 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Bayesian Active Learning for Natural Language Processing: Results of a Large-Scale Empirical Study
Sep 24, 2018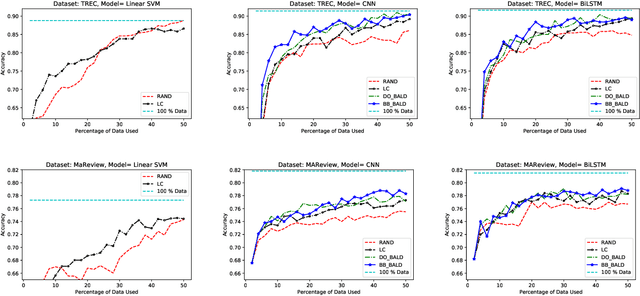
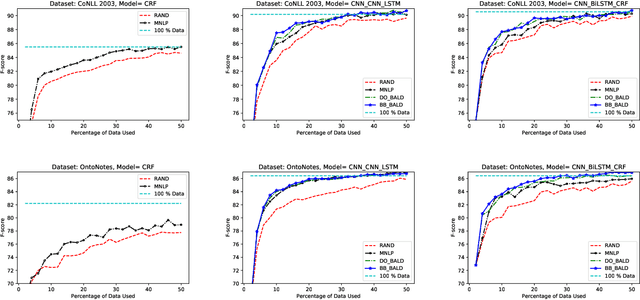
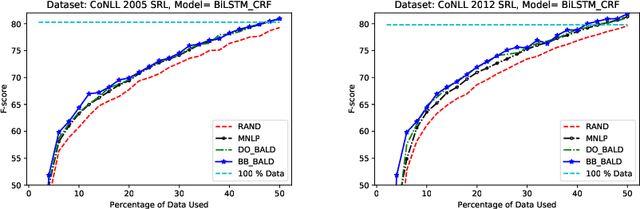
Several recent papers investigate Active Learning (AL) for mitigating the data dependence of deep learning for natural language processing. However, the applicability of AL to real-world problems remains an open question. While in supervised learning, practitioners can try many different methods, evaluating each against a validation set before selecting a model, AL affords no such luxury. Over the course of one AL run, an agent annotates its dataset exhausting its labeling budget. Thus, given a new task, an active learner has no opportunity to compare models and acquisition functions. This paper provides a large scale empirical study of deep active learning, addressing multiple tasks and, for each, multiple datasets, multiple models, and a full suite of acquisition functions. We find that across all settings, Bayesian active learning by disagreement, using uncertainty estimates provided either by Dropout or Bayes-by Backprop significantly improves over i.i.d. baselines and usually outperforms classic uncertainty sampling.
Leveraging Native Language Speech for Accent Identification using Deep Siamese Networks
Jun 18, 2018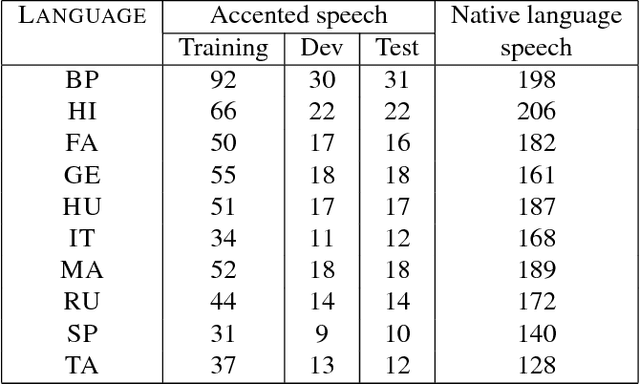
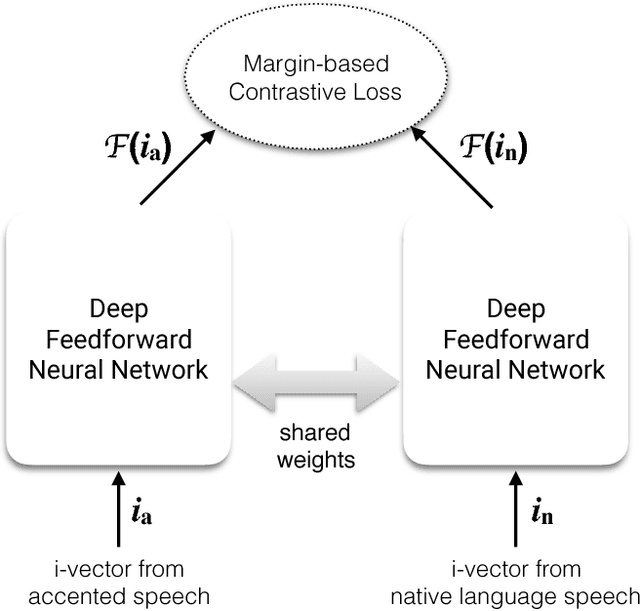
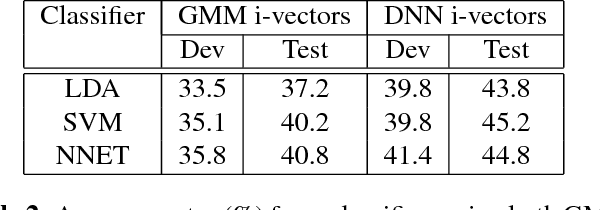
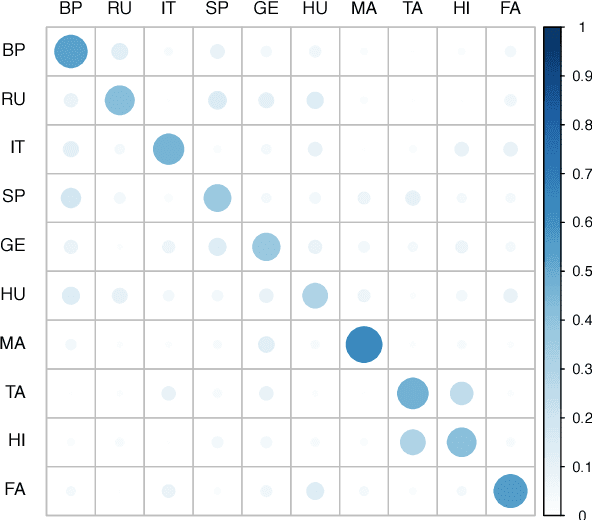
The problem of automatic accent identification is important for several applications like speaker profiling and recognition as well as for improving speech recognition systems. The accented nature of speech can be primarily attributed to the influence of the speaker's native language on the given speech recording. In this paper, we propose a novel accent identification system whose training exploits speech in native languages along with the accented speech. Specifically, we develop a deep Siamese network-based model which learns the association between accented speech recordings and the native language speech recordings. The Siamese networks are trained with i-vector features extracted from the speech recordings using either an unsupervised Gaussian mixture model (GMM) or a supervised deep neural network (DNN) model. We perform several accent identification experiments using the CSLU Foreign Accented English (FAE) corpus. In these experiments, our proposed approach using deep Siamese networks yield significant relative performance improvements of 15.4 percent on a 10-class accent identification task, over a baseline DNN-based classification system that uses GMM i-vectors. Furthermore, we present a detailed error analysis of the proposed accent identification system.