 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuess & Sketch: Language Model Guided Transpilation
Sep 25, 2023



Maintaining legacy software requires many software and systems engineering hours. Assembly code programs, which demand low-level control over the computer machine state and have no variable names, are particularly difficult for humans to analyze. Existing conventional program translators guarantee correctness, but are hand-engineered for the source and target programming languages in question. Learned transpilation, i.e. automatic translation of code, offers an alternative to manual re-writing and engineering efforts. Automated symbolic program translation approaches guarantee correctness but struggle to scale to longer programs due to the exponentially large search space. Their rigid rule-based systems also limit their expressivity, so they can only reason about a reduced space of programs. Probabilistic neural language models (LMs) produce plausible outputs for every input, but do so at the cost of guaranteed correctness. In this work, we leverage the strengths of LMs and symbolic solvers in a neurosymbolic approach to learned transpilation for assembly code. Assembly code is an appropriate setting for a neurosymbolic approach, since assembly code can be divided into shorter non-branching basic blocks amenable to the use of symbolic methods. Guess & Sketch extracts alignment and confidence information from features of the LM then passes it to a symbolic solver to resolve semantic equivalence of the transpilation input and output. We test Guess & Sketch on three different test sets of assembly transpilation tasks, varying in difficulty, and show that it successfully transpiles 57.6% more examples than GPT-4 and 39.6% more examples than an engineered transpiler. We also share a training and evaluation dataset for this task.
OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
Jun 21, 2023



Large multimodal models trained on natural documents, which interleave images and text, outperform models trained on image-text pairs on various multimodal benchmarks that require reasoning over one or multiple images to generate a text. However, the datasets used to train these models have not been released, and the collection process has not been fully specified. We introduce the OBELISC dataset, an open web-scale filtered dataset of interleaved image-text documents comprising 141 million web pages extracted from Common Crawl, 353 million associated images, and 115 billion text tokens. We describe the dataset creation process, present comprehensive filtering rules, and provide an analysis of the dataset's content. To show the viability of OBELISC, we train an 80 billion parameters vision and language model on the dataset and obtain competitive performance on various multimodal benchmarks. We release the code to reproduce the dataset along with the dataset itself.
Scaling Data-Constrained Language Models
May 25, 2023The current trend of scaling language models involves increasing both parameter count and training dataset size. Extrapolating this trend suggests that training dataset size may soon be limited by the amount of text data available on the internet. Motivated by this limit, we investigate scaling language models in data-constrained regimes. Specifically, we run a large set of experiments varying the extent of data repetition and compute budget, ranging up to 900 billion training tokens and 9 billion parameter models. We find that with constrained data for a fixed compute budget, training with up to 4 epochs of repeated data yields negligible changes to loss compared to having unique data. However, with more repetition, the value of adding compute eventually decays to zero. We propose and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters. Finally, we experiment with approaches mitigating data scarcity, including augmenting the training dataset with code data or removing commonly used filters. Models and datasets from our 400 training runs are publicly available at https://github.com/huggingface/datablations.
Abductive Commonsense Reasoning Exploiting Mutually Exclusive Explanations
May 24, 2023



Abductive reasoning aims to find plausible explanations for an event. This style of reasoning is critical for commonsense tasks where there are often multiple plausible explanations. Existing approaches for abductive reasoning in natural language processing (NLP) often rely on manually generated annotations for supervision; however, such annotations can be subjective and biased. Instead of using direct supervision, this work proposes an approach for abductive commonsense reasoning that exploits the fact that only a subset of explanations is correct for a given context. The method uses posterior regularization to enforce a mutual exclusion constraint, encouraging the model to learn the distinction between fluent explanations and plausible ones. We evaluate our approach on a diverse set of abductive reasoning datasets; experimental results show that our approach outperforms or is comparable to directly applying pretrained language models in a zero-shot manner and other knowledge-augmented zero-shot methods.
HOP, UNION, GENERATE: Explainable Multi-hop Reasoning without Rationale Supervision
May 23, 2023



Explainable multi-hop question answering (QA) not only predicts answers but also identifies rationales, i. e. subsets of input sentences used to derive the answers. This problem has been extensively studied under the supervised setting, where both answer and rationale annotations are given. Because rationale annotations are expensive to collect and not always available, recent efforts have been devoted to developing methods that do not rely on supervision for rationales. However, such methods have limited capacities in modeling interactions between sentences, let alone reasoning across multiple documents. This work proposes a principled, probabilistic approach for training explainable multi-hop QA systems without rationale supervision. Our approach performs multi-hop reasoning by explicitly modeling rationales as sets, enabling the model to capture interactions between documents and sentences within a document. Experimental results show that our approach is more accurate at selecting rationales than the previous methods, while maintaining similar accuracy in predicting answers.
Pretraining Without Attention
Dec 20, 2022Transformers have been essential to pretraining success in NLP. Other architectures have been used, but require attention layers to match benchmark accuracy. This work explores pretraining without attention. We test recently developed routing layers based on state-space models (SSM) and model architectures based on multiplicative gating. Used together these modeling choices have a large impact on pretraining accuracy. Empirically the proposed Bidirectional Gated SSM (BiGS) replicates BERT pretraining results without attention and can be extended to long-form pretraining of 4096 tokens without approximation.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Teal: Learning-Accelerated Optimization of Traffic Engineering
Oct 25, 2022



In the last decade, global cloud wide-area networks (WANs) have grown 10$\times$ in size due to the deployment of new network sites and datacenters, making it challenging for commercial optimization engines to solve the network traffic engineering (TE) problem within the temporal budget of a few minutes. In this work, we show that carefully designed deep learning models are key to accelerating the running time of intra-WAN TE systems for large deployments since deep learning is both massively parallel and it benefits from the wealth of historical traffic allocation data from production WANs. However, off-the-shelf deep learning methods fail to perform well on the TE task since they ignore the effects of network connectivity on flow allocations. They are also faced with a tractability challenge posed by the large problem scale of TE optimization. Moreover, neural networks do not have mechanisms to readily enforce hard constraints on model outputs (e.g., link capacity constraints). We tackle these challenges by designing a deep learning-based TE system -- Teal. First, Teal leverages graph neural networks (GNN) to faithfully capture connectivity and model network flows. Second, Teal devises a multi-agent reinforcement learning (RL) algorithm to process individual demands independently in parallel to lower the problem scale. Finally, Teal reduces link capacity violations and improves solution quality using the alternating direction method of multipliers (ADMM). We evaluate Teal on traffic matrices of a global commercial cloud provider and find that Teal computes near-optimal traffic allocations with a 59$\times$ speedup over state-of-the-art TE systems on a WAN topology of over 1,500 nodes.
ESB: A Benchmark For Multi-Domain End-to-End Speech Recognition
Oct 24, 2022Speech recognition applications cover a range of different audio and text distributions, with different speaking styles, background noise, transcription punctuation and character casing. However, many speech recognition systems require dataset-specific tuning (audio filtering, punctuation removal and normalisation of casing), therefore assuming a-priori knowledge of both the audio and text distributions. This tuning requirement can lead to systems failing to generalise to other datasets and domains. To promote the development of multi-domain speech systems, we introduce the End-to-end Speech Benchmark (ESB) for evaluating the performance of a single automatic speech recognition (ASR) system across a broad set of speech datasets. Benchmarked systems must use the same data pre- and post-processing algorithm across datasets - assuming the audio and text data distributions are a-priori unknown. We compare a series of state-of-the-art (SoTA) end-to-end (E2E) systems on this benchmark, demonstrating how a single speech system can be applied and evaluated on a wide range of data distributions. We find E2E systems to be effective across datasets: in a fair comparison, E2E systems achieve within 2.6% of SoTA systems tuned to a specific dataset. Our analysis reveals that transcription artefacts, such as punctuation and casing, pose difficulties for ASR systems and should be included in evaluation. We believe E2E benchmarking over a range of datasets promotes the research of multi-domain speech recognition systems. ESB is available at https://huggingface.co/esb.
Model Criticism for Long-Form Text Generation
Oct 16, 2022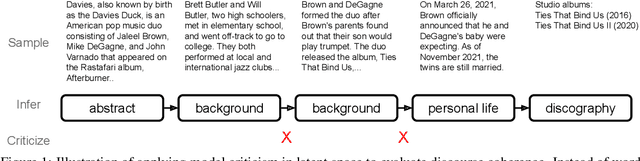
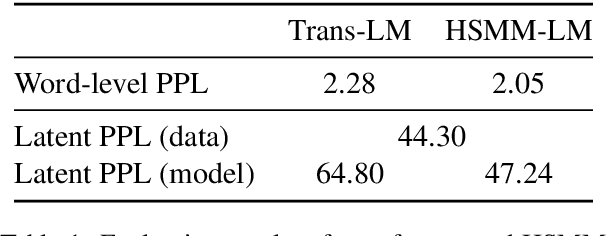
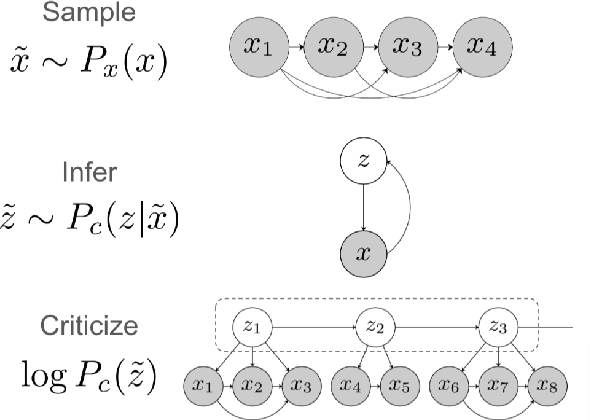
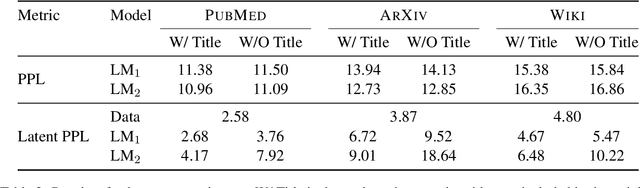
Language models have demonstrated the ability to generate highly fluent text; however, it remains unclear whether their output retains coherent high-level structure (e.g., story progression). Here, we propose to apply a statistical tool, model criticism in latent space, to evaluate the high-level structure of the generated text. Model criticism compares the distributions between real and generated data in a latent space obtained according to an assumptive generative process. Different generative processes identify specific failure modes of the underlying model. We perform experiments on three representative aspects of high-level discourse -- coherence, coreference, and topicality -- and find that transformer-based language models are able to capture topical structures but have a harder time maintaining structural coherence or modeling coreference.