 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgewav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
Paper and Code
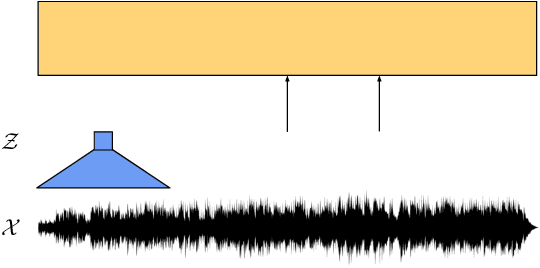
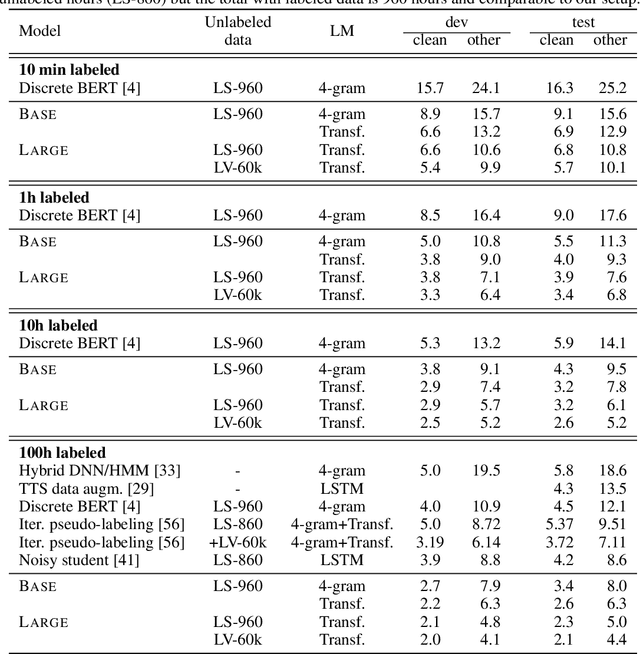
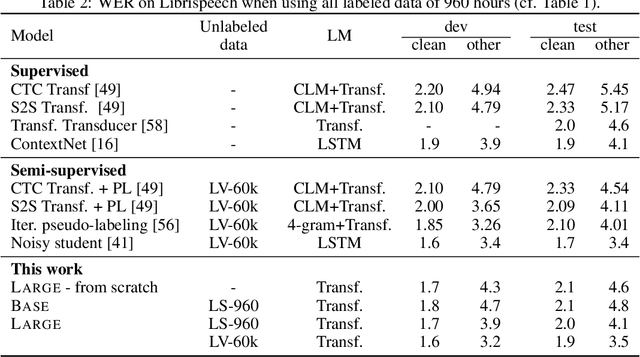
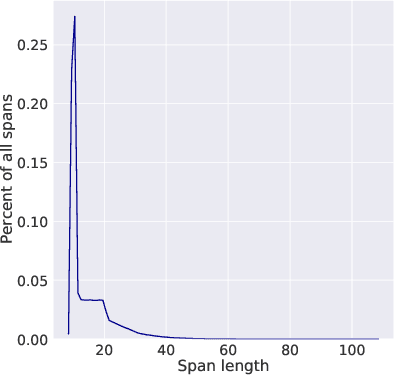
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. We set a new state of the art on both the 100 hour subset of Librispeech as well as on TIMIT phoneme recognition. When lowering the amount of labeled data to one hour, our model outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 5.7/10.1 WER on the noisy/clean test sets of Librispeech. This demonstrates the feasibility of speech recognition with limited amounts of labeled data. Fine-tuning on all of Librispeech achieves 1.9/3.5 WER using a simple baseline model architecture. We will release code and models.