 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactive Flux Matching: Mechanism Discovery and Adaptive Sampling of Rare Events
Jun 04, 2026Path sampling methods generate ensembles of reactive trajectories connecting metastable states, but extracting mechanistic insight from these data remains nontrivial. We introduce Flux Matching, a framework that learns two complementary objects directly from reactive trajectory data: a current velocity $u(z)$, whose streamlines trace the dominant reaction pathways, and a scalar potential $h(z)$, obtained from a weighted Helmholtz-Hodge decomposition of the reactive current, that serves as a data-driven reaction coordinate. Both minimize quadratic functionals over the reactive path ensemble, analogous to the flow matching loss in generative modeling, and require no knowledge of the underlying dynamics or stationary distribution. Unlike committor-based methods, $u$ and $h$ remain well-defined under projection onto non-Markovian collective variables, and their level sets in turn provide adaptive interfaces for improved sampling with enhanced sampling methods. Flux Matching is validated through the generation of current velocity trajectories and rate constant calculations on molecular systems.
Scalable Inference-Time Annealing with Surrogate Likelihood Estimators
Jun 01, 2026A long standing challenge in computational chemistry and biophysics is efficiently sampling the Boltzmann distribution of molecules. Advances in generative modeling have been proposed to address the limitations of conventional sampling techniques by eliminating the computational cost of simulation. A promising direction is iteratively finetuning diffusion models along a temperature ladder whereby training data is generated via importance sampling during inference-time annealing. Unfortunately, these methods require computing a divergence over the score field to estimate importance weights, rendering them intractable for larger systems. Here we present scalable inference-time annealing (SITA), which retrains flow-based models to generate samples at progressively lower temperatures using an energy-based model to facilitate fast surrogate likelihoods. We demonstrate state-of-the-art performance on both Alanine Dipeptide and Alanine Tripeptide while avoiding costly divergence terms. Our code is available at https://github.com/countrsignal/sita.git
BoltzNCE: Learning Likelihoods for Boltzmann Generation with Stochastic Interpolants and Noise Contrastive Estimation
Jul 02, 2025



Efficient sampling from the Boltzmann distribution defined by an energy function is a key challenge in modeling physical systems such as molecules. Boltzmann Generators tackle this by leveraging Continuous Normalizing Flows that transform a simple prior into a distribution that can be reweighted to match the Boltzmann distribution using sample likelihoods. However, obtaining likelihoods requires computing costly Jacobians during integration, making it impractical for large molecular systems. To overcome this, we propose learning the likelihood of the generated distribution via an energy-based model trained with noise contrastive estimation and score matching. By using stochastic interpolants to anneal between the prior and generated distributions, we combine both the objective functions to efficiently learn the density function. On the alanine dipeptide system, we demonstrate that our method yields free energy profiles and energy distributions comparable to those obtained with exact likelihoods. Additionally, we show that free energy differences between metastable states can be estimated accurately with orders-of-magnitude speedup.
APObind: A Dataset of Ligand Unbound Protein Conformations for Machine Learning Applications in De Novo Drug Design
Aug 25, 2021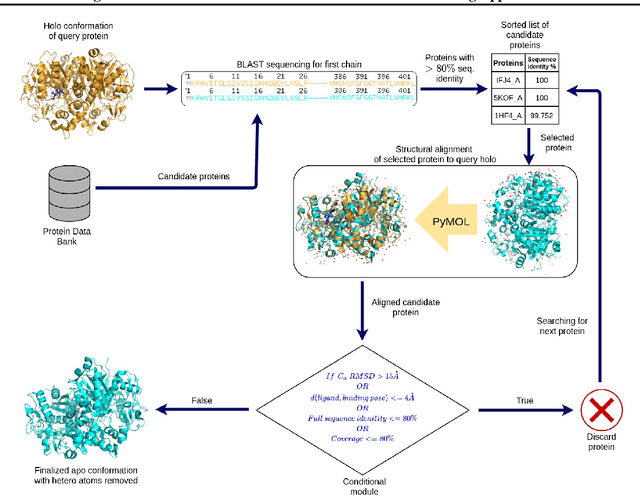

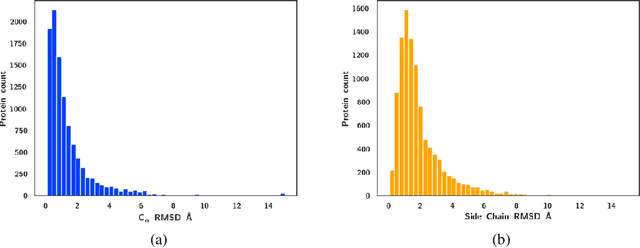
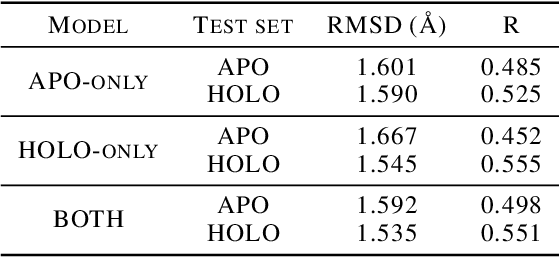
Protein-ligand complex structures have been utilised to design benchmark machine learning methods that perform important tasks related to drug design such as receptor binding site detection, small molecule docking and binding affinity prediction. However, these methods are usually trained on only ligand bound (or holo) conformations of the protein and therefore are not guaranteed to perform well when the protein structure is in its native unbound conformation (or apo), which is usually the conformation available for a newly identified receptor. A primary reason for this is that the local structure of the binding site usually changes upon ligand binding. To facilitate solutions for this problem, we propose a dataset called APObind that aims to provide apo conformations of proteins present in the PDBbind dataset, a popular dataset used in drug design. Furthermore, we explore the performance of methods specific to three use cases on this dataset, through which, the importance of validating them on the APObind dataset is demonstrated.