 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Native Language Speech for Accent Identification using Deep Siamese Networks
Paper and Code
Jun 18, 2018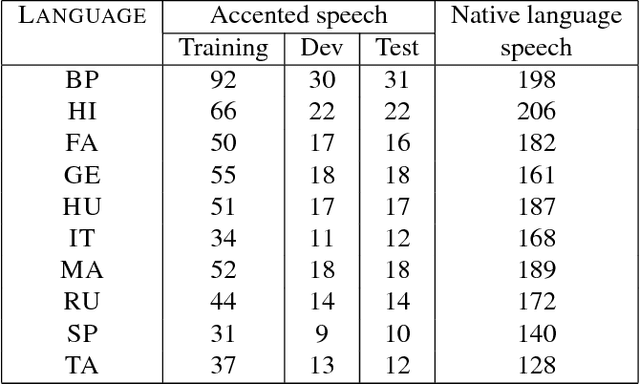
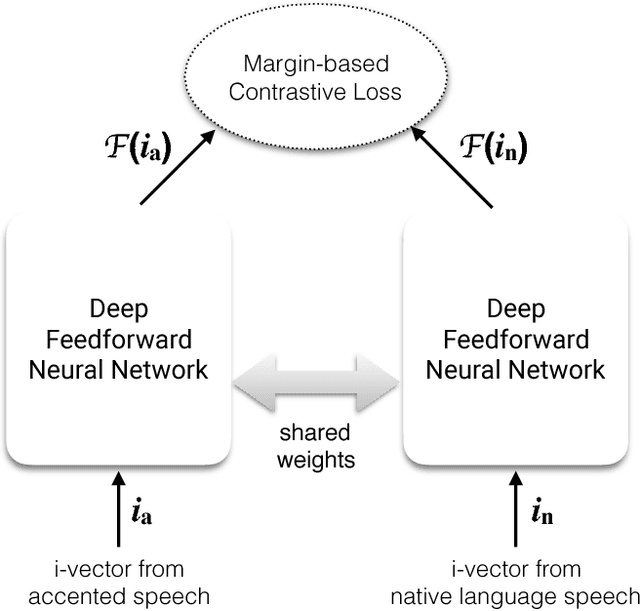
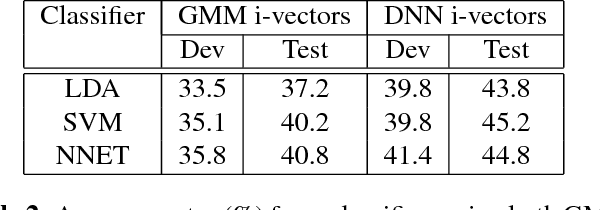
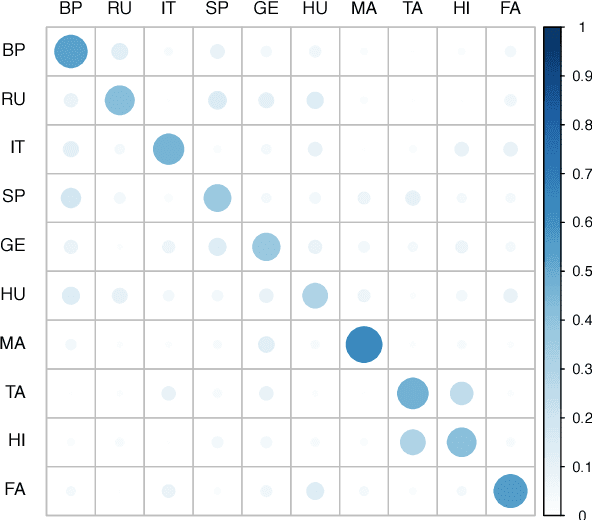
The problem of automatic accent identification is important for several applications like speaker profiling and recognition as well as for improving speech recognition systems. The accented nature of speech can be primarily attributed to the influence of the speaker's native language on the given speech recording. In this paper, we propose a novel accent identification system whose training exploits speech in native languages along with the accented speech. Specifically, we develop a deep Siamese network-based model which learns the association between accented speech recordings and the native language speech recordings. The Siamese networks are trained with i-vector features extracted from the speech recordings using either an unsupervised Gaussian mixture model (GMM) or a supervised deep neural network (DNN) model. We perform several accent identification experiments using the CSLU Foreign Accented English (FAE) corpus. In these experiments, our proposed approach using deep Siamese networks yield significant relative performance improvements of 15.4 percent on a 10-class accent identification task, over a baseline DNN-based classification system that uses GMM i-vectors. Furthermore, we present a detailed error analysis of the proposed accent identification system.