 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXTREME-R: Towards More Challenging and Nuanced Multilingual Evaluation
Apr 15, 2021
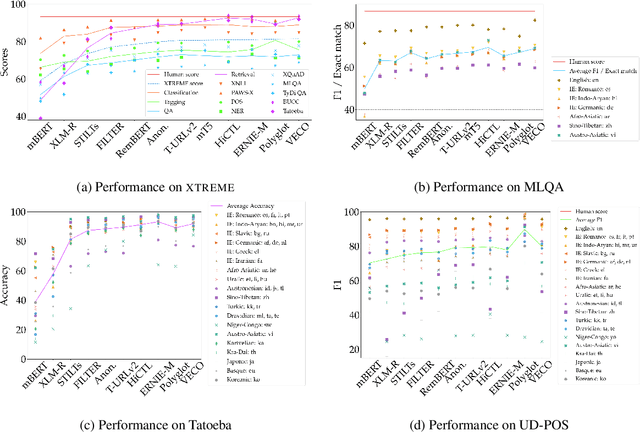
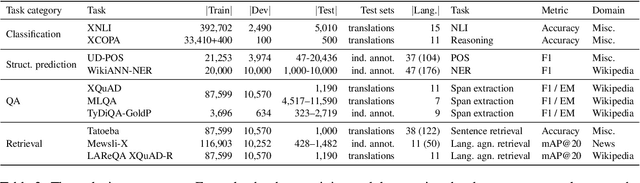
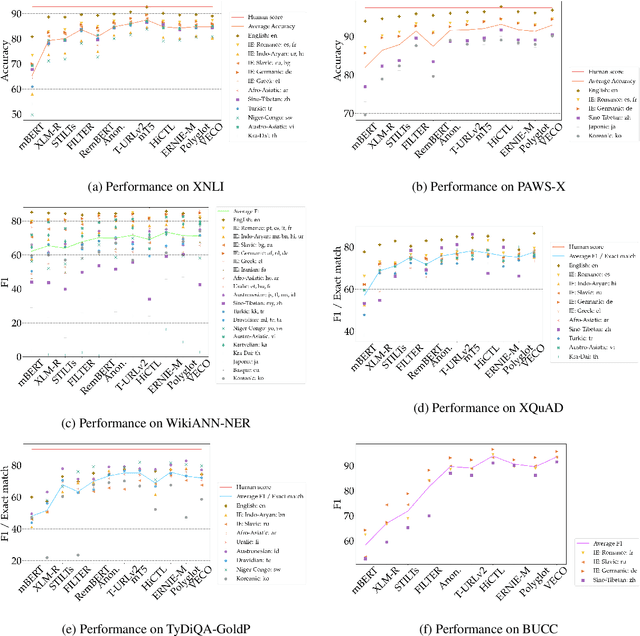
Machine learning has brought striking advances in multilingual natural language processing capabilities over the past year. For example, the latest techniques have improved the state-of-the-art performance on the XTREME multilingual benchmark by more than 13 points. While a sizeable gap to human-level performance remains, improvements have been easier to achieve in some tasks than in others. This paper analyzes the current state of cross-lingual transfer learning and summarizes some lessons learned. In order to catalyze meaningful progress, we extend XTREME to XTREME-R, which consists of an improved set of ten natural language understanding tasks, including challenging language-agnostic retrieval tasks, and covers 50 typologically diverse languages. In addition, we provide a massively multilingual diagnostic suite and fine-grained multi-dataset evaluation capabilities through an interactive public leaderboard to gain a better understanding of such models.
Distilling Large Language Models into Tiny and Effective Students using pQRNN
Jan 21, 2021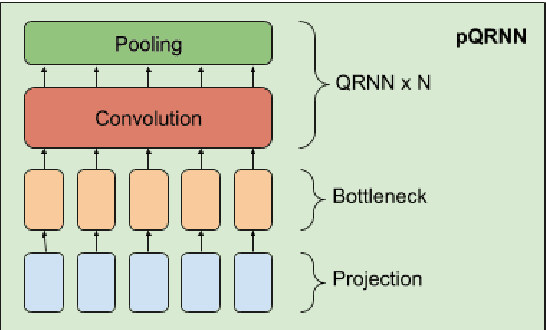
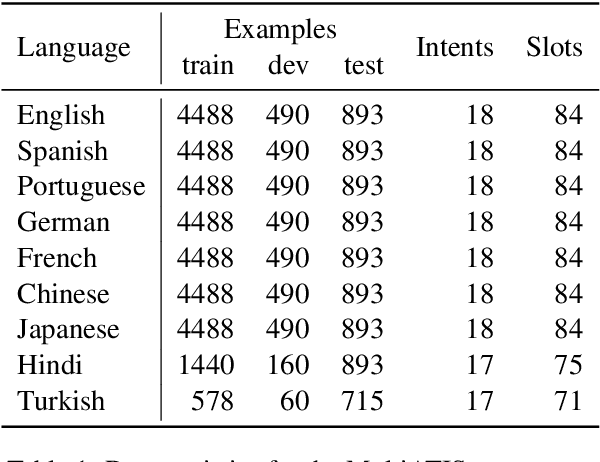
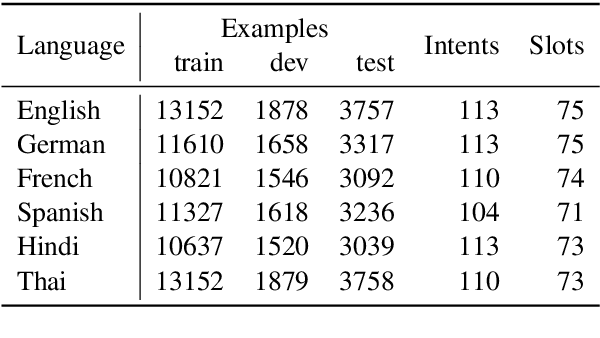
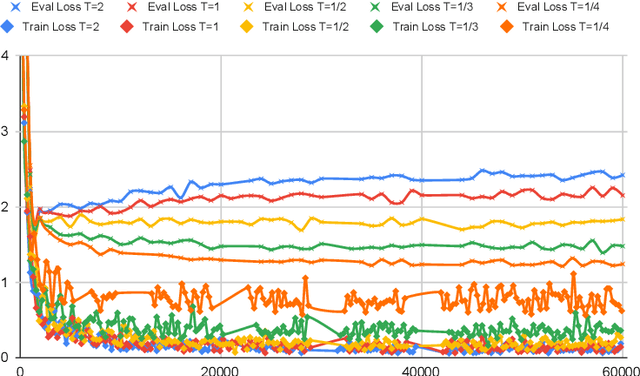
Large pre-trained multilingual models like mBERT, XLM-R achieve state of the art results on language understanding tasks. However, they are not well suited for latency critical applications on both servers and edge devices. It's important to reduce the memory and compute resources required by these models. To this end, we propose pQRNN, a projection-based embedding-free neural encoder that is tiny and effective for natural language processing tasks. Without pre-training, pQRNNs significantly outperform LSTM models with pre-trained embeddings despite being 140x smaller. With the same number of parameters, they outperform transformer baselines thereby showcasing their parameter efficiency. Additionally, we show that pQRNNs are effective student architectures for distilling large pre-trained language models. We perform careful ablations which study the effect of pQRNN parameters, data augmentation, and distillation settings. On MTOP, a challenging multilingual semantic parsing dataset, pQRNN students achieve 95.9\% of the performance of an mBERT teacher while being 350x smaller. On mATIS, a popular parsing task, pQRNN students on average are able to get to 97.1\% of the teacher while again being 350x smaller. Our strong results suggest that our approach is great for latency-sensitive applications while being able to leverage large mBERT-like models.
mT5: A massively multilingual pre-trained text-to-text transformer
Oct 23, 2020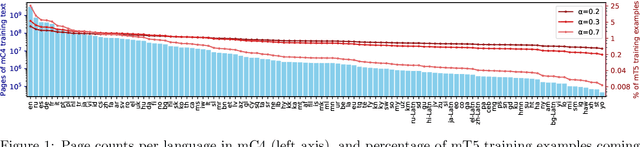

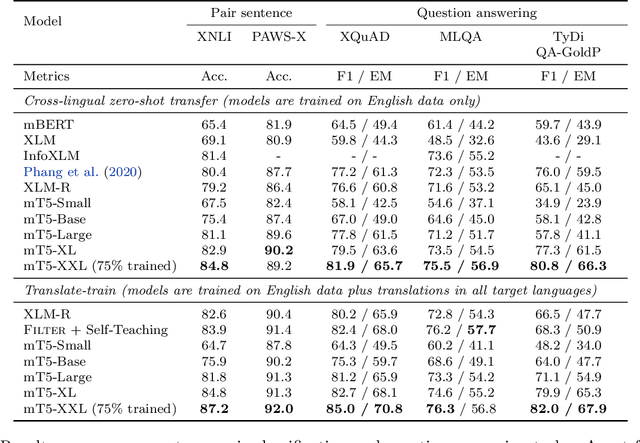
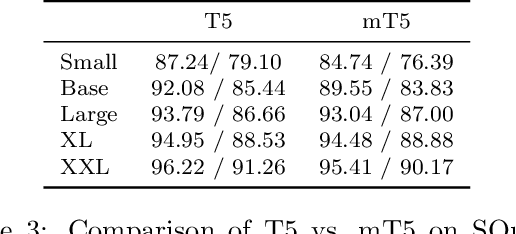
The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We describe the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual benchmarks. All of the code and model checkpoints used in this work are publicly available.
Explicit Alignment Objectives for Multilingual Bidirectional Encoders
Oct 15, 2020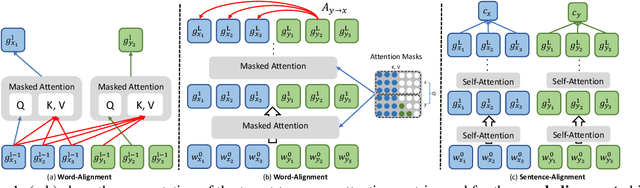
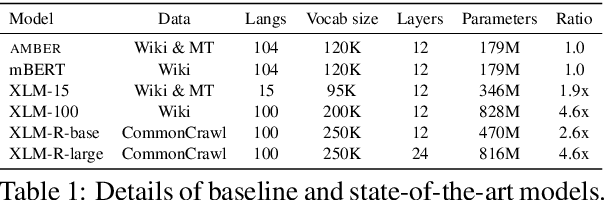
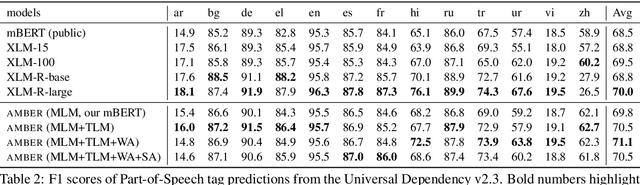
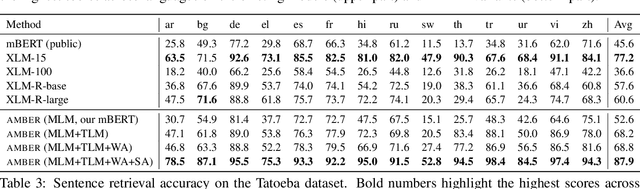
Pre-trained cross-lingual encoders such as mBERT (Devlin et al., 2019) and XLMR (Conneau et al., 2020) have proven to be impressively effective at enabling transfer-learning of NLP systems from high-resource languages to low-resource languages. This success comes despite the fact that there is no explicit objective to align the contextual embeddings of words/sentences with similar meanings across languages together in the same space. In this paper, we present a new method for learning multilingual encoders, AMBER (Aligned Multilingual Bidirectional EncodeR). AMBER is trained on additional parallel data using two explicit alignment objectives that align the multilingual representations at different granularities. We conduct experiments on zero-shot cross-lingual transfer learning for different tasks including sequence tagging, sentence retrieval and sentence classification. Experimental results show that AMBER obtains gains of up to 1.1 average F1 score on sequence tagging and up to 27.3 average accuracy on retrieval over the XLMR-large model which has 4.6x the parameters of AMBER.
Harnessing Multilinguality in Unsupervised Machine Translation for Rare Languages
Sep 23, 2020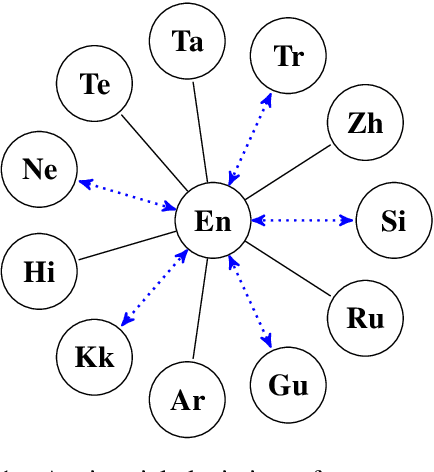

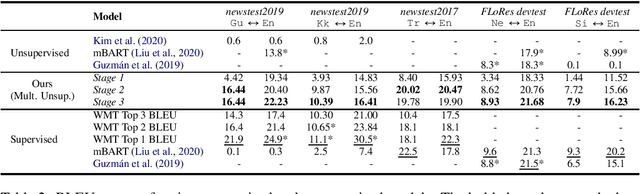
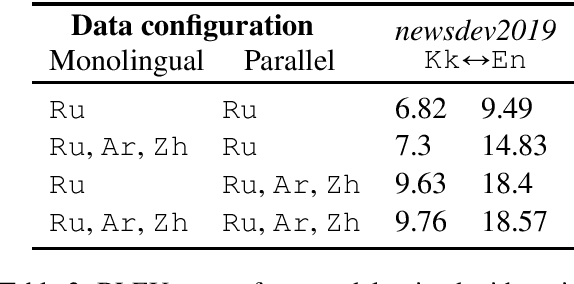
Unsupervised translation has reached impressive performance on resource-rich language pairs such as English-French and English-German. However, early studies have shown that in more realistic settings involving low-resource, rare languages, unsupervised translation performs poorly, achieving less than 3.0 BLEU. In this work, we show that multilinguality is critical to making unsupervised systems practical for low-resource settings. In particular, we present a single model for 5 low-resource languages (Gujarati, Kazakh, Nepali, Sinhala, and Turkish) to and from English directions, which leverages monolingual and auxiliary parallel data from other high-resource language pairs via a three-stage training scheme. We outperform all current state-of-the-art unsupervised baselines for these languages, achieving gains of up to 14.4 BLEU. Additionally, we outperform a large collection of supervised WMT submissions for various language pairs as well as match the performance of the current state-of-the-art supervised model for Nepali-English. We conduct a series of ablation studies to establish the robustness of our model under different degrees of data quality, as well as to analyze the factors which led to the superior performance of the proposed approach over traditional unsupervised models.
Leveraging Monolingual Data with Self-Supervision for Multilingual Neural Machine Translation
May 11, 2020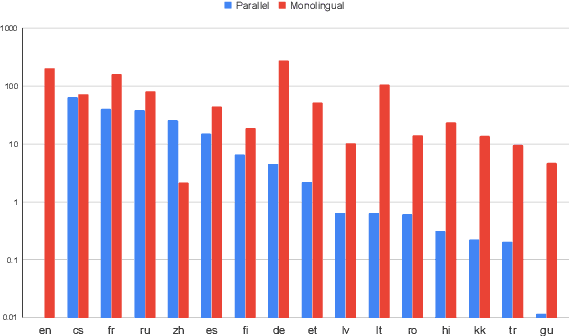

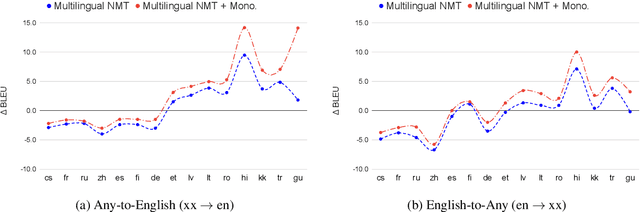
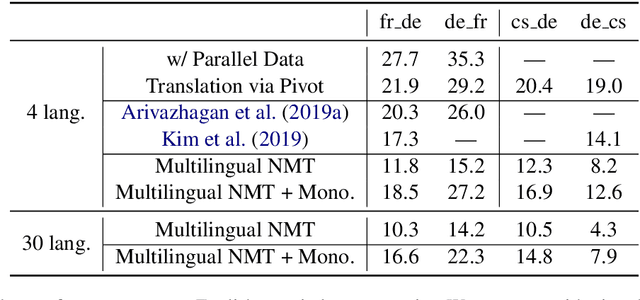
Over the last few years two promising research directions in low-resource neural machine translation (NMT) have emerged. The first focuses on utilizing high-resource languages to improve the quality of low-resource languages via multilingual NMT. The second direction employs monolingual data with self-supervision to pre-train translation models, followed by fine-tuning on small amounts of supervised data. In this work, we join these two lines of research and demonstrate the efficacy of monolingual data with self-supervision in multilingual NMT. We offer three major results: (i) Using monolingual data significantly boosts the translation quality of low-resource languages in multilingual models. (ii) Self-supervision improves zero-shot translation quality in multilingual models. (iii) Leveraging monolingual data with self-supervision provides a viable path towards adding new languages to multilingual models, getting up to 33 BLEU on ro-en translation without any parallel data or back-translation.
XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization
Apr 10, 2020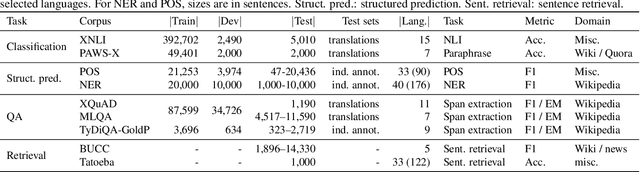
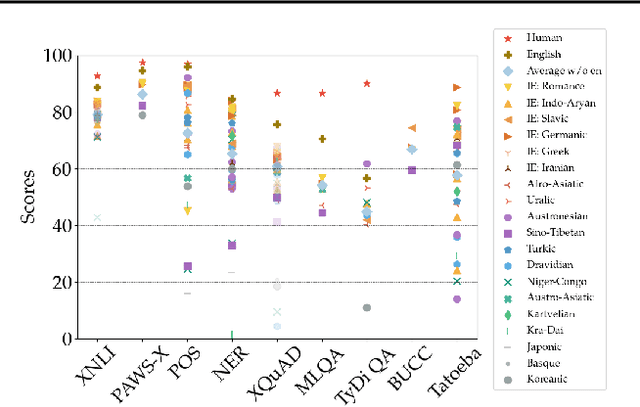
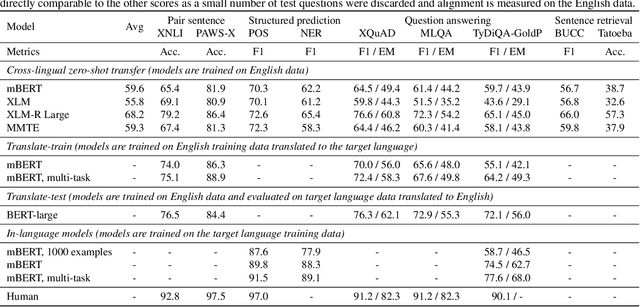
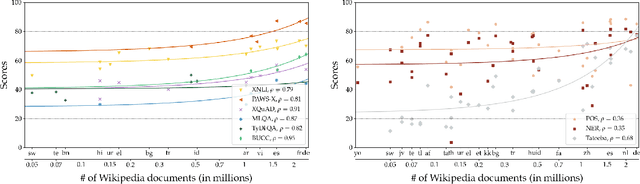
Much recent progress in applications of machine learning models to NLP has been driven by benchmarks that evaluate models across a wide variety of tasks. However, these broad-coverage benchmarks have been mostly limited to English, and despite an increasing interest in multilingual models, a benchmark that enables the comprehensive evaluation of such methods on a diverse range of languages and tasks is still missing. To this end, we introduce the Cross-lingual TRansfer Evaluation of Multilingual Encoders XTREME benchmark, a multi-task benchmark for evaluating the cross-lingual generalization capabilities of multilingual representations across 40 languages and 9 tasks. We demonstrate that while models tested on English reach human performance on many tasks, there is still a sizable gap in the performance of cross-lingually transferred models, particularly on syntactic and sentence retrieval tasks. There is also a wide spread of results across languages. We release the benchmark to encourage research on cross-lingual learning methods that transfer linguistic knowledge across a diverse and representative set of languages and tasks.
Evaluating the Cross-Lingual Effectiveness of Massively Multilingual Neural Machine Translation
Sep 01, 2019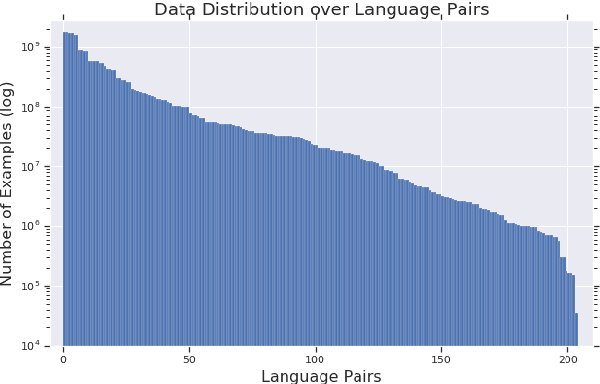
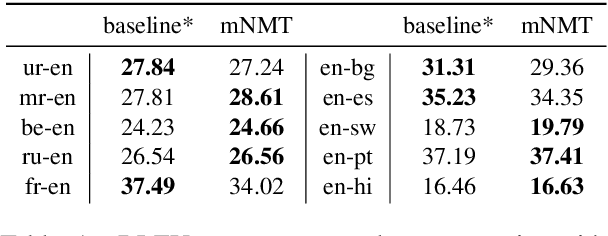
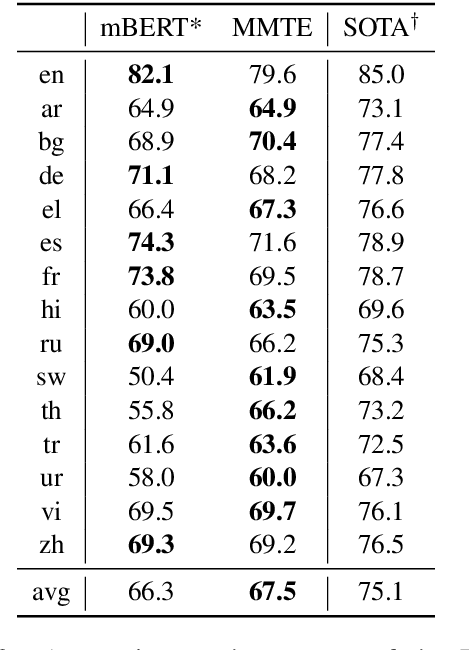
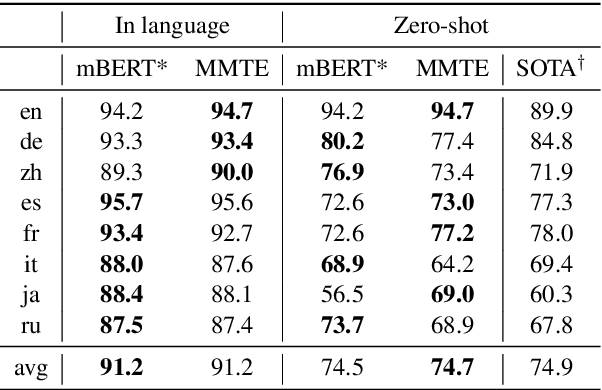
The recently proposed massively multilingual neural machine translation (NMT) system has been shown to be capable of translating over 100 languages to and from English within a single model. Its improved translation performance on low resource languages hints at potential cross-lingual transfer capability for downstream tasks. In this paper, we evaluate the cross-lingual effectiveness of representations from the encoder of a massively multilingual NMT model on 5 downstream classification and sequence labeling tasks covering a diverse set of over 50 languages. We compare against a strong baseline, multilingual BERT (mBERT), in different cross-lingual transfer learning scenarios and show gains in zero-shot transfer in 4 out of these 5 tasks.
Supervised Contextual Embeddings for Transfer Learning in Natural Language Processing Tasks
Jun 28, 2019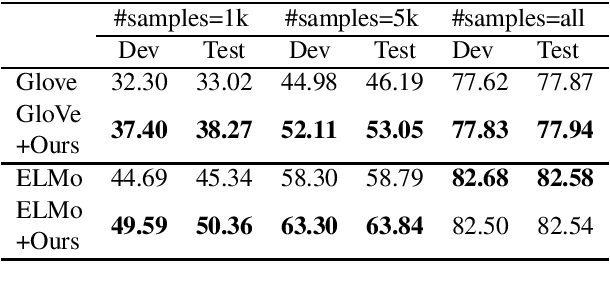
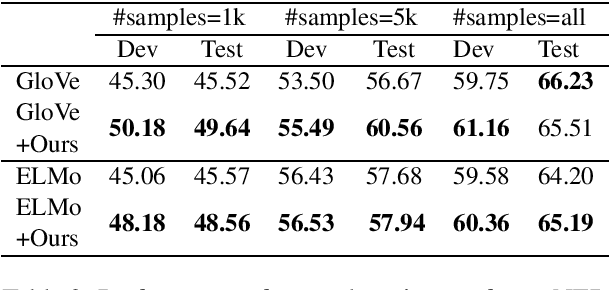
Pre-trained word embeddings are the primary method for transfer learning in several Natural Language Processing (NLP) tasks. Recent works have focused on using unsupervised techniques such as language modeling to obtain these embeddings. In contrast, this work focuses on extracting representations from multiple pre-trained supervised models, which enriches word embeddings with task and domain specific knowledge. Experiments performed in cross-task, cross-domain and cross-lingual settings indicate that such supervised embeddings are helpful, especially in the low-resource setting, but the extent of gains is dependent on the nature of the task and domain. We make our code publicly available.
Unsupervised Transfer Learning for Spoken Language Understanding in Intelligent Agents
Nov 13, 2018
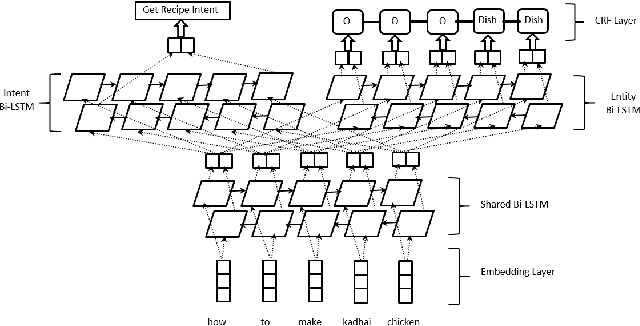
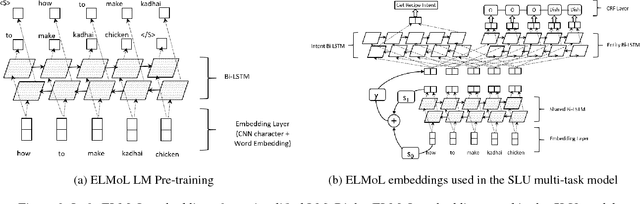
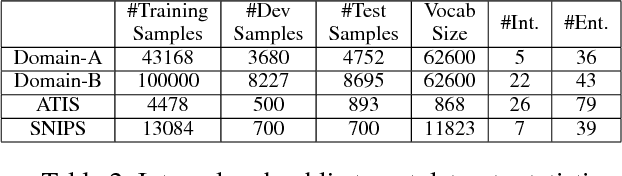
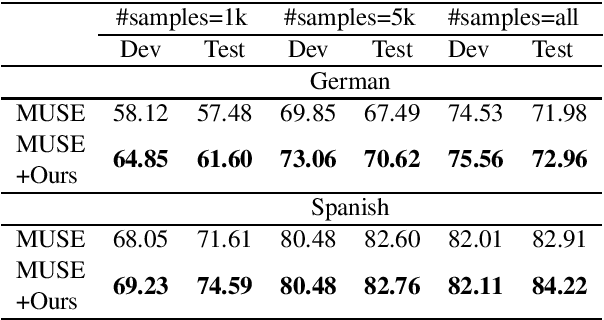
User interaction with voice-powered agents generates large amounts of unlabeled utterances. In this paper, we explore techniques to efficiently transfer the knowledge from these unlabeled utterances to improve model performance on Spoken Language Understanding (SLU) tasks. We use Embeddings from Language Model (ELMo) to take advantage of unlabeled data by learning contextualized word representations. Additionally, we propose ELMo-Light (ELMoL), a faster and simpler unsupervised pre-training method for SLU. Our findings suggest unsupervised pre-training on a large corpora of unlabeled utterances leads to significantly better SLU performance compared to training from scratch and it can even outperform conventional supervised transfer. Additionally, we show that the gains from unsupervised transfer techniques can be further improved by supervised transfer. The improvements are more pronounced in low resource settings and when using only 1000 labeled in-domain samples, our techniques match the performance of training from scratch on 10-15x more labeled in-domain data.