 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHIELD: An Auto-Healing Agentic Defense Framework for LLM Resource Exhaustion Attacks
Jan 27, 2026Sponge attacks increasingly threaten LLM systems by inducing excessive computation and DoS. Existing defenses either rely on statistical filters that fail on semantically meaningful attacks or use static LLM-based detectors that struggle to adapt as attack strategies evolve. We introduce SHIELD, a multi-agent, auto-healing defense framework centered on a three-stage Defense Agent that integrates semantic similarity retrieval, pattern matching, and LLM-based reasoning. Two auxiliary agents, a Knowledge Updating Agent and a Prompt Optimization Agent, form a closed self-healing loop, when an attack bypasses detection, the system updates an evolving knowledgebase, and refines defense instructions. Extensive experiments show that SHIELD consistently outperforms perplexity-based and standalone LLM defenses, achieving high F1 scores across both non-semantic and semantic sponge attacks, demonstrating the effectiveness of agentic self-healing against evolving resource-exhaustion threats.
Multi-level Explanation of Deep Reinforcement Learning-based Scheduling
Sep 18, 2022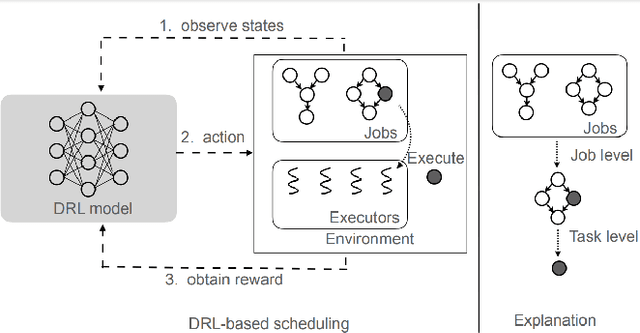
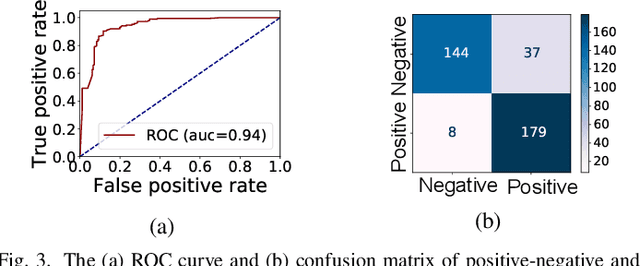
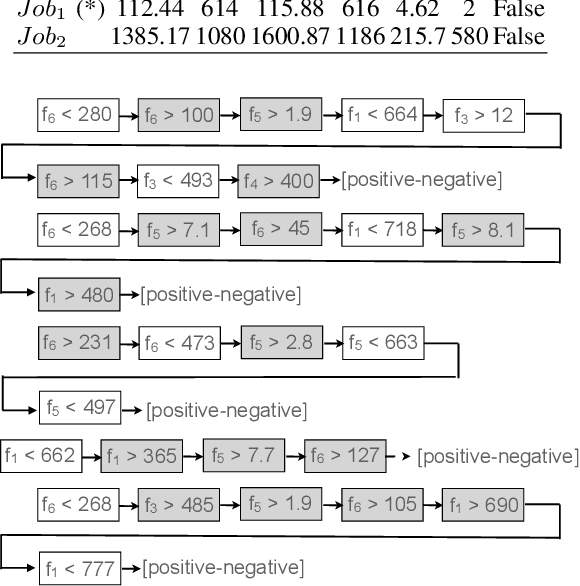
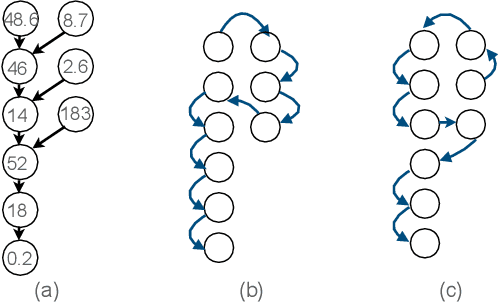
Dependency-aware job scheduling in the cluster is NP-hard. Recent work shows that Deep Reinforcement Learning (DRL) is capable of solving it. It is difficult for the administrator to understand the DRL-based policy even though it achieves remarkable performance gain. Therefore the complex model-based scheduler is not easy to gain trust in the system where simplicity is favored. In this paper, we give the multi-level explanation framework to interpret the policy of DRL-based scheduling. We dissect its decision-making process to job level and task level and approximate each level with interpretable models and rules, which align with operational practices. We show that the framework gives the system administrator insights into the state-of-the-art scheduler and reveals the robustness issue in regards to its behavior pattern.
Multi-Component Optimization and Efficient Deployment of Neural-Networks on Resource-Constrained IoT Hardware
Apr 20, 2022
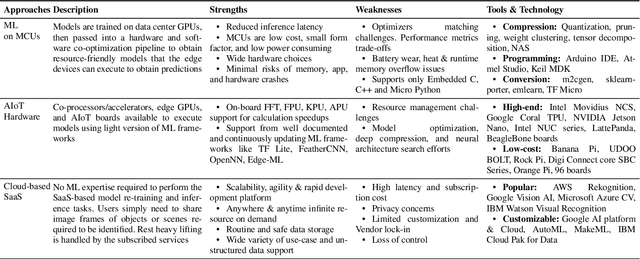
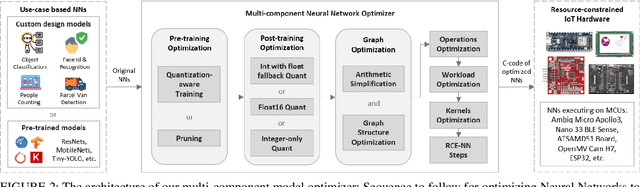
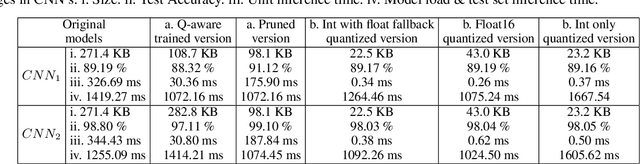
The majority of IoT devices like smartwatches, smart plugs, HVAC controllers, etc., are powered by hardware with a constrained specification (low memory, clock speed and processor) which is insufficient to accommodate and execute large, high-quality models. On such resource-constrained devices, manufacturers still manage to provide attractive functionalities (to boost sales) by following the traditional approach of programming IoT devices/products to collect and transmit data (image, audio, sensor readings, etc.) to their cloud-based ML analytics platforms. For decades, this online approach has been facing issues such as compromised data streams, non-real-time analytics due to latency, bandwidth constraints, costly subscriptions, recent privacy issues raised by users and the GDPR guidelines, etc. In this paper, to enable ultra-fast and accurate AI-based offline analytics on resource-constrained IoT devices, we present an end-to-end multi-component model optimization sequence and open-source its implementation. Researchers and developers can use our optimization sequence to optimize high memory, computation demanding models in multiple aspects in order to produce small size, low latency, low-power consuming models that can comfortably fit and execute on resource-constrained hardware. The experimental results show that our optimization components can produce models that are; (i) 12.06 x times compressed; (ii) 0.13% to 0.27% more accurate; (iii) Orders of magnitude faster unit inference at 0.06 ms. Our optimization sequence is generic and can be applied to any state-of-the-art models trained for anomaly detection, predictive maintenance, robotics, voice recognition, and machine vision.