 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-MelNet: Reduced Mel-Spectral Modeling for Neural TTS
Jun 30, 2022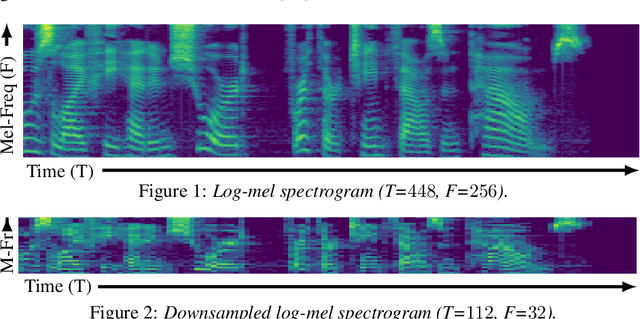
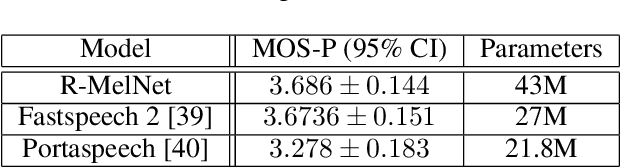
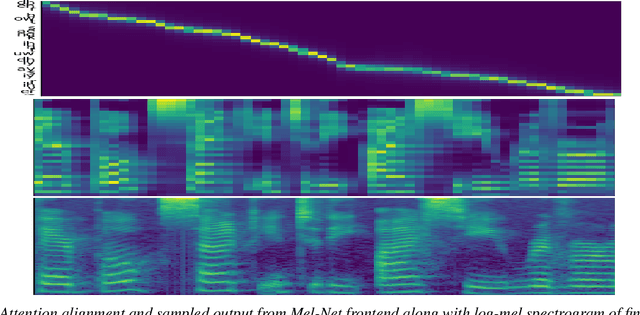

This paper introduces R-MelNet, a two-part autoregressive architecture with a frontend based on the first tier of MelNet and a backend WaveRNN-style audio decoder for neural text-to-speech synthesis. Taking as input a mixed sequence of characters and phonemes, with an optional audio priming sequence, this model produces low-resolution mel-spectral features which are interpolated and used by a WaveRNN decoder to produce an audio waveform. Coupled with half precision training, R-MelNet uses under 11 gigabytes of GPU memory on a single commodity GPU (NVIDIA 2080Ti). We detail a number of critical implementation details for stable half precision training, including an approximate, numerically stable mixture of logistics attention. Using a stochastic, multi-sample per step inference scheme, the resulting model generates highly varied audio, while enabling text and audio based controls to modify output waveforms. Qualitative and quantitative evaluations of an R-MelNet system trained on a single speaker TTS dataset demonstrate the effectiveness of our approach.
Building Robust Ensembles via Margin Boosting
Jun 07, 2022
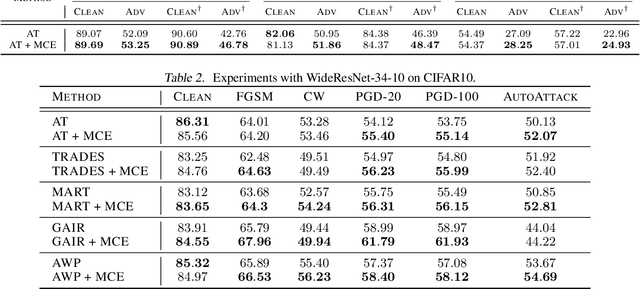

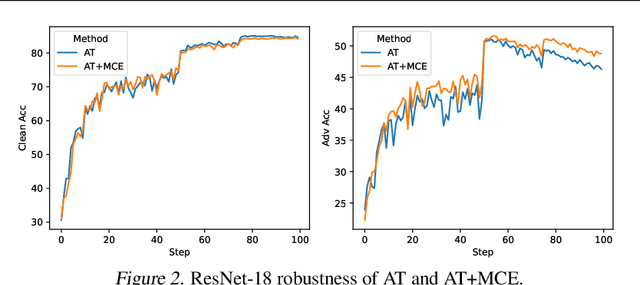
In the context of adversarial robustness, a single model does not usually have enough power to defend against all possible adversarial attacks, and as a result, has sub-optimal robustness. Consequently, an emerging line of work has focused on learning an ensemble of neural networks to defend against adversarial attacks. In this work, we take a principled approach towards building robust ensembles. We view this problem from the perspective of margin-boosting and develop an algorithm for learning an ensemble with maximum margin. Through extensive empirical evaluation on benchmark datasets, we show that our algorithm not only outperforms existing ensembling techniques, but also large models trained in an end-to-end fashion. An important byproduct of our work is a margin-maximizing cross-entropy (MCE) loss, which is a better alternative to the standard cross-entropy (CE) loss. Empirically, we show that replacing the CE loss in state-of-the-art adversarial training techniques with our MCE loss leads to significant performance improvement.
Beyond Tabula Rasa: Reincarnating Reinforcement Learning
Jun 03, 2022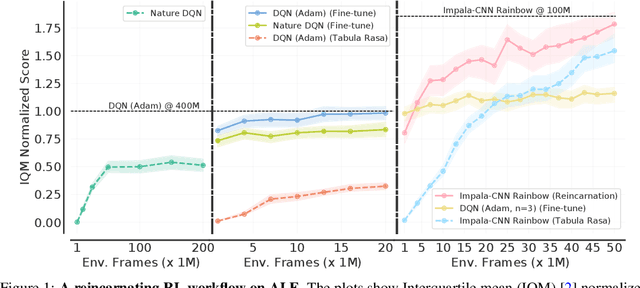
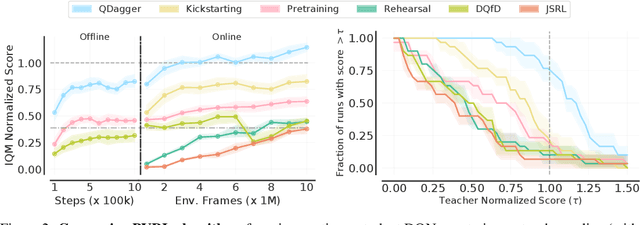
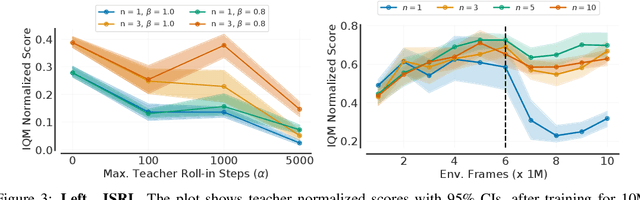
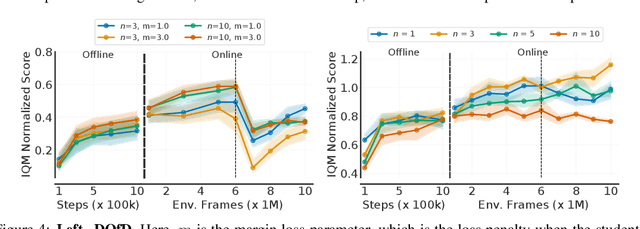
Learning tabula rasa, that is without any prior knowledge, is the prevalent workflow in reinforcement learning (RL) research. However, RL systems, when applied to large-scale settings, rarely operate tabula rasa. Such large-scale systems undergo multiple design or algorithmic changes during their development cycle and use ad hoc approaches for incorporating these changes without re-training from scratch, which would have been prohibitively expensive. Additionally, the inefficiency of deep RL typically excludes researchers without access to industrial-scale resources from tackling computationally-demanding problems. To address these issues, we present reincarnating RL as an alternative workflow, where prior computational work (e.g., learned policies) is reused or transferred between design iterations of an RL agent, or from one RL agent to another. As a step towards enabling reincarnating RL from any agent to any other agent, we focus on the specific setting of efficiently transferring an existing sub-optimal policy to a standalone value-based RL agent. We find that existing approaches fail in this setting and propose a simple algorithm to address their limitations. Equipped with this algorithm, we demonstrate reincarnating RL's gains over tabula rasa RL on Atari 2600 games, a challenging locomotion task, and the real-world problem of navigating stratospheric balloons. Overall, this work argues for an alternative approach to RL research, which we believe could significantly improve real-world RL adoption and help democratize it further.
Expressiveness and Learnability: A Unifying View for Evaluating Self-Supervised Learning
Jun 02, 2022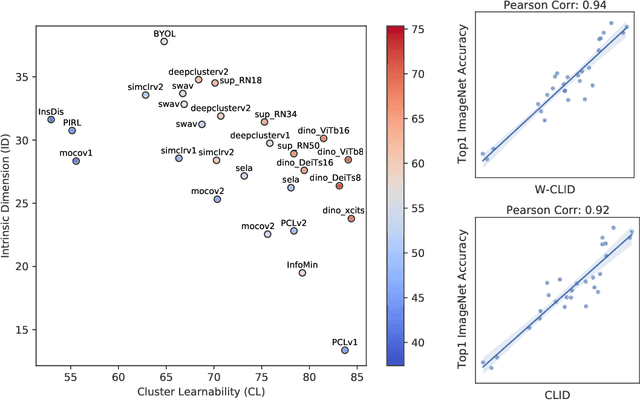
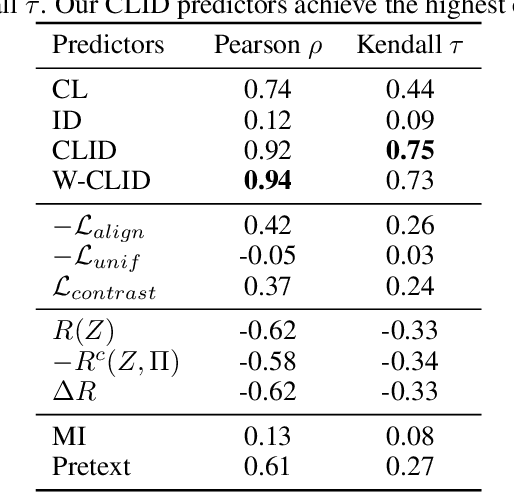
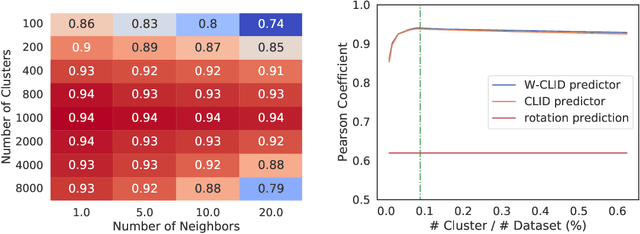
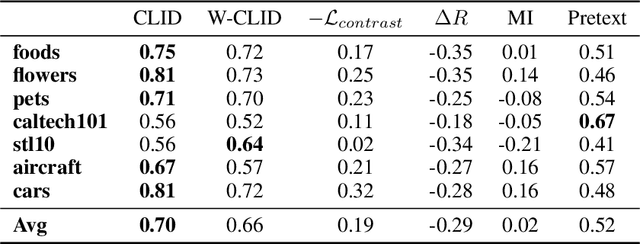
We propose a unifying view to analyze the representation quality of self-supervised learning (SSL) models without access to supervised labels, while being agnostic to the architecture, learning algorithm or data manipulation used during training. We argue that representations can be evaluated through the lens of expressiveness and learnability. We propose to use the Intrinsic Dimension (ID) to assess expressiveness and introduce Cluster Learnability (CL) to assess learnability. CL is measured as the learning speed of a KNN classifier trained to predict labels obtained by clustering the representations with K-means. We thus combine CL and ID into a single predictor: CLID. Through a large-scale empirical study with a diverse family of SSL algorithms, we find that CLID better correlates with in-distribution model performance than other competing recent evaluation schemes. We also benchmark CLID on out-of-domain generalization, where CLID serves as a predictor of the transfer performance of SSL models on several classification tasks, yielding improvements with respect to the competing baselines.
Cascaded Video Generation for Videos In-the-Wild
Jun 01, 2022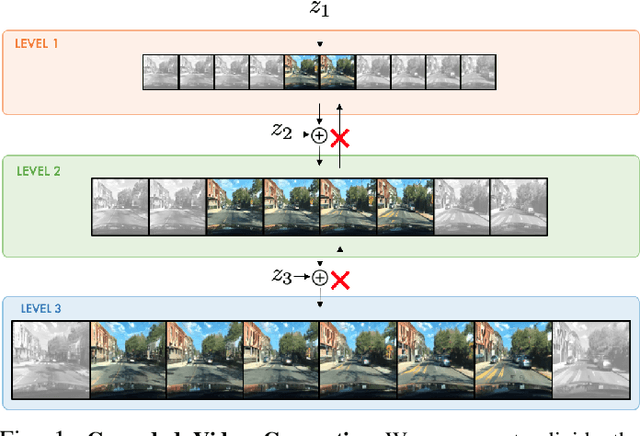

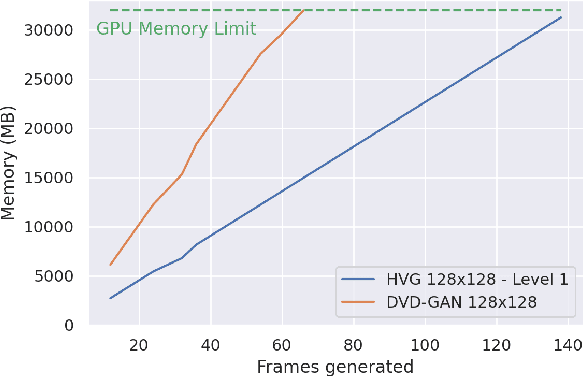

Videos can be created by first outlining a global view of the scene and then adding local details. Inspired by this idea we propose a cascaded model for video generation which follows a coarse to fine approach. First our model generates a low resolution video, establishing the global scene structure, which is then refined by subsequent cascade levels operating at larger resolutions. We train each cascade level sequentially on partial views of the videos, which reduces the computational complexity of our model and makes it scalable to high-resolution videos with many frames. We empirically validate our approach on UCF101 and Kinetics-600, for which our model is competitive with the state-of-the-art. We further demonstrate the scaling capabilities of our model and train a three-level model on the BDD100K dataset which generates 256x256 pixels videos with 48 frames.
The Primacy Bias in Deep Reinforcement Learning
May 16, 2022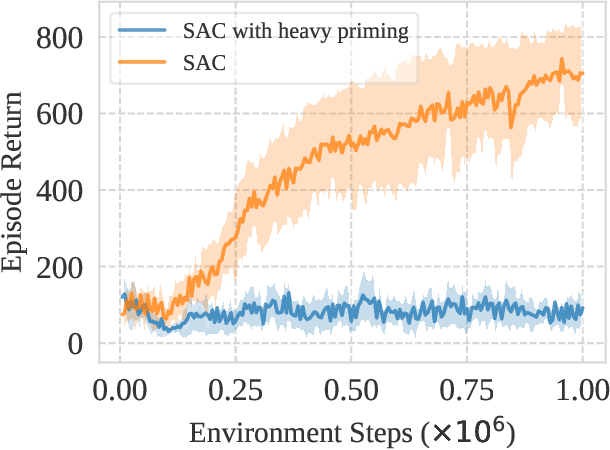
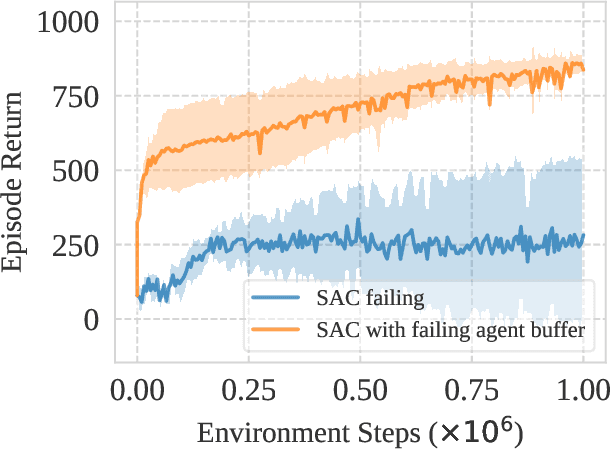
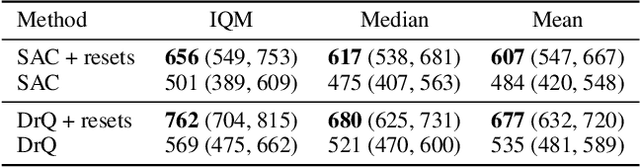

This work identifies a common flaw of deep reinforcement learning (RL) algorithms: a tendency to rely on early interactions and ignore useful evidence encountered later. Because of training on progressively growing datasets, deep RL agents incur a risk of overfitting to earlier experiences, negatively affecting the rest of the learning process. Inspired by cognitive science, we refer to this effect as the primacy bias. Through a series of experiments, we dissect the algorithmic aspects of deep RL that exacerbate this bias. We then propose a simple yet generally-applicable mechanism that tackles the primacy bias by periodically resetting a part of the agent. We apply this mechanism to algorithms in both discrete (Atari 100k) and continuous action (DeepMind Control Suite) domains, consistently improving their performance.
Simplicial Embeddings in Self-Supervised Learning and Downstream Classification
Apr 01, 2022



We introduce Simplicial Embeddings (SEMs) as a way to constrain the encoded representations of a self-supervised model to $L$ simplices of $V$ dimensions each using a Softmax operation. This procedure imposes a structure on the representations that reduce their expressivity for training downstream classifiers, which helps them generalize better. Specifically, we show that the temperature $\tau$ of the Softmax operation controls for the SEM representation's expressivity, allowing us to derive a tighter downstream classifier generalization bound than that for classifiers using unnormalized representations. We empirically demonstrate that SEMs considerably improve generalization on natural image datasets such as CIFAR-100 and ImageNet. Finally, we also present evidence of the emergence of semantically relevant features in SEMs, a pattern that is absent from baseline self-supervised models.
Generative Flow Networks for Discrete Probabilistic Modeling
Feb 03, 2022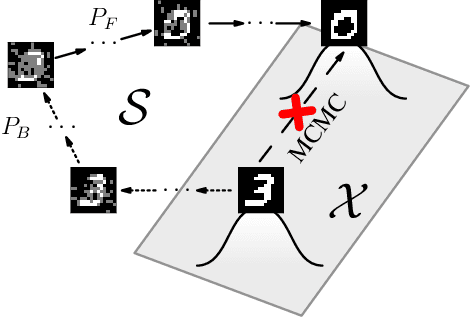
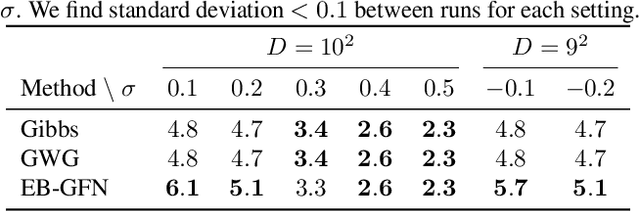
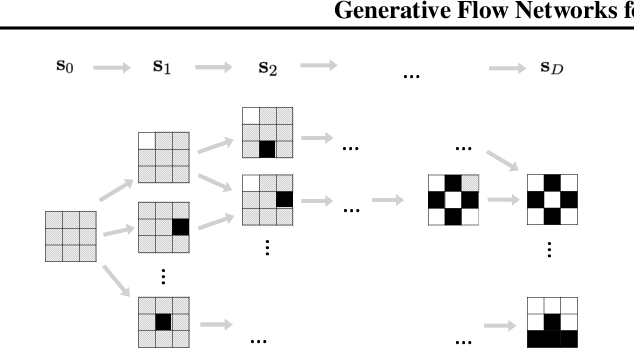
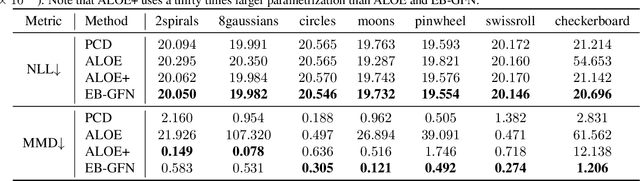
We present energy-based generative flow networks (EB-GFN), a novel probabilistic modeling algorithm for high-dimensional discrete data. Building upon the theory of generative flow networks (GFlowNets), we model the generation process by a stochastic data construction policy and thus amortize expensive MCMC exploration into a fixed number of actions sampled from a GFlowNet. We show how GFlowNets can approximately perform large-block Gibbs sampling to mix between modes. We propose a framework to jointly train a GFlowNet with an energy function, so that the GFlowNet learns to sample from the energy distribution, while the energy learns with an approximate MLE objective with negative samples from the GFlowNet. We demonstrate EB-GFN's effectiveness on various probabilistic modeling tasks.
Fortuitous Forgetting in Connectionist Networks
Feb 01, 2022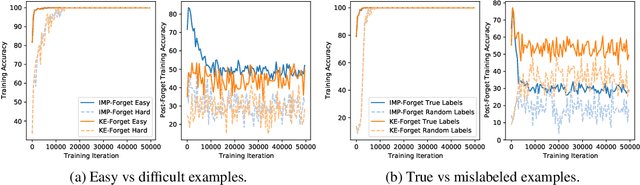
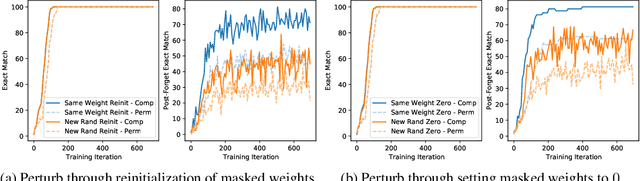
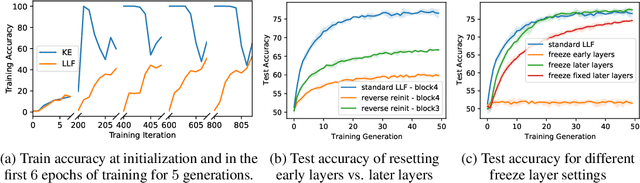
Forgetting is often seen as an unwanted characteristic in both human and machine learning. However, we propose that forgetting can in fact be favorable to learning. We introduce "forget-and-relearn" as a powerful paradigm for shaping the learning trajectories of artificial neural networks. In this process, the forgetting step selectively removes undesirable information from the model, and the relearning step reinforces features that are consistently useful under different conditions. The forget-and-relearn framework unifies many existing iterative training algorithms in the image classification and language emergence literature, and allows us to understand the success of these algorithms in terms of the disproportionate forgetting of undesirable information. We leverage this understanding to improve upon existing algorithms by designing more targeted forgetting operations. Insights from our analysis provide a coherent view on the dynamics of iterative training in neural networks and offer a clear path towards performance improvements.
* ICLR Camera Ready
Invariant Representation Driven Neural Classifier for Anti-QCD Jet Tagging
Jan 18, 2022
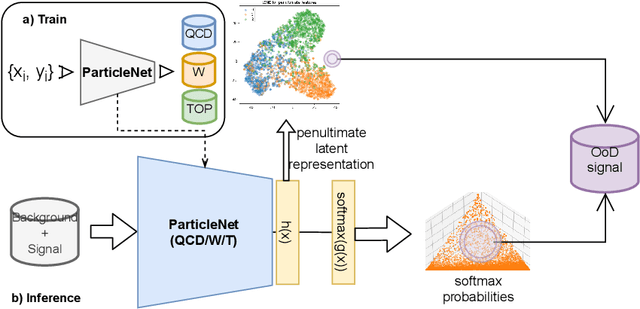
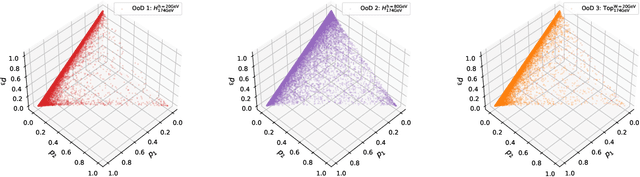
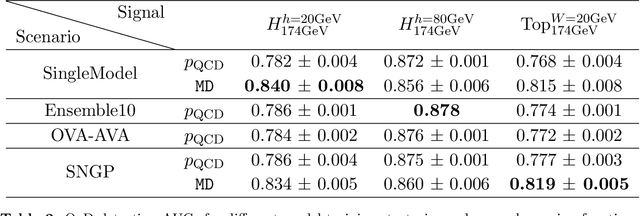
We leverage representation learning and the inductive bias in neural-net-based Standard Model jet classification tasks, to detect non-QCD signal jets. In establishing the framework for classification-based anomaly detection in jet physics, we demonstrate that with a \emph{well-calibrated} and \emph{powerful enough feature extractor}, a well-trained \emph{mass-decorrelated} supervised neural jet tagger can serve as a strong generic anti-QCD jet tagger for effectively reducing the QCD background. Imposing \emph{data-augmented} mass-invariance (decoupling the dominant factor) not only facilitates background estimation, but also induces more substructure-aware representation learning. We are able to reach excellent tagging efficiencies for all the test signals considered. In the best case, we reach a background rejection rate around 50 and a significance improvement factor of 3.6 at 50 \% signal acceptance, with jet mass decorrelated. This study indicates that supervised Standard Model jet classifiers have great potential in general new physics searches.