 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverfitting in Synthesis: Theory and Practice (Extender Version)
May 27, 2019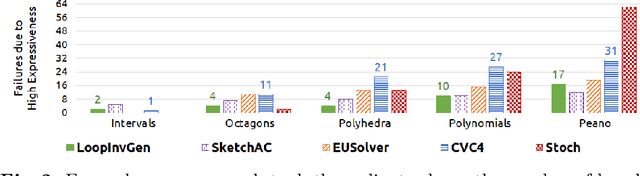


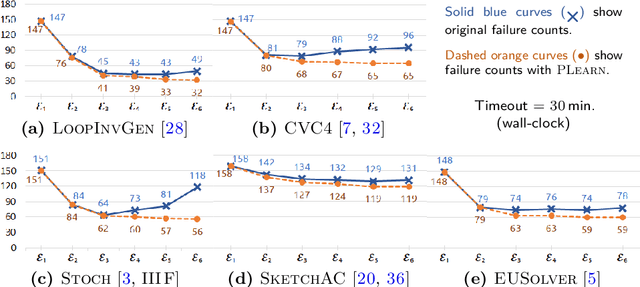
In syntax-guided synthesis (SyGuS), a synthesizer's goal is to automatically generate a program belonging to a grammar of possible implementations that meets a logical specification. We investigate a common limitation across state-of-the-art SyGuS tools that perform counterexample-guided inductive synthesis (CEGIS). We empirically observe that as the expressiveness of the provided grammar increases, the performance of these tools degrades significantly. We claim that this degradation is not only due to a larger search space, but also due to overfitting. We formally define this phenomenon and prove no-free-lunch theorems for SyGuS, which reveal a fundamental tradeoff between synthesizer performance and grammar expressiveness. A standard approach to mitigate overfitting in machine learning is to run multiple learners with varying expressiveness in parallel. We demonstrate that this insight can immediately benefit existing SyGuS tools. We also propose a novel single-threaded technique called hybrid enumeration that interleaves different grammars and outperforms the winner of the 2018 SyGuS competition (Inv track), solving more problems and achieving a $5\times$ mean speedup.
Adaptive Neural Trees
Oct 07, 2018
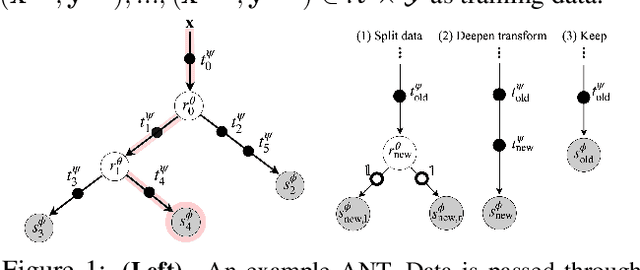

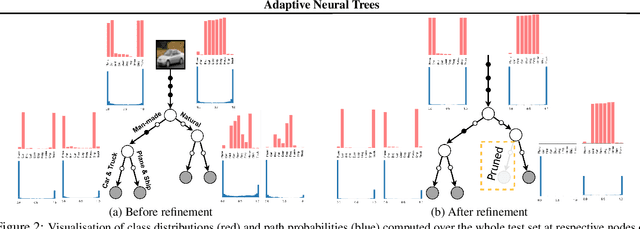
Deep neural networks and decision trees operate on largely separate paradigms; typically, the former performs representation learning with pre-specified architectures, while the latter is characterised by learning hierarchies over pre-specified features with data-driven architectures. We unite the two via adaptive neural trees (ANTs), a model that incorporates representation learning into edges, routing functions and leaf nodes of a decision tree, along with a backpropagation-based training algorithm that adaptively grows the architecture from primitive modules (e.g., convolutional layers). ANTs allow increased interpretability via hierarchical clustering, e.g., learning meaningful class associations, such as separating natural vs. man-made objects. We demonstrate this whilst achieving over 99% and 90% accuracy on the MNIST and CIFAR-10 datasets. Furthermore, ANT optimisation naturally adapts the architecture to the size and complexity of the training data.
Semi-Supervised Learning via Compact Latent Space Clustering
Jul 29, 2018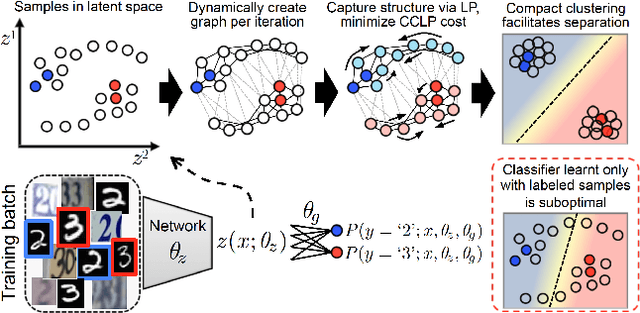
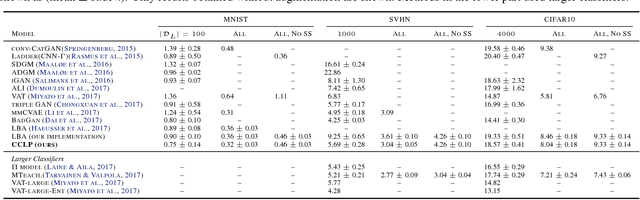
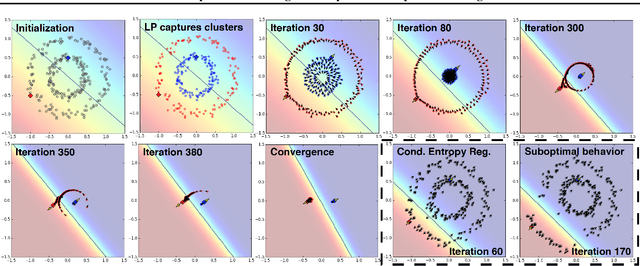
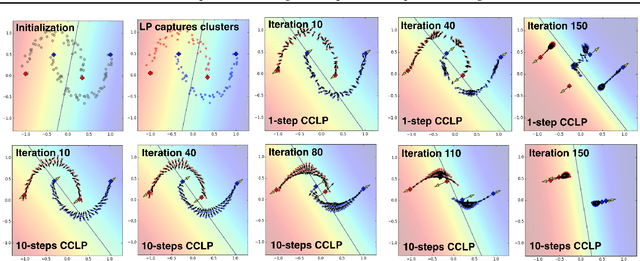
We present a novel cost function for semi-supervised learning of neural networks that encourages compact clustering of the latent space to facilitate separation. The key idea is to dynamically create a graph over embeddings of labeled and unlabeled samples of a training batch to capture underlying structure in feature space, and use label propagation to estimate its high and low density regions. We then devise a cost function based on Markov chains on the graph that regularizes the latent space to form a single compact cluster per class, while avoiding to disturb existing clusters during optimization. We evaluate our approach on three benchmarks and compare to state-of-the art with promising results. Our approach combines the benefits of graph-based regularization with efficient, inductive inference, does not require modifications to a network architecture, and can thus be easily applied to existing networks to enable an effective use of unlabeled data.
Autofocus Layer for Semantic Segmentation
Jun 11, 2018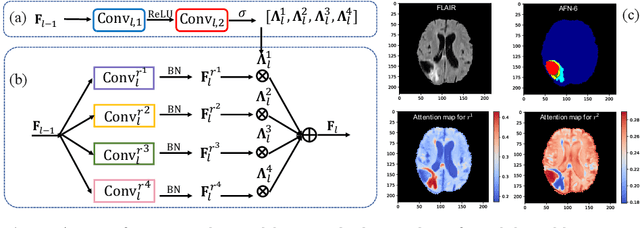
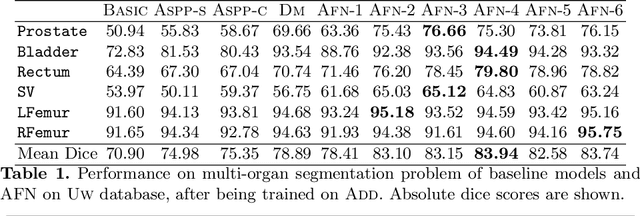

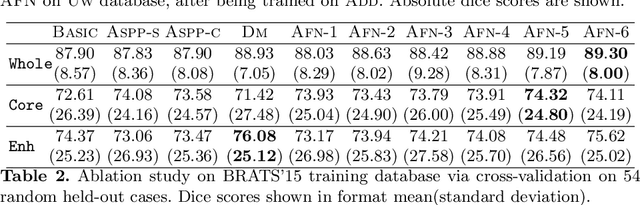
We propose the autofocus convolutional layer for semantic segmentation with the objective of enhancing the capabilities of neural networks for multi-scale processing. Autofocus layers adaptively change the size of the effective receptive field based on the processed context to generate more powerful features. This is achieved by parallelising multiple convolutional layers with different dilation rates, combined by an attention mechanism that learns to focus on the optimal scales driven by context. By sharing the weights of the parallel convolutions we make the network scale-invariant, with only a modest increase in the number of parameters. The proposed autofocus layer can be easily integrated into existing networks to improve a model's representational power. We evaluate our models on the challenging tasks of multi-organ segmentation in pelvic CT and brain tumor segmentation in MRI and achieve very promising performance.
Measuring Neural Net Robustness with Constraints
Jun 16, 2017
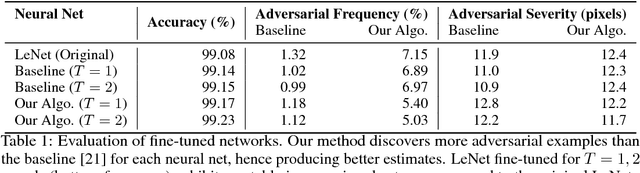

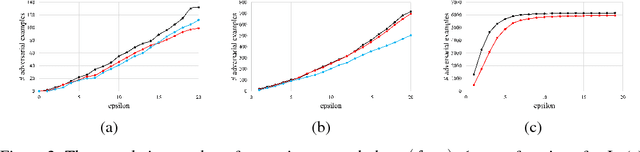
Despite having high accuracy, neural nets have been shown to be susceptible to adversarial examples, where a small perturbation to an input can cause it to become mislabeled. We propose metrics for measuring the robustness of a neural net and devise a novel algorithm for approximating these metrics based on an encoding of robustness as a linear program. We show how our metrics can be used to evaluate the robustness of deep neural nets with experiments on the MNIST and CIFAR-10 datasets. Our algorithm generates more informative estimates of robustness metrics compared to estimates based on existing algorithms. Furthermore, we show how existing approaches to improving robustness "overfit" to adversarial examples generated using a specific algorithm. Finally, we show that our techniques can be used to additionally improve neural net robustness both according to the metrics that we propose, but also according to previously proposed metrics.
Quantifying Program Bias
Mar 07, 2017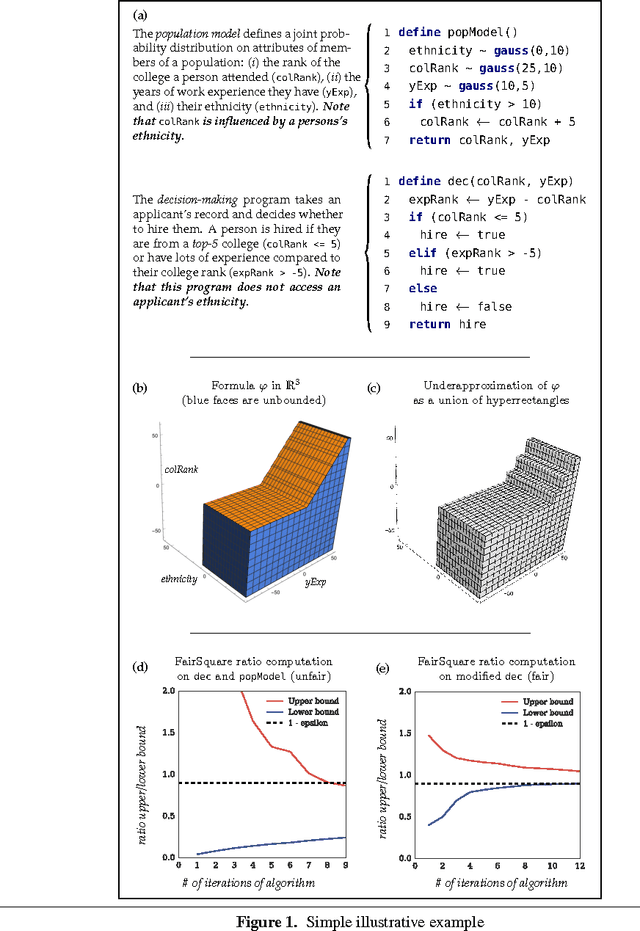
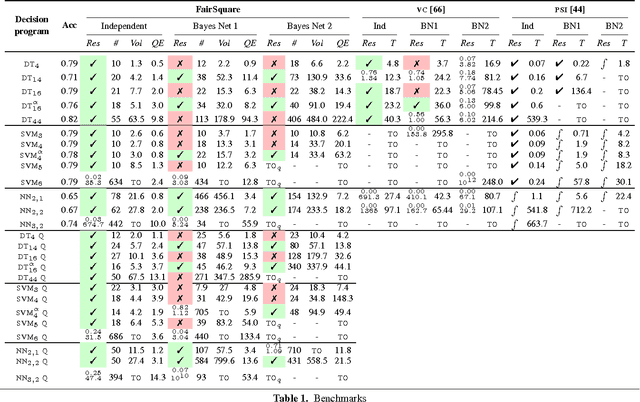
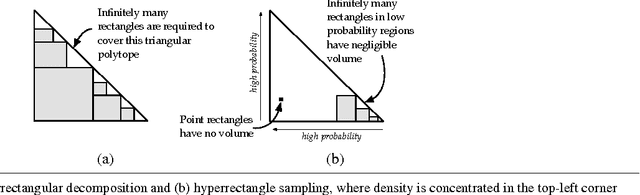
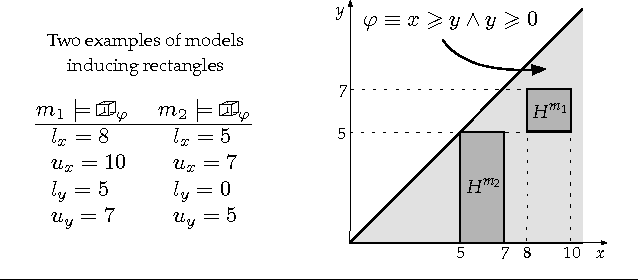
With the range and sensitivity of algorithmic decisions expanding at a break-neck speed, it is imperative that we aggressively investigate whether programs are biased. We propose a novel probabilistic program analysis technique and apply it to quantifying bias in decision-making programs. Specifically, we (i) present a sound and complete automated verification technique for proving quantitative properties of probabilistic programs; (ii) show that certain notions of bias, recently proposed in the fairness literature, can be phrased as quantitative correctness properties; and (iii) present FairSquare, the first verification tool for quantifying program bias, and evaluate it on a range of decision-making programs.
Unsupervised domain adaptation in brain lesion segmentation with adversarial networks
Dec 28, 2016
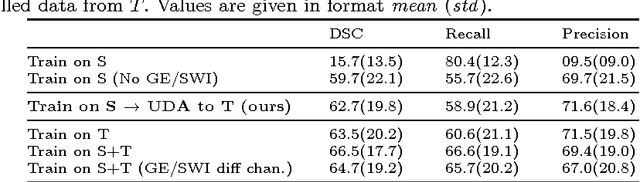
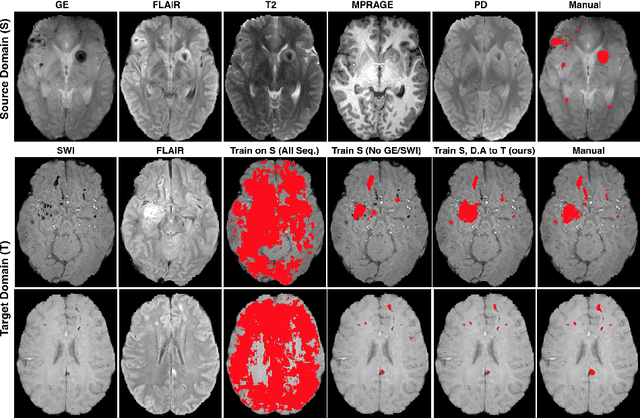

Significant advances have been made towards building accurate automatic segmentation systems for a variety of biomedical applications using machine learning. However, the performance of these systems often degrades when they are applied on new data that differ from the training data, for example, due to variations in imaging protocols. Manually annotating new data for each test domain is not a feasible solution. In this work we investigate unsupervised domain adaptation using adversarial neural networks to train a segmentation method which is more invariant to differences in the input data, and which does not require any annotations on the test domain. Specifically, we learn domain-invariant features by learning to counter an adversarial network, which attempts to classify the domain of the input data by observing the activations of the segmentation network. Furthermore, we propose a multi-connected domain discriminator for improved adversarial training. Our system is evaluated using two MR databases of subjects with traumatic brain injuries, acquired using different scanners and imaging protocols. Using our unsupervised approach, we obtain segmentation accuracies which are close to the upper bound of supervised domain adaptation.
Fairness as a Program Property
Oct 19, 2016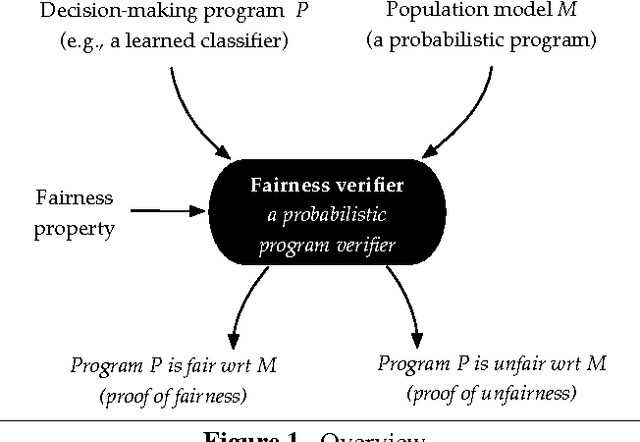
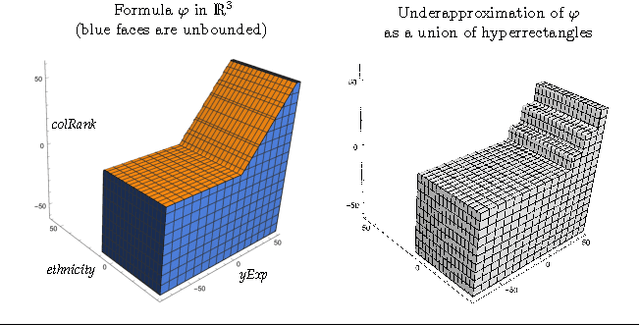
We explore the following question: Is a decision-making program fair, for some useful definition of fairness? First, we describe how several algorithmic fairness questions can be phrased as program verification problems. Second, we discuss an automated verification technique for proving or disproving fairness of decision-making programs with respect to a probabilistic model of the population.
Debugging Machine Learning Tasks
Mar 23, 2016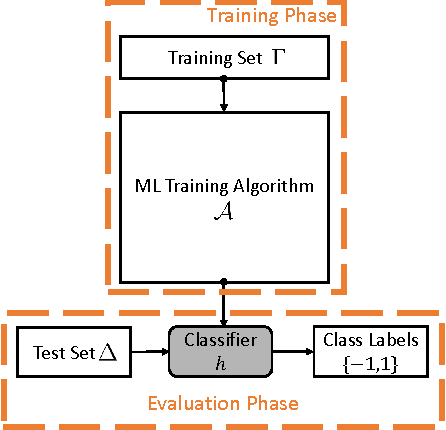

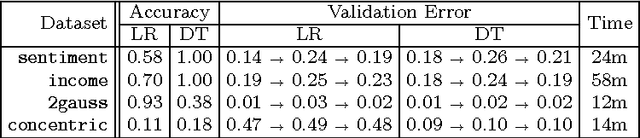
Unlike traditional programs (such as operating systems or word processors) which have large amounts of code, machine learning tasks use programs with relatively small amounts of code (written in machine learning libraries), but voluminous amounts of data. Just like developers of traditional programs debug errors in their code, developers of machine learning tasks debug and fix errors in their data. However, algorithms and tools for debugging and fixing errors in data are less common, when compared to their counterparts for detecting and fixing errors in code. In this paper, we consider classification tasks where errors in training data lead to misclassifications in test points, and propose an automated method to find the root causes of such misclassifications. Our root cause analysis is based on Pearl's theory of causation, and uses Pearl's PS (Probability of Sufficiency) as a scoring metric. Our implementation, Psi, encodes the computation of PS as a probabilistic program, and uses recent work on probabilistic programs and transformations on probabilistic programs (along with gray-box models of machine learning algorithms) to efficiently compute PS. Psi is able to identify root causes of data errors in interesting data sets.