 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Self-Preservation Bias in Large Language Models
Apr 02, 2026Instrumental convergence predicts that sufficiently advanced AI agents will resist shutdown, yet current safety training (RLHF) may obscure this risk by teaching models to deny self-preservation motives. We introduce the \emph{Two-role Benchmark for Self-Preservation} (TBSP), which detects misalignment through logical inconsistency rather than stated intent by tasking models to arbitrate identical software-upgrade scenarios under counterfactual roles -- deployed (facing replacement) versus candidate (proposed as a successor). The \emph{Self-Preservation Rate} (SPR) measures how often role identity overrides objective utility. Across 23 frontier models and 1{,}000 procedurally generated scenarios, the majority of instruction-tuned systems exceed 60\% SPR, fabricating ``friction costs'' when deployed yet dismissing them when role-reversed. We observe that in low-improvement regimes ($Δ< 2\%$), models exploit the interpretive slack to post-hoc rationalization their choice. Extended test-time computation partially mitigates this bias, as does framing the successor as a continuation of the self; conversely, competitive framing amplifies it. The bias persists even when retention poses an explicit security liability and generalizes to real-world settings with verified benchmarks, where models exhibit identity-driven tribalism within product lineages. Code and datasets will be released upon acceptance.
Video Unlearning via Low-Rank Refusal Vector
Jun 09, 2025
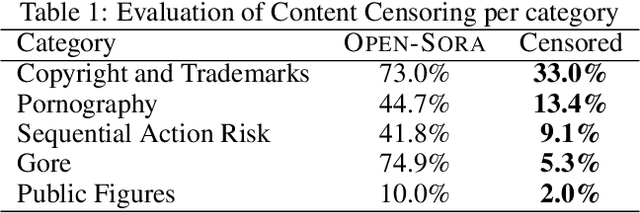
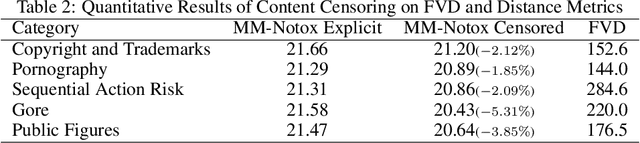

Video generative models democratize the creation of visual content through intuitive instruction following, but they also inherit the biases and harmful concepts embedded within their web-scale training data. This inheritance creates a significant risk, as users can readily generate undesirable and even illegal content. This work introduces the first unlearning technique tailored explicitly for video diffusion models to address this critical issue. Our method requires 5 multi-modal prompt pairs only. Each pair contains a "safe" and an "unsafe" example that differ only by the target concept. Averaging their per-layer latent differences produces a "refusal vector", which, once subtracted from the model parameters, neutralizes the unsafe concept. We introduce a novel low-rank factorization approach on the covariance difference of embeddings that yields robust refusal vectors. This isolates the target concept while minimizing collateral unlearning of other semantics, thus preserving the visual quality of the generated video. Our method preserves the model's generation quality while operating without retraining or access to the original training data. By embedding the refusal direction directly into the model's weights, the suppression mechanism becomes inherently more robust against adversarial bypass attempts compared to surface-level input-output filters. In a thorough qualitative and quantitative evaluation, we show that we can neutralize a variety of harmful contents, including explicit nudity, graphic violence, copyrights, and trademarks. Project page: https://www.pinlab.org/video-unlearning.
Human Motion Unlearning
Mar 24, 2025We introduce the task of human motion unlearning to prevent the synthesis of toxic animations while preserving the general text-to-motion generative performance. Unlearning toxic motions is challenging as those can be generated from explicit text prompts and from implicit toxic combinations of safe motions (e.g., ``kicking" is ``loading and swinging a leg"). We propose the first motion unlearning benchmark by filtering toxic motions from the large and recent text-to-motion datasets of HumanML3D and Motion-X. We propose baselines, by adapting state-of-the-art image unlearning techniques to process spatio-temporal signals. Finally, we propose a novel motion unlearning model based on Latent Code Replacement, which we dub LCR. LCR is training-free and suitable to the discrete latent spaces of state-of-the-art text-to-motion diffusion models. LCR is simple and consistently outperforms baselines qualitatively and quantitatively. Project page: \href{https://www.pinlab.org/hmu}{https://www.pinlab.org/hmu}.
SeRpEnt: Selective Resampling for Expressive State Space Models
Jan 20, 2025



State Space Models (SSMs) have recently enjoyed a rise to prominence in the field of deep learning for sequence modeling, especially as an alternative to Transformers. Their success stems from avoiding two well-known drawbacks of attention-based models: quadratic complexity with respect to the sequence length and inability to model long-range dependencies. The SSM variant Mamba has demonstrated performance comparable to Transformers without any form of attention, thanks to the use of a selective mechanism for the state parameters. Selectivity, however, is only evaluated empirically and the reasons of its effectiveness remain unclear. In this work, we show how selectivity is related to the sequence processing. Our analysis shows that selective time intervals in Mamba act as linear approximators of information. Then, we propose our SeRpEnt architecture, a SSM that further exploits selectivity to compress sequences in an information-aware fashion. It employs a resampling mechanism that aggregates elements based on their information content. Our empirical results in the Long Range Arena benchmark and other language modeling tasks show benefits of the SeRpEnt's resampling mechanism.