 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoinT-5: Pointer Network and T-5 based Financial NarrativeSummarisation
Oct 12, 2020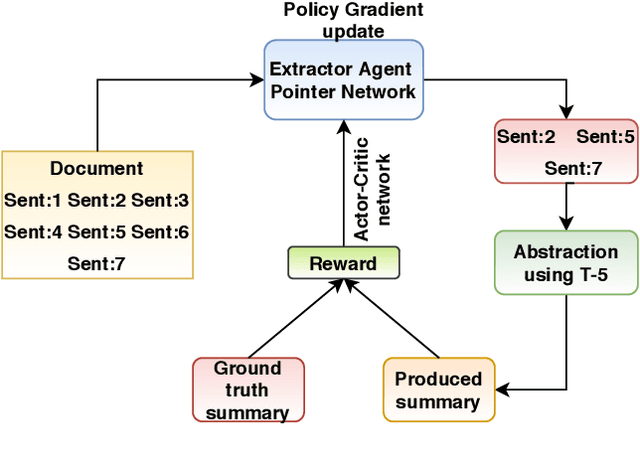
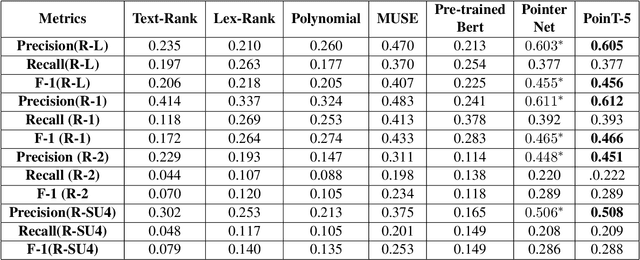

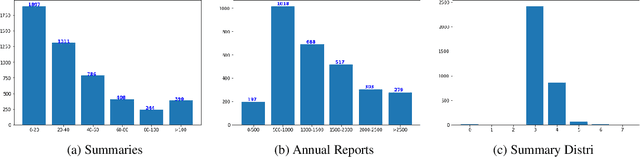
Companies provide annual reports to their shareholders at the end of the financial year that describes their operations and financial conditions. The average length of these reports is 80, and it may extend up to 250 pages long. In this paper, we propose our methodology PoinT-5 (the combination of Pointer Network and T-5 (Test-to-text transfer Transformer) algorithms) that we used in the Financial Narrative Summarisation (FNS) 2020 task. The proposed method uses pointer networks to extract important narrative sentences from the report, and then T-5 is used to paraphrase extracted sentences into a concise yet informative sentence. We evaluate our method using ROUGE-N (1,2), L, and SU4. The proposed method achieves the highest precision scores in all the metrics and highest F1 scores in ROUGE1, and LCS and the only solution to cross the MUSE solution baseline in ROUGE-LCS metrics.
Proximity Sensing for Contact Tracing
Sep 04, 2020
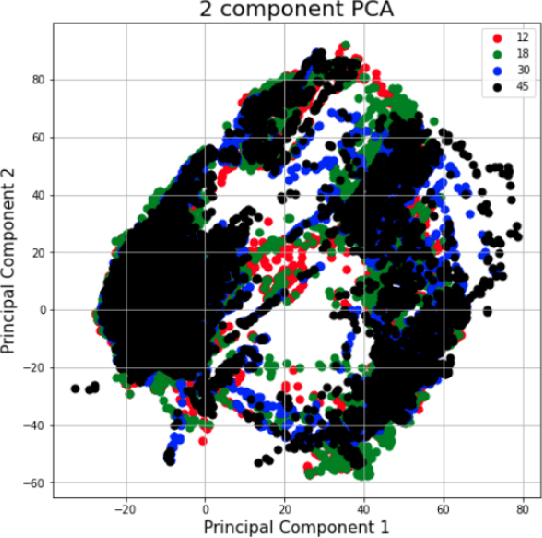
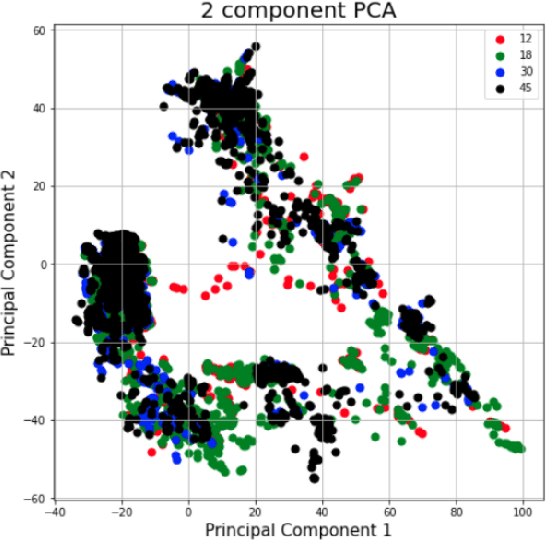
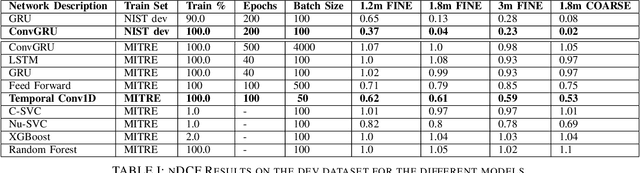
The TC4TL (Too Close For Too Long) challenge is aimed towards designing an effective proximity sensing algorithm that can accurately provide exposure notifications. In this paper, we describe our approach to model sensor and other device-level data to estimate the distance between two phones. We also present our research and data analysis on the TC4TL challenge and discuss various limitations associated with the task, and the dataset used for this purpose.
NoPeek: Information leakage reduction to share activations in distributed deep learning
Aug 20, 2020
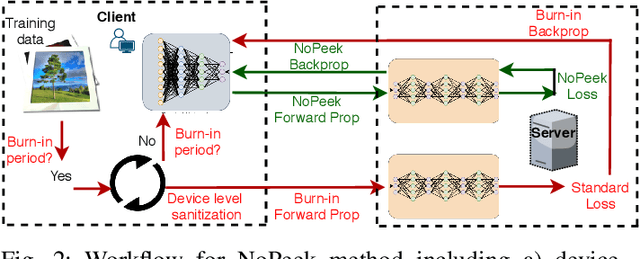
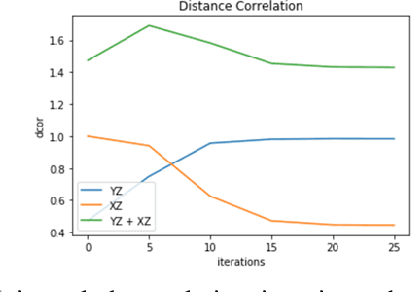
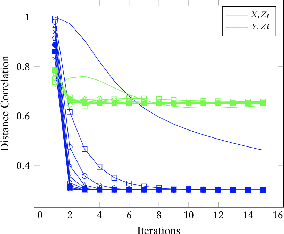
For distributed machine learning with sensitive data, we demonstrate how minimizing distance correlation between raw data and intermediary representations reduces leakage of sensitive raw data patterns across client communications while maintaining model accuracy. Leakage (measured using distance correlation between input and intermediate representations) is the risk associated with the invertibility of raw data from intermediary representations. This can prevent client entities that hold sensitive data from using distributed deep learning services. We demonstrate that our method is resilient to such reconstruction attacks and is based on reduction of distance correlation between raw data and learned representations during training and inference with image datasets. We prevent such reconstruction of raw data while maintaining information required to sustain good classification accuracies.
SplitNN-driven Vertical Partitioning
Aug 07, 2020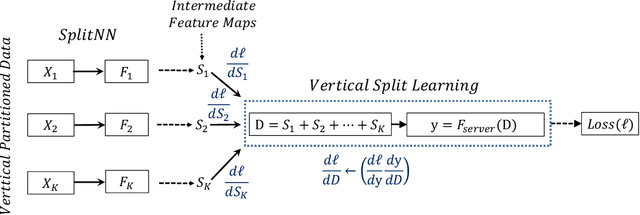
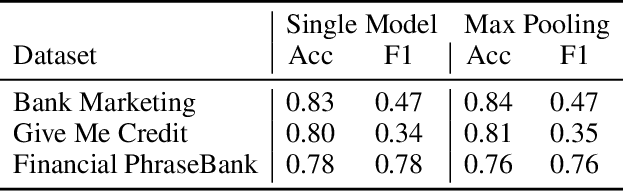
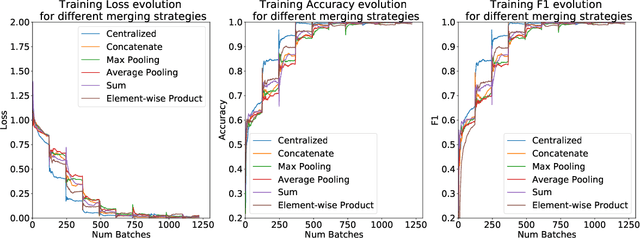
In this work, we introduce SplitNN-driven Vertical Partitioning, a configuration of a distributed deep learning method called SplitNN to facilitate learning from vertically distributed features. SplitNN does not share raw data or model details with collaborating institutions. The proposed configuration allows training among institutions holding diverse sources of data without the need of complex encryption algorithms or secure computation protocols. We evaluate several configurations to merge the outputs of the split models, and compare performance and resource efficiency. The method is flexible and allows many different configurations to tackle the specific challenges posed by vertically split datasets.
FedML: A Research Library and Benchmark for Federated Machine Learning
Jul 27, 2020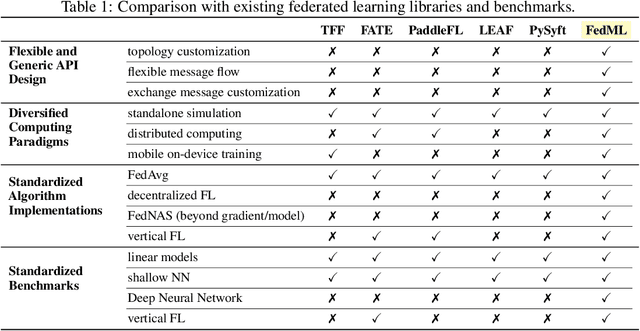
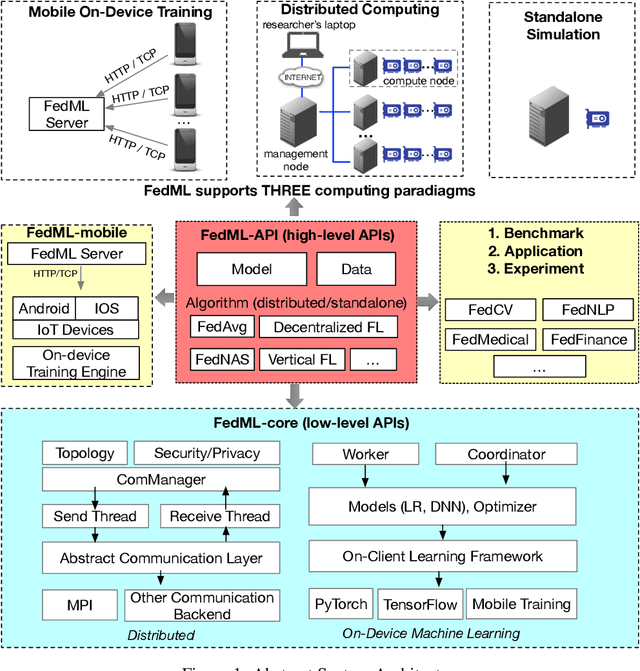


Federated learning is a rapidly growing research field in the machine learning domain. Although considerable research efforts have been made, existing libraries cannot adequately support diverse algorithmic development (e.g., diverse topology and flexible message exchange), and inconsistent dataset and model usage in experiments make fair comparisons difficult. In this work, we introduce FedML, an open research library and benchmark that facilitates the development of new federated learning algorithms and fair performance comparisons. FedML supports three computing paradigms (distributed training, mobile on-device training, and standalone simulation) for users to conduct experiments in different system environments. FedML also promotes diverse algorithmic research with flexible and generic API design and reference baseline implementations. A curated and comprehensive benchmark dataset for the non-I.I.D setting aims at making a fair comparison. We believe FedML can provide an efficient and reproducible means of developing and evaluating algorithms for the federated learning research community. We maintain the source code, documents, and user community at https://FedML.ai.
Voice@SRIB at SemEval-2020 Task : Sentiment and Offensiveness detection in Social Media
Jul 20, 2020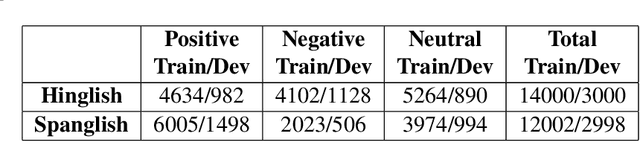
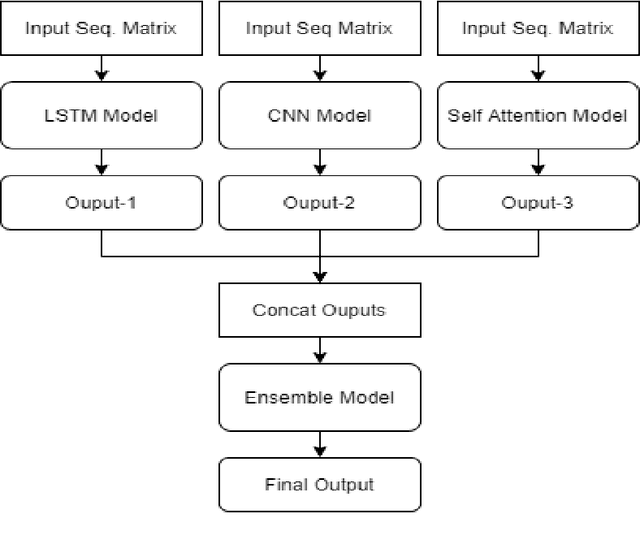
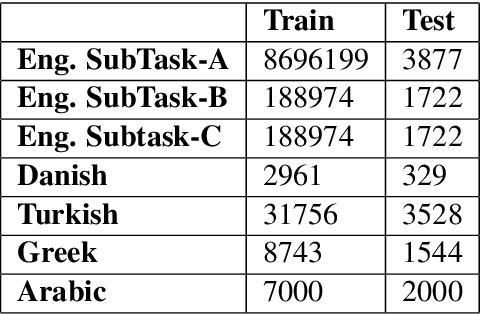
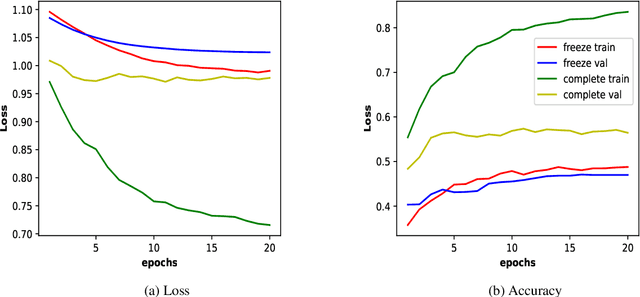
In social-media platforms such as Twitter, Facebook, and Reddit, people prefer to use code-mixed language such as Spanish-English, Hindi-English to express their opinions. In this paper, we describe different models we used, using the external dataset to train embeddings, ensembling methods for Sentimix, and OffensEval tasks. The use of pre-trained embeddings usually helps in multiple tasks such as sentence classification, and machine translation. In this experiment, we haveused our trained code-mixed embeddings and twitter pre-trained embeddings to SemEval tasks. We evaluate our models on macro F1-score, precision, accuracy, and recall on the datasets. We intend to show that hyper-parameter tuning and data pre-processing steps help a lot in improving the scores. In our experiments, we are able to achieve 0.886 F1-Macro on OffenEval Greek language subtask post-evaluation, whereas the highest is 0.852 during the Evaluation Period. We stood third in Spanglish competition with our best F1-score of 0.756. Codalab username is asking28.
Privacy in Deep Learning: A Survey
May 09, 2020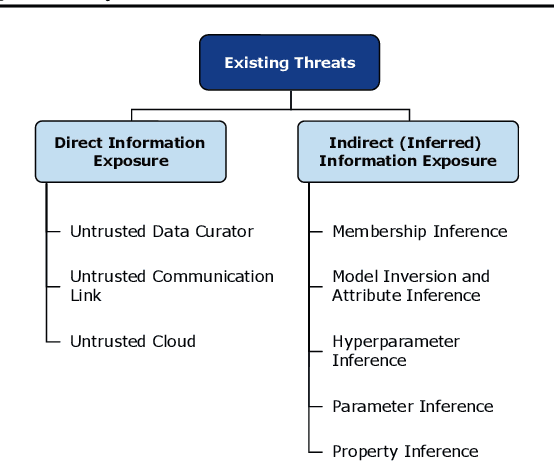


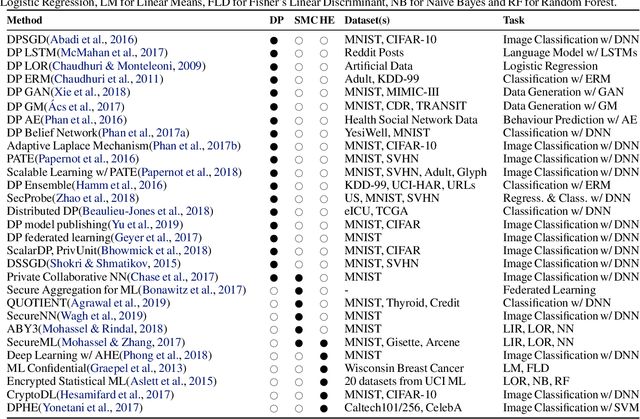
The ever-growing advances of deep learning in many areas including vision, recommendation systems, natural language processing, etc., have led to the adoption of Deep Neural Networks (DNNs) in production systems. The availability of large datasets and high computational power are the main contributors to these advances. The datasets are usually crowdsourced and may contain sensitive information. This poses serious privacy concerns as this data can be misused or leaked through various vulnerabilities. Even if the cloud provider and the communication link is trusted, there are still threats of inference attacks where an attacker could speculate properties of the data used for training, or find the underlying model architecture and parameters. In this survey, we review the privacy concerns brought by deep learning, and the mitigating techniques introduced to tackle these issues. We also show that there is a gap in the literature regarding test-time inference privacy, and propose possible future research directions.
Clinical XLNet: Modeling Sequential Clinical Notes and Predicting Prolonged Mechanical Ventilation
Dec 27, 2019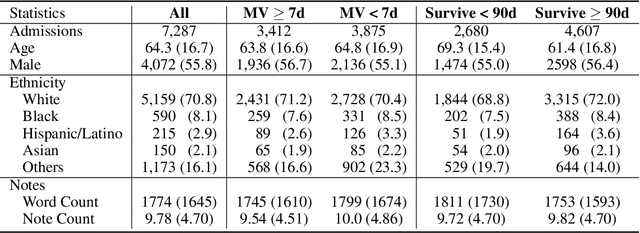
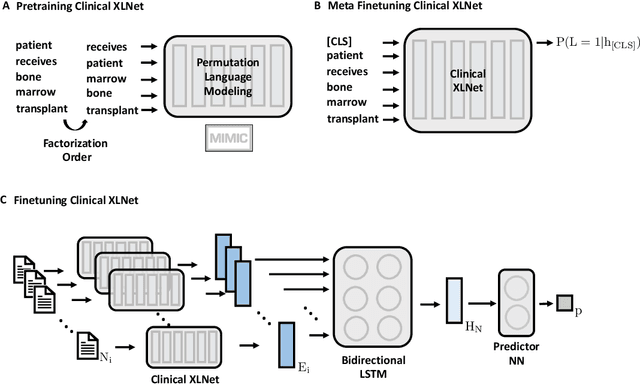
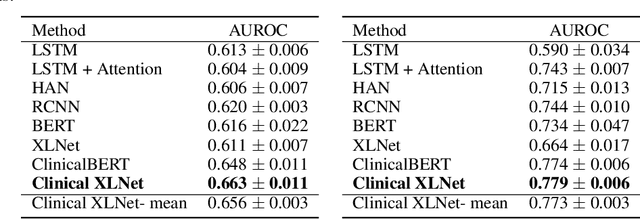
Clinical notes contain rich data, which is unexploited in predictive modeling compared to structured data. In this work, we developed a new text representation Clinical XLNet for clinical notes which also leverages the temporal information of the sequence of the notes. We evaluated our models on prolonged mechanical ventilation prediction problem and our experiments demonstrated that Clinical XLNet outperforms the best baselines consistently.
NASIB: Neural Architecture Search withIn Budget
Oct 19, 2019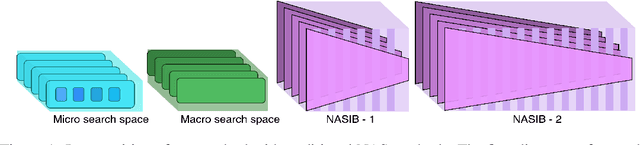
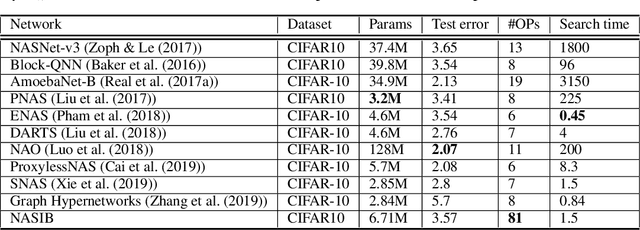
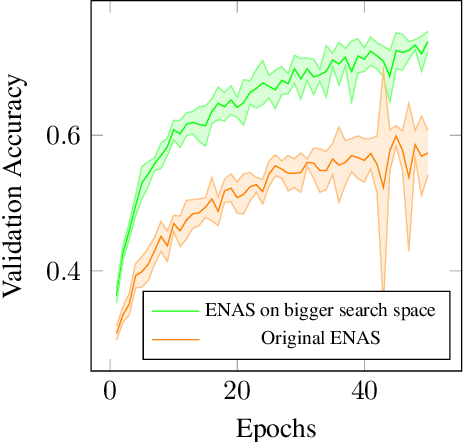
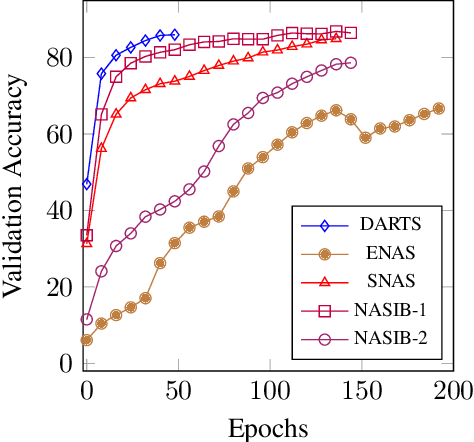
Neural Architecture Search (NAS) represents a class of methods to generate the optimal neural network architecture and typically iterate over candidate architectures till convergence over some particular metric like validation loss. They are constrained by the available computation resources, especially in enterprise environments. In this paper, we propose a new approach for NAS, called NASIB, which adapts and attunes to the computation resources (budget) available by varying the exploration vs. exploitation trade-off. We reduce the expert bias by searching over an augmented search space induced by Superkernels. The proposed method can provide the architecture search useful for different computation resources and different domains beyond image classification of natural images where we lack bespoke architecture motifs and domain expertise. We show, on CIFAR10, that itis possible to search over a space that comprises of 12x more candidate operations than the traditional prior art in just 1.5 GPU days, while reaching close to state of the art accuracy. While our method searches over an exponentially larger search space, it could lead to novel architectures that require lesser domain expertise, compared to the majority of the existing methods.
Maximal adversarial perturbations for obfuscation: Hiding certain attributes while preserving rest
Sep 27, 2019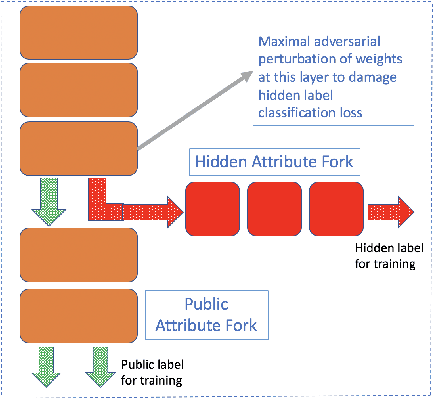
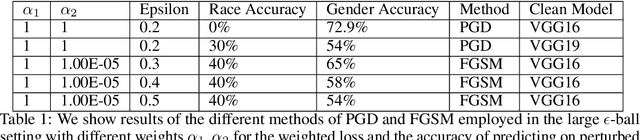
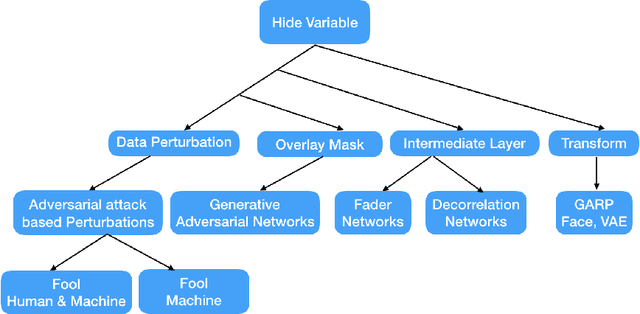

In this paper we investigate the usage of adversarial perturbations for the purpose of privacy from human perception and model (machine) based detection. We employ adversarial perturbations for obfuscating certain variables in raw data while preserving the rest. Current adversarial perturbation methods are used for data poisoning with minimal perturbations of the raw data such that the machine learning model's performance is adversely impacted while the human vision cannot perceive the difference in the poisoned dataset due to minimal nature of perturbations. We instead apply relatively maximal perturbations of raw data to conditionally damage model's classification of one attribute while preserving the model performance over another attribute. In addition, the maximal nature of perturbation helps adversely impact human perception in classifying hidden attribute apart from impacting model performance. We validate our result qualitatively by showing the obfuscated dataset and quantitatively by showing the inability of models trained on clean data to predict the hidden attribute from the perturbed dataset while being able to predict the rest of attributes.