 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Critical Control with Bounded Inputs via Reduced Order Models
Mar 06, 2023Guaranteeing safe behavior on complex autonomous systems -- from cars to walking robots -- is challenging due to the inherently high dimensional nature of these systems and the corresponding complex models that may be difficult to determine in practice. With this as motivation, this paper presents a safety-critical control framework that leverages reduced order models to ensure safety on the full order dynamics -- even when these models are subject to disturbances and bounded inputs (e.g., actuation limits). To handle input constraints, the backup set method is reformulated in the context of reduced order models, and conditions for the provably safe behavior of the full order system are derived. Then, the input-to-state safe backup set method is introduced to provide robustness against discrepancies between the reduced order model and the actual system. Finally, the proposed framework is demonstrated in high-fidelity simulation, where a quadrupedal robot is safely navigated around an obstacle with legged locomotion by the help of the unicycle model.
FRoGGeR: Fast Robust Grasp Generation via the Min-Weight Metric
Feb 27, 2023



Many approaches to grasp synthesis optimize analytic quality metrics that measure grasp robustness based on finger placements and local surface geometry. However, generating feasible dexterous grasps by optimizing these metrics is slow, often taking minutes. To address this issue, this paper presents FRoGGeR: a method that quickly generates robust precision grasps using the min-weight metric, a novel, almost-everywhere differentiable approximation of the classical epsilon grasp metric. The min-weight metric is simple and interpretable, provides a reasonable measure of grasp robustness, and admits numerically efficient gradients for smooth optimization. We leverage these properties to rapidly synthesize collision-free robust grasps - typically in less than a second. FRoGGeR can refine the candidate grasps generated by other methods (heuristic, data-driven, etc.) and is compatible with many object representations (SDFs, meshes, etc.). We study FRoGGeR's performance on over 40 objects drawn from the YCB dataset, outperforming a competitive baseline in computation time, feasibility rate of grasp synthesis, and picking success in simulation. We conclude that FRoGGeR is fast: it has a median synthesis time of 0.834s over hundreds of experiments.
Barrier-Based Test Synthesis for Safety-Critical Systems Subject to Timed Reach-Avoid Specifications
Jan 23, 2023We propose an adversarial, time-varying test-synthesis procedure for safety-critical systems without requiring specific knowledge of the underlying controller steering the system. From a broader test and evaluation context, determination of difficult tests of system behavior is important as these tests would elucidate problematic system phenomena before these mistakes can engender problematic outcomes, e.g. loss of human life in autonomous cars, costly failures for airplane systems, etc. Our approach builds on existing, simulation-based work in the test and evaluation literature by offering a controller-agnostic test-synthesis procedure that provides a series of benchmark tests with which to determine controller reliability. To achieve this, our approach codifies the system objective as a timed reach-avoid specification. Then, by coupling control barrier functions with this class of specifications, we construct an instantaneous difficulty metric whose minimizer corresponds to the most difficult test at that system state. We use this instantaneous difficulty metric in a game-theoretic fashion, to produce an adversarial, time-varying test-synthesis procedure that does not require specific knowledge of the system's controller, but can still provably identify realizable and maximally difficult tests of system behavior. Finally, we develop this test-synthesis procedure for both continuous and discrete-time systems and showcase our test-synthesis procedure on simulated and hardware examples.
Learning Disturbances Online for Risk-Aware Control: Risk-Aware Flight with Less Than One Minute of Data
Dec 12, 2022Recent advances in safety-critical risk-aware control are predicated on apriori knowledge of the disturbances a system might face. This paper proposes a method to efficiently learn these disturbances online, in a risk-aware context. First, we introduce the concept of a Surface-at-Risk, a risk measure for stochastic processes that extends Value-at-Risk -- a commonly utilized risk measure in the risk-aware controls community. Second, we model the norm of the state discrepancy between the model and the true system evolution as a scalar-valued stochastic process and determine an upper bound to its Surface-at-Risk via Gaussian Process Regression. Third, we provide theoretical results on the accuracy of our fitted surface subject to mild assumptions that are verifiable with respect to the data sets collected during system operation. Finally, we experimentally verify our procedure by augmenting a drone's controller and highlight performance increases achieved via our risk-aware approach after collecting less than a minute of operating data.
Synthesizing Reactive Test Environments for Autonomous Systems: Testing Reach-Avoid Specifications with Multi-Commodity Flows
Oct 19, 2022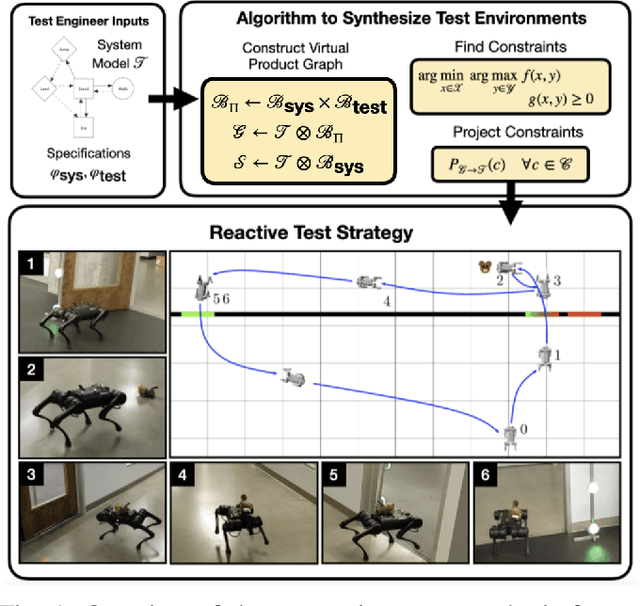
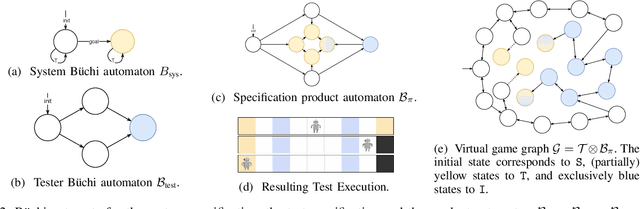
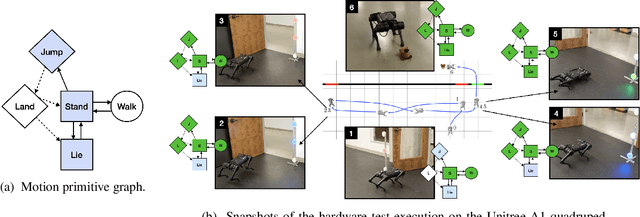
We study automated test generation for verifying discrete decision-making modules in autonomous systems. We utilize linear temporal logic to encode the requirements on the system under test in the system specification and the behavior that we want to observe during the test is given as the test specification which is unknown to the system. First, we use the specifications and their corresponding non-deterministic B\"uchi automata to generate the specification product automaton. Second, a virtual product graph representing the high-level interaction between the system and the test environment is constructed modeling the product automaton encoding the system, the test environment, and specifications. The main result of this paper is an optimization problem, framed as a multi-commodity network flow problem, that solves for constraints on the virtual product graph which can then be projected to the test environment. Therefore, the result of the optimization problem is reactive test synthesis that ensures that the system meets the test specifications along with satisfying the system specifications. This framework is illustrated in simulation on grid world examples, and demonstrated on hardware with the Unitree A1 quadruped, wherein dynamic locomotion behaviors are verified in the context of reactive test environments.
Emulating Human Kinematic Behavior on Lower-Limb Prostheses via Multi-Contact Models and Force-Based Nonlinear Control
Sep 27, 2022
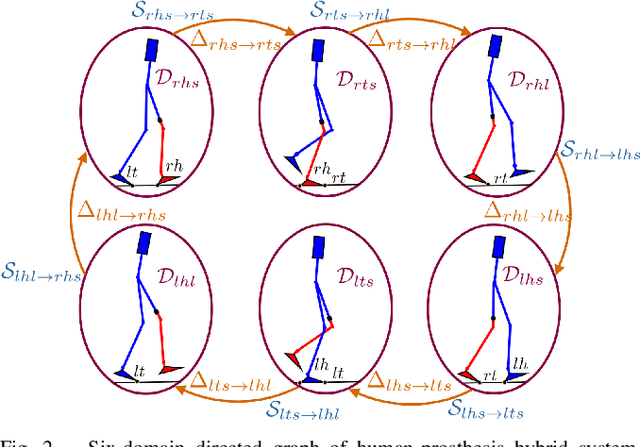
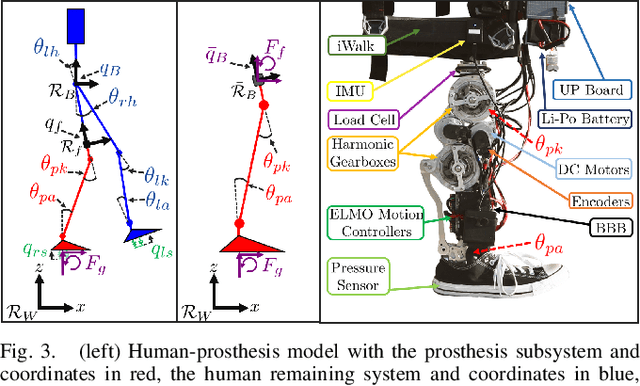
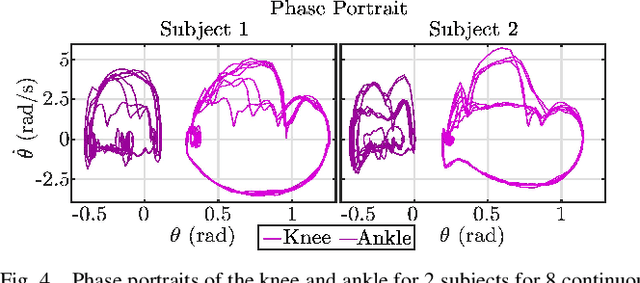
Ankle push-off largely contributes to limb energy generation in human walking, leading to smoother and more efficient locomotion. Providing this net positive work to an amputee requires an active prosthesis, but has the potential to enable more natural assisted locomotion. To this end, this paper uses multi-contact models of locomotion together with force-based nonlinear optimization-based controllers to achieve human-like kinematic behavior, including ankle push-off, on a powered transfemoral prosthesis for 2 subjects. In particular, we leverage model-based control approaches for dynamic bipedal robotic walking to develop a systematic method to realize human-like walking on a powered prosthesis that does not require subject-specific tuning. We begin by synthesizing an optimization problem that yields gaits that resemble human joint trajectories at a kinematic level, and realize these gaits on a prosthesis through a control Lyapunov function based nonlinear controller that responds to real-time ground reaction forces and interaction forces with the human. The proposed controller is implemented on a prosthesis for two subjects without tuning between subjects, emulating subject-specific human kinematic trends on the prosthesis joints. These experimental results demonstrate that our force-based nonlinear control approach achieves better tracking of human kinematic trajectories than traditional methods.
Nonlinear Model Predictive Control of a 3D Hopping Robot: Leveraging Lie Group Integrators for Dynamically Stable Behaviors
Sep 27, 2022
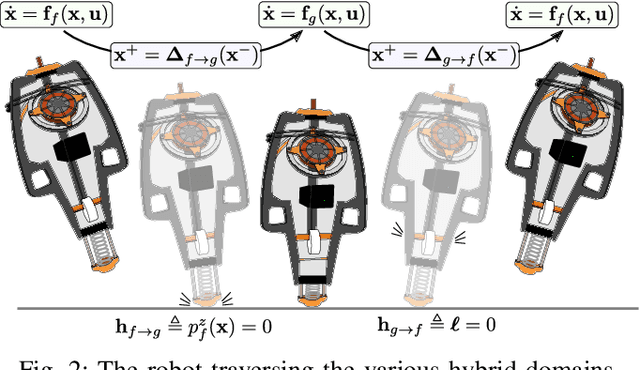
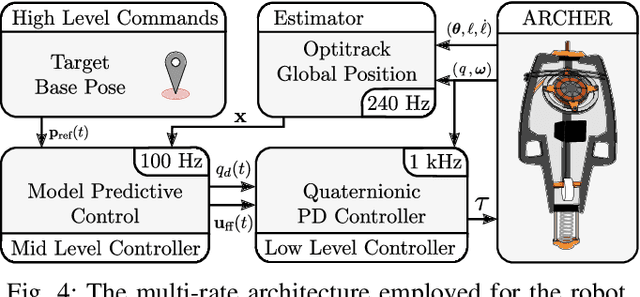
Achieving stable hopping has been a hallmark challenge in the field of dynamic legged locomotion. Controlled hopping is notably difficult due to extended periods of underactuation, combined with very short ground phases wherein ground interactions must be modulated to regulate global state. In this work, we explore the use of hybrid nonlinear model predictive control, paired with a low-level feedback controller in a multi-rate hierarchy, to achieve dynamically stable motions on a novel 3D hopping robot. In order to demonstrate richer behaviors on the manifold of rotations, both the planning and feedback layers must be done in a geometrically consistent fashion; therefore, we develop the necessary tools to employ Lie group integrators and an appropriate feedback controller. We experimentally demonstrate stable 3D hopping on a novel robot, as well as trajectory tracking and flipping in simulation.
Robust Bipedal Locomotion: Leveraging Saltation Matrices for Gait Optimization
Sep 21, 2022

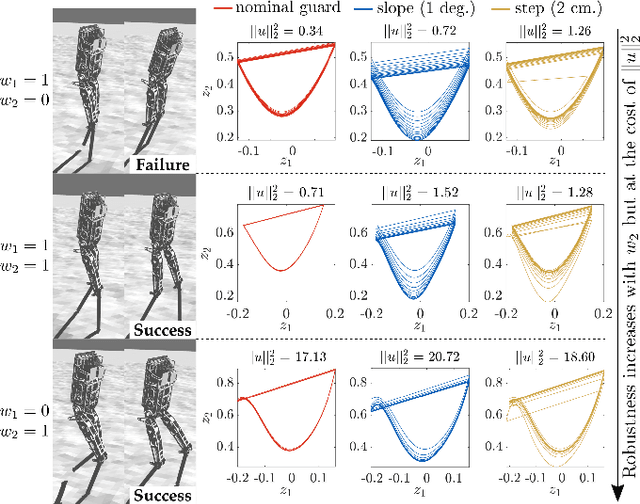

The ability to generate robust walking gaits on bipedal robots is key to their successful realization on hardware. To this end, this work extends the method of Hybrid Zero Dynamics (HZD) -- which traditionally only accounts for locomotive stability via periodicity constraints under perfect impact events -- through the inclusion of the saltation matrix with a view toward synthesizing robust walking gaits. By jointly minimizing the norm of the extended saltation matrix and the torque of the robot directly in the gait generation process, we show that the synthesized gaits are more robust than gaits generated with either term alone; these results are shown in simulation and on hardware for both the AMBER-3M planar biped and the Atalante lower-body exoskeleton (both with and without a human subject). The end result is experimental validation that combining saltation matrices with HZD methods produces more robust bipedal walking in practice.
Data-driven Step-to-step Dynamics based Adaptive Control for Robust and Versatile Underactuated Bipedal Robotic Walking
Sep 18, 2022
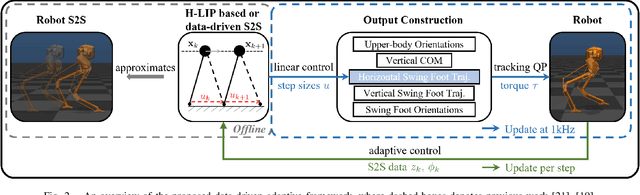
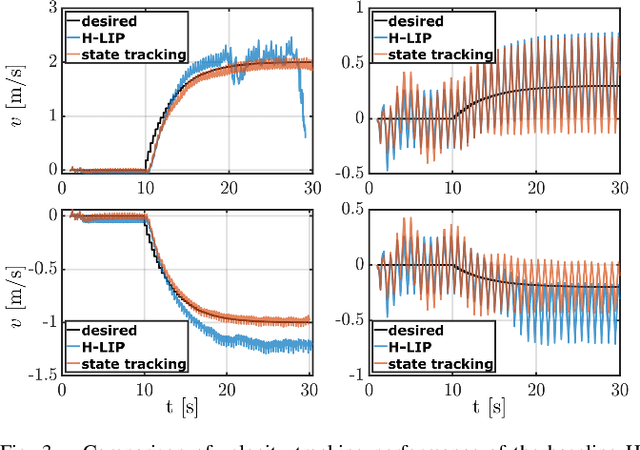
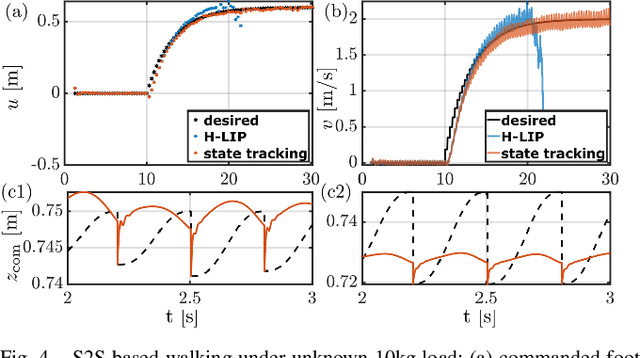
This paper presents a framework for synthesizing bipedal robotic walking that adapts to unknown environment and dynamics error via a data-driven step-to-step (S2S) dynamics model. We begin by synthesizing an S2S controller that stabilizes the walking using foot placement through nominal S2S dynamics from the hybrid linear inverted pendulum (H-LIP) model. Next, a data-driven representation of the S2S dynamics of the robot is learned online via classical adaptive control methods. The desired discrete foot placement on the robot is thereby realized by proper continuous output synthesis capturing the data-driven S2S controller coupled with a low-level tracking controller. The proposed approach is implemented in simulation on an underactuated 3D bipedal robot, Cassie, and improved reference velocity tracking is demonstrated. The proposed approach is also able to realize walking behavior that is robustly adaptive to unknown loads, inaccurate robot models, external disturbance forces, biased velocity estimation, and unknown slopes.
POLAR: Preference Optimization and Learning Algorithms for Robotics
Aug 08, 2022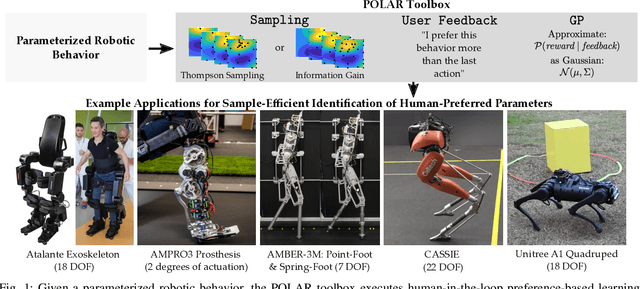
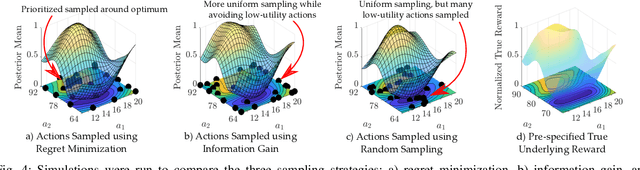
Parameter tuning for robotic systems is a time-consuming and challenging task that often relies on domain expertise of the human operator. Moreover, existing learning methods are not well suited for parameter tuning for many reasons including: the absence of a clear numerical metric for `good robotic behavior'; limited data due to the reliance on real-world experimental data; and the large search space of parameter combinations. In this work, we present an open-source MATLAB Preference Optimization and Learning Algorithms for Robotics toolbox (POLAR) for systematically exploring high-dimensional parameter spaces using human-in-the-loop preference-based learning. This aim of this toolbox is to systematically and efficiently accomplish one of two objectives: 1) to optimize robotic behaviors for human operator preference; 2) to learn the operator's underlying preference landscape to better understand the relationship between adjustable parameters and operator preference. The POLAR toolbox achieves these objectives using only subjective feedback mechanisms (pairwise preferences, coactive feedback, and ordinal labels) to infer a Bayesian posterior over the underlying reward function dictating the user's preferences. We demonstrate the performance of the toolbox in simulation and present various applications of human-in-the-loop preference-based learning.