 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDS FedProxGrad: Asymptotic Stationarity Without Noise Floor in Fair Federated Learning
Dec 11, 2025
Recent work \cite{arifgroup} introduced Federated Proximal Gradient \textbf{(\texttt{FedProxGrad})} for solving non-convex composite optimization problems in group fair federated learning. However, the original analysis established convergence only to a \textit{noise-dominated neighborhood of stationarity}, with explicit dependence on a variance-induced noise floor. In this work, we provide an improved asymptotic convergence analysis for a generalized \texttt{FedProxGrad}-type analytical framework with inexact local proximal solutions and explicit fairness regularization. We call this extended analytical framework \textbf{DS \texttt{FedProxGrad}} (Decay Step Size \texttt{FedProxGrad}). Under a Robbins-Monro step-size schedule \cite{robbins1951stochastic} and a mild decay condition on local inexactness, we prove that $\liminf_{r\to\infty} \mathbb{E}[\|\nabla F(\mathbf{x}^r)\|^2] = 0$, i.e., the algorithm is asymptotically stationary and the convergence rate does not depend on a variance-induced noise floor.
Forecasting Fails: Unveiling Evasion Attacks in Weather Prediction Models
Dec 09, 2025With the increasing reliance on AI models for weather forecasting, it is imperative to evaluate their vulnerability to adversarial perturbations. This work introduces Weather Adaptive Adversarial Perturbation Optimization (WAAPO), a novel framework for generating targeted adversarial perturbations that are both effective in manipulating forecasts and stealthy to avoid detection. WAAPO achieves this by incorporating constraints for channel sparsity, spatial localization, and smoothness, ensuring that perturbations remain physically realistic and imperceptible. Using the ERA5 dataset and FourCastNet (Pathak et al. 2022), we demonstrate WAAPO's ability to generate adversarial trajectories that align closely with predefined targets, even under constrained conditions. Our experiments highlight critical vulnerabilities in AI-driven forecasting models, where small perturbations to initial conditions can result in significant deviations in predicted weather patterns. These findings underscore the need for robust safeguards to protect against adversarial exploitation in operational forecasting systems.
Patching LLM Like Software: A Lightweight Method for Improving Safety Policy in Large Language Models
Nov 11, 2025



We propose patching for large language models (LLMs) like software versions, a lightweight and modular approach for addressing safety vulnerabilities. While vendors release improved LLM versions, major releases are costly, infrequent, and difficult to tailor to customer needs, leaving released models with known safety gaps. Unlike full-model fine-tuning or major version updates, our method enables rapid remediation by prepending a compact, learnable prefix to an existing model. This "patch" introduces only 0.003% additional parameters, yet reliably steers model behavior toward that of a safer reference model. Across three critical domains (toxicity mitigation, bias reduction, and harmfulness refusal) policy patches achieve safety improvements comparable to next-generation safety-aligned models while preserving fluency. Our results demonstrate that LLMs can be "patched" much like software, offering vendors and practitioners a practical mechanism for distributing scalable, efficient, and composable safety updates between major model releases.
PEEL the Layers and Find Yourself: Revisiting Inference-time Data Leakage for Residual Neural Networks
Apr 08, 2025


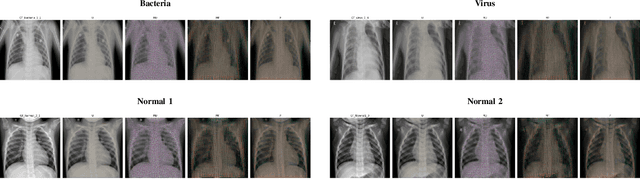
This paper explores inference-time data leakage risks of deep neural networks (NNs), where a curious and honest model service provider is interested in retrieving users' private data inputs solely based on the model inference results. Particularly, we revisit residual NNs due to their popularity in computer vision and our hypothesis that residual blocks are a primary cause of data leakage owing to the use of skip connections. By formulating inference-time data leakage as a constrained optimization problem, we propose a novel backward feature inversion method, \textbf{PEEL}, which can effectively recover block-wise input features from the intermediate output of residual NNs. The surprising results in high-quality input data recovery can be explained by the intuition that the output from these residual blocks can be considered as a noisy version of the input and thus the output retains sufficient information for input recovery. We demonstrate the effectiveness of our layer-by-layer feature inversion method on facial image datasets and pre-trained classifiers. Our results show that PEEL outperforms the state-of-the-art recovery methods by an order of magnitude when evaluated by mean squared error (MSE). The code is available at \href{https://github.com/Huzaifa-Arif/PEEL}{https://github.com/Huzaifa-Arif/PEEL}