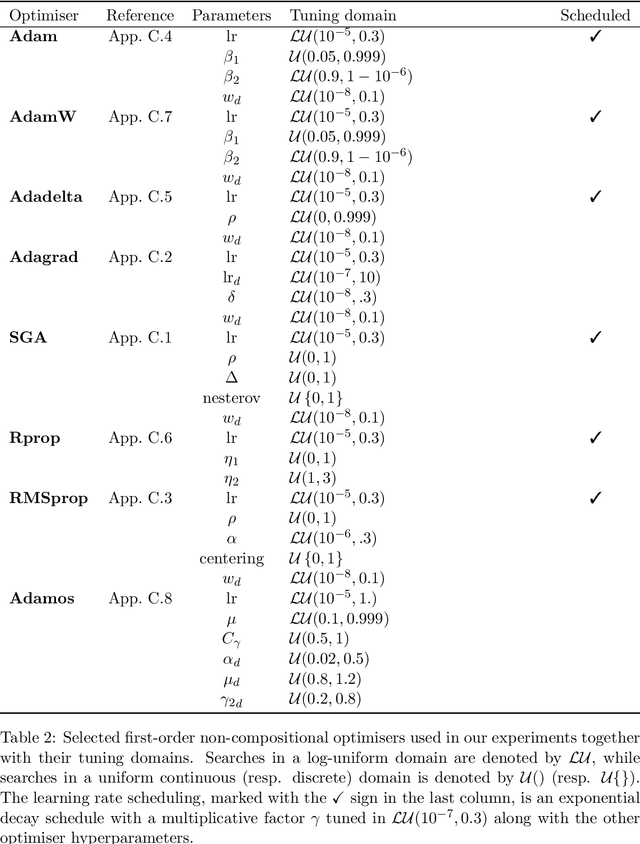
Bayesian optimisation presents a sample-efficient methodology for global optimisation. Within this framework, a crucial performance-determining subroutine is the maximisation of the acquisition function, a task complicated by the fact that acquisition functions tend to be non-convex and thus nontrivial to optimise. In this paper, we undertake a comprehensive empirical study of approaches to maximise the acquisition function. Additionally, by deriving novel, yet mathematically equivalent, compositional forms for popular acquisition functions, we recast the maximisation task as a compositional optimisation problem, allowing us to benefit from the extensive literature in this field. We highlight the empirical advantages of the compositional approach to acquisition function maximisation across 3958 individual experiments comprising synthetic optimisation tasks as well as tasks from Bayesmark. Given the generality of the acquisition function maximisation subroutine, we posit that the adoption of compositional optimisers has the potential to yield performance improvements across all domains in which Bayesian optimisation is currently being applied.
HEBO: Heteroscedastic Evolutionary Bayesian Optimisation
Dec 07, 2020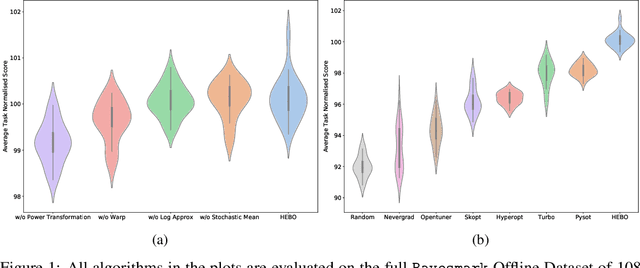

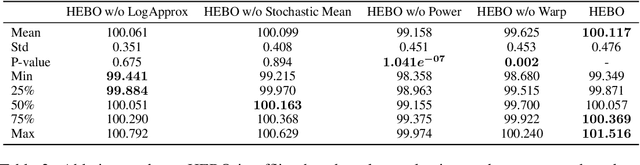
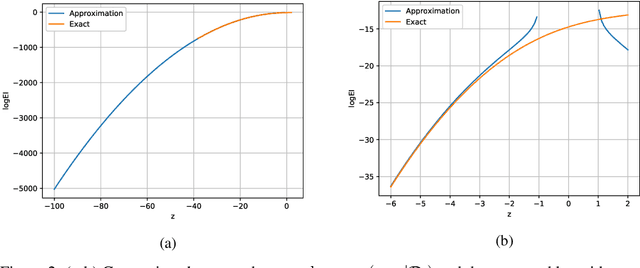
We introduce HEBO: Heteroscedastic Evolutionary Bayesian Optimisation that won the NeurIPS 2020 black-box optimisation competition. We present non-conventional modifications to the surrogate model and acquisition maximisation process and show such a combination superior against all baselines provided by the \texttt{Bayesmark} package. Lastly, we perform an ablation study to highlight the components that contributed to the success of HEBO.
SAMBA: Safe Model-Based & Active Reinforcement Learning
Jun 12, 2020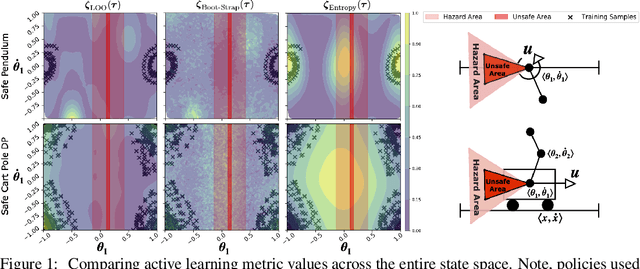
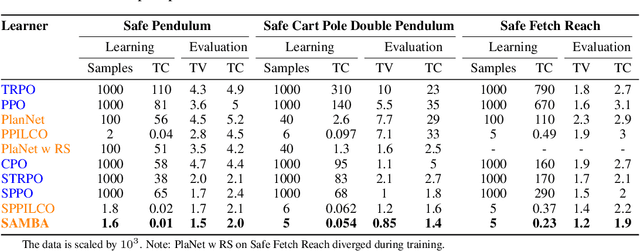

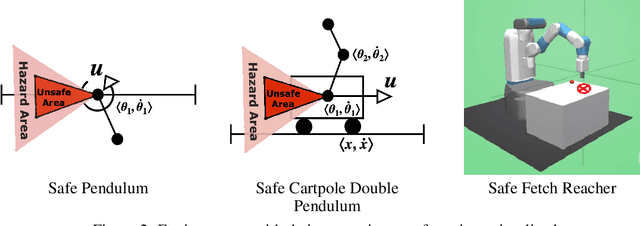
In this paper, we propose SAMBA, a novel framework for safe reinforcement learning that combines aspects from probabilistic modelling, information theory, and statistics. Our method builds upon PILCO to enable active exploration using novel(semi-)metrics for out-of-sample Gaussian process evaluation optimised through a multi-objective problem that supports conditional-value-at-risk constraints. We evaluate our algorithm on a variety of safe dynamical system benchmarks involving both low and high-dimensional state representations. Our results show orders of magnitude reductions in samples and violations compared to state-of-the-art methods. Lastly, we provide intuition as to the effectiveness of the framework by a detailed analysis of our active metrics and safety constraints.
Emergent Communication with World Models
Feb 22, 2020

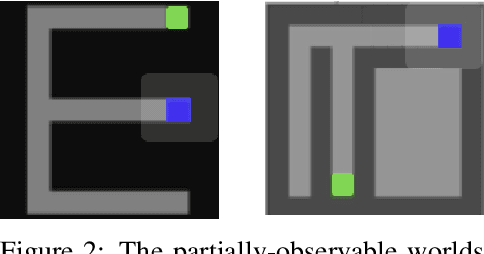
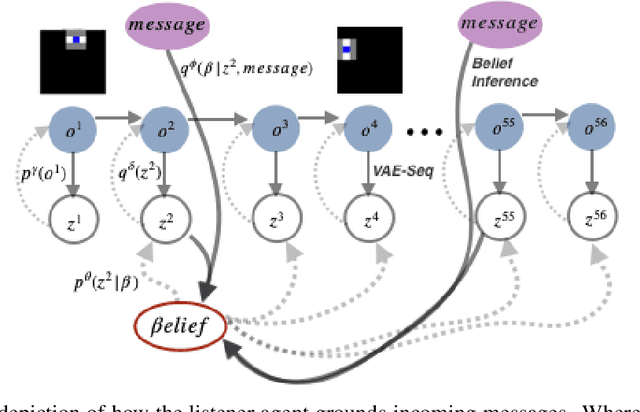
We introduce Language World Models, a class of language-conditional generative model which interpret natural language messages by predicting latent codes of future observations. This provides a visual grounding of the message, similar to an enhanced observation of the world, which may include objects outside of the listening agent's field-of-view. We incorporate this "observation" into a persistent memory state, and allow the listening agent's policy to condition on it, akin to the relationship between memory and controller in a World Model. We show this improves effective communication and task success in 2D gridworld speaker-listener navigation tasks. In addition, we develop two losses framed specifically for our model-based formulation to promote positive signalling and positive listening. Finally, because messages are interpreted in a generative model, we can visualize the model beliefs to gain insight into how the communication channel is utilized.
Neural Variational Inference For Estimating Uncertainty in Knowledge Graph Embeddings
Jun 12, 2019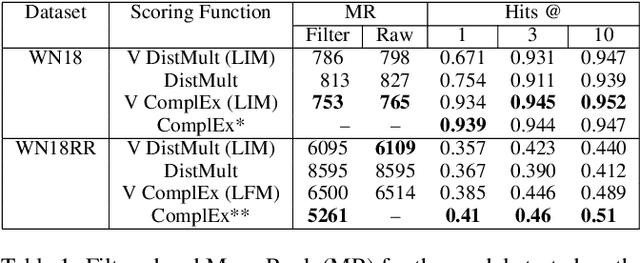
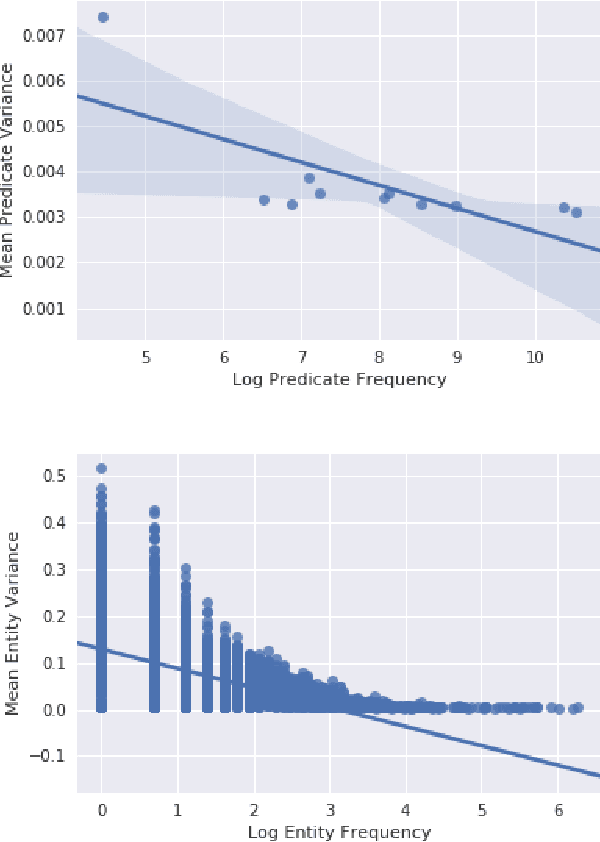

Recent advances in Neural Variational Inference allowed for a renaissance in latent variable models in a variety of domains involving high-dimensional data. While traditional variational methods derive an analytical approximation for the intractable distribution over the latent variables, here we construct an inference network conditioned on the symbolic representation of entities and relation types in the Knowledge Graph, to provide the variational distributions. The new framework results in a highly-scalable method. Under a Bernoulli sampling framework, we provide an alternative justification for commonly used techniques in large-scale stochastic variational inference, which drastically reduce training time at a cost of an additional approximation to the variational lower bound. We introduce two models from this highly scalable probabilistic framework, namely the Latent Information and Latent Fact models, for reasoning over knowledge graph-based representations. Our Latent Information and Latent Fact models improve upon baseline performance under certain conditions. We use the learnt embedding variance to estimate predictive uncertainty during link prediction, and discuss the quality of these learnt uncertainty estimates. Our source code and datasets are publicly available online at https://github.com/alexanderimanicowenrivers/Neural-Variational-Knowledge-Graphs.