 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep End-to-end Causal Inference
Feb 04, 2022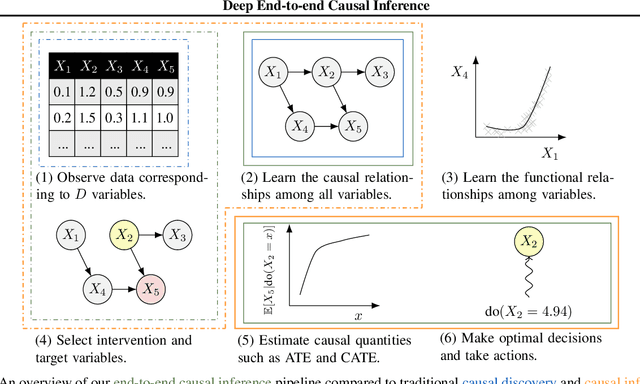
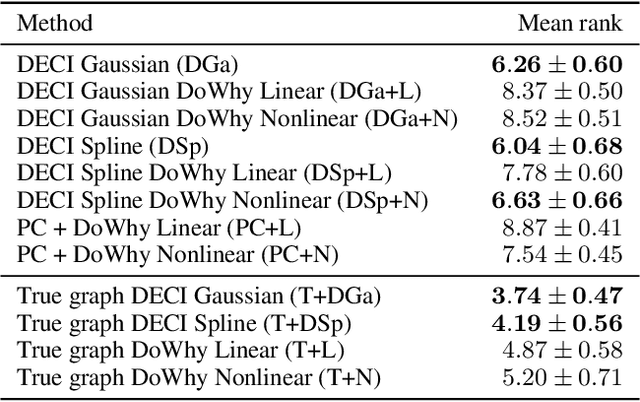
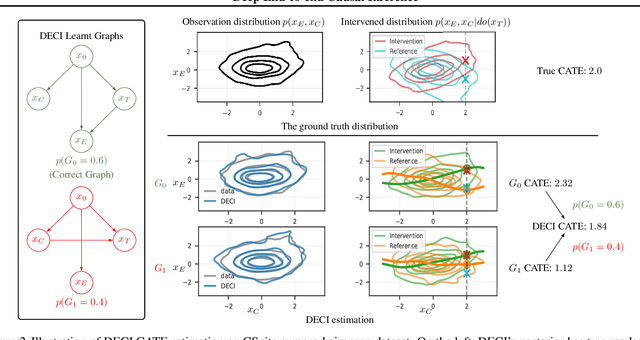
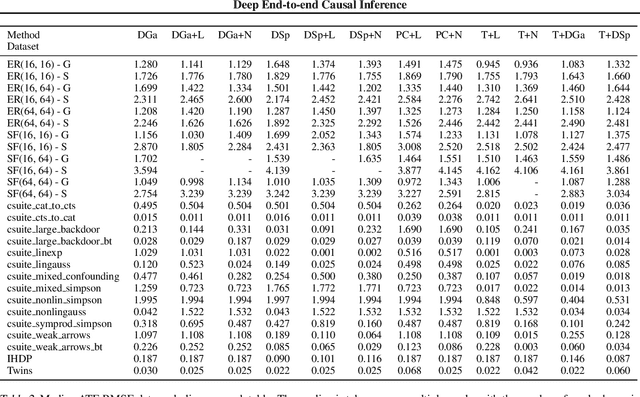
Causal inference is essential for data-driven decision making across domains such as business engagement, medical treatment or policy making. However, research on causal discovery and inference has evolved separately, and the combination of the two domains is not trivial. In this work, we develop Deep End-to-end Causal Inference (DECI), a single flow-based method that takes in observational data and can perform both causal discovery and inference, including conditional average treatment effect (CATE) estimation. We provide a theoretical guarantee that DECI can recover the ground truth causal graph under mild assumptions. In addition, our method can handle heterogeneous, real-world, mixed-type data with missing values, allowing for both continuous and discrete treatment decisions. Moreover, the design principle of our method can generalize beyond DECI, providing a general End-to-end Causal Inference (ECI) recipe, which enables different ECI frameworks to be built using existing methods. Our results show the superior performance of DECI when compared to relevant baselines for both causal discovery and (C)ATE estimation in over a thousand experiments on both synthetic datasets and other causal machine learning benchmark datasets.
Implicit Deep Adaptive Design: Policy-Based Experimental Design without Likelihoods
Nov 03, 2021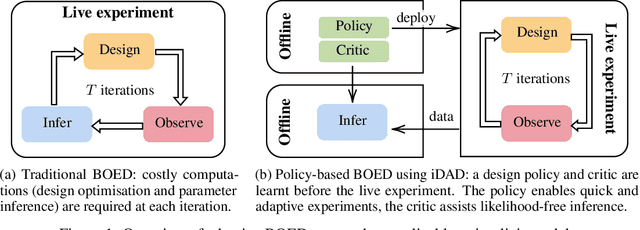
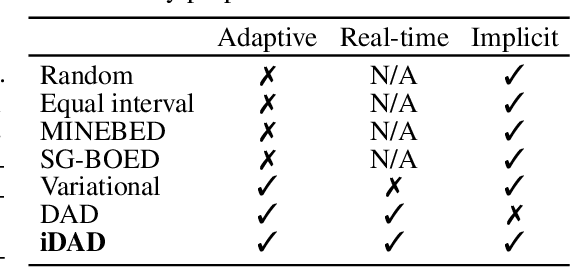
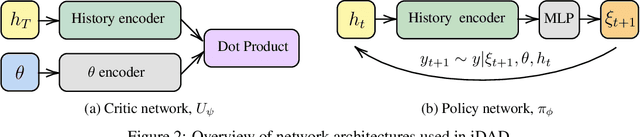
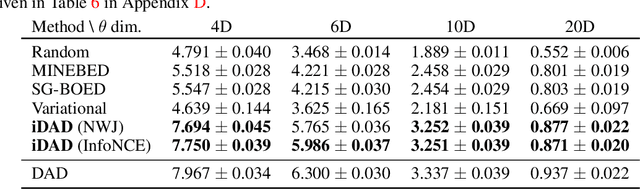
We introduce implicit Deep Adaptive Design (iDAD), a new method for performing adaptive experiments in real-time with implicit models. iDAD amortizes the cost of Bayesian optimal experimental design (BOED) by learning a design policy network upfront, which can then be deployed quickly at the time of the experiment. The iDAD network can be trained on any model which simulates differentiable samples, unlike previous design policy work that requires a closed form likelihood and conditionally independent experiments. At deployment, iDAD allows design decisions to be made in milliseconds, in contrast to traditional BOED approaches that require heavy computation during the experiment itself. We illustrate the applicability of iDAD on a number of experiments, and show that it provides a fast and effective mechanism for performing adaptive design with implicit models.
On Contrastive Representations of Stochastic Processes
Jun 18, 2021


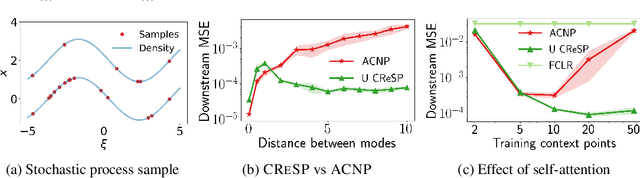
Learning representations of stochastic processes is an emerging problem in machine learning with applications from meta-learning to physical object models to time series. Typical methods rely on exact reconstruction of observations, but this approach breaks down as observations become high-dimensional or noise distributions become complex. To address this, we propose a unifying framework for learning contrastive representations of stochastic processes (CRESP) that does away with exact reconstruction. We dissect potential use cases for stochastic process representations, and propose methods that accommodate each. Empirically, we show that our methods are effective for learning representations of periodic functions, 3D objects and dynamical processes. Our methods tolerate noisy high-dimensional observations better than traditional approaches, and the learned representations transfer to a range of downstream tasks.
Contrastive Mixture of Posteriors for Counterfactual Inference, Data Integration and Fairness
Jun 15, 2021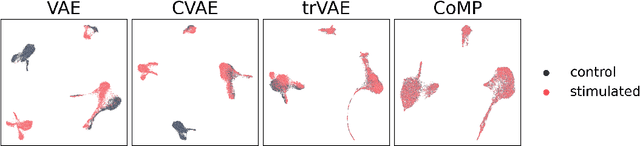
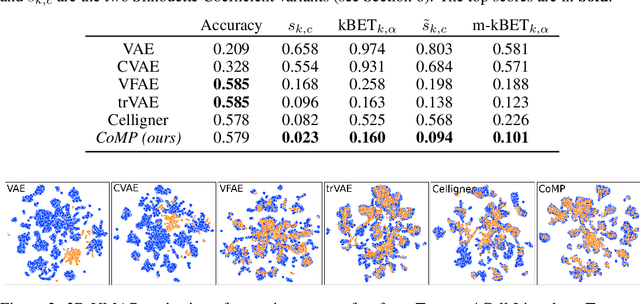
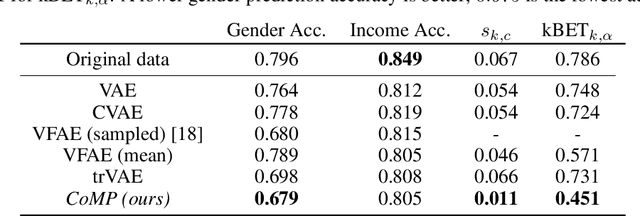
Learning meaningful representations of data that can address challenges such as batch effect correction, data integration and counterfactual inference is a central problem in many domains including computational biology. Adopting a Conditional VAE framework, we identify the mathematical principle that unites these challenges: learning a representation that is marginally independent of a condition variable. We therefore propose the Contrastive Mixture of Posteriors (CoMP) method that uses a novel misalignment penalty to enforce this independence. This penalty is defined in terms of mixtures of the variational posteriors themselves, unlike prior work which uses external discrepancy measures such as MMD to ensure independence in latent space. We show that CoMP has attractive theoretical properties compared to previous approaches, especially when there is complex global structure in latent space. We further demonstrate state of the art performance on a number of real-world problems, including the challenging tasks of aligning human tumour samples with cancer cell-lines and performing counterfactual inference on single-cell RNA sequencing data. Incidentally, we find parallels with the fair representation learning literature, and demonstrate CoMP has competitive performance in learning fair yet expressive latent representations.
Deep Adaptive Design: Amortizing Sequential Bayesian Experimental Design
Mar 03, 2021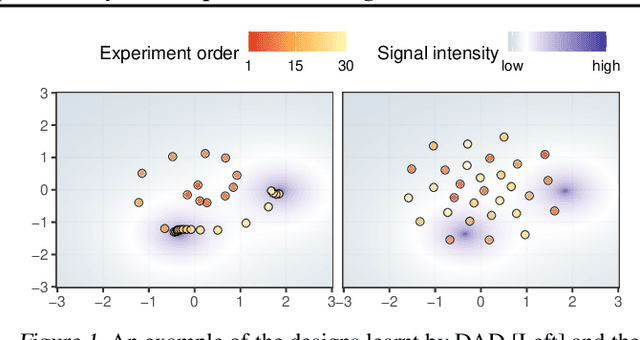

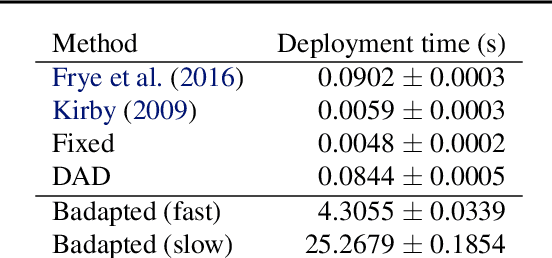
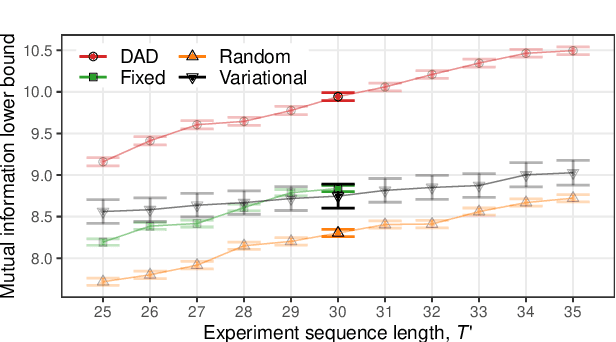
We introduce Deep Adaptive Design (DAD), a general method for amortizing the cost of performing sequential adaptive experiments using the framework of Bayesian optimal experimental design (BOED). Traditional sequential BOED approaches require substantial computational time at each stage of the experiment. This makes them unsuitable for most real-world applications, where decisions must typically be made quickly. DAD addresses this restriction by learning an amortized design network upfront and then using this to rapidly run (multiple) adaptive experiments at deployment time. This network takes as input the data from previous steps, and outputs the next design using a single forward pass; these design decisions can be made in milliseconds during the live experiment. To train the network, we introduce contrastive information bounds that are suitable objectives for the sequential setting, and propose a customized network architecture that exploits key symmetries. We demonstrate that DAD successfully amortizes the process of experimental design, outperforming alternative strategies on a number of problems.
Improving Transformation Invariance in Contrastive Representation Learning
Oct 19, 2020
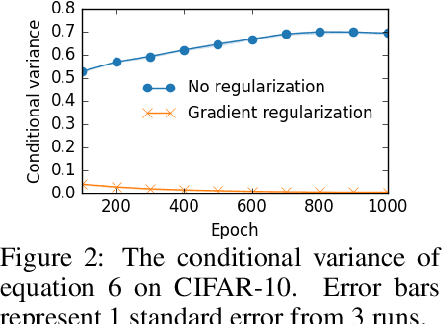
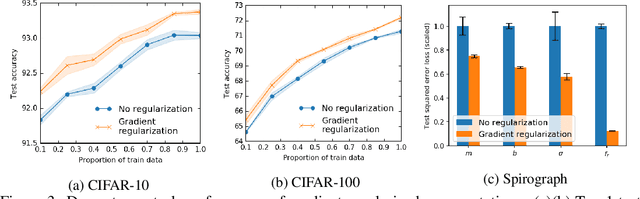

We propose methods to strengthen the invariance properties of representations obtained by contrastive learning. While existing approaches implicitly induce a degree of invariance as representations are learned, we look to more directly enforce invariance in the encoding process. To this end, we first introduce a training objective for contrastive learning that uses a novel regularizer to control how the representation changes under transformation. We show that representations trained with this objective perform better on downstream tasks and are more robust to the introduction of nuisance transformations at test time. Second, we propose a change to how test time representations are generated by introducing a feature averaging approach that combines encodings from multiple transformations of the original input, finding that this leads to across the board performance gains. Finally, we introduce the novel Spirograph dataset to explore our ideas in the context of a differentiable generative process with multiple downstream tasks, showing that our techniques for learning invariance are highly beneficial.
A Unified Stochastic Gradient Approach to Designing Bayesian-Optimal Experiments
Nov 01, 2019
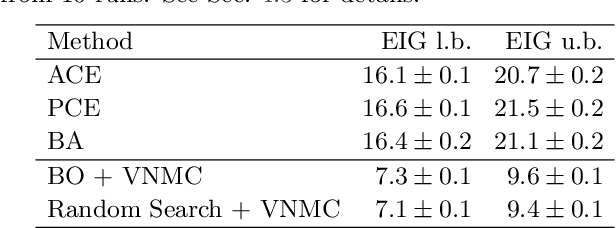
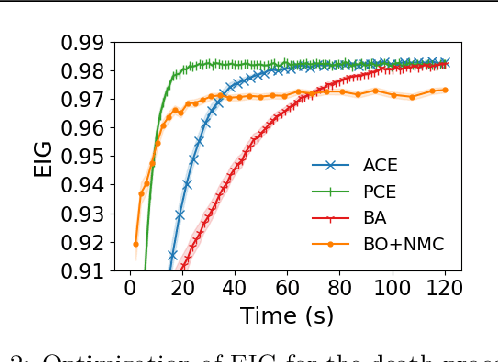
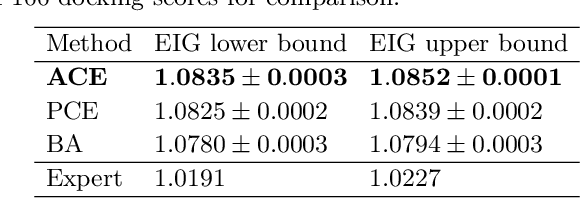
We introduce a fully stochastic gradient based approach to Bayesian optimal experimental design (BOED). This is achieved through the use of variational lower bounds on the expected information gain (EIG) of an experiment that can be simultaneously optimized with respect to both the variational and design parameters. This allows the design process to be carried out through a single unified stochastic gradient ascent procedure, in contrast to existing approaches that typically construct an EIG estimator on a pointwise basis, before passing this estimator to a separate optimizer. We show that this, in turn, leads to more efficient BOED schemes and provide a number of a different variational objectives suited to different settings. Furthermore, we show that our gradient-based approaches are able to provide effective design optimization in substantially higher dimensional settings than existing approaches.
Variational Estimators for Bayesian Optimal Experimental Design
Mar 13, 2019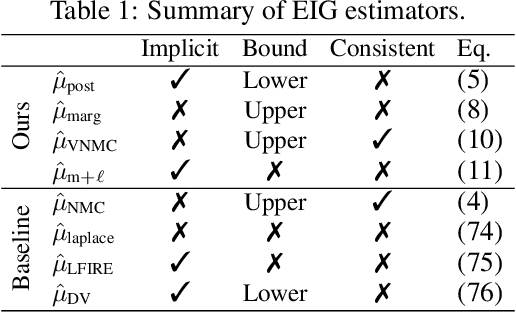
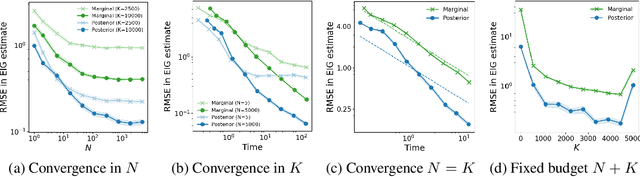
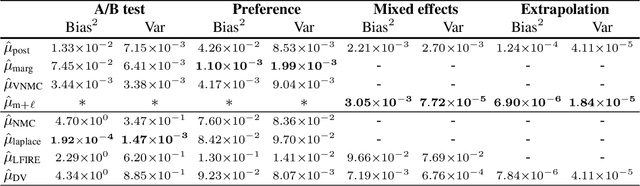
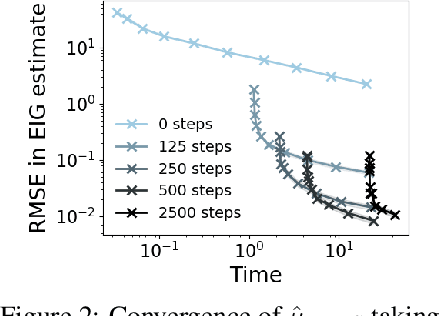
Bayesian optimal experimental design (BOED) is a principled framework for making efficient use of limited experimental resources. Unfortunately, its applicability is hampered by the difficulty of obtaining accurate estimates of the expected information gain (EIG) of an experiment. To address this, we introduce several classes of fast EIG estimators suited to the experiment design context by building on ideas from variational inference and mutual information estimation. We show theoretically and empirically that these estimators can provide significant gains in speed and accuracy over previous approaches. We demonstrate the practicality of our approach via a number of experiments, including an adaptive experiment with human participants.
Sampling and Inference for Beta Neutral-to-the-Left Models of Sparse Networks
Jul 09, 2018
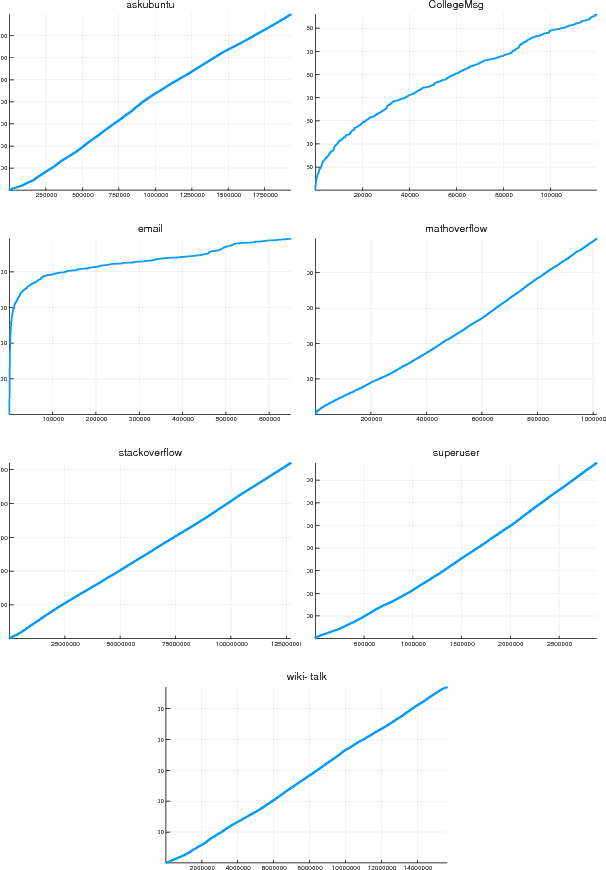


Empirical evidence suggests that heavy-tailed degree distributions occurring in many real networks are well-approximated by power laws with exponents $\eta$ that may take values either less than and greater than two. Models based on various forms of exchangeability are able to capture power laws with $\eta < 2$, and admit tractable inference algorithms; we draw on previous results to show that $\eta > 2$ cannot be generated by the forms of exchangeability used in existing random graph models. Preferential attachment models generate power law exponents greater than two, but have been of limited use as statistical models due to the inherent difficulty of performing inference in non-exchangeable models. Motivated by this gap, we design and implement inference algorithms for a recently proposed class of models that generates $\eta$ of all possible values. We show that although they are not exchangeable, these models have probabilistic structure amenable to inference. Our methods make a large class of previously intractable models useful for statistical inference.