 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Controlling Model Selection via Guided Bayesian Optimization
Dec 04, 2023Adjustable hyperparameters of machine learning models typically impact various key trade-offs such as accuracy, fairness, robustness, or inference cost. Our goal in this paper is to find a configuration that adheres to user-specified limits on certain risks while being useful with respect to other conflicting metrics. We solve this by combining Bayesian Optimization (BO) with rigorous risk-controlling procedures, where our core idea is to steer BO towards an efficient testing strategy. Our BO method identifies a set of Pareto optimal configurations residing in a designated region of interest. The resulting candidates are statistically verified and the best-performing configuration is selected with guaranteed risk levels. We demonstrate the effectiveness of our approach on a range of tasks with multiple desiderata, including low error rates, equitable predictions, handling spurious correlations, managing rate and distortion in generative models, and reducing computational costs.
Towards Robust and Efficient Continual Language Learning
Jul 11, 2023



As the application space of language models continues to evolve, a natural question to ask is how we can quickly adapt models to new tasks. We approach this classic question from a continual learning perspective, in which we aim to continue fine-tuning models trained on past tasks on new tasks, with the goal of "transferring" relevant knowledge. However, this strategy also runs the risk of doing more harm than good, i.e., negative transfer. In this paper, we construct a new benchmark of task sequences that target different possible transfer scenarios one might face, such as a sequence of tasks with high potential of positive transfer, high potential for negative transfer, no expected effect, or a mixture of each. An ideal learner should be able to maximally exploit information from all tasks that have any potential for positive transfer, while also avoiding the negative effects of any distracting tasks that may confuse it. We then propose a simple, yet effective, learner that satisfies many of our desiderata simply by leveraging a selective strategy for initializing new models from past task checkpoints. Still, limitations remain, and we hope this benchmark can help the community to further build and analyze such learners.
Conformal Language Modeling
Jun 16, 2023We propose a novel approach to conformal prediction for generative language models (LMs). Standard conformal prediction produces prediction sets -- in place of single predictions -- that have rigorous, statistical performance guarantees. LM responses are typically sampled from the model's predicted distribution over the large, combinatorial output space of natural language. Translating this process to conformal prediction, we calibrate a stopping rule for sampling different outputs from the LM that get added to a growing set of candidates until we are confident that the output set is sufficient. Since some samples may be low-quality, we also simultaneously calibrate and apply a rejection rule for removing candidates from the output set to reduce noise. Similar to conformal prediction, we prove that the sampled set returned by our procedure contains at least one acceptable answer with high probability, while still being empirically precise (i.e., small) on average. Furthermore, within this set of candidate responses, we show that we can also accurately identify subsets of individual components -- such as phrases or sentences -- that are each independently correct (e.g., that are not "hallucinations"), again with statistical guarantees. We demonstrate the promise of our approach on multiple tasks in open-domain question answering, text summarization, and radiology report generation using different LM variants.
Efficiently Controlling Multiple Risks with Pareto Testing
Oct 14, 2022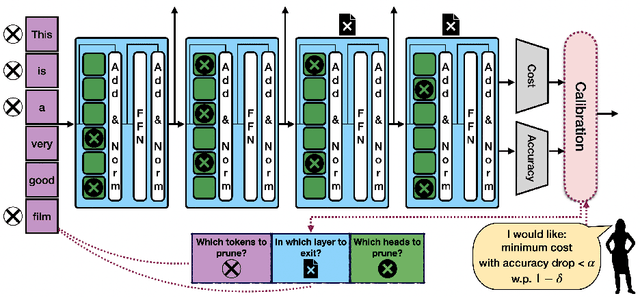
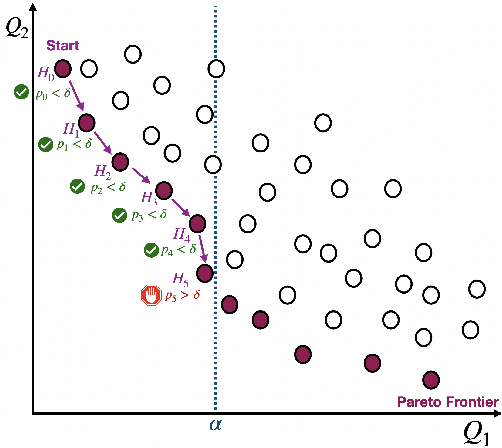
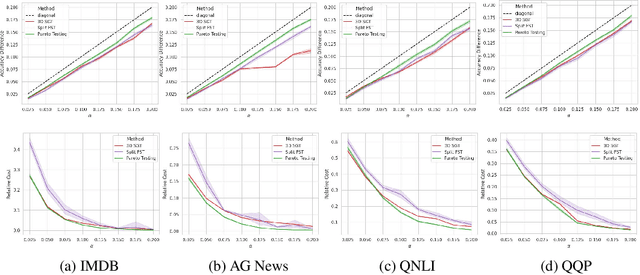
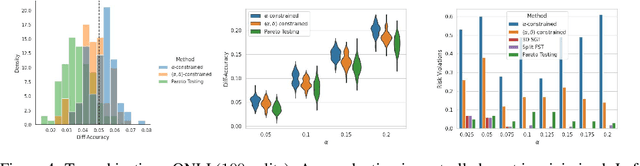
Machine learning applications frequently come with multiple diverse objectives and constraints that can change over time. Accordingly, trained models can be tuned with sets of hyper-parameters that affect their predictive behavior (e.g., their run-time efficiency versus error rate). As the number of constraints and hyper-parameter dimensions grow, naively selected settings may lead to sub-optimal and/or unreliable results. We develop an efficient method for calibrating models such that their predictions provably satisfy multiple explicit and simultaneous statistical guarantees (e.g., upper-bounded error rates), while also optimizing any number of additional, unconstrained objectives (e.g., total run-time cost). Building on recent results in distribution-free, finite-sample risk control for general losses, we propose Pareto Testing: a two-stage process which combines multi-objective optimization with multiple hypothesis testing. The optimization stage constructs a set of promising combinations on the Pareto frontier. We then apply statistical testing to this frontier only to identify configurations that have (i) high utility with respect to our objectives, and (ii) guaranteed risk levels with respect to our constraints, with specifiable high probability. We demonstrate the effectiveness of our approach to reliably accelerate the execution of large-scale Transformer models in natural language processing (NLP) applications. In particular, we show how Pareto Testing can be used to dynamically configure multiple inter-dependent model attributes -- including the number of layers computed before exiting, number of attention heads pruned, or number of text tokens considered -- to simultaneously control and optimize various accuracy and cost metrics.
Calibrated Selective Classification
Aug 25, 2022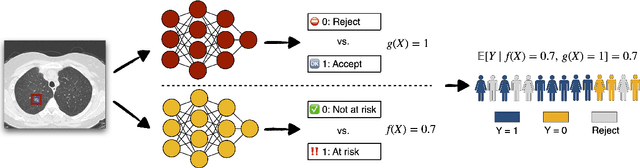
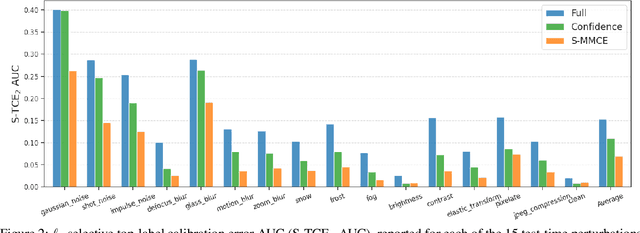
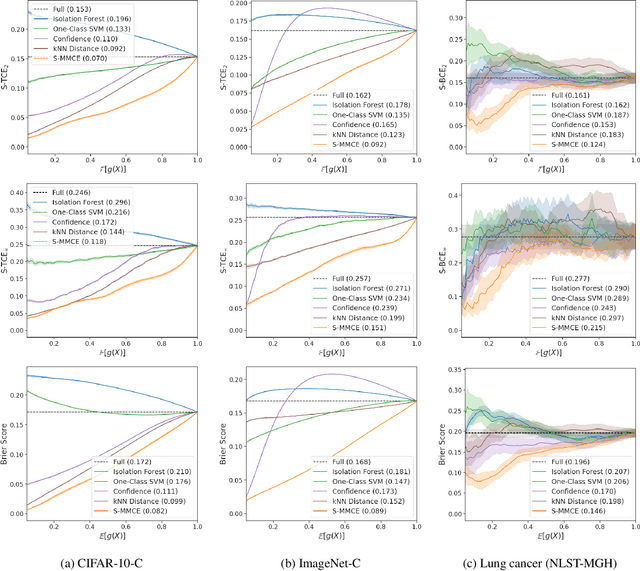
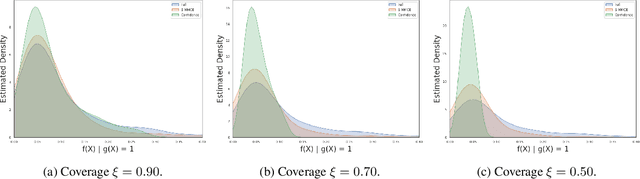
Selective classification allows models to abstain from making predictions (e.g., say "I don't know") when in doubt in order to obtain better effective accuracy. While typical selective models can be effective at producing more accurate predictions on average, they may still allow for wrong predictions that have high confidence, or skip correct predictions that have low confidence. Providing calibrated uncertainty estimates alongside predictions -- probabilities that correspond to true frequencies -- can be as important as having predictions that are simply accurate on average. However, uncertainty estimates can be unreliable for certain inputs. In this paper, we develop a new approach to selective classification in which we propose a method for rejecting examples with "uncertain" uncertainties. By doing so, we aim to make predictions with {well-calibrated} uncertainty estimates over the distribution of accepted examples, a property we call selective calibration. We present a framework for learning selectively calibrated models, where a separate selector network is trained to improve the selective calibration error of a given base model. In particular, our work focuses on achieving robust calibration, where the model is intentionally designed to be tested on out-of-domain data. We achieve this through a training strategy inspired by distributionally robust optimization, in which we apply simulated input perturbations to the known, in-domain training data. We demonstrate the empirical effectiveness of our approach on multiple image classification and lung cancer risk assessment tasks.
Conformal Risk Control
Aug 04, 2022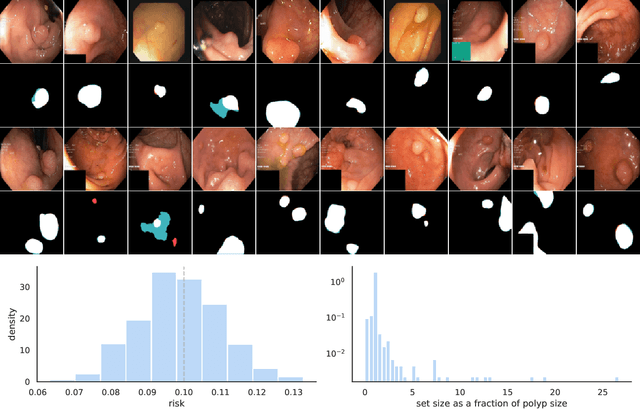
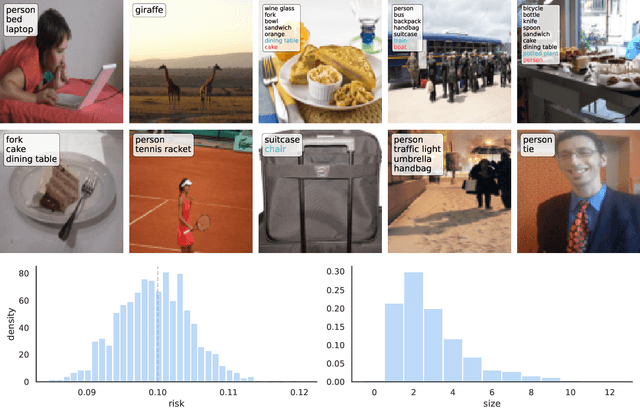
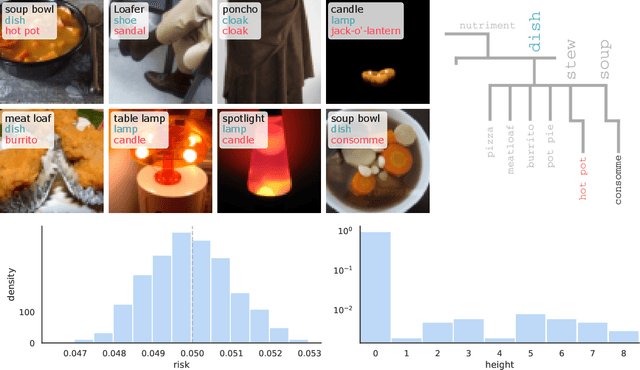
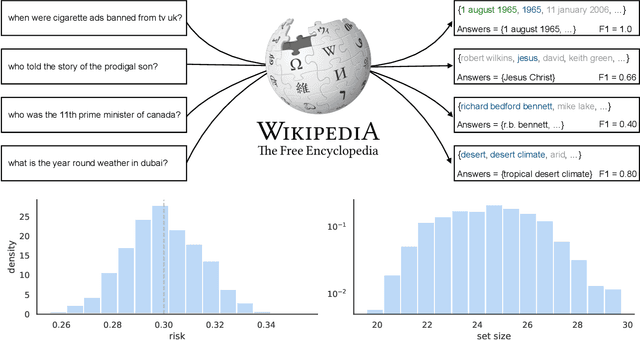
We extend conformal prediction to control the expected value of any monotone loss function. The algorithm generalizes split conformal prediction together with its coverage guarantee. Like conformal prediction, the conformal risk control procedure is tight up to an $\mathcal{O}(1/n)$ factor. Worked examples from computer vision and natural language processing demonstrate the usage of our algorithm to bound the false negative rate, graph distance, and token-level F1-score.
Confident Adaptive Language Modeling
Jul 14, 2022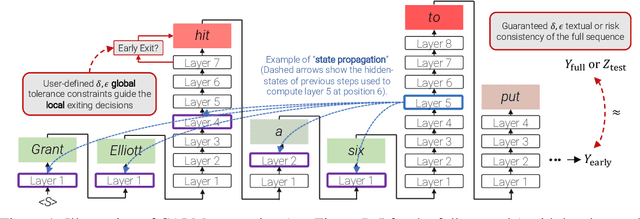
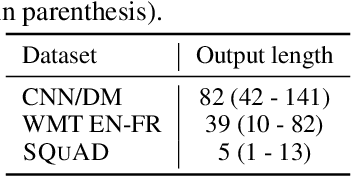
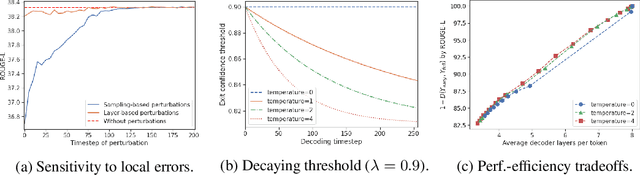
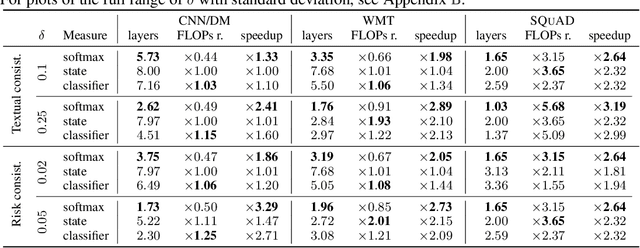
Recent advances in Transformer-based large language models (LLMs) have led to significant performance improvements across many tasks. These gains come with a drastic increase in the models' size, potentially leading to slow and costly use at inference time. In practice, however, the series of generations made by LLMs is composed of varying levels of difficulty. While certain predictions truly benefit from the models' full capacity, other continuations are more trivial and can be solved with reduced compute. In this work, we introduce Confident Adaptive Language Modeling (CALM), a framework for dynamically allocating different amounts of compute per input and generation timestep. Early exit decoding involves several challenges that we address here, such as: (1) what confidence measure to use; (2) connecting sequence-level constraints to local per-token exit decisions; and (3) attending back to missing hidden representations due to early exits in previous tokens. Through theoretical analysis and empirical experiments on three diverse text generation tasks, we demonstrate the efficacy of our framework in reducing compute -- potential speedup of up to $\times 3$ -- while provably maintaining high performance.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Conformal Prediction Sets with Limited False Positives
Feb 15, 2022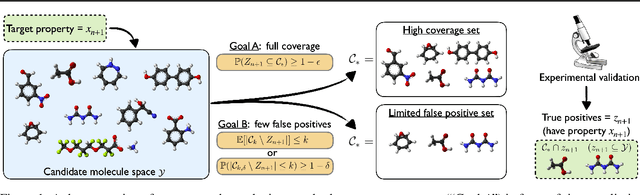
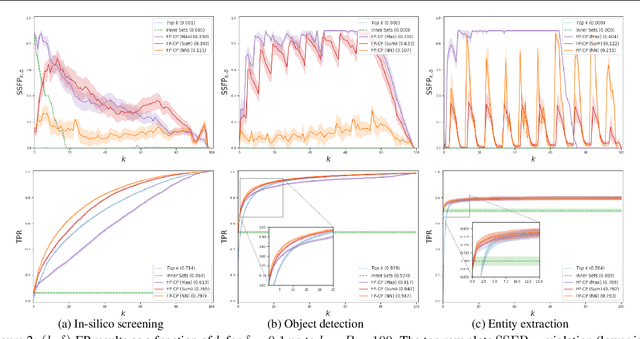
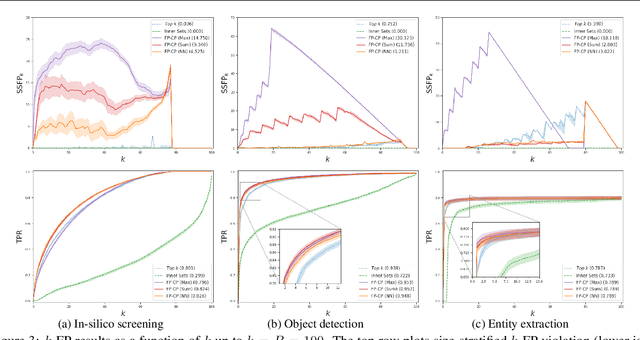
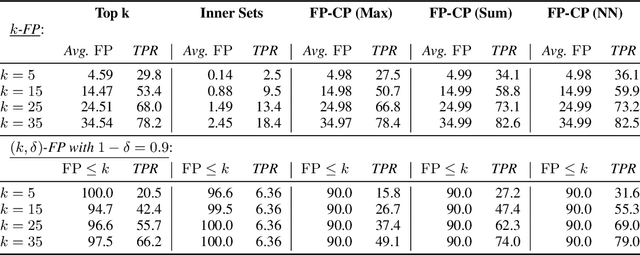
We develop a new approach to multi-label conformal prediction in which we aim to output a precise set of promising prediction candidates with a bounded number of incorrect answers. Standard conformal prediction provides the ability to adapt to model uncertainty by constructing a calibrated candidate set in place of a single prediction, with guarantees that the set contains the correct answer with high probability. In order to obey this coverage property, however, conformal sets can become inundated with noisy candidates -- which can render them unhelpful in practice. This is particularly relevant to practical applications where there is a limited budget, and the cost (monetary or otherwise) associated with false positives is non-negligible. We propose to trade coverage for a notion of precision by enforcing that the presence of incorrect candidates in the predicted conformal sets (i.e., the total number of false positives) is bounded according to a user-specified tolerance. Subject to this constraint, our algorithm then optimizes for a generalized notion of set coverage (i.e., the true positive rate) that allows for any number of true answers for a given query (including zero). We demonstrate the effectiveness of this approach across a number of classification tasks in natural language processing, computer vision, and computational chemistry.
Consistent Accelerated Inference via Confident Adaptive Transformers
Apr 18, 2021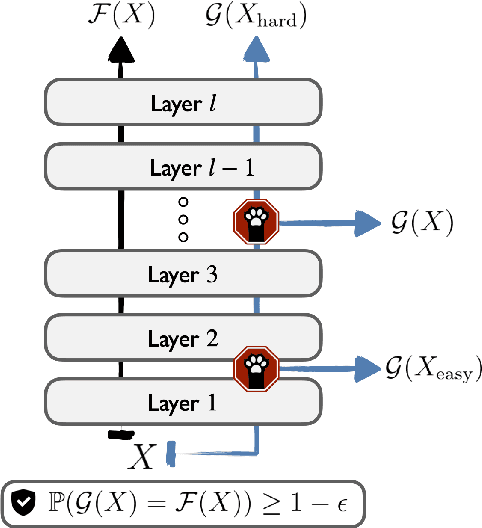

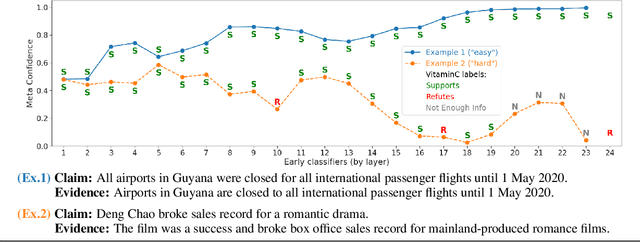
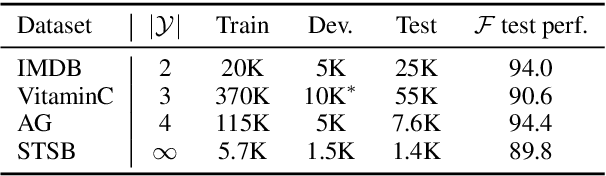
We develop a novel approach for confidently accelerating inference in the large and expensive multilayer Transformers that are now ubiquitous in natural language processing (NLP). Amortized or approximate computational methods increase efficiency, but can come with unpredictable performance costs. In this work, we present CATs -- Confident Adaptive Transformers -- in which we simultaneously increase computational efficiency, while guaranteeing a specifiable degree of consistency with the original model with high confidence. Our method trains additional prediction heads on top of intermediate layers, and dynamically decides when to stop allocating computational effort to each input using a meta consistency classifier. To calibrate our early prediction stopping rule, we formulate a unique extension of conformal prediction. We demonstrate the effectiveness of this approach on four classification and regression tasks.