 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreePiece: Faster Semantic Parsing via Tree Tokenization
Mar 30, 2023



Autoregressive (AR) encoder-decoder neural networks have proved successful in many NLP problems, including Semantic Parsing -- a task that translates natural language to machine-readable parse trees. However, the sequential prediction process of AR models can be slow. To accelerate AR for semantic parsing, we introduce a new technique called TreePiece that tokenizes a parse tree into subtrees and generates one subtree per decoding step. On TopV2 benchmark, TreePiece shows 4.6 times faster decoding speed than standard AR, and comparable speed but significantly higher accuracy compared to Non-Autoregressive (NAR).
Privately Customizing Prefinetuning to Better Match User Data in Federated Learning
Feb 23, 2023



In Federated Learning (FL), accessing private client data incurs communication and privacy costs. As a result, FL deployments commonly prefinetune pretrained foundation models on a (large, possibly public) dataset that is held by the central server; they then FL-finetune the model on a private, federated dataset held by clients. Evaluating prefinetuning dataset quality reliably and privately is therefore of high importance. To this end, we propose FreD (Federated Private Fr\'echet Distance) -- a privately computed distance between a prefinetuning dataset and federated datasets. Intuitively, it privately computes and compares a Fr\'echet distance between embeddings generated by a large language model on both the central (public) dataset and the federated private client data. To make this computation privacy-preserving, we use distributed, differentially-private mean and covariance estimators. We show empirically that FreD accurately predicts the best prefinetuning dataset at minimal privacy cost. Altogether, using FreD we demonstrate a proof-of-concept for a new approach in private FL training: (1) customize a prefinetuning dataset to better match user data (2) prefinetune (3) perform FL-finetuning.
Introducing Semantics into Speech Encoders
Nov 15, 2022



Recent studies find existing self-supervised speech encoders contain primarily acoustic rather than semantic information. As a result, pipelined supervised automatic speech recognition (ASR) to large language model (LLM) systems achieve state-of-the-art results on semantic spoken language tasks by utilizing rich semantic representations from the LLM. These systems come at the cost of labeled audio transcriptions, which is expensive and time-consuming to obtain. We propose a task-agnostic unsupervised way of incorporating semantic information from LLMs into self-supervised speech encoders without labeled audio transcriptions. By introducing semantics, we improve existing speech encoder spoken language understanding performance by over 10\% on intent classification, with modest gains in named entity resolution and slot filling, and spoken question answering FF1 score by over 2\%. Our unsupervised approach achieves similar performance as supervised methods trained on over 100 hours of labeled audio transcripts, demonstrating the feasibility of unsupervised semantic augmentations to existing speech encoders.
Data-Efficiency with a Single GPU: An Exploration of Transfer Methods for Small Language Models
Oct 08, 2022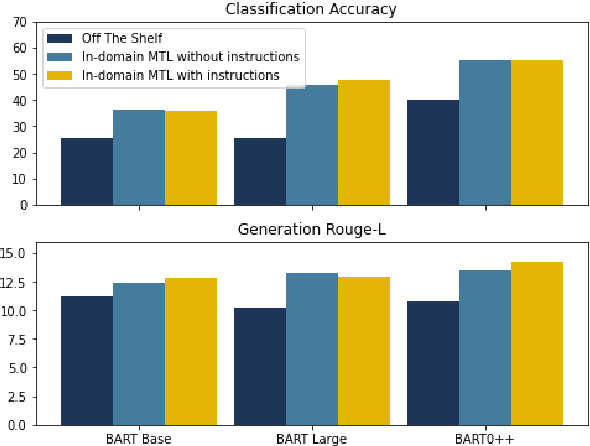
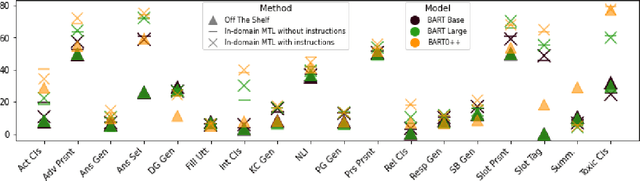
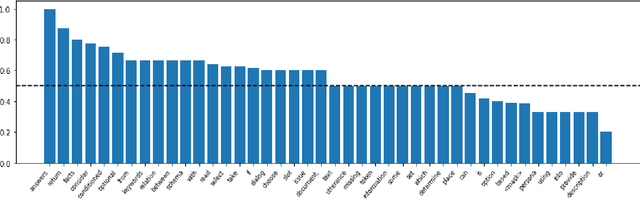
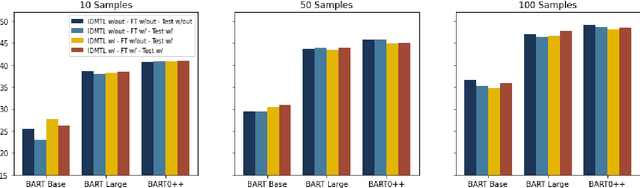
Multi-task learning (MTL), instruction tuning, and prompting have recently been shown to improve the generalizability of large language models to new tasks. However, the benefits of such methods are less well-documented in smaller language models, with some studies finding contradictory results. In this work, we explore and isolate the effects of (i) model size, (ii) general purpose MTL, (iii) in-domain MTL, (iv) instruction tuning, and (v) few-shot fine-tuning for models with fewer than 500 million parameters. Our experiments in the zero-shot setting demonstrate that models gain 31% relative improvement, on average, from general purpose MTL, with an additional 37.6% relative gain from in-domain MTL. Contradictory to prior works on large models, we find that instruction tuning provides a modest 2% performance improvement for small models.
Deliberation Model for On-Device Spoken Language Understanding
Apr 04, 2022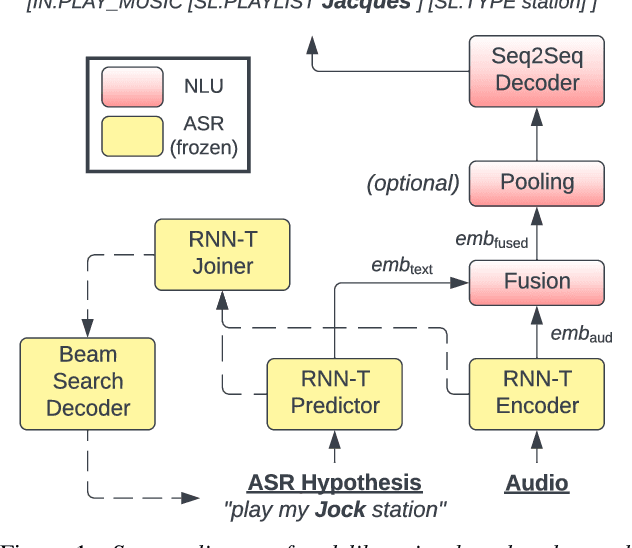

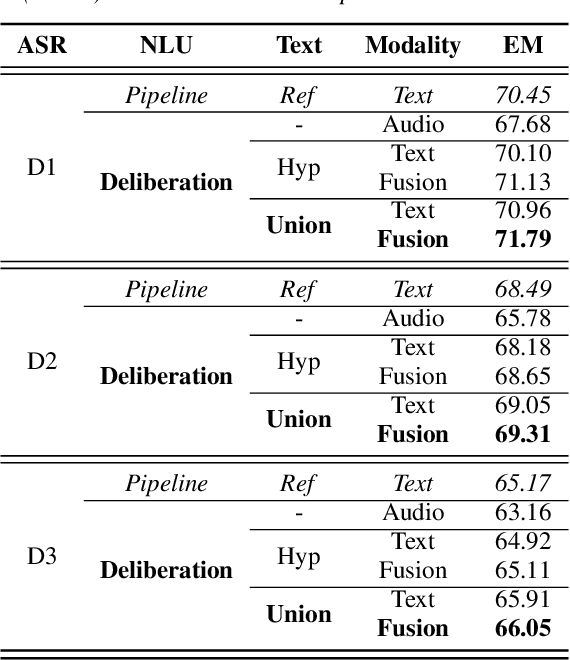
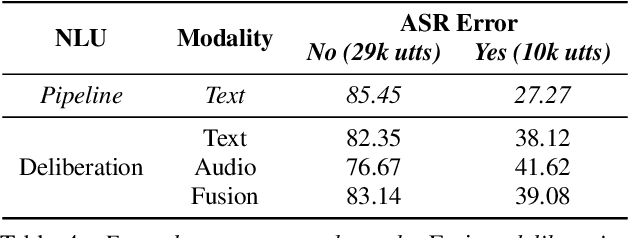
We propose a novel deliberation-based approach to end-to-end (E2E) spoken language understanding (SLU), where a streaming automatic speech recognition (ASR) model produces the first-pass hypothesis and a second-pass natural language understanding (NLU) component generates the semantic parse by conditioning on both ASR's text and audio embeddings. By formulating E2E SLU as a generalized decoder, our system is able to support complex compositional semantic structures. Furthermore, the sharing of parameters between ASR and NLU makes the system especially suitable for resource-constrained (on-device) environments; our proposed approach consistently outperforms strong pipeline NLU baselines by 0.82% to 1.34% across various operating points on the spoken version of the TOPv2 dataset. We demonstrate that the fusion of text and audio features, coupled with the system's ability to rewrite the first-pass hypothesis, makes our approach more robust to ASR errors. Finally, we show that our approach can significantly reduce the degradation when moving from natural speech to synthetic speech training, but more work is required to make text-to-speech (TTS) a viable solution for scaling up E2E SLU.
Retrieve-and-Fill for Scenario-based Task-Oriented Semantic Parsing
Feb 02, 2022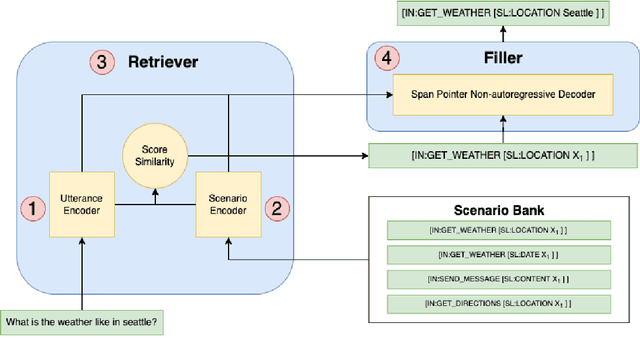
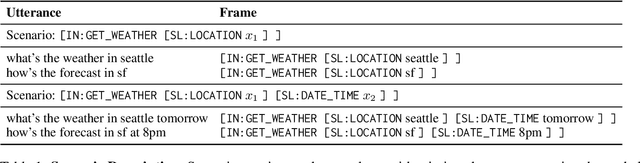
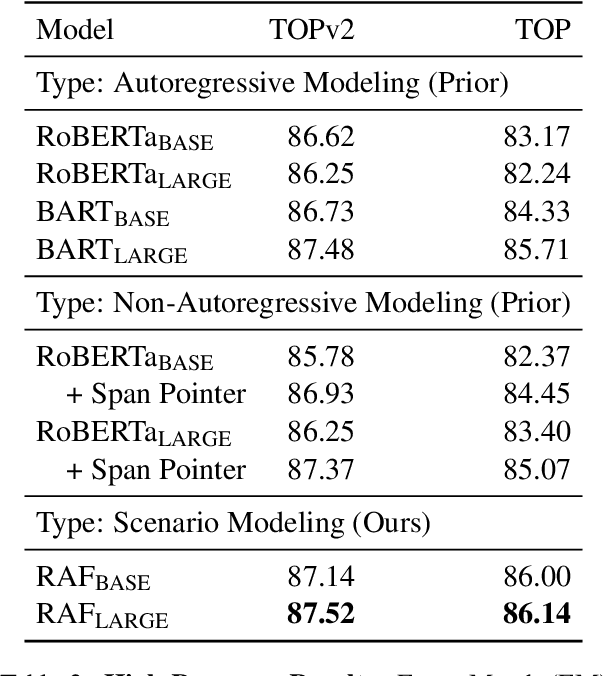

Task-oriented semantic parsing models have achieved strong results in recent years, but unfortunately do not strike an appealing balance between model size, runtime latency, and cross-domain generalizability. We tackle this problem by introducing scenario-based semantic parsing: a variant of the original task which first requires disambiguating an utterance's "scenario" (an intent-slot template with variable leaf spans) before generating its frame, complete with ontology and utterance tokens. This formulation enables us to isolate coarse-grained and fine-grained aspects of the task, each of which we solve with off-the-shelf neural modules, also optimizing for the axes outlined above. Concretely, we create a Retrieve-and-Fill (RAF) architecture comprised of (1) a retrieval module which ranks the best scenario given an utterance and (2) a filling module which imputes spans into the scenario to create the frame. Our model is modular, differentiable, interpretable, and allows us to garner extra supervision from scenarios. RAF achieves strong results in high-resource, low-resource, and multilingual settings, outperforming recent approaches by wide margins despite, using base pre-trained encoders, small sequence lengths, and parallel decoding.
RETRONLU: Retrieval Augmented Task-Oriented Semantic Parsing
Sep 21, 2021
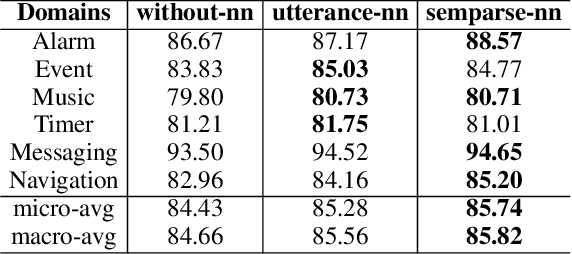
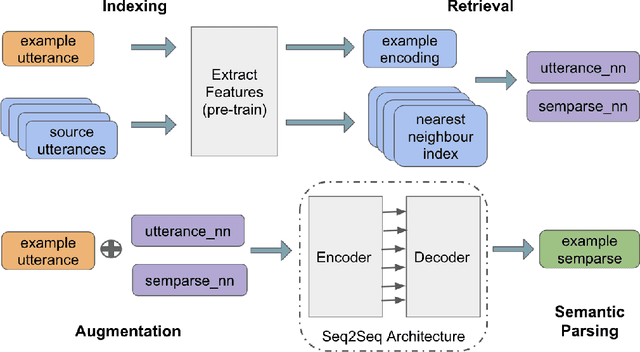
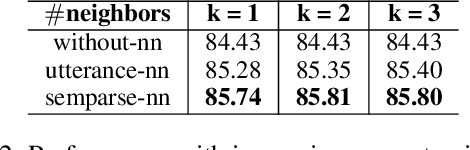
While large pre-trained language models accumulate a lot of knowledge in their parameters, it has been demonstrated that augmenting it with non-parametric retrieval-based memory has a number of benefits from accuracy improvements to data efficiency for knowledge-focused tasks, such as question answering. In this paper, we are applying retrieval-based modeling ideas to the problem of multi-domain task-oriented semantic parsing for conversational assistants. Our approach, RetroNLU, extends a sequence-to-sequence model architecture with a retrieval component, used to fetch existing similar examples and provide them as an additional input to the model. In particular, we analyze two settings, where we augment an input with (a) retrieved nearest neighbor utterances (utterance-nn), and (b) ground-truth semantic parses of nearest neighbor utterances (semparse-nn). Our technique outperforms the baseline method by 1.5% absolute macro-F1, especially at the low resource setting, matching the baseline model accuracy with only 40% of the data. Furthermore, we analyze the nearest neighbor retrieval component's quality, model sensitivity and break down the performance for semantic parses of different utterance complexity.
Assessing Data Efficiency in Task-Oriented Semantic Parsing
Jul 10, 2021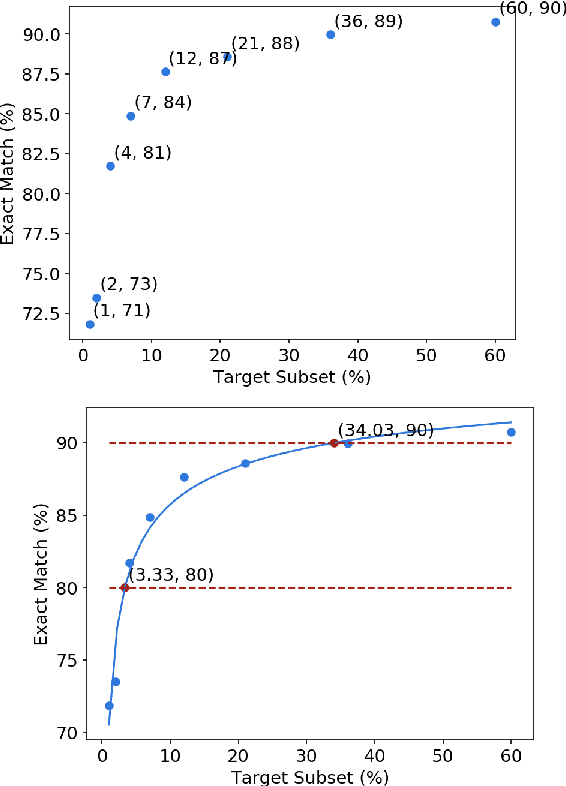
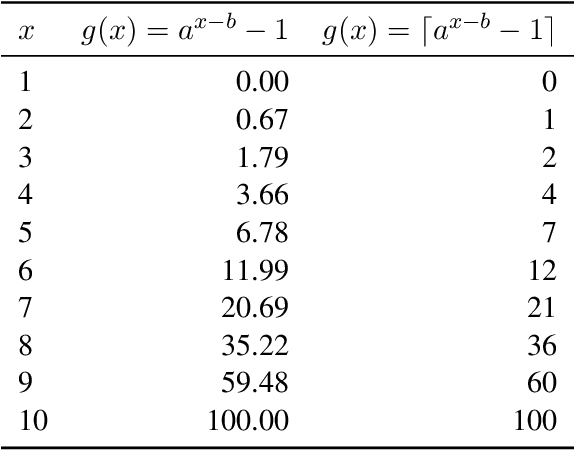
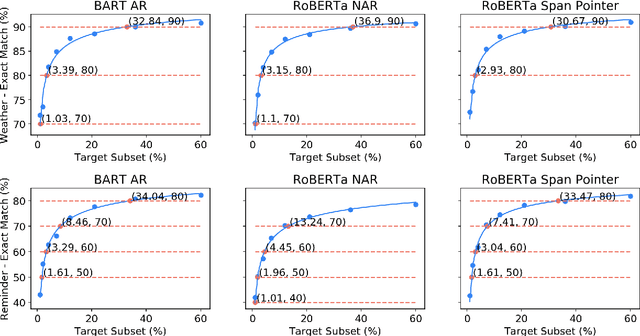

Data efficiency, despite being an attractive characteristic, is often challenging to measure and optimize for in task-oriented semantic parsing; unlike exact match, it can require both model- and domain-specific setups, which have, historically, varied widely across experiments. In our work, as a step towards providing a unified solution to data-efficiency-related questions, we introduce a four-stage protocol which gives an approximate measure of how much in-domain, "target" data a parser requires to achieve a certain quality bar. Specifically, our protocol consists of (1) sampling target subsets of different cardinalities, (2) fine-tuning parsers on each subset, (3) obtaining a smooth curve relating target subset (%) vs. exact match (%), and (4) referencing the curve to mine ad-hoc (target subset, exact match) points. We apply our protocol in two real-world case studies -- model generalizability and intent complexity -- illustrating its flexibility and applicability to practitioners in task-oriented semantic parsing.
Latency-Aware Neural Architecture Search with Multi-Objective Bayesian Optimization
Jun 25, 2021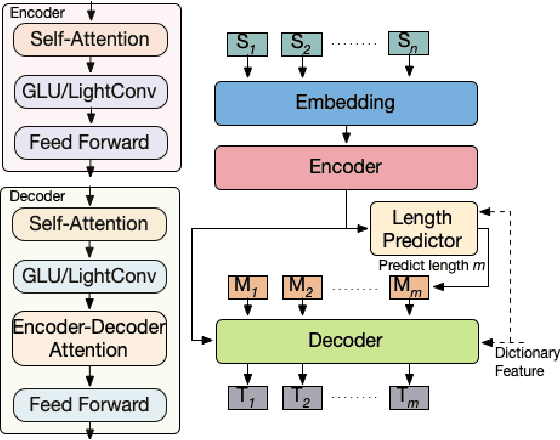

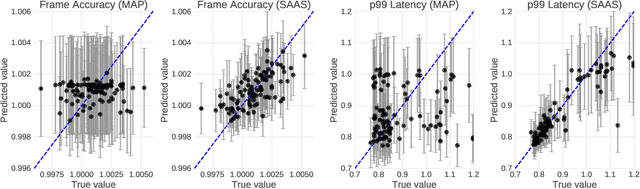
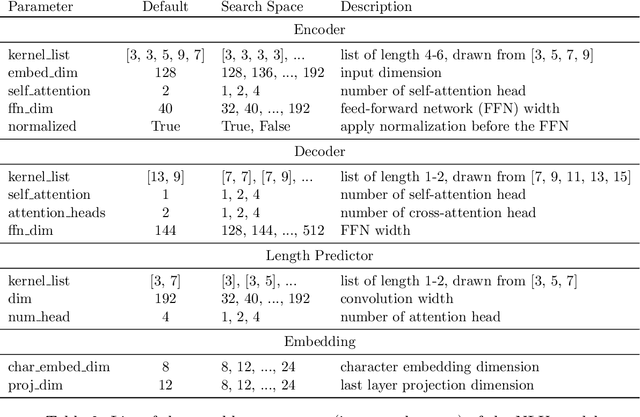
When tuning the architecture and hyperparameters of large machine learning models for on-device deployment, it is desirable to understand the optimal trade-offs between on-device latency and model accuracy. In this work, we leverage recent methodological advances in Bayesian optimization over high-dimensional search spaces and multi-objective Bayesian optimization to efficiently explore these trade-offs for a production-scale on-device natural language understanding model at Facebook.
Span Pointer Networks for Non-Autoregressive Task-Oriented Semantic Parsing
Apr 16, 2021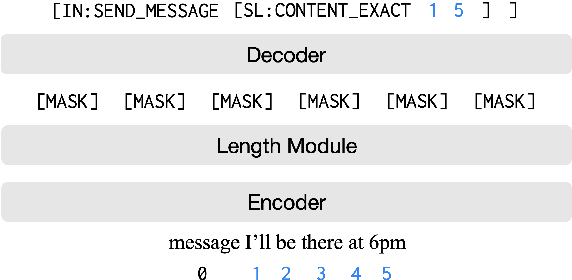

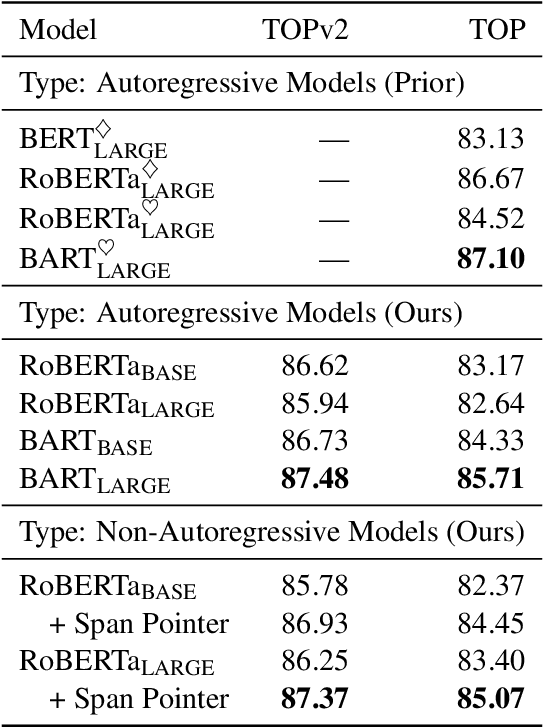
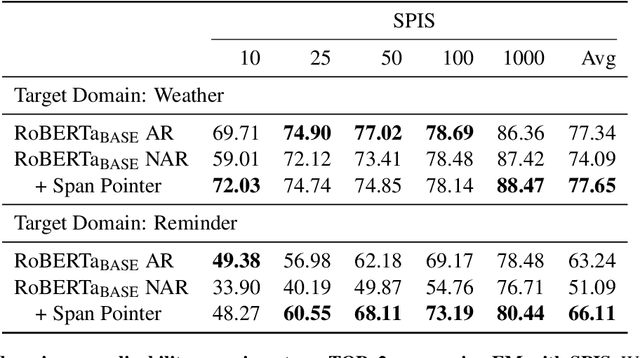
An effective recipe for building seq2seq, non-autoregressive, task-oriented parsers to map utterances to semantic frames proceeds in three steps: encoding an utterance $x$, predicting a frame's length |y|, and decoding a |y|-sized frame with utterance and ontology tokens. Though empirically strong, these models are typically bottlenecked by length prediction, as even small inaccuracies change the syntactic and semantic characteristics of resulting frames. In our work, we propose span pointer networks, non-autoregressive parsers which shift the decoding task from text generation to span prediction; that is, when imputing utterance spans into frame slots, our model produces endpoints (e.g., [i, j]) as opposed to text (e.g., "6pm"). This natural quantization of the output space reduces the variability of gold frames, therefore improving length prediction and, ultimately, exact match. Furthermore, length prediction is now responsible for frame syntax and the decoder is responsible for frame semantics, resulting in a coarse-to-fine model. We evaluate our approach on several task-oriented semantic parsing datasets. Notably, we bridge the quality gap between non-autogressive and autoregressive parsers, achieving 87 EM on TOPv2 (Chen et al. 2020). Furthermore, due to our more consistent gold frames, we show strong improvements in model generalization in both cross-domain and cross-lingual transfer in low-resource settings. Finally, due to our diminished output vocabulary, we observe 70% reduction in latency and 83% reduction in memory at beam size 5 compared to prior non-autoregressive parsers.