 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Correction of Writing Anomalies in Hausa Texts
Jun 04, 2025Hausa texts are often characterized by writing anomalies such as incorrect character substitutions and spacing errors, which sometimes hinder natural language processing (NLP) applications. This paper presents an approach to automatically correct the anomalies by finetuning transformer-based models. Using a corpus gathered from several public sources, we created a large-scale parallel dataset of over 450,000 noisy-clean Hausa sentence pairs by introducing synthetically generated noise, fine-tuned to mimic realistic writing errors. Moreover, we adapted several multilingual and African language-focused models, including M2M100, AfriTEVA, mBART, and Opus-MT variants for this correction task using SentencePiece tokenization. Our experimental results demonstrate significant increases in F1, BLEU and METEOR scores, as well as reductions in Character Error Rate (CER) and Word Error Rate (WER). This research provides a robust methodology, a publicly available dataset, and effective models to improve Hausa text quality, thereby advancing NLP capabilities for the language and offering transferable insights for other low-resource languages.
A Typology of Synthetic Datasets for Dialogue Processing in Clinical Contexts
May 05, 2025Synthetic data sets are used across linguistic domains and NLP tasks, particularly in scenarios where authentic data is limited (or even non-existent). One such domain is that of clinical (healthcare) contexts, where there exist significant and long-standing challenges (e.g., privacy, anonymization, and data governance) which have led to the development of an increasing number of synthetic datasets. One increasingly important category of clinical dataset is that of clinical dialogues which are especially sensitive and difficult to collect, and as such are commonly synthesized. While such synthetic datasets have been shown to be sufficient in some situations, little theory exists to inform how they may be best used and generalized to new applications. In this paper, we provide an overview of how synthetic datasets are created, evaluated and being used for dialogue related tasks in the medical domain. Additionally, we propose a novel typology for use in classifying types and degrees of data synthesis, to facilitate comparison and evaluation.
Dialectal and Low Resource Machine Translation for Aromanian
Oct 23, 2024We present a neural machine translation system that can translate between Romanian, English, and Aromanian (an endangered Eastern Romance language); the first of its kind. BLEU scores range from 17 to 32 depending on the direction and genre of the text. Alongside, we release the biggest known Aromanian-Romanian bilingual corpus, consisting of 79k cleaned sentence pairs. Additional tools such as an agnostic sentence embedder (used for both text mining and automatic evaluation) and a diacritics converter are also presented. We publicly release our findings and models. Finally, we describe the deployment of our quantized model at https://arotranslate.com.
Cheap Ways of Extracting Clinical Markers from Texts
Mar 17, 2024



This paper describes the work of the UniBuc Archaeology team for CLPsych's 2024 Shared Task, which involved finding evidence within the text supporting the assigned suicide risk level. Two types of evidence were required: highlights (extracting relevant spans within the text) and summaries (aggregating evidence into a synthesis). Our work focuses on evaluating Large Language Models (LLM) as opposed to an alternative method that is much more memory and resource efficient. The first approach employs a good old-fashioned machine learning (GOML) pipeline consisting of a tf-idf vectorizer with a logistic regression classifier, whose representative features are used to extract relevant highlights. The second, more resource intensive, uses an LLM for generating the summaries and is guided by chain-of-thought to provide sequences of text indicating clinical markers.
A Visual Representation of Wittgenstein's Tractatus Logico-Philosophicus
Mar 13, 2017
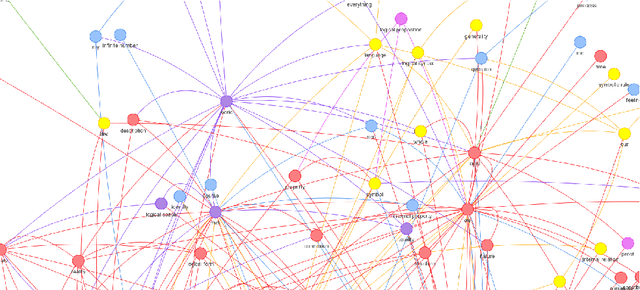
In this paper we present a data visualization method together with its potential usefulness in digital humanities and philosophy of language. We compile a multilingual parallel corpus from different versions of Wittgenstein's Tractatus Logico-Philosophicus, including the original in German and translations into English, Spanish, French, and Russian. Using this corpus, we compute a similarity measure between propositions and render a visual network of relations for different languages.
On the Similarities Between Native, Non-native and Translated Texts
Sep 11, 2016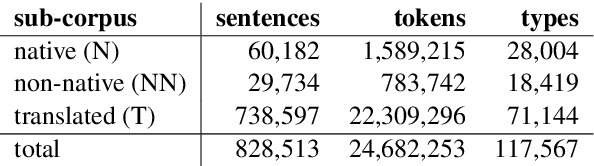
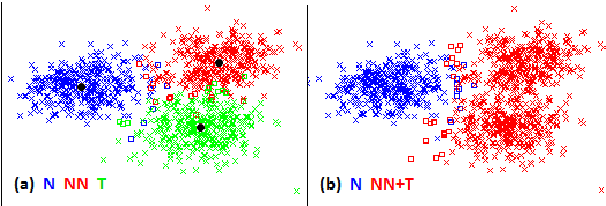
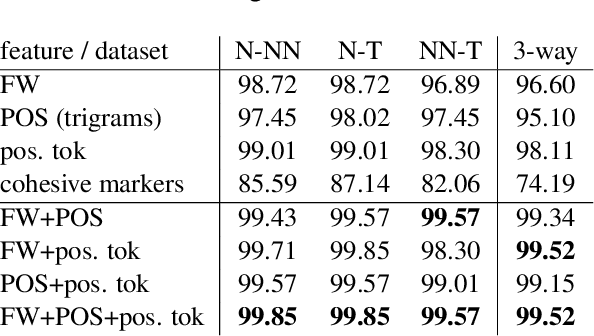
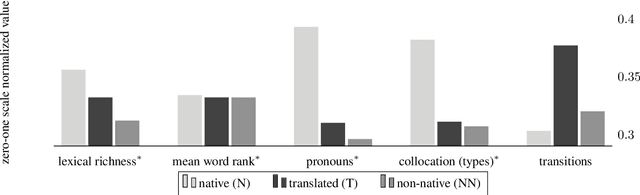
We present a computational analysis of three language varieties: native, advanced non-native, and translation. Our goal is to investigate the similarities and differences between non-native language productions and translations, contrasting both with native language. Using a collection of computational methods we establish three main results: (1) the three types of texts are easily distinguishable; (2) non-native language and translations are closer to each other than each of them is to native language; and (3) some of these characteristics depend on the source or native language, while others do not, reflecting, perhaps, unified principles that similarly affect translations and non-native language.