 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconstructing Instruction-Following: A New Benchmark for Granular Evaluation of Large Language Model Instruction Compliance Abilities
Jan 26, 2026Reliably ensuring Large Language Models (LLMs) follow complex instructions is a critical challenge, as existing benchmarks often fail to reflect real-world use or isolate compliance from task success. We introduce MOSAIC (MOdular Synthetic Assessment of Instruction Compliance), a modular framework that uses a dynamically generated dataset with up to 20 application-oriented generation constraints to enable a granular and independent analysis of this capability. Our evaluation of five LLMs from different families based on this new benchmark demonstrates that compliance is not a monolithic capability but varies significantly with constraint type, quantity, and position. The analysis reveals model-specific weaknesses, uncovers synergistic and conflicting interactions between instructions, and identifies distinct positional biases such as primacy and recency effects. These granular insights are critical for diagnosing model failures and developing more reliable LLMs for systems that demand strict adherence to complex instructions.
Enhancing LLM Instruction Following: An Evaluation-Driven Multi-Agentic Workflow for Prompt Instructions Optimization
Jan 06, 2026Large Language Models (LLMs) often generate substantively relevant content but fail to adhere to formal constraints, leading to outputs that are conceptually correct but procedurally flawed. Traditional prompt refinement approaches focus on rephrasing the description of the primary task an LLM has to perform, neglecting the granular constraints that function as acceptance criteria for its response. We propose a novel multi-agentic workflow that decouples optimization of the primary task description from its constraints, using quantitative scores as feedback to iteratively rewrite and improve them. Our evaluation demonstrates this method produces revised prompts that yield significantly higher compliance scores from models like Llama 3.1 8B and Mixtral-8x 7B.
Towards Theme Detection in Personal Finance Questions
Oct 04, 2021
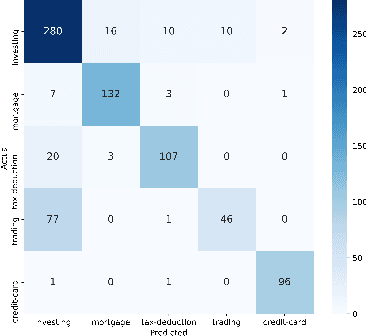
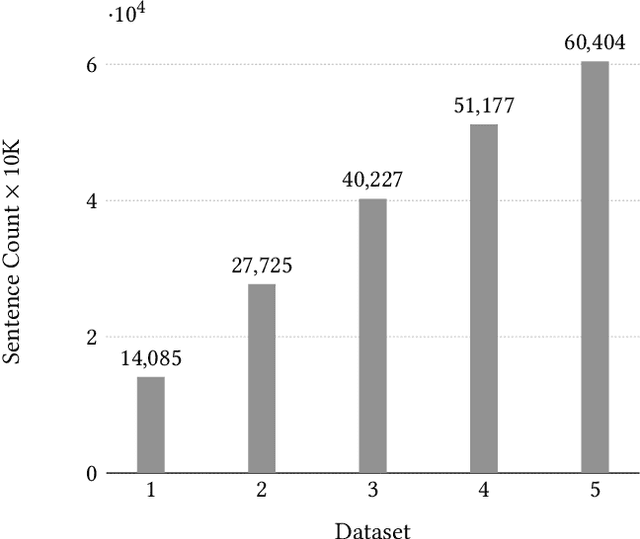
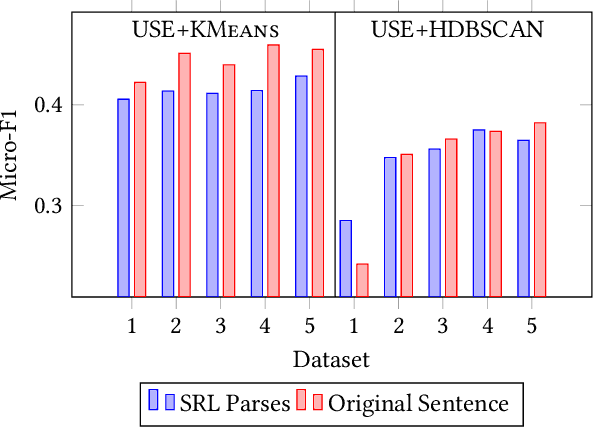
Banking call centers receive millions of calls annually, with much of the information in these calls unavailable to analysts interested in tracking new and emerging call center trends. In this study we present an approach to call center theme detection that captures the occurrence of multiple themes in a question, using a publicly available corpus of StackExchange personal finance questions, labeled by users with topic tags, as a testbed. To capture the occurrence of multiple themes in a single question, the approach encodes and clusters at the sentence- rather than question-level. We also present a comparison of state-of-the-art sentence encoding models, including the SBERT family of sentence encoders. We frame our evaluation as a multiclass classification task and show that a simple combination of the original sentence text, Universal Sentence Encoder, and KMeans outperforms more sophisticated techniques that involve semantic parsing, SBERT-family models, and HDBSCAN. Our highest performing approach achieves a Micro-F1 of 0.46 for this task and we show that the resulting clusters, even when slightly noisy, contain sentences that are topically consistent with the label associated with the cluster.