 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Discrete Communication Bottlenecks with Dynamic Vector Quantization
Feb 02, 2022



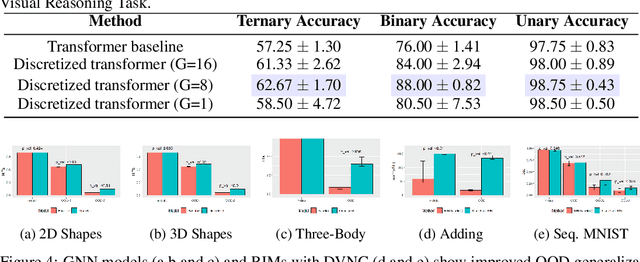
Vector Quantization (VQ) is a method for discretizing latent representations and has become a major part of the deep learning toolkit. It has been theoretically and empirically shown that discretization of representations leads to improved generalization, including in reinforcement learning where discretization can be used to bottleneck multi-agent communication to promote agent specialization and robustness. The discretization tightness of most VQ-based methods is defined by the number of discrete codes in the representation vector and the codebook size, which are fixed as hyperparameters. In this work, we propose learning to dynamically select discretization tightness conditioned on inputs, based on the hypothesis that data naturally contains variations in complexity that call for different levels of representational coarseness. We show that dynamically varying tightness in communication bottlenecks can improve model performance on visual reasoning and reinforcement learning tasks.
Discrete-Valued Neural Communication
Jul 10, 2021

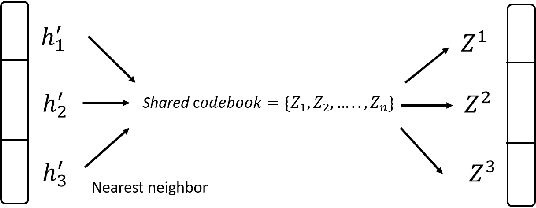
Deep learning has advanced from fully connected architectures to structured models organized into components, e.g., the transformer composed of positional elements, modular architectures divided into slots, and graph neural nets made up of nodes. In structured models, an interesting question is how to conduct dynamic and possibly sparse communication among the separate components. Here, we explore the hypothesis that restricting the transmitted information among components to discrete representations is a beneficial bottleneck. The motivating intuition is human language in which communication occurs through discrete symbols. Even though individuals have different understandings of what a "cat" is based on their specific experiences, the shared discrete token makes it possible for communication among individuals to be unimpeded by individual differences in internal representation. To discretize the values of concepts dynamically communicated among specialist components, we extend the quantization mechanism from the Vector-Quantized Variational Autoencoder to multi-headed discretization with shared codebooks and use it for discrete-valued neural communication (DVNC). Our experiments show that DVNC substantially improves systematic generalization in a variety of architectures -- transformers, modular architectures, and graph neural networks. We also show that the DVNC is robust to the choice of hyperparameters, making the method very useful in practice. Moreover, we establish a theoretical justification of our discretization process, proving that it has the ability to increase noise robustness and reduce the underlying dimensionality of the model.
Predicting the Ordering of Characters in Japanese Historical Documents
Jun 12, 2021


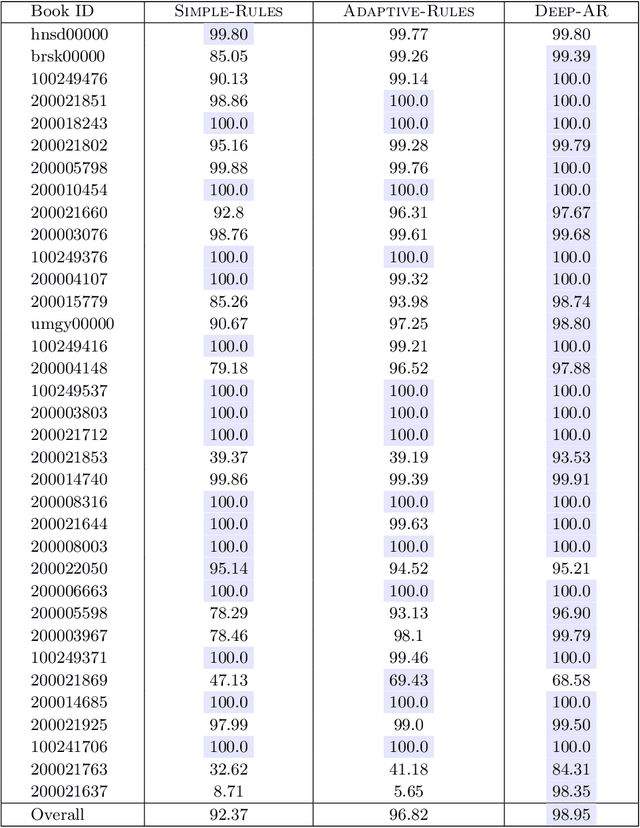
Japan is a unique country with a distinct cultural heritage, which is reflected in billions of historical documents that have been preserved. However, the change in Japanese writing system in 1900 made these documents inaccessible for the general public. A major research project has been to make these historical documents accessible and understandable. An increasing amount of research has focused on the character recognition task and the location of characters on image, yet less research has focused on how to predict the sequential ordering of the characters. This is because sequence in classical Japanese is very different from modern Japanese. Ordering characters into a sequence is important for making the document text easily readable and searchable. Additionally, it is a necessary step for any kind of natural language processing on the data (e.g. machine translation, language modeling, and word embeddings). We explore a few approaches to the task of predicting the sequential ordering of the characters: one using simple hand-crafted rules, another using hand-crafted rules with adaptive thresholds, and another using a deep recurrent sequence model trained with teacher forcing. We provide a quantitative and qualitative comparison of these techniques as well as their distinct trade-offs. Our best-performing system has an accuracy of 98.65\% and has a perfect accuracy on 49\% of the books in our dataset, suggesting that the technique is able to predict the order of the characters well enough for many tasks.
Coordination Among Neural Modules Through a Shared Global Workspace
Mar 01, 2021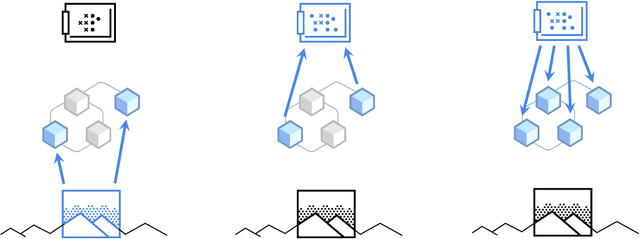
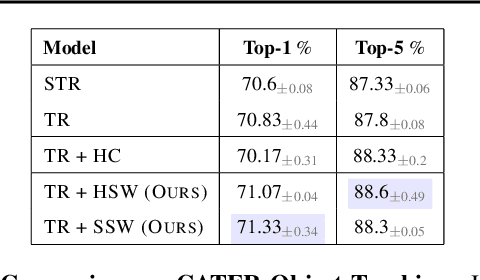
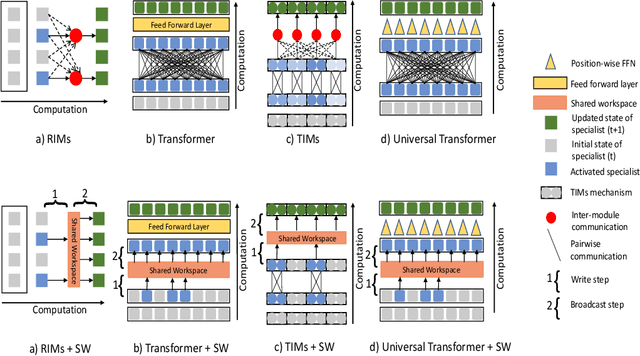
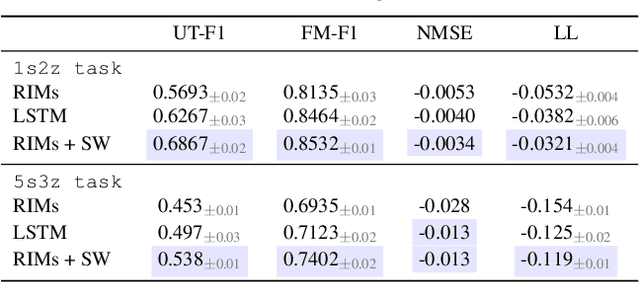
Deep learning has seen a movement away from representing examples with a monolithic hidden state towards a richly structured state. For example, Transformers segment by position, and object-centric architectures decompose images into entities. In all these architectures, interactions between different elements are modeled via pairwise interactions: Transformers make use of self-attention to incorporate information from other positions; object-centric architectures make use of graph neural networks to model interactions among entities. However, pairwise interactions may not achieve global coordination or a coherent, integrated representation that can be used for downstream tasks. In cognitive science, a global workspace architecture has been proposed in which functionally specialized components share information through a common, bandwidth-limited communication channel. We explore the use of such a communication channel in the context of deep learning for modeling the structure of complex environments. The proposed method includes a shared workspace through which communication among different specialist modules takes place but due to limits on the communication bandwidth, specialist modules must compete for access. We show that capacity limitations have a rational basis in that (1) they encourage specialization and compositionality and (2) they facilitate the synchronization of otherwise independent specialists.
Transformers with Competitive Ensembles of Independent Mechanisms
Feb 27, 2021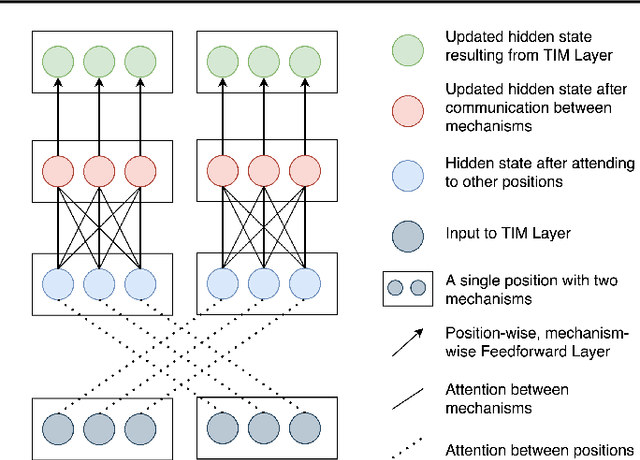
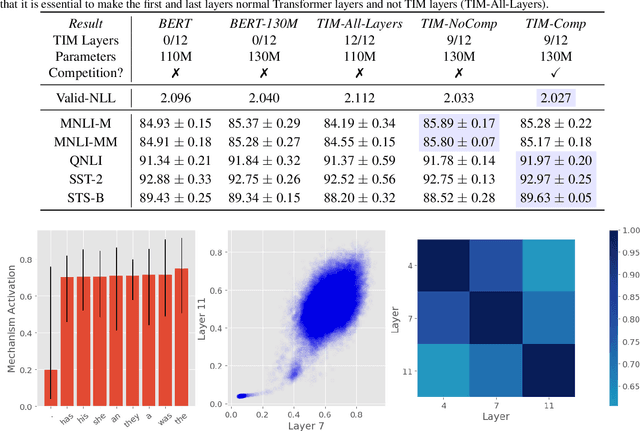
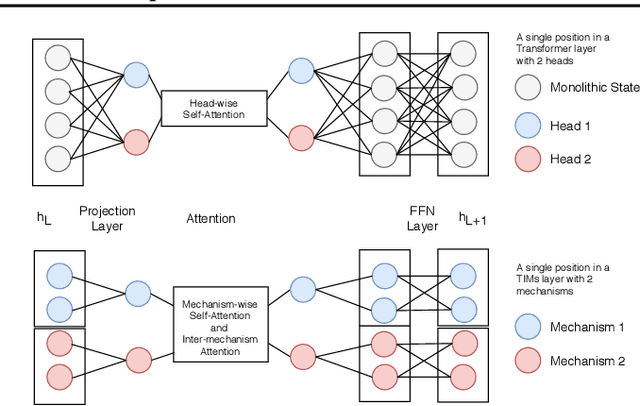
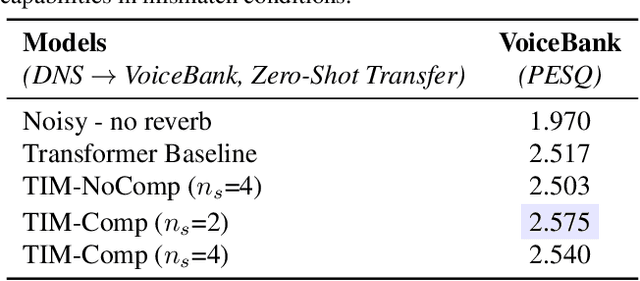
An important development in deep learning from the earliest MLPs has been a move towards architectures with structural inductive biases which enable the model to keep distinct sources of information and routes of processing well-separated. This structure is linked to the notion of independent mechanisms from the causality literature, in which a mechanism is able to retain the same processing as irrelevant aspects of the world are changed. For example, convnets enable separation over positions, while attention-based architectures (especially Transformers) learn which combination of positions to process dynamically. In this work we explore a way in which the Transformer architecture is deficient: it represents each position with a large monolithic hidden representation and a single set of parameters which are applied over the entire hidden representation. This potentially throws unrelated sources of information together, and limits the Transformer's ability to capture independent mechanisms. To address this, we propose Transformers with Independent Mechanisms (TIM), a new Transformer layer which divides the hidden representation and parameters into multiple mechanisms, which only exchange information through attention. Additionally, we propose a competition mechanism which encourages these mechanisms to specialize over time steps, and thus be more independent. We study TIM on a large-scale BERT model, on the Image Transformer, and on speech enhancement and find evidence for semantically meaningful specialization as well as improved performance.
A Brief Introduction to Generative Models
Feb 27, 2021We introduce and motivate generative modeling as a central task for machine learning and provide a critical view of the algorithms which have been proposed for solving this task. We overview how generative modeling can be defined mathematically as trying to make an estimating distribution the same as an unknown ground truth distribution. This can then be quantified in terms of the value of a statistical divergence between the two distributions. We outline the maximum likelihood approach and how it can be interpreted as minimizing KL-divergence. We explore a number of approaches in the maximum likelihood family, while discussing their limitations. Finally, we explore the alternative adversarial approach which involves studying the differences between an estimating distribution and a real data distribution. We discuss how this approach can give rise to new divergences and methods that are necessary to make adversarial learning successful. We also discuss new evaluation metrics which are required by the adversarial approach.
Neural Function Modules with Sparse Arguments: A Dynamic Approach to Integrating Information across Layers
Oct 15, 2020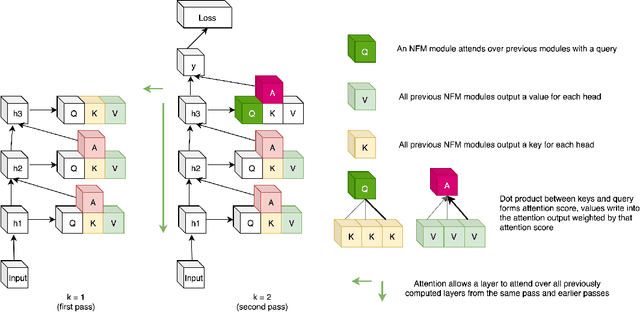


Feed-forward neural networks consist of a sequence of layers, in which each layer performs some processing on the information from the previous layer. A downside to this approach is that each layer (or module, as multiple modules can operate in parallel) is tasked with processing the entire hidden state, rather than a particular part of the state which is most relevant for that module. Methods which only operate on a small number of input variables are an essential part of most programming languages, and they allow for improved modularity and code re-usability. Our proposed method, Neural Function Modules (NFM), aims to introduce the same structural capability into deep learning. Most of the work in the context of feed-forward networks combining top-down and bottom-up feedback is limited to classification problems. The key contribution of our work is to combine attention, sparsity, top-down and bottom-up feedback, in a flexible algorithm which, as we show, improves the results in standard classification, out-of-domain generalization, generative modeling, and learning representations in the context of reinforcement learning.
Object Files and Schemata: Factorizing Declarative and Procedural Knowledge in Dynamical Systems
Jun 30, 2020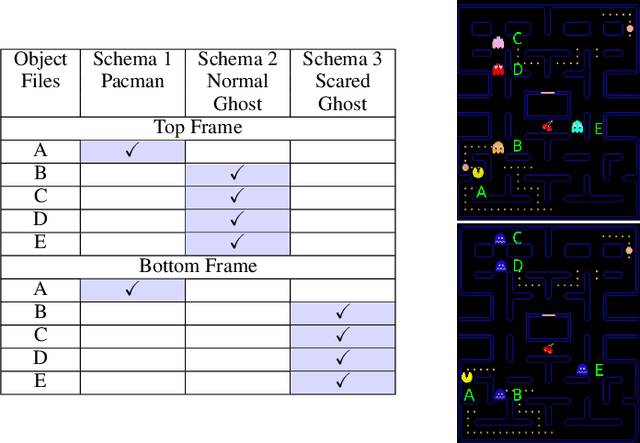
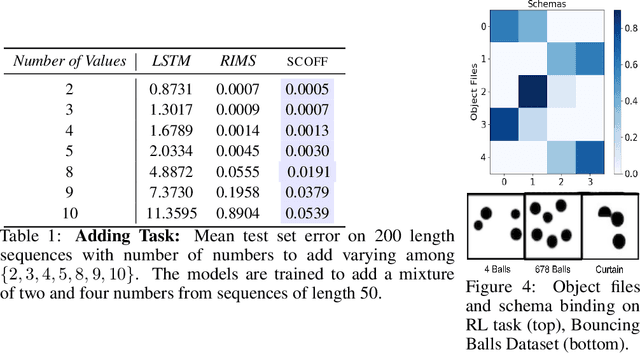
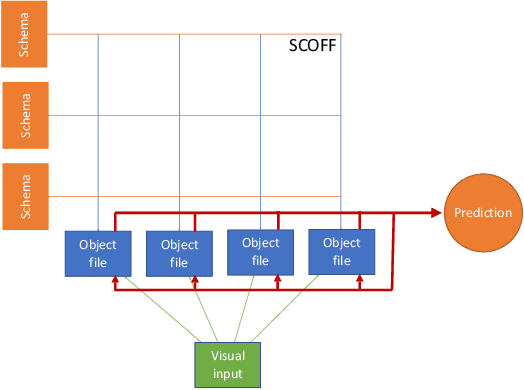

Modeling a structured, dynamic environment like a video game requires keeping track of the objects and their states (\emph{declarative} knowledge) as well as predicting how objects behave (\emph{procedural} knowledge). Black-box models with a monolithic hidden state often lack \emph{systematicity}: they fail to apply procedural knowledge consistently and uniformly. For example, in a video game, correct prediction of one enemy's trajectory does not ensure correct prediction of another's. We address this issue via an architecture that factorizes declarative and procedural knowledge and that imposes modularity within each form of knowledge. The architecture consists of active modules called \emph{object files} that maintain the state of a single object and invoke passive external knowledge sources called \emph{schemata} that prescribe state updates. To use a video game as an illustration, two enemies of the same type will share schemata but will each have their own object file to encode their distinct state (e.g., health, position). We propose to use attention to control the determination of which object files to update, the selection of schemata, and the propagation of information between object files. The resulting architecture is a drop-in replacement conforming to the same input-output interface as normal recurrent networks (e.g., LSTM, GRU) yet achieves substantially better generalization on environments that have factorized declarative and procedural knowledge, including a challenging intuitive physics benchmark.
Learning to Combine Top-Down and Bottom-Up Signals in Recurrent Neural Networks with Attention over Modules
Jun 30, 2020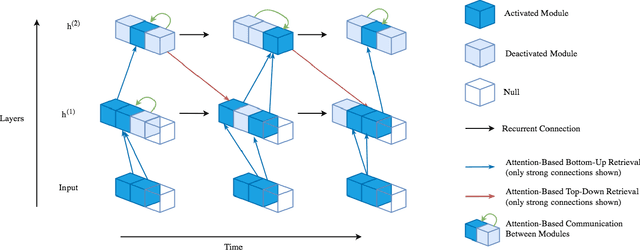
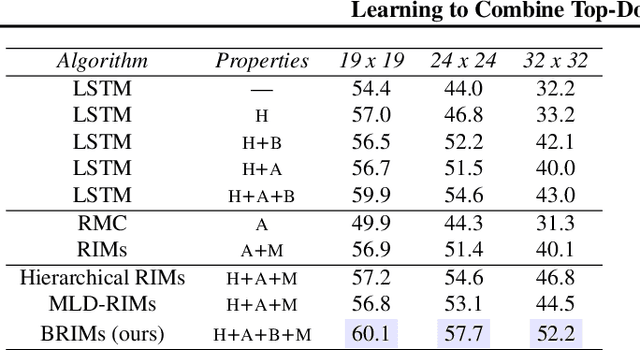
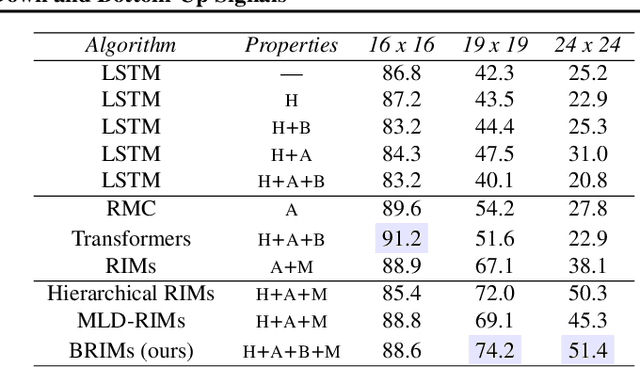
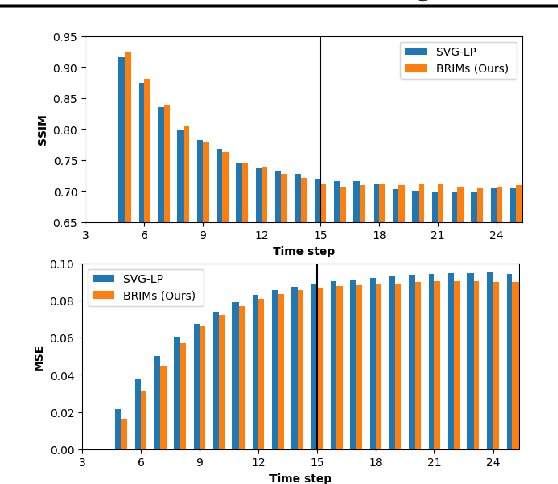
Robust perception relies on both bottom-up and top-down signals. Bottom-up signals consist of what's directly observed through sensation. Top-down signals consist of beliefs and expectations based on past experience and short-term memory, such as how the phrase `peanut butter and~...' will be completed. The optimal combination of bottom-up and top-down information remains an open question, but the manner of combination must be dynamic and both context and task dependent. To effectively utilize the wealth of potential top-down information available, and to prevent the cacophony of intermixed signals in a bidirectional architecture, mechanisms are needed to restrict information flow. We explore deep recurrent neural net architectures in which bottom-up and top-down signals are dynamically combined using attention. Modularity of the architecture further restricts the sharing and communication of information. Together, attention and modularity direct information flow, which leads to reliable performance improvements in perceptual and language tasks, and in particular improves robustness to distractions and noisy data. We demonstrate on a variety of benchmarks in language modeling, sequential image classification, video prediction and reinforcement learning that the \emph{bidirectional} information flow can improve results over strong baselines.
Jigsaw-VAE: Towards Balancing Features in Variational Autoencoders
May 12, 2020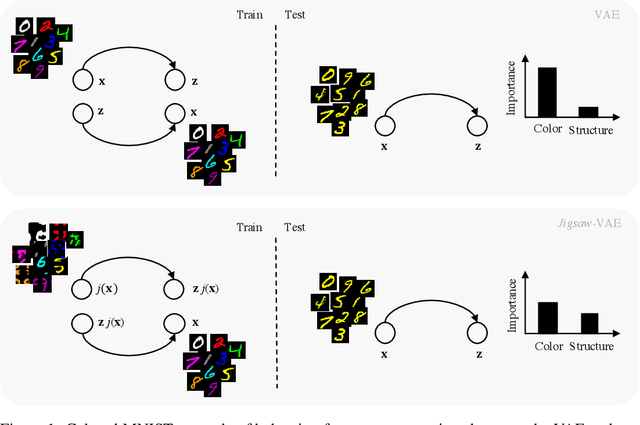
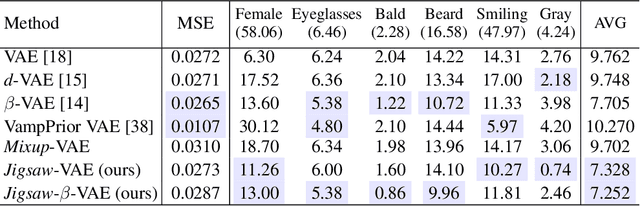
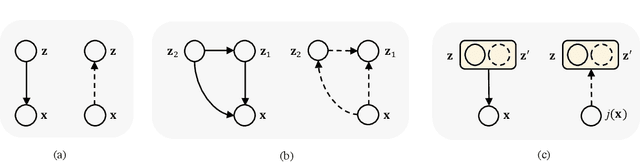
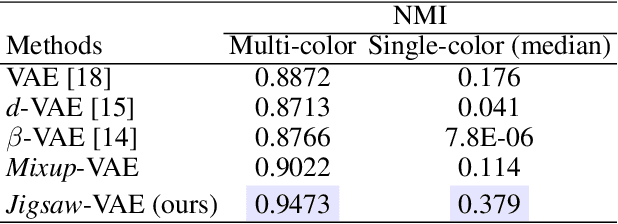
The latent variables learned by VAEs have seen considerable interest as an unsupervised way of extracting features, which can then be used for downstream tasks. There is a growing interest in the question of whether features learned on one environment will generalize across different environments. We demonstrate here that VAE latent variables often focus on some factors of variation at the expense of others - in this case we refer to the features as ``imbalanced''. Feature imbalance leads to poor generalization when the latent variables are used in an environment where the presence of features changes. Similarly, latent variables trained with imbalanced features induce the VAE to generate less diverse (i.e. biased towards dominant features) samples. To address this, we propose a regularization scheme for VAEs, which we show substantially addresses the feature imbalance problem. We also introduce a simple metric to measure the balance of features in generated images.