 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Efficient neural speech synthesis for low-resource languages through multilingual modeling
Aug 20, 2020
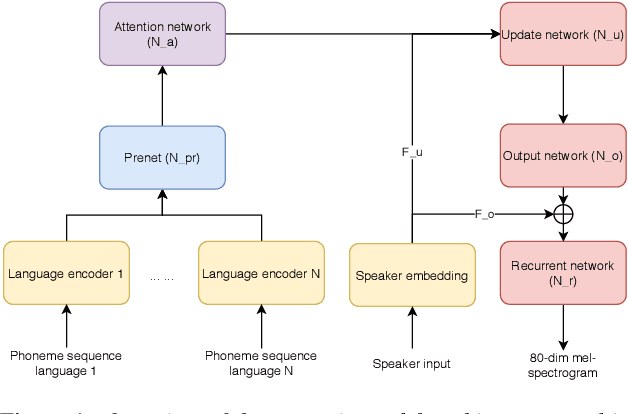
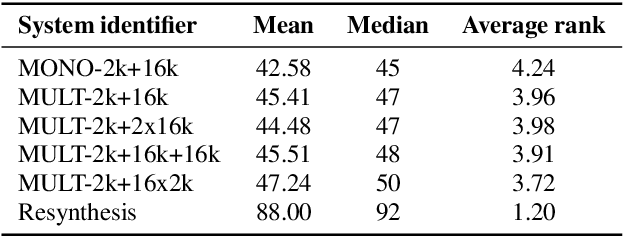

Recent advances in neural TTS have led to models that can produce high-quality synthetic speech. However, these models typically require large amounts of training data, which can make it costly to produce a new voice with the desired quality. Although multi-speaker modeling can reduce the data requirements necessary for a new voice, this approach is usually not viable for many low-resource languages for which abundant multi-speaker data is not available. In this paper, we therefore investigated to what extent multilingual multi-speaker modeling can be an alternative to monolingual multi-speaker modeling, and explored how data from foreign languages may best be combined with low-resource language data. We found that multilingual modeling can increase the naturalness of low-resource language speech, showed that multilingual models can produce speech with a naturalness comparable to monolingual multi-speaker models, and saw that the target language naturalness was affected by the strategy used to add foreign language data.
A Practical Guide to Logical Access Voice Presentation Attack Detection
Jan 10, 2022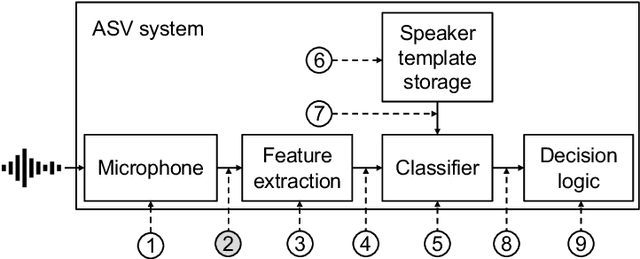

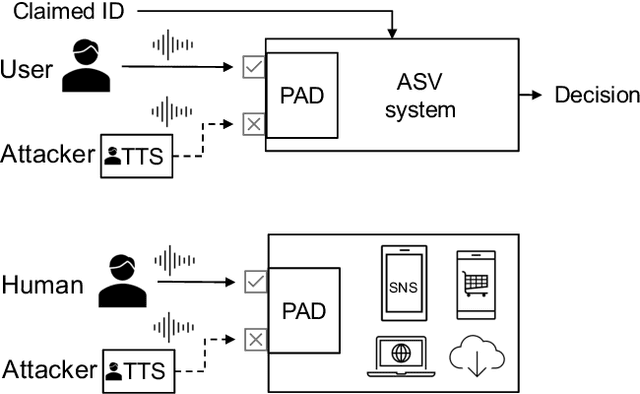
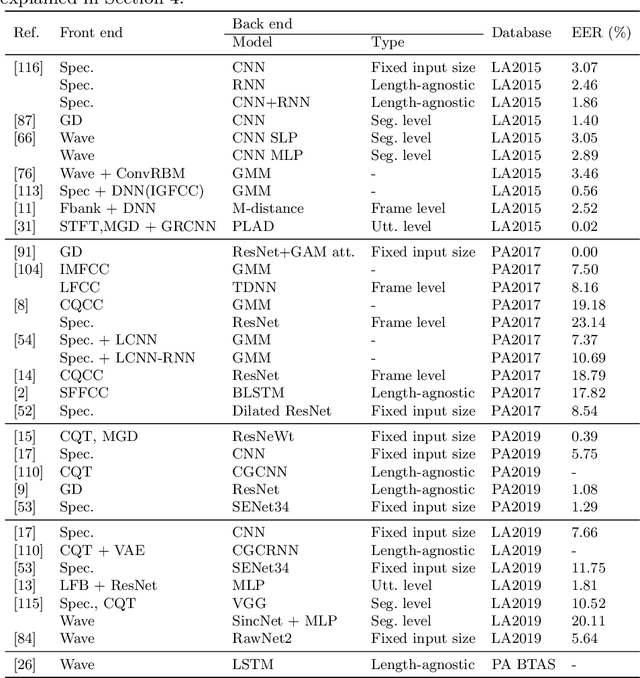
Voice-based human-machine interfaces with an automatic speaker verification (ASV) component are commonly used in the market. However, the threat from presentation attacks is also growing since attackers can use recent speech synthesis technology to produce a natural-sounding voice of a victim. Presentation attack detection (PAD) for ASV, or speech anti-spoofing, is therefore indispensable. Research on voice PAD has seen significant progress since the early 2010s, including the advancement in PAD models, benchmark datasets, and evaluation campaigns. This chapter presents a practical guide to the field of voice PAD, with a focus on logical access attacks using text-to-speech and voice conversion algorithms and spoofing countermeasures based on artifact detection. It introduces the basic concept of voice PAD, explains the common techniques, and provides an experimental study using recent methods on a benchmark dataset. Code for the experiments is open-sourced.
Latent linguistic embedding for cross-lingual text-to-speech and voice conversion
Oct 08, 2020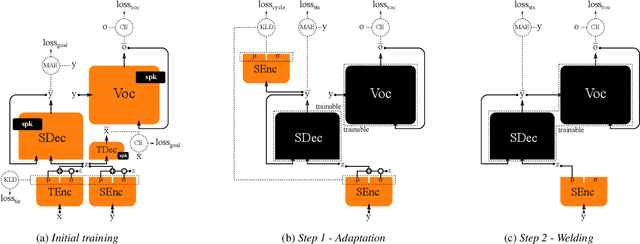
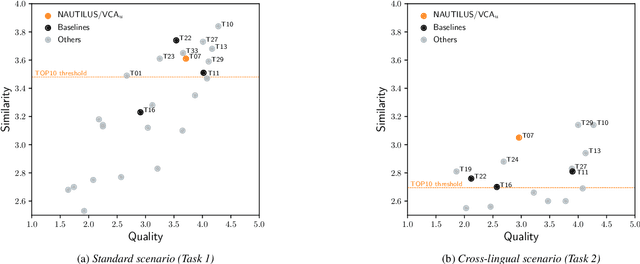
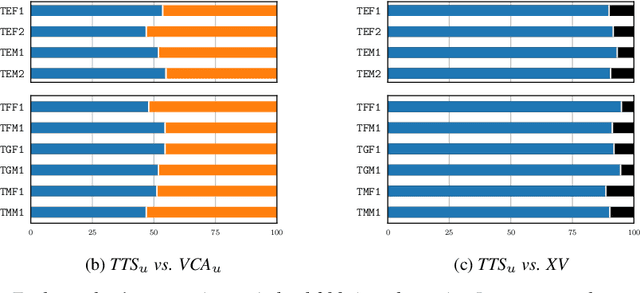
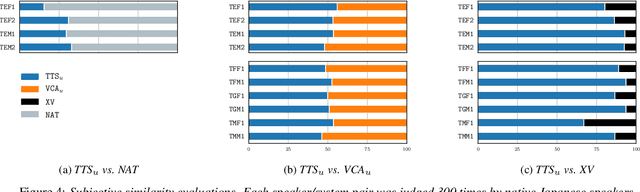
As the recently proposed voice cloning system, NAUTILUS, is capable of cloning unseen voices using untranscribed speech, we investigate the feasibility of using it to develop a unified cross-lingual TTS/VC system. Cross-lingual speech generation is the scenario in which speech utterances are generated with the voices of target speakers in a language not spoken by them originally. This type of system is not simply cloning the voice of the target speaker, but essentially creating a new voice that can be considered better than the original under a specific framing. By using a well-trained English latent linguistic embedding to create a cross-lingual TTS and VC system for several German, Finnish, and Mandarin speakers included in the Voice Conversion Challenge 2020, we show that our method not only creates cross-lingual VC with high speaker similarity but also can be seamlessly used for cross-lingual TTS without having to perform any extra steps. However, the subjective evaluations of perceived naturalness seemed to vary between target speakers, which is one aspect for future improvement.
Key-Sparse Transformer with Cascaded Cross-Attention Block for Multimodal Speech Emotion Recognition
Jun 22, 2021
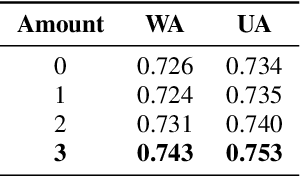
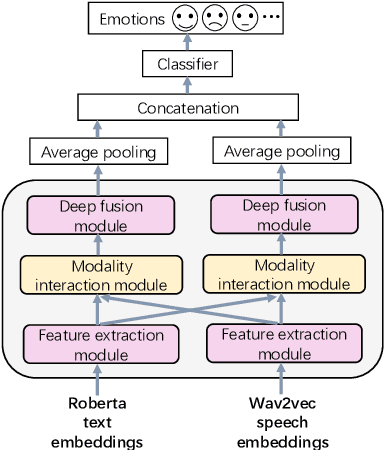
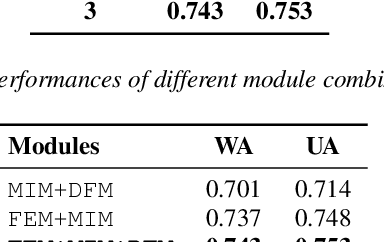
Speech emotion recognition is a challenging and important research topic that plays a critical role in human-computer interaction. Multimodal inputs can improve the performance as more emotional information is used for recognition. However, existing studies learnt all the information in the sample while only a small portion of it is about emotion. Moreover, under the multimodal framework, the interaction between different modalities is shallow and insufficient. In this paper, a keysparse Transformer is proposed for efficient SER by only focusing on emotion related information. Furthermore, a cascaded cross-attention block, which is specially designed for multimodal framework, is introduced to achieve deep interaction between different modalities. The proposed method is evaluated by IEMOCAP corpus and the experimental results show that the proposed method gives better performance than the state-of-theart approaches.
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
Jun 20, 2020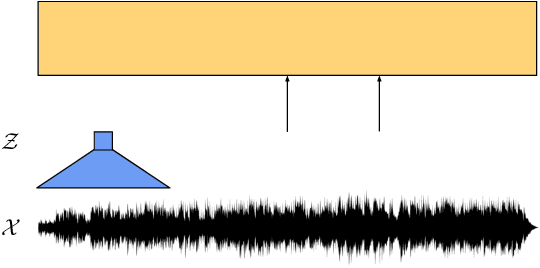
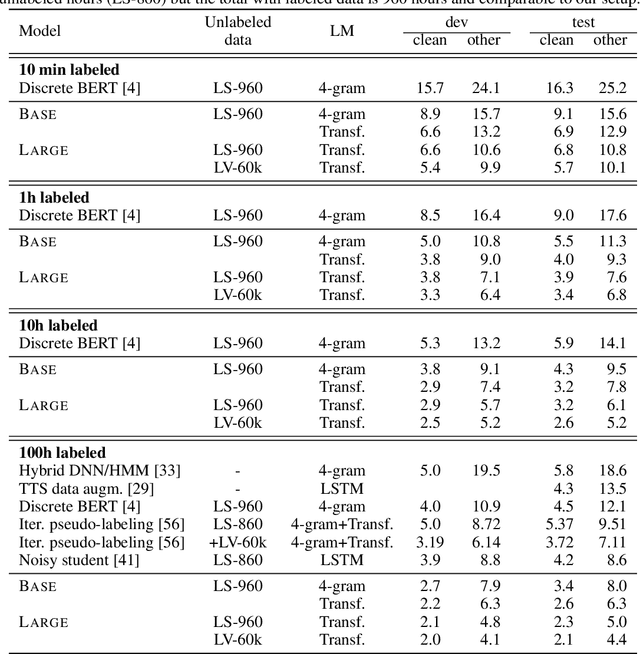
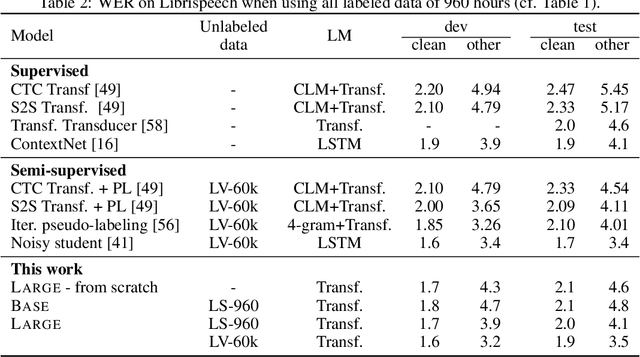
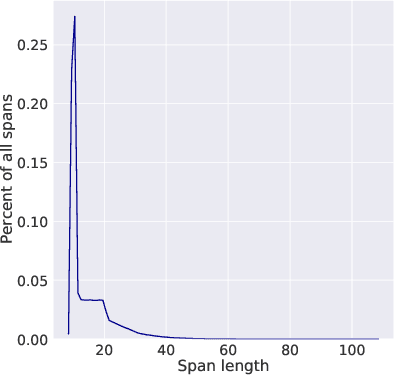
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. We set a new state of the art on both the 100 hour subset of Librispeech as well as on TIMIT phoneme recognition. When lowering the amount of labeled data to one hour, our model outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 5.7/10.1 WER on the noisy/clean test sets of Librispeech. This demonstrates the feasibility of speech recognition with limited amounts of labeled data. Fine-tuning on all of Librispeech achieves 1.9/3.5 WER using a simple baseline model architecture. We will release code and models.
Nonlinear ISA with Auxiliary Variables for Learning Speech Representations
Jul 25, 2020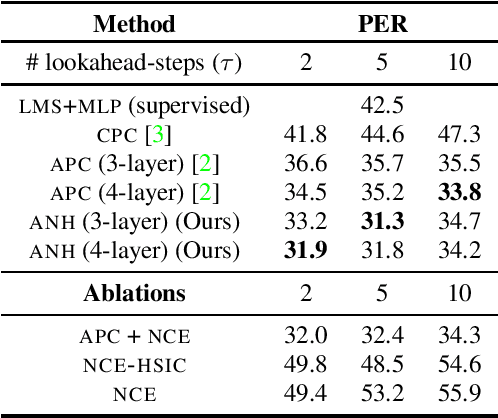
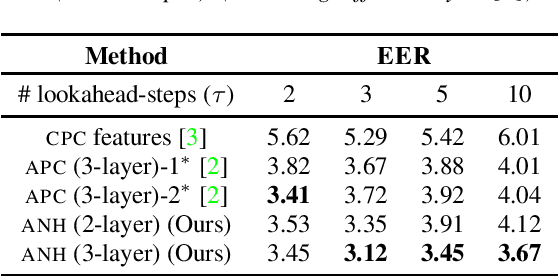
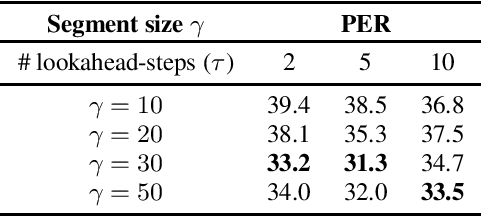
This paper extends recent work on nonlinear Independent Component Analysis (ICA) by introducing a theoretical framework for nonlinear Independent Subspace Analysis (ISA) in the presence of auxiliary variables. Observed high dimensional acoustic features like log Mel spectrograms can be considered as surface level manifestations of nonlinear transformations over individual multivariate sources of information like speaker characteristics, phonological content etc. Under assumptions of energy based models we use the theory of nonlinear ISA to propose an algorithm that learns unsupervised speech representations whose subspaces are independent and potentially highly correlated with the original non-stationary multivariate sources. We show how nonlinear ICA with auxiliary variables can be extended to a generic identifiable model for subspaces as well while also providing sufficient conditions for the identifiability of these high dimensional subspaces. Our proposed methodology is generic and can be integrated with standard unsupervised approaches to learn speech representations with subspaces that can theoretically capture independent higher order speech signals. We evaluate the gains of our algorithm when integrated with the Autoregressive Predictive Decoding (APC) model by showing empirical results on the speaker verification and phoneme recognition tasks.
Two-stage Textual Knowledge Distillation to Speech Encoder for Spoken Language Understanding
Oct 25, 2020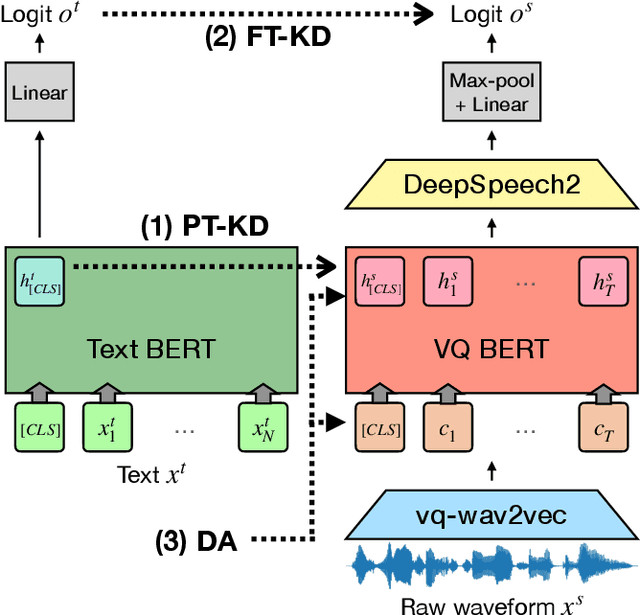
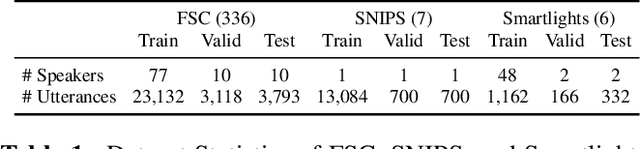
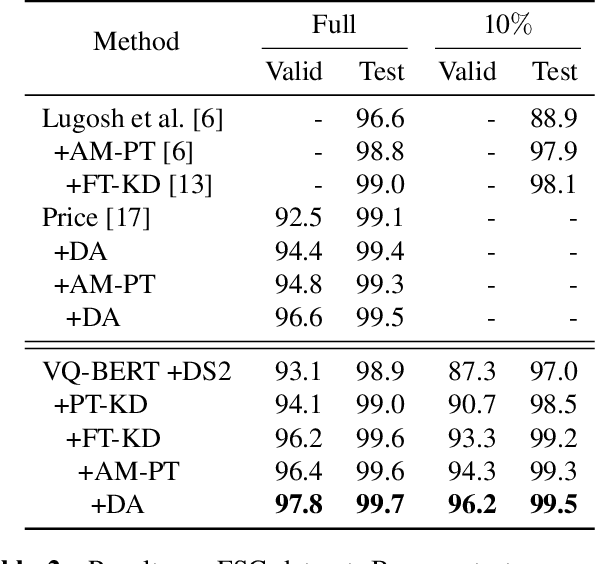
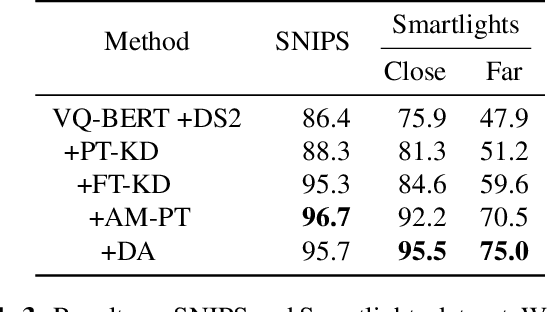
End-to-end approaches open a new way for more accurate and efficient spoken language understanding (SLU) systems by alleviating the drawbacks of traditional pipeline systems. Previous works exploit textual information for an SLU model via pre-training with automatic speech recognition or fine-tuning with knowledge distillation. To utilize textual information more effectively, this work proposes a two-stage textual knowledge distillation method that matches utterance-level representations and predicted logits of two modalities during pre-training and fine-tuning, sequentially. We use vq-wav2vec BERT as a speech encoder because it captures general and rich features. Furthermore, we improve the performance, especially in a low-resource scenario, with data augmentation methods by randomly masking spans of discrete audio tokens and contextualized hidden representations. Consequently, we push the state-of-the-art on the Fluent Speech Commands, achieving 99.7% test accuracy in the full dataset setting and 99.5% in the 10% subset setting. Throughout the ablation studies, we empirically verify that all used methods are crucial to the final performance, providing the best practice for spoken language understanding. Code to reproduce our results will be available upon publication.
Deep F-measure Maximization for End-to-End Speech Understanding
Aug 08, 2020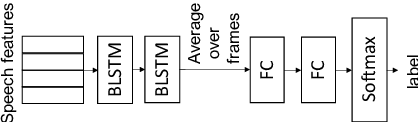
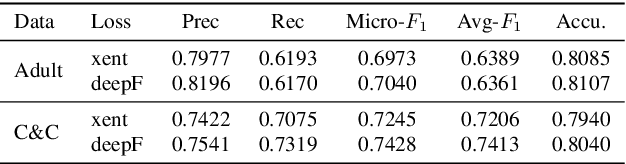
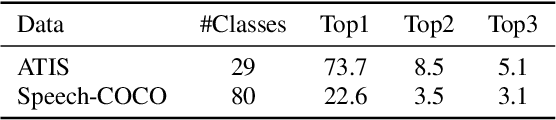
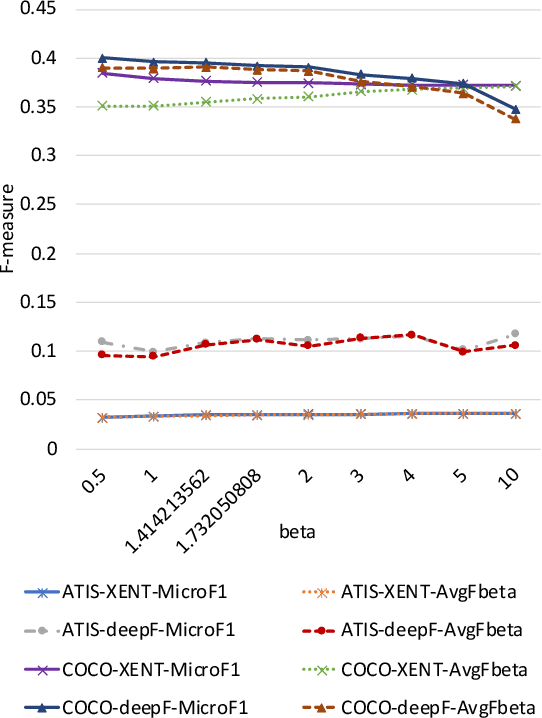
Spoken language understanding (SLU) datasets, like many other machine learning datasets, usually suffer from the label imbalance problem. Label imbalance usually causes the learned model to replicate similar biases at the output which raises the issue of unfairness to the minority classes in the dataset. In this work, we approach the fairness problem by maximizing the F-measure instead of accuracy in neural network model training. We propose a differentiable approximation to the F-measure and train the network with this objective using standard backpropagation. We perform experiments on two standard fairness datasets, Adult, and Communities and Crime, and also on speech-to-intent detection on the ATIS dataset and speech-to-image concept classification on the Speech-COCO dataset. In all four of these tasks, F-measure maximization results in improved micro-F1 scores, with absolute improvements of up to 8% absolute, as compared to models trained with the cross-entropy loss function. In the two multi-class SLU tasks, the proposed approach significantly improves class coverage, i.e., the number of classes with positive recall.
CRAB: Class Representation Attentive BERT for Hate Speech Identification in Social Media
Oct 25, 2020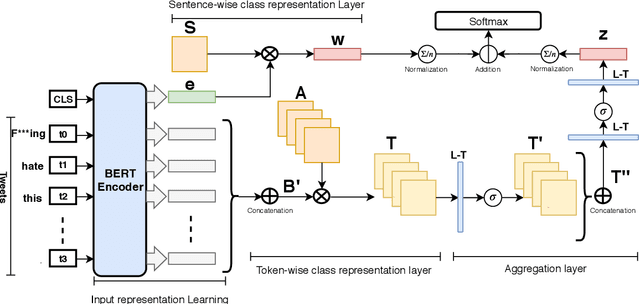
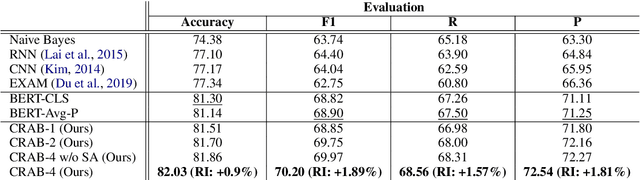
In recent years, social media platforms have hosted an explosion of hate speech and objectionable content. The urgent need for effective automatic hate speech detection models have drawn remarkable investment from companies and researchers. Social media posts are generally short and their semantics could drastically be altered by even a single token. Thus, it is crucial for this task to learn context-aware input representations, and consider relevancy scores between input embeddings and class representations as an additional signal. To accommodate these needs, this paper introduces CRAB (Class Representation Attentive BERT), a neural model for detecting hate speech in social media. The model benefits from two semantic representations: (i) trainable token-wise and sentence-wise class representations, and (ii) contextualized input embeddings from state-of-the-art BERT encoder. To investigate effectiveness of CRAB, we train our model on Twitter data and compare it against strong baselines. Our results show that CRAB achieves 1.89% relative improved Macro-averaged F1 over state-of-the-art baseline. The results of this research open an opportunity for the future research on automated abusive behavior detection in social media
Audio Self-supervised Learning: A Survey
Mar 02, 2022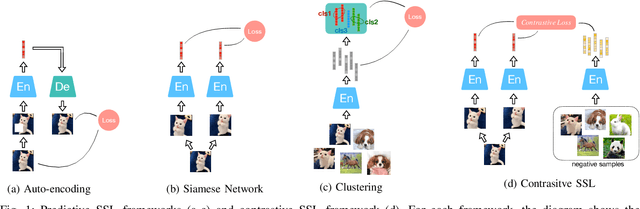
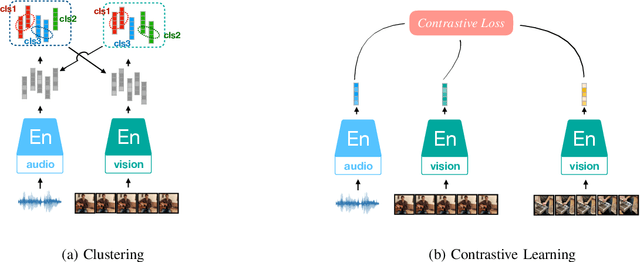
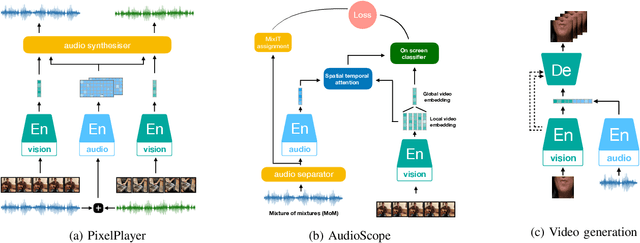
Inspired by the humans' cognitive ability to generalise knowledge and skills, Self-Supervised Learning (SSL) targets at discovering general representations from large-scale data without requiring human annotations, which is an expensive and time consuming task. Its success in the fields of computer vision and natural language processing have prompted its recent adoption into the field of audio and speech processing. Comprehensive reviews summarising the knowledge in audio SSL are currently missing. To fill this gap, in the present work, we provide an overview of the SSL methods used for audio and speech processing applications. Herein, we also summarise the empirical works that exploit the audio modality in multi-modal SSL frameworks, and the existing suitable benchmarks to evaluate the power of SSL in the computer audition domain. Finally, we discuss some open problems and point out the future directions on the development of audio SSL.