 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Dense Visual Representations
Nov 11, 2020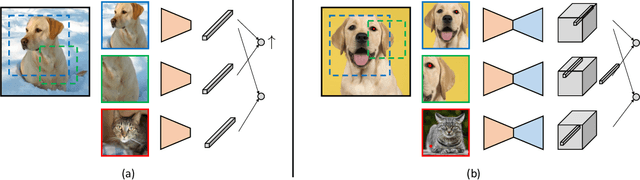


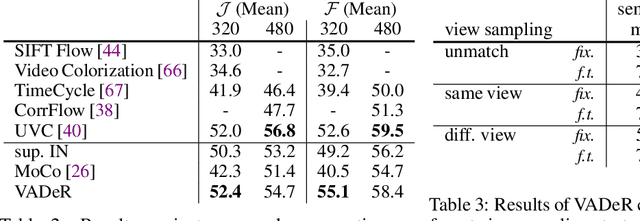
Contrastive self-supervised learning has emerged as a promising approach to unsupervised visual representation learning. In general, these methods learn global (image-level) representations that are invariant to different views (i.e., compositions of data augmentation) of the same image. However, many visual understanding tasks require dense (pixel-level) representations. In this paper, we propose View-Agnostic Dense Representation (VADeR) for unsupervised learning of dense representations. VADeR learns pixelwise representations by forcing local features to remain constant over different viewing conditions. Specifically, this is achieved through pixel-level contrastive learning: matching features (that is, features that describes the same location of the scene on different views) should be close in an embedding space, while non-matching features should be apart. VADeR provides a natural representation for dense prediction tasks and transfers well to downstream tasks. Our method outperforms ImageNet supervised pretraining (and strong unsupervised baselines) in multiple dense prediction tasks.
NU-GAN: High resolution neural upsampling with GAN
Oct 22, 2020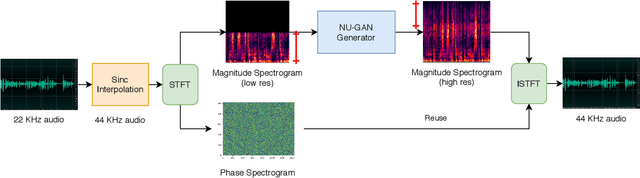
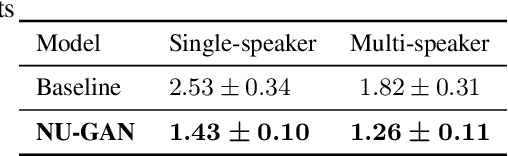
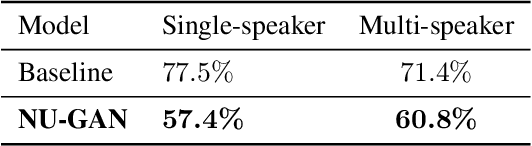
In this paper, we propose NU-GAN, a new method for resampling audio from lower to higher sampling rates (upsampling). Audio upsampling is an important problem since productionizing generative speech technology requires operating at high sampling rates. Such applications use audio at a resolution of 44.1 kHz or 48 kHz, whereas current speech synthesis methods are equipped to handle a maximum of 24 kHz resolution. NU-GAN takes a leap towards solving audio upsampling as a separate component in the text-to-speech (TTS) pipeline by leveraging techniques for audio generation using GANs. ABX preference tests indicate that our NU-GAN resampler is capable of resampling 22 kHz to 44.1 kHz audio that is distinguishable from original audio only 7.4% higher than random chance for single speaker dataset, and 10.8% higher than chance for multi-speaker dataset.
Neural Approximate Sufficient Statistics for Implicit Models
Oct 20, 2020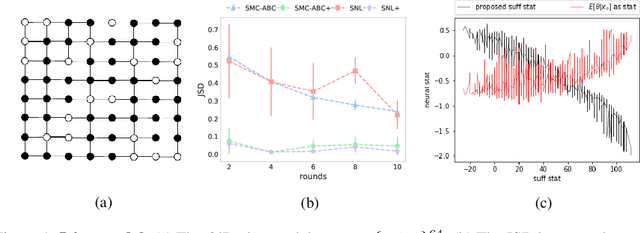

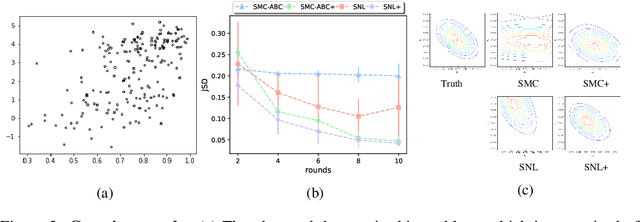

We consider the fundamental problem of how to automatically construct summary statistics for implicit generative models where the evaluation of likelihood function is intractable but sampling / simulating data from the model is possible. The idea is to frame the task of constructing sufficient statistics as learning mutual information maximizing representation of the data. This representation is computed by a deep neural network trained by a joint statistic-posterior learning strategy. We apply our approach to both traditional approximate Bayesian computation (ABC) and recent neural likelihood approaches, boosting their performance on a range of tasks.
Recursive Top-Down Production for Sentence Generation with Latent Trees
Oct 09, 2020
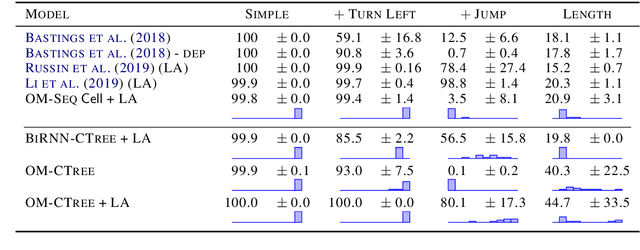

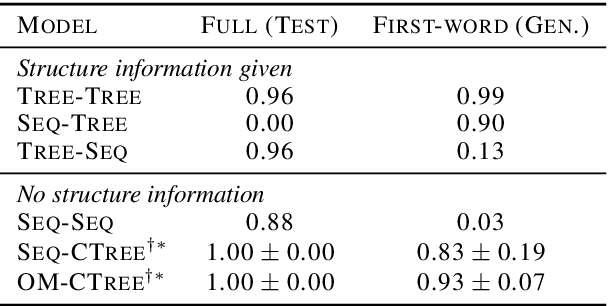
We model the recursive production property of context-free grammars for natural and synthetic languages. To this end, we present a dynamic programming algorithm that marginalises over latent binary tree structures with $N$ leaves, allowing us to compute the likelihood of a sequence of $N$ tokens under a latent tree model, which we maximise to train a recursive neural function. We demonstrate performance on two synthetic tasks: SCAN (Lake and Baroni, 2017), where it outperforms previous models on the LENGTH split, and English question formation (McCoy et al., 2020), where it performs comparably to decoders with the ground-truth tree structure. We also present experimental results on German-English translation on the Multi30k dataset (Elliott et al., 2016), and qualitatively analyse the induced tree structures our model learns for the SCAN tasks and the German-English translation task.
Supervised Seeded Iterated Learning for Interactive Language Learning
Oct 06, 2020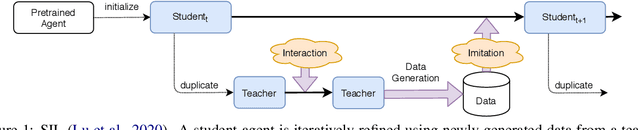
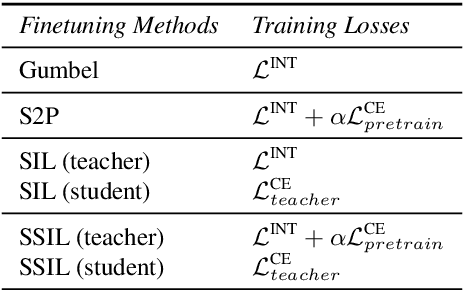
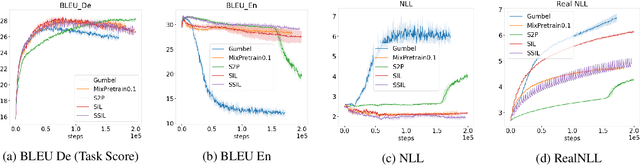
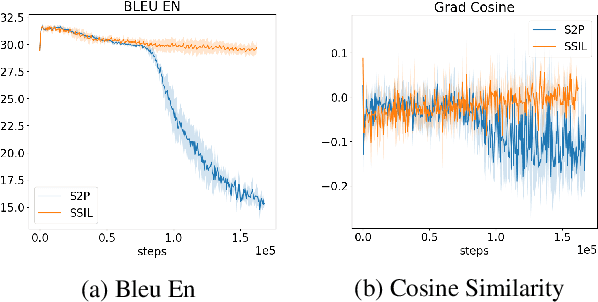
Language drift has been one of the major obstacles to train language models through interaction. When word-based conversational agents are trained towards completing a task, they tend to invent their language rather than leveraging natural language. In recent literature, two general methods partially counter this phenomenon: Supervised Selfplay (S2P) and Seeded Iterated Learning (SIL). While S2P jointly trains interactive and supervised losses to counter the drift, SIL changes the training dynamics to prevent language drift from occurring. In this paper, we first highlight their respective weaknesses, i.e., late-stage training collapses and higher negative likelihood when evaluated on human corpus. Given these observations, we introduce Supervised Seeded Iterated Learning to combine both methods to minimize their respective weaknesses. We then show the effectiveness of \algo in the language-drift translation game.
Integrating Categorical Semantics into Unsupervised Domain Translation
Oct 03, 2020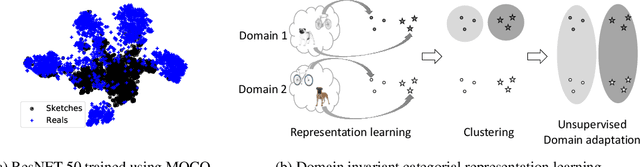

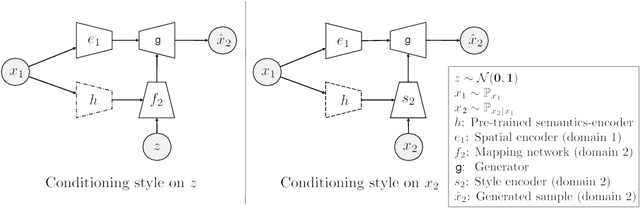
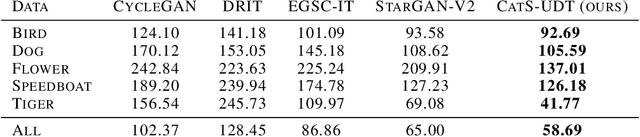
While unsupervised domain translation (UDT) has seen a lot of success recently, we argue that allowing its translation to be mediated via categorical semantic features could enable wider applicability. In particular, we argue that categorical semantics are important when translating between domains with multiple object categories possessing distinctive styles, or even between domains that are simply too different but still share high-level semantics. We propose a method to learn, in an unsupervised manner, categorical semantic features (such as object labels) that are invariant of the source and target domains. We show that conditioning the style of a unsupervised domain translation methods on the learned categorical semantics leads to a considerably better high-level features preservation on tasks such as MNIST$\leftrightarrow$SVHN and to a more realistic stylization on Sketches$\to$Reals.
Data-Efficient Reinforcement Learning with Momentum Predictive Representations
Jul 12, 2020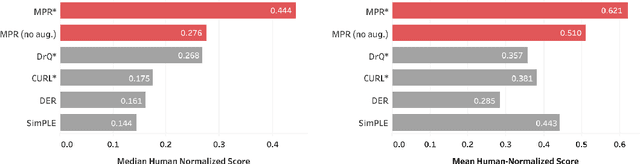
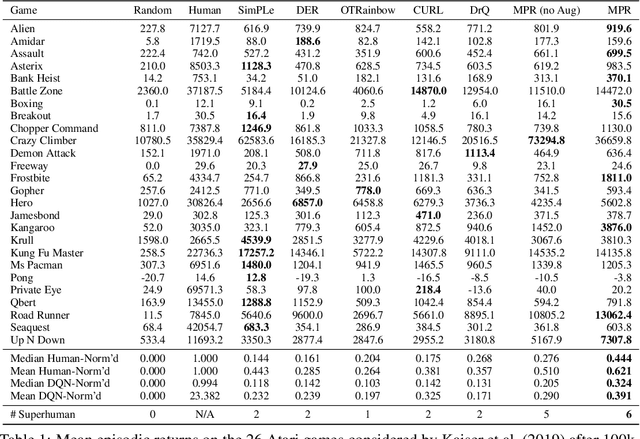
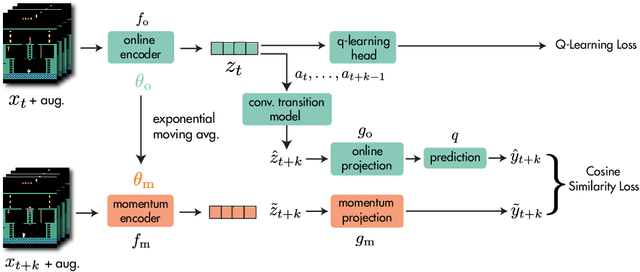

While deep reinforcement learning excels at solving tasks where large amounts of data can be collected through virtually unlimited interaction with the environment, learning from limited interaction remains a key challenge. We posit that an agent can learn more efficiently if we augment reward maximization with self-supervised objectives based on structure in its visual input and sequential interaction with the environment. Our method, Momentum Predictive Representations (MPR), trains an agent to predict its own latent state representations multiple steps into the future. We compute target representations for future states using an encoder which is an exponential moving average of the agent's parameters, and we make predictions using a learned transition model. On its own, this future prediction objective outperforms prior methods for sample-efficient deep RL from pixels. We further improve performance by adding data augmentation to the future prediction loss, which forces the agent's representations to be consistent across multiple views of an observation. Our full self-supervised objective, which combines future prediction and data augmentation, achieves a median human-normalized score of 0.444 on Atari in a setting limited to 100K steps of environment interaction, which is a 66% relative improvement over the previous state-of-the-art. Moreover, even in this limited data regime, MPR exceeds expert human scores on 6 out of 26 games.
Generative Graph Perturbations for Scene Graph Prediction
Jul 11, 2020



Inferring objects and their relationships from an image is useful in many applications at the intersection of vision and language. Due to a long tail data distribution, the task is challenging, with the inevitable appearance of zero-shot compositions of objects and relationships at test time. Current models often fail to properly understand a scene in such cases, as during training they only observe a tiny fraction of the distribution corresponding to the most frequent compositions. This motivates us to study whether increasing the diversity of the training distribution, by generating replacement for parts of real scene graphs, can lead to better generalization? We employ generative adversarial networks (GANs) conditioned on scene graphs to generate augmented visual features. To increase their diversity, we propose several strategies to perturb the conditioning. One of them is to use a language model, such as BERT, to synthesize plausible yet still unlikely scene graphs. By evaluating our model on Visual Genome, we obtain both positive and negative results. This prompts us to make several observations that can potentially lead to further improvements.
AR-DAE: Towards Unbiased Neural Entropy Gradient Estimation
Jun 09, 2020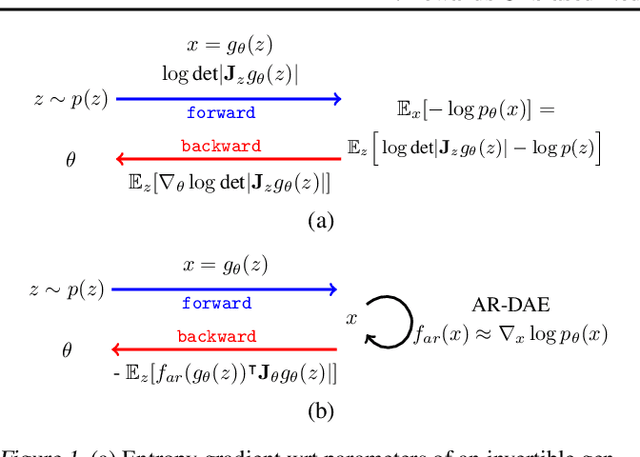
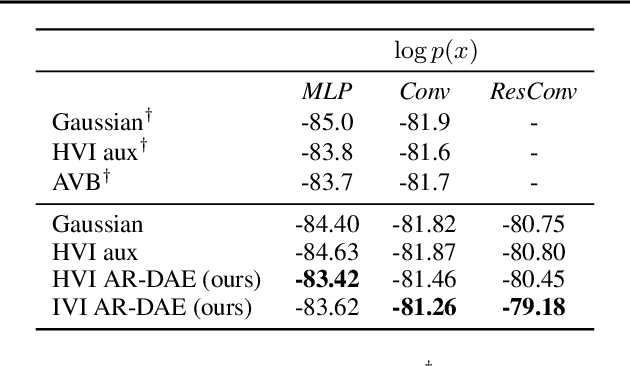
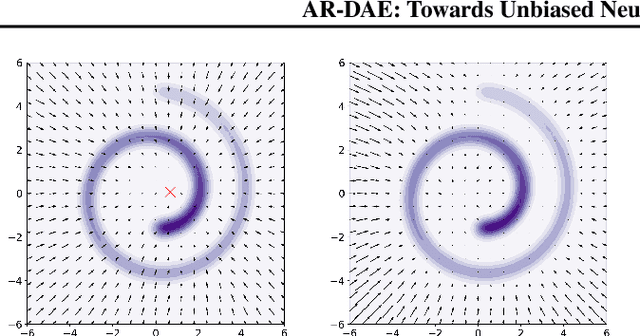

Entropy is ubiquitous in machine learning, but it is in general intractable to compute the entropy of the distribution of an arbitrary continuous random variable. In this paper, we propose the amortized residual denoising autoencoder (AR-DAE) to approximate the gradient of the log density function, which can be used to estimate the gradient of entropy. Amortization allows us to significantly reduce the error of the gradient approximator by approaching asymptotic optimality of a regular DAE, in which case the estimation is in theory unbiased. We conduct theoretical and experimental analyses on the approximation error of the proposed method, as well as extensive studies on heuristics to ensure its robustness. Finally, using the proposed gradient approximator to estimate the gradient of entropy, we demonstrate state-of-the-art performance on density estimation with variational autoencoders and continuous control with soft actor-critic.
Graph Density-Aware Losses for Novel Compositions in Scene Graph Generation
May 17, 2020
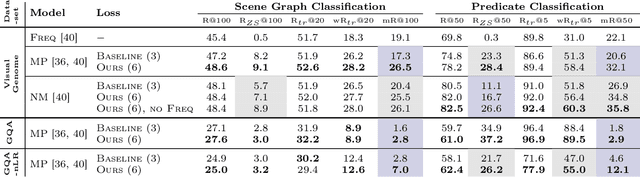
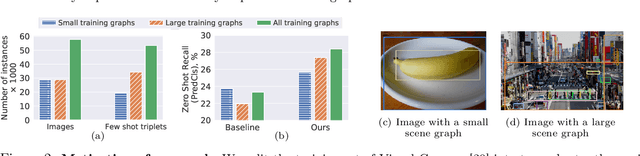
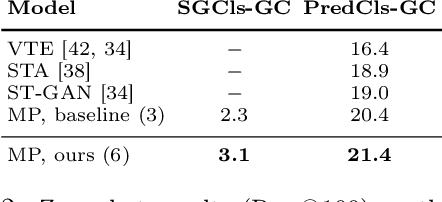
Scene graph generation (SGG) aims to predict graph-structured descriptions of input images, in the form of objects and relationships between them. This task is becoming increasingly useful for progress at the interface of vision and language. Here, it is important - yet challenging - to perform well on novel (zero-shot) or rare (few-shot) compositions of objects and relationships. In this paper, we identify two key issues that limit such generalization. Firstly, we show that the standard loss used in this task is unintentionally a function of scene graph density. This leads to the neglect of individual edges in large sparse graphs during training, even though these contain diverse few-shot examples that are important for generalization. Secondly, the frequency of relationships can create a strong bias in this task, such that a blind model predicting the most frequent relationship achieves good performance. Consequently, some state-of-the-art models exploit this bias to improve results. We show that such models can suffer the most in their ability to generalize to rare compositions, evaluating two different models on the Visual Genome dataset and its more recent, improved version, GQA. To address these issues, we introduce a density-normalized edge loss, which provides more than a two-fold improvement in certain generalization metrics. Compared to other works in this direction, our enhancements require only a few lines of code and no added computational cost. We also highlight the difficulty of accurately evaluating models using existing metrics, especially on zero/few shots, and introduce a novel weighted metric.