 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Training with Weak Supervision
Apr 12, 2021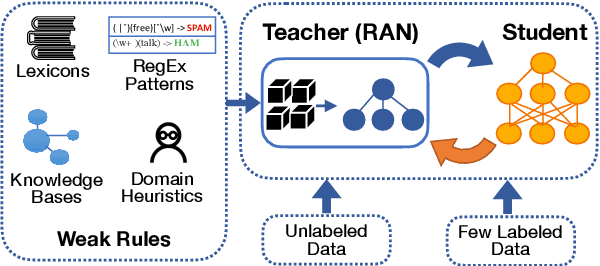
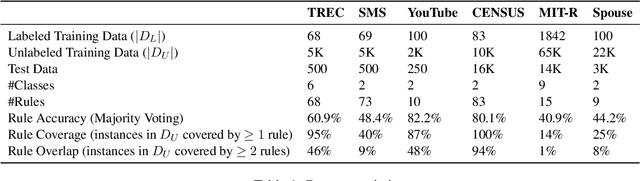
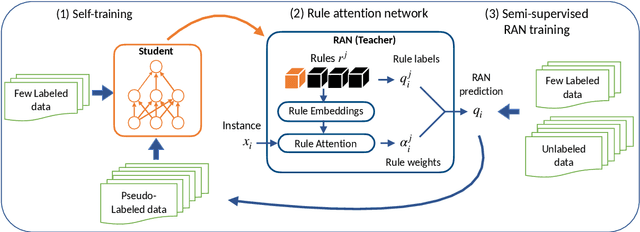
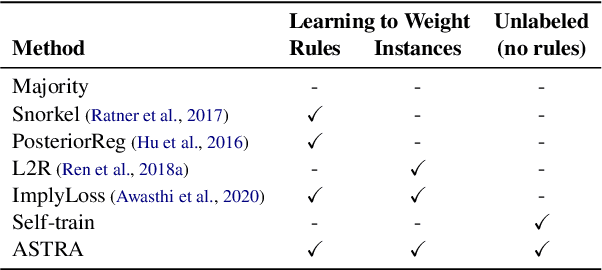
State-of-the-art deep neural networks require large-scale labeled training data that is often expensive to obtain or not available for many tasks. Weak supervision in the form of domain-specific rules has been shown to be useful in such settings to automatically generate weakly labeled training data. However, learning with weak rules is challenging due to their inherent heuristic and noisy nature. An additional challenge is rule coverage and overlap, where prior work on weak supervision only considers instances that are covered by weak rules, thus leaving valuable unlabeled data behind. In this work, we develop a weak supervision framework (ASTRA) that leverages all the available data for a given task. To this end, we leverage task-specific unlabeled data through self-training with a model (student) that considers contextualized representations and predicts pseudo-labels for instances that may not be covered by weak rules. We further develop a rule attention network (teacher) that learns how to aggregate student pseudo-labels with weak rule labels, conditioned on their fidelity and the underlying context of an instance. Finally, we construct a semi-supervised learning objective for end-to-end training with unlabeled data, domain-specific rules, and a small amount of labeled data. Extensive experiments on six benchmark datasets for text classification demonstrate the effectiveness of our approach with significant improvements over state-of-the-art baselines.
NL-EDIT: Correcting semantic parse errors through natural language interaction
Mar 26, 2021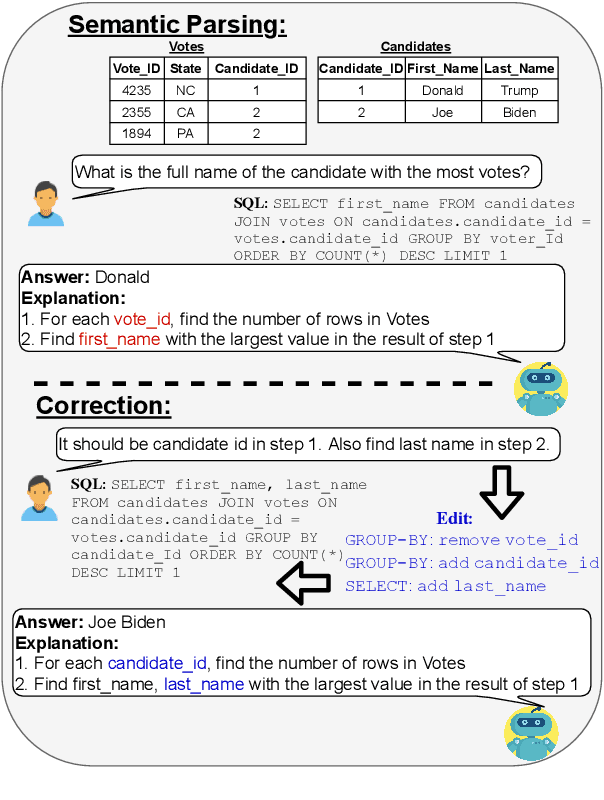


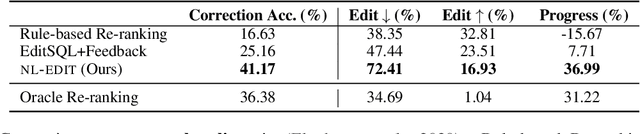
We study semantic parsing in an interactive setting in which users correct errors with natural language feedback. We present NL-EDIT, a model for interpreting natural language feedback in the interaction context to generate a sequence of edits that can be applied to the initial parse to correct its errors. We show that NL-EDIT can boost the accuracy of existing text-to-SQL parsers by up to 20% with only one turn of correction. We analyze the limitations of the model and discuss directions for improvement and evaluation. The code and datasets used in this paper are publicly available at http://aka.ms/NLEdit.
Structure-Grounded Pretraining for Text-to-SQL
Oct 24, 2020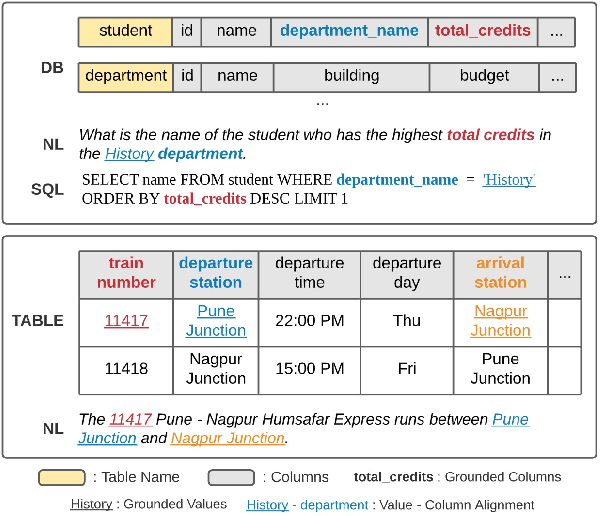
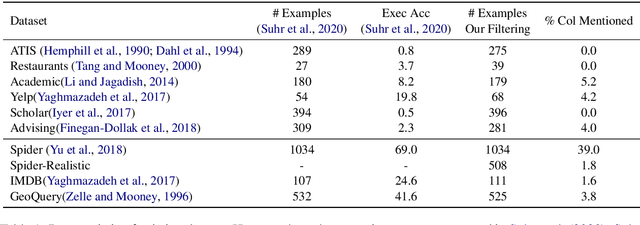
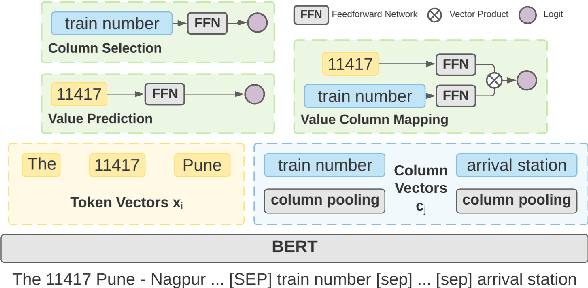

Learning to capture text-table alignment is essential for table related tasks like text-to-SQL. The model needs to correctly recognize natural language references to columns and values and to ground them in the given database schema. In this paper, we present a novel weakly supervised Structure-Grounded pretraining framework (StruG) for text-to-SQL that can effectively learn to capture text-table alignment based on a parallel text-table corpus. We identify a set of novel prediction tasks: column grounding, value grounding and column-value mapping, and train them using weak supervision without requiring complex SQL annotation. Additionally, to evaluate the model under a more realistic setting, we create a new evaluation set Spider-Realistic based on Spider with explicit mentions of column names removed, and adopt two existing single-database text-to-SQL datasets. StruG significantly outperforms BERT-LARGE on Spider and the realistic evaluation sets, while bringing consistent improvement on the large-scale WikiSQL benchmark.
Adaptive Self-training for Few-shot Neural Sequence Labeling
Oct 07, 2020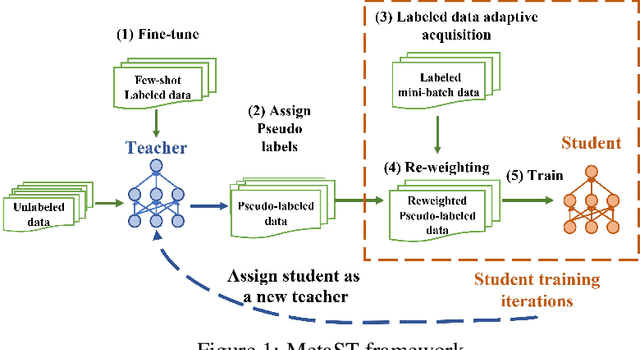
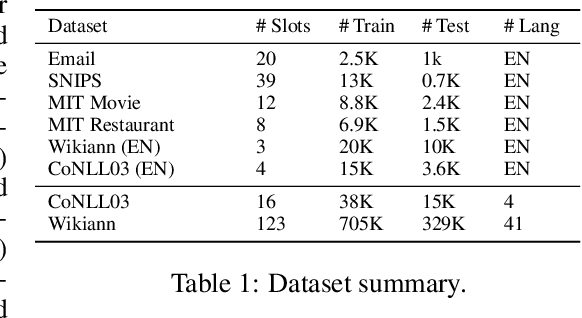
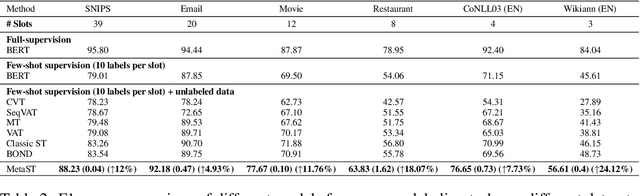
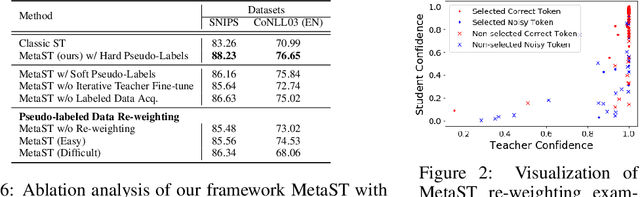
Neural sequence labeling is an important technique employed for many Natural Language Processing (NLP) tasks, such as Named Entity Recognition (NER), slot tagging for dialog systems and semantic parsing. Large-scale pre-trained language models obtain very good performance on these tasks when fine-tuned on large amounts of task-specific labeled data. However, such large-scale labeled datasets are difficult to obtain for several tasks and domains due to the high cost of human annotation as well as privacy and data access constraints for sensitive user applications. This is exacerbated for sequence labeling tasks requiring such annotations at token-level. In this work, we develop techniques to address the label scarcity challenge for neural sequence labeling models. Specifically, we develop self-training and meta-learning techniques for few-shot training of neural sequence taggers, namely MetaST. While self-training serves as an effective mechanism to learn from large amounts of unlabeled data -- meta-learning helps in adaptive sample re-weighting to mitigate error propagation from noisy pseudo-labels. Extensive experiments on six benchmark datasets including two massive multilingual NER datasets and four slot tagging datasets for task-oriented dialog systems demonstrate the effectiveness of our method with around 10% improvement over state-of-the-art systems for the 10-shot setting.
Uncertainty-aware Self-training for Text Classification with Few Labels
Jun 27, 2020
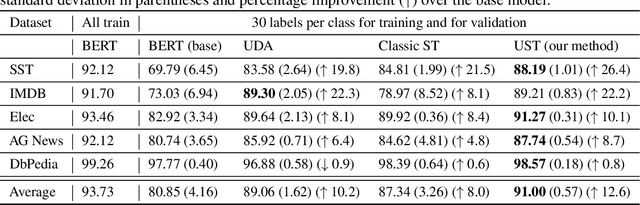
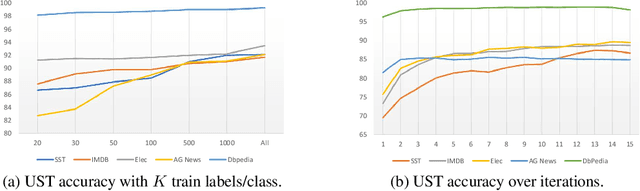
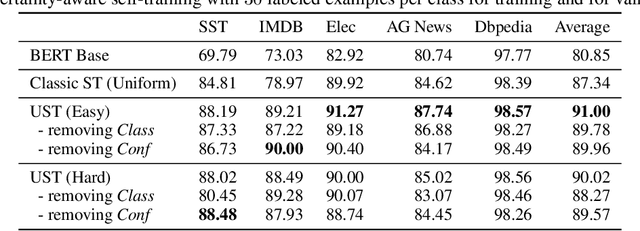
Recent success of large-scale pre-trained language models crucially hinge on fine-tuning them on large amounts of labeled data for the downstream task, that are typically expensive to acquire. In this work, we study self-training as one of the earliest semi-supervised learning approaches to reduce the annotation bottleneck by making use of large-scale unlabeled data for the target task. Standard self-training mechanism randomly samples instances from the unlabeled pool to pseudo-label and augment labeled data. In this work, we propose an approach to improve self-training by incorporating uncertainty estimates of the underlying neural network leveraging recent advances in Bayesian deep learning. Specifically, we propose (i) acquisition functions to select instances from the unlabeled pool leveraging Monte Carlo (MC) Dropout, and (ii) learning mechanism leveraging model confidence for self-training. As an application, we focus on text classification on five benchmark datasets. We show our methods leveraging only 20-30 labeled samples per class for each task for training and for validation can perform within 3% of fully supervised pre-trained language models fine-tuned on thousands of labeled instances with an aggregate accuracy of 91% and improving by upto 12% over baselines.
Speak to your Parser: Interactive Text-to-SQL with Natural Language Feedback
Jun 01, 2020
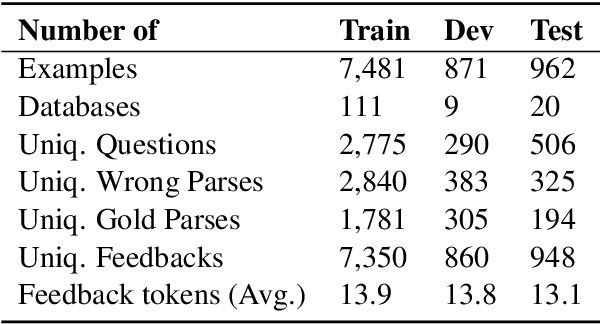


We study the task of semantic parse correction with natural language feedback. Given a natural language utterance, most semantic parsing systems pose the problem as one-shot translation where the utterance is mapped to a corresponding logical form. In this paper, we investigate a more interactive scenario where humans can further interact with the system by providing free-form natural language feedback to correct the system when it generates an inaccurate interpretation of an initial utterance. We focus on natural language to SQL systems and construct, SPLASH, a dataset of utterances, incorrect SQL interpretations and the corresponding natural language feedback. We compare various reference models for the correction task and show that incorporating such a rich form of feedback can significantly improve the overall semantic parsing accuracy while retaining the flexibility of natural language interaction. While we estimated human correction accuracy is 81.5%, our best model achieves only 25.1%, which leaves a large gap for improvement in future research. SPLASH is publicly available at https://aka.ms/Splash_dataset.
Learning with Weak Supervision for Email Intent Detection
May 26, 2020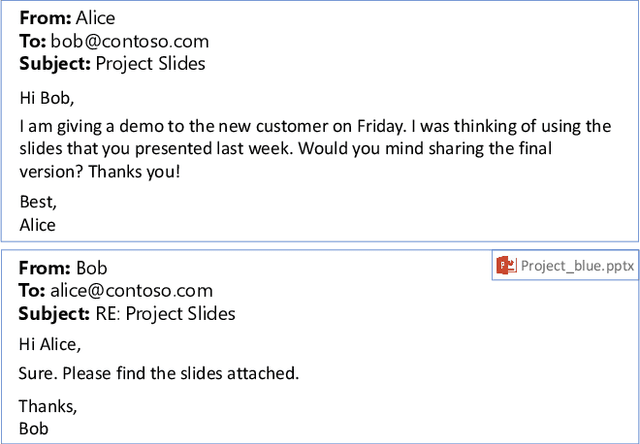

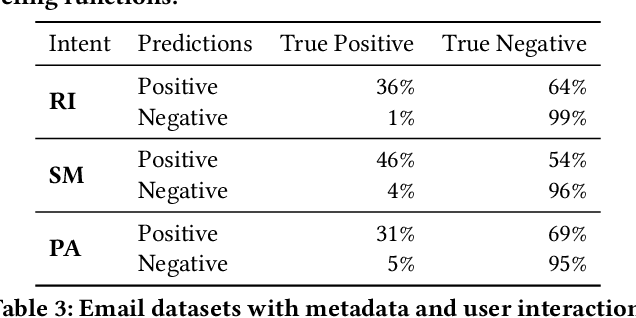
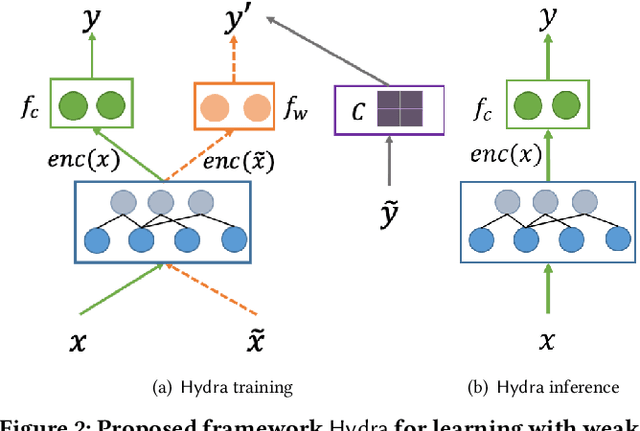
Email remains one of the most frequently used means of online communication. People spend a significant amount of time every day on emails to exchange information, manage tasks and schedule events. Previous work has studied different ways for improving email productivity by prioritizing emails, suggesting automatic replies or identifying intents to recommend appropriate actions. The problem has been mostly posed as a supervised learning problem where models of different complexities were proposed to classify an email message into a predefined taxonomy of intents or classes. The need for labeled data has always been one of the largest bottlenecks in training supervised models. This is especially the case for many real-world tasks, such as email intent classification, where large scale annotated examples are either hard to acquire or unavailable due to privacy or data access constraints. Email users often take actions in response to intents expressed in an email (e.g., setting up a meeting in response to an email with a scheduling request). Such actions can be inferred from user interaction logs. In this paper, we propose to leverage user actions as a source of weak supervision, in addition to a limited set of annotated examples, to detect intents in emails. We develop an end-to-end robust deep neural network model for email intent identification that leverages both clean annotated data and noisy weak supervision along with a self-paced learning mechanism. Extensive experiments on three different intent detection tasks show that our approach can effectively leverage the weakly supervised data to improve intent detection in emails.
* 10 pages, 3 figures
Smart To-Do : Automatic Generation of To-Do Items from Emails
May 05, 2020

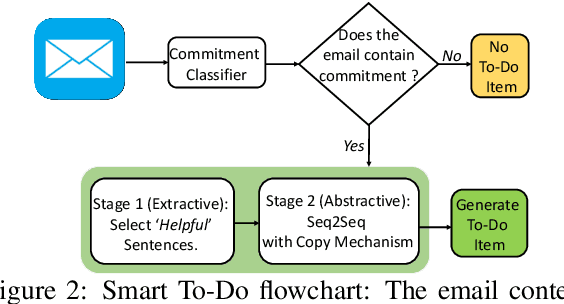
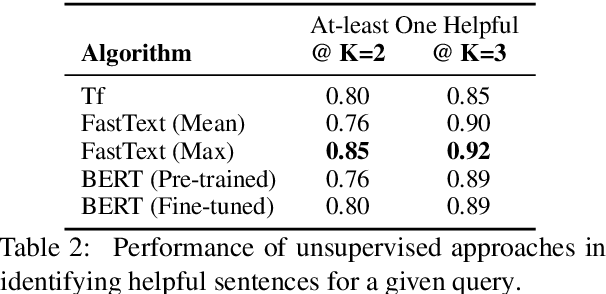
Intelligent features in email service applications aim to increase productivity by helping people organize their folders, compose their emails and respond to pending tasks. In this work, we explore a new application, Smart-To-Do, that helps users with task management over emails. We introduce a new task and dataset for automatically generating To-Do items from emails where the sender has promised to perform an action. We design a two-stage process leveraging recent advances in neural text generation and sequence-to-sequence learning, obtaining BLEU and ROUGE scores of 0:23 and 0:63 for this task. To the best of our knowledge, this is the first work to address the problem of composing To-Do items from emails.
Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer
May 02, 2020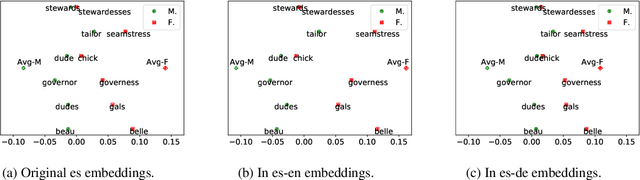
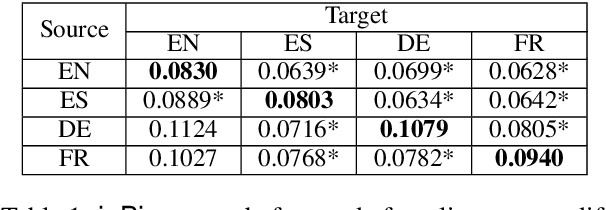
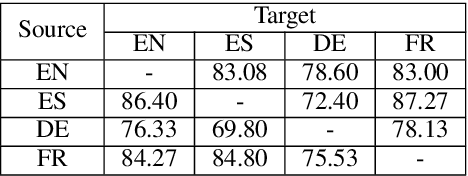
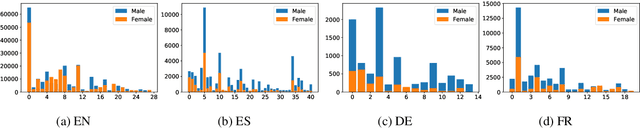
Multilingual representations embed words from many languages into a single semantic space such that words with similar meanings are close to each other regardless of the language. These embeddings have been widely used in various settings, such as cross-lingual transfer, where a natural language processing (NLP) model trained on one language is deployed to another language. While the cross-lingual transfer techniques are powerful, they carry gender bias from the source to target languages. In this paper, we study gender bias in multilingual embeddings and how it affects transfer learning for NLP applications. We create a multilingual dataset for bias analysis and propose several ways for quantifying bias in multilingual representations from both the intrinsic and extrinsic perspectives. Experimental results show that the magnitude of bias in the multilingual representations changes differently when we align the embeddings to different target spaces and that the alignment direction can also have an influence on the bias in transfer learning. We further provide recommendations for using the multilingual word representations for downstream tasks.
Leveraging Multi-Source Weak Social Supervision for Early Detection of Fake News
Apr 03, 2020
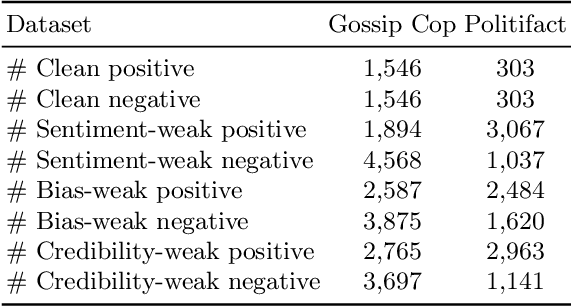
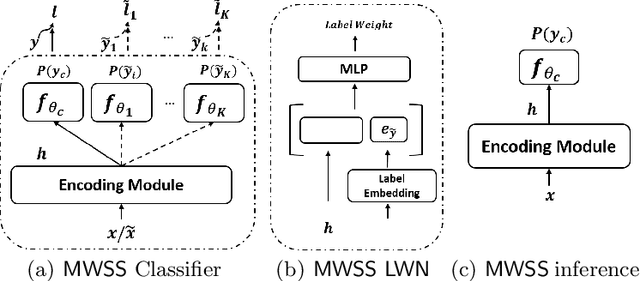
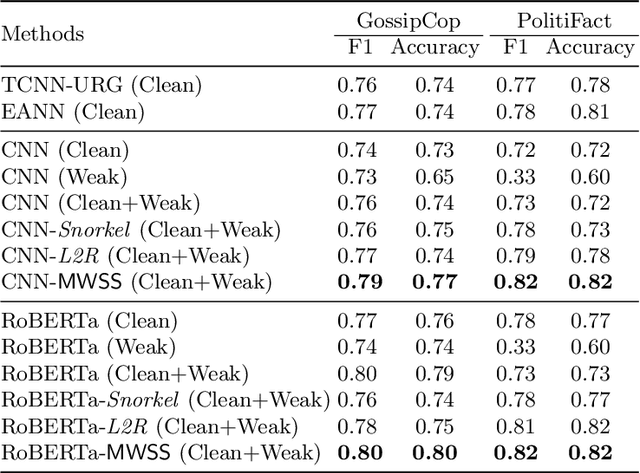
Social media has greatly enabled people to participate in online activities at an unprecedented rate. However, this unrestricted access also exacerbates the spread of misinformation and fake news online which might cause confusion and chaos unless being detected early for its mitigation. Given the rapidly evolving nature of news events and the limited amount of annotated data, state-of-the-art systems on fake news detection face challenges due to the lack of large numbers of annotated training instances that are hard to come by for early detection. In this work, we exploit multiple weak signals from different sources given by user and content engagements (referred to as weak social supervision), and their complementary utilities to detect fake news. We jointly leverage the limited amount of clean data along with weak signals from social engagements to train deep neural networks in a meta-learning framework to estimate the quality of different weak instances. Experiments on realworld datasets demonstrate that the proposed framework outperforms state-of-the-art baselines for early detection of fake news without using any user engagements at prediction time.