 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Graphical Memory for Robust Planning
Mar 13, 2020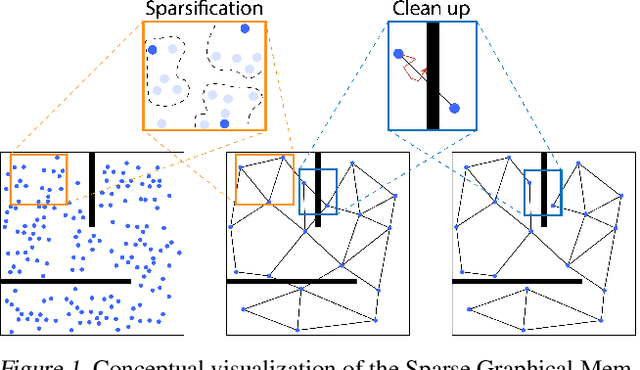
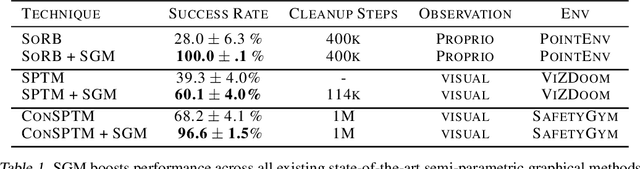
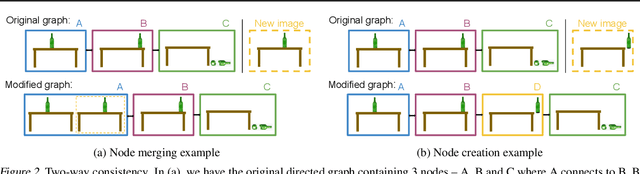
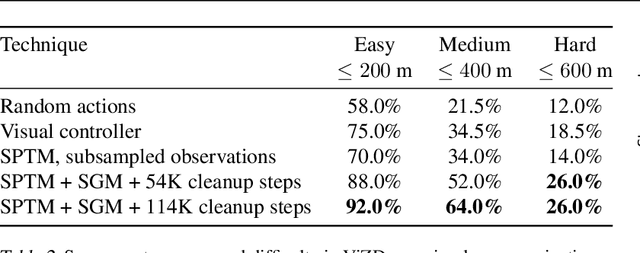
To operate effectively in the real world, artificial agents must act from raw sensory input such as images and achieve diverse goals across long time-horizons. On the one hand, recent strides in deep reinforcement and imitation learning have demonstrated impressive ability to learn goal-conditioned policies from high-dimensional image input, though only for short-horizon tasks. On the other hand, classical graphical methods like A* search are able to solve long-horizon tasks, but assume that the graph structure is abstracted away from raw sensory input and can only be constructed with task-specific priors. We wish to combine the strengths of deep learning and classical planning to solve long-horizon tasks from raw sensory input. To this end, we introduce Sparse Graphical Memory (SGM), a new data structure that stores observations and feasible transitions in a sparse memory. SGM can be combined with goal-conditioned RL or imitative agents to solve long-horizon tasks across a diverse set of domains. We show that SGM significantly outperforms current state of the art methods on long-horizon, sparse-reward visual navigation tasks. Project video and code are available at https://mishalaskin.github.io/sgm/
Discrete Residual Flow for Probabilistic Pedestrian Behavior Prediction
Oct 17, 2019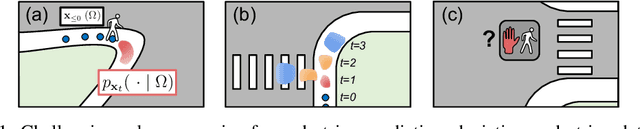
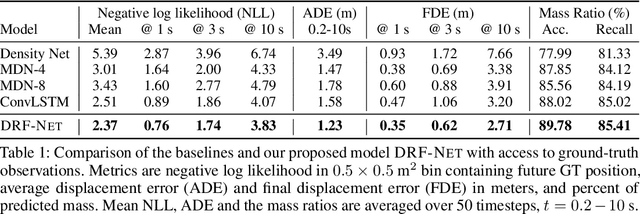
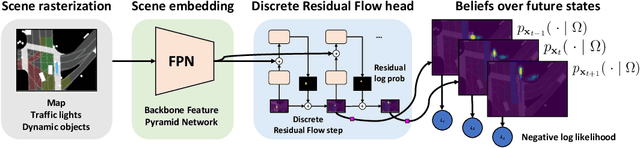
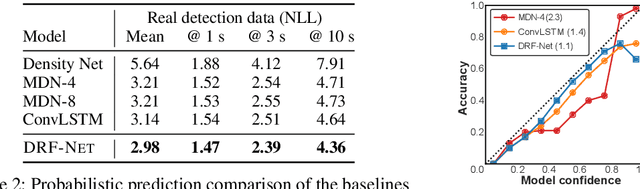
Self-driving vehicles plan around both static and dynamic objects, applying predictive models of behavior to estimate future locations of the objects in the environment. However, future behavior is inherently uncertain, and models of motion that produce deterministic outputs are limited to short timescales. Particularly difficult is the prediction of human behavior. In this work, we propose the discrete residual flow network (DRF-Net), a convolutional neural network for human motion prediction that captures the uncertainty inherent in long-range motion forecasting. In particular, our learned network effectively captures multimodal posteriors over future human motion by predicting and updating a discretized distribution over spatial locations. We compare our model against several strong competitors and show that our model outperforms all baselines.
Checkmate: Breaking the Memory Wall with Optimal Tensor Rematerialization
Oct 07, 2019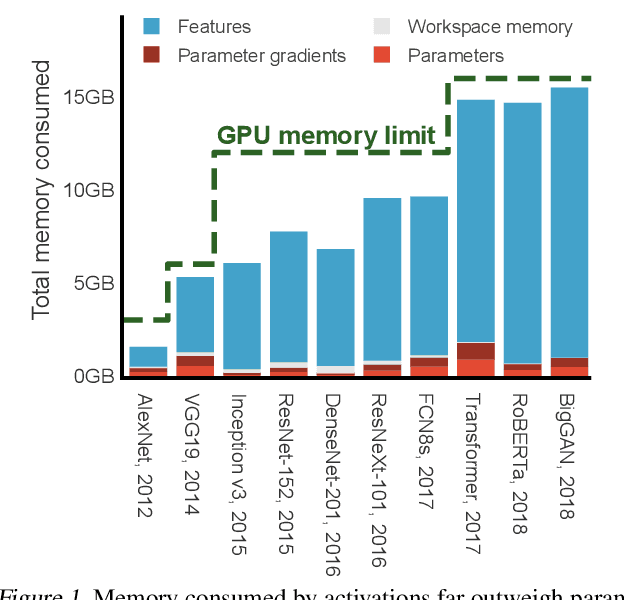

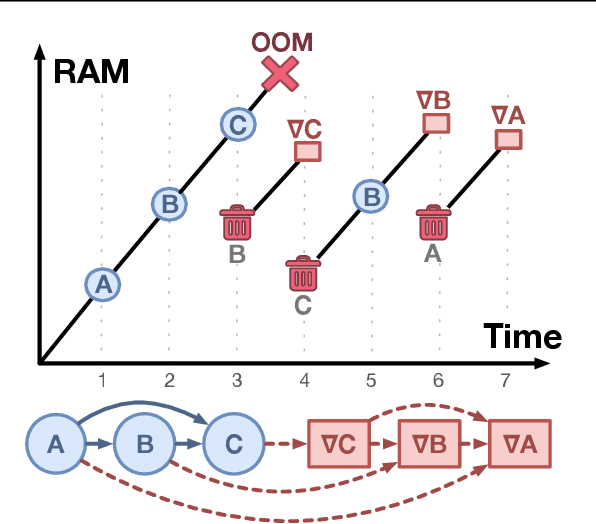
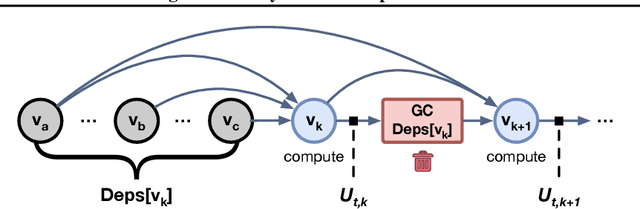
Modern neural networks are increasingly bottlenecked by the limited capacity of on-device GPU memory. Prior work explores dropping activations as a strategy to scale to larger neural networks under memory constraints. However, these heuristics assume uniform per-layer costs and are limited to simple architectures with linear graphs, limiting their usability. In this paper, we formalize the problem of trading-off DNN training time and memory requirements as the tensor rematerialization optimization problem, a generalization of prior checkpointing strategies. We introduce Checkmate, a system that solves for optimal schedules in reasonable times (under an hour) using off-the-shelf MILP solvers, then uses these schedules to accelerate millions of training iterations. Our method scales to complex, realistic architectures and is hardware-aware through the use of accelerator-specific, profile-based cost models. In addition to reducing training cost, Checkmate enables real-world networks to be trained with up to 5.1$\times$ larger input sizes.
The OoO VLIW JIT Compiler for GPU Inference
Jan 31, 2019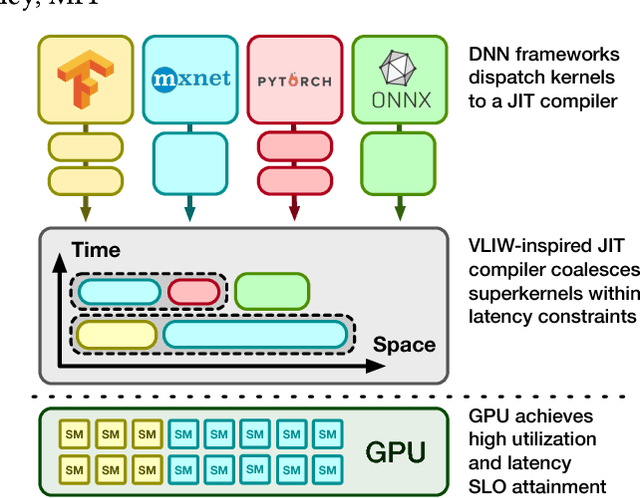

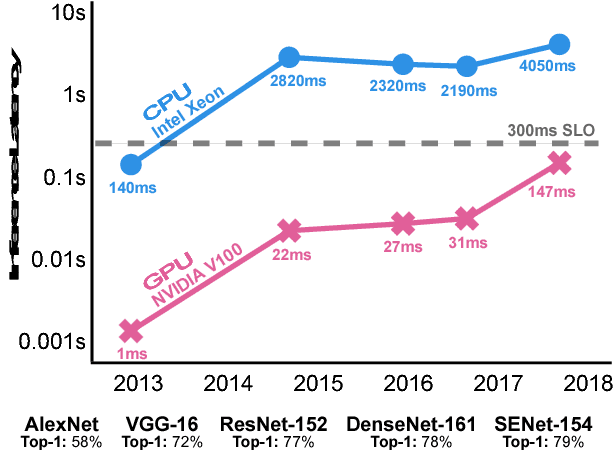
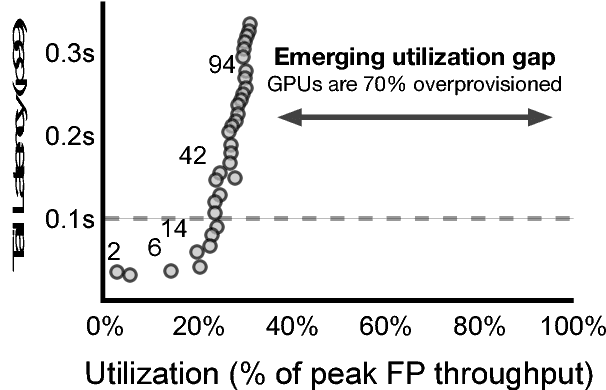
Current trends in Machine Learning~(ML) inference on hardware accelerated devices (e.g., GPUs, TPUs) point to alarmingly low utilization. As ML inference is increasingly time-bounded by tight latency SLOs, increasing data parallelism is not an option. The need for better efficiency motivates GPU multiplexing. Furthermore, existing GPU programming abstractions force programmers to micro-manage GPU resources in an early-binding, context-free fashion. We propose a VLIW-inspired Out-of-Order (OoO) Just-in-Time (JIT) compiler that coalesces and reorders execution kernels at runtime for throughput-optimal device utilization while satisfying latency SLOs. We quantify the inefficiencies of space-only and time-only multiplexing alternatives and demonstrate an achievable 7.7x opportunity gap through spatial coalescing.