 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
IIITT@LT-EDI-EACL2021-Hope Speech Detection: There is always Hope in Transformers
Apr 19, 2021

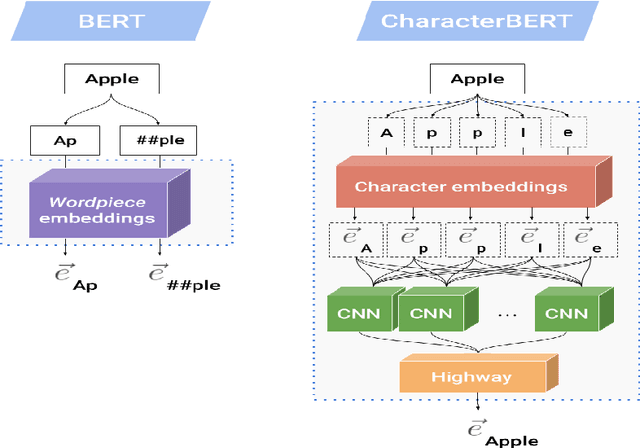
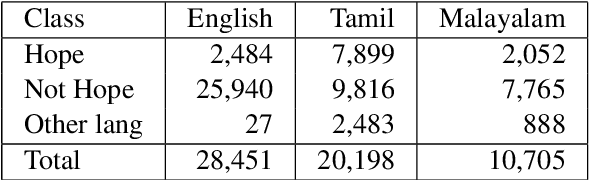
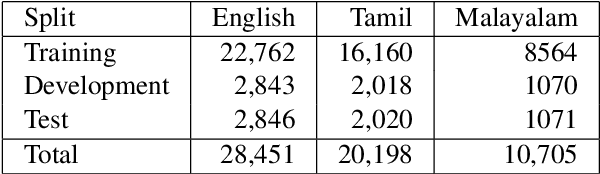
In a world filled with serious challenges like climate change, religious and political conflicts, global pandemics, terrorism, and racial discrimination, an internet full of hate speech, abusive and offensive content is the last thing we desire for. In this paper, we work to identify and promote positive and supportive content on these platforms. We work with several transformer-based models to classify social media comments as hope speech or not-hope speech in English, Malayalam and Tamil languages. This paper portrays our work for the Shared Task on Hope Speech Detection for Equality, Diversity, and Inclusion at LT-EDI 2021- EACL 2021.
Weight, Block or Unit? Exploring Sparsity Tradeoffs for Speech Enhancement on Tiny Neural Accelerators
Nov 09, 2021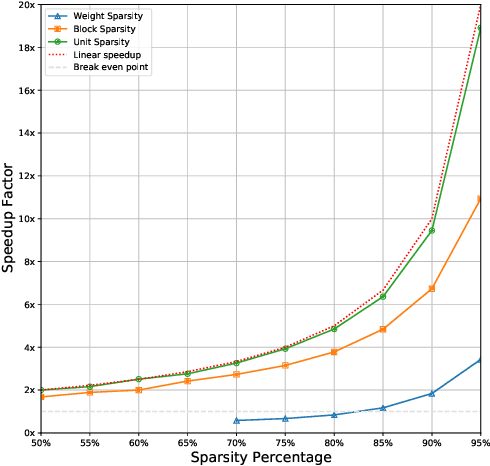
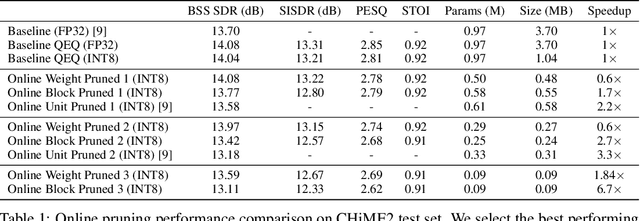
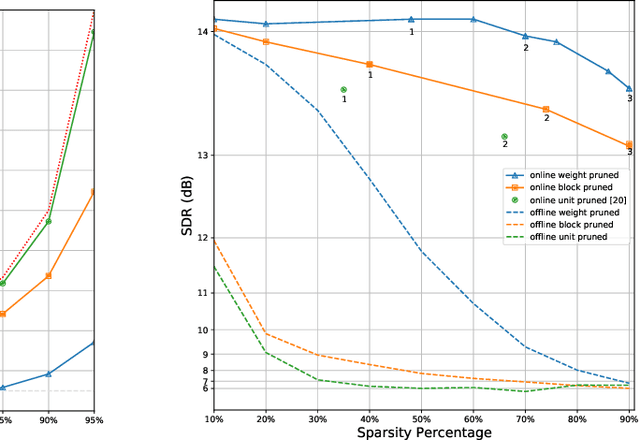

We explore network sparsification strategies with the aim of compressing neural speech enhancement (SE) down to an optimal configuration for a new generation of low power microcontroller based neural accelerators (microNPU's). We examine three unique sparsity structures: weight pruning, block pruning and unit pruning; and discuss their benefits and drawbacks when applied to SE. We focus on the interplay between computational throughput, memory footprint and model quality. Our method supports all three structures above and jointly learns integer quantized weights along with sparsity. Additionally, we demonstrate offline magnitude based pruning of integer quantized models as a performance baseline. Although efficient speech enhancement is an active area of research, our work is the first to apply block pruning to SE and the first to address SE model compression in the context of microNPU's. Using weight pruning, we show that we are able to compress an already compact model's memory footprint by a factor of 42x from 3.7MB to 87kB while only losing 0.1 dB SDR in performance. We also show a computational speedup of 6.7x with a corresponding SDR drop of only 0.59 dB SDR using block pruning.
A Time-domain Generalized Wiener Filter for Multi-channel Speech Separation
Dec 07, 2021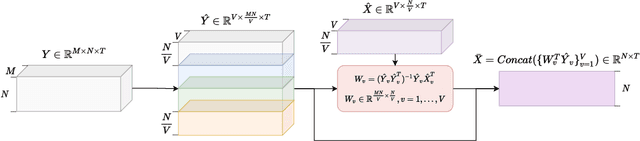
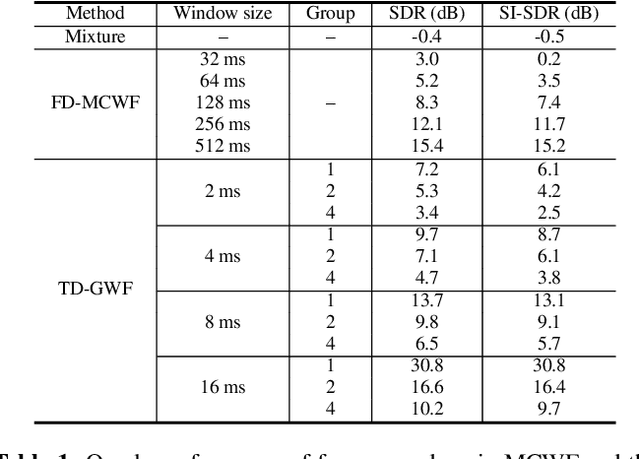
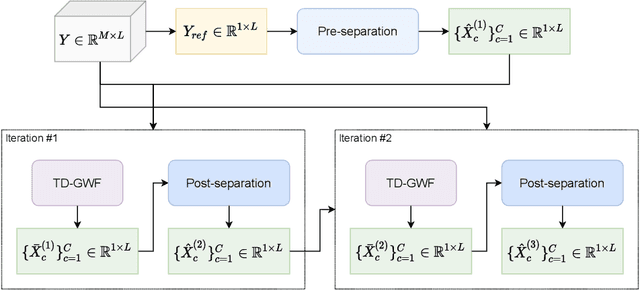

Frequency-domain neural beamformers are the mainstream methods for recent multi-channel speech separation models. Despite their well-defined behaviors and the effectiveness, such frequency-domain beamformers still have the limitations of a bounded oracle performance and the difficulties of designing proper networks for the complex-valued operations. In this paper, we propose a time-domain generalized Wiener filter (TD-GWF), an extension to the conventional frequency-domain beamformers that has higher oracle performance and only involves real-valued operations. We also provide discussions on how TD-GWF can be connected to conventional frequency-domain beamformers. Experiment results show that a significant performance improvement can be achieved by replacing frequency-domain beamformers by the TD-GWF in the recently proposed sequential neural beamforming pipelines.
Adversarial synthesis based data-augmentation for code-switched spoken language identification
May 30, 2022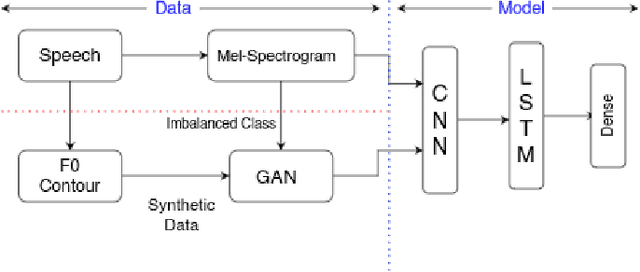
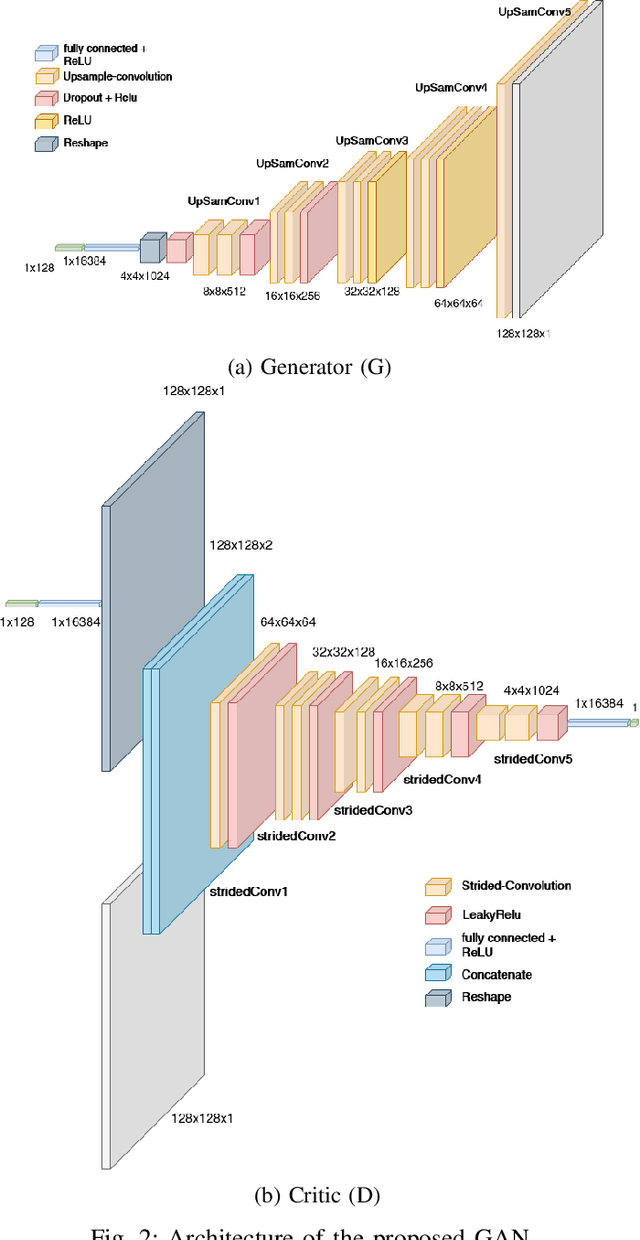
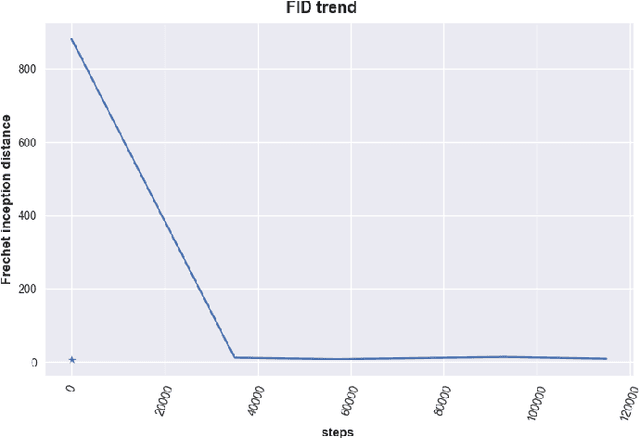
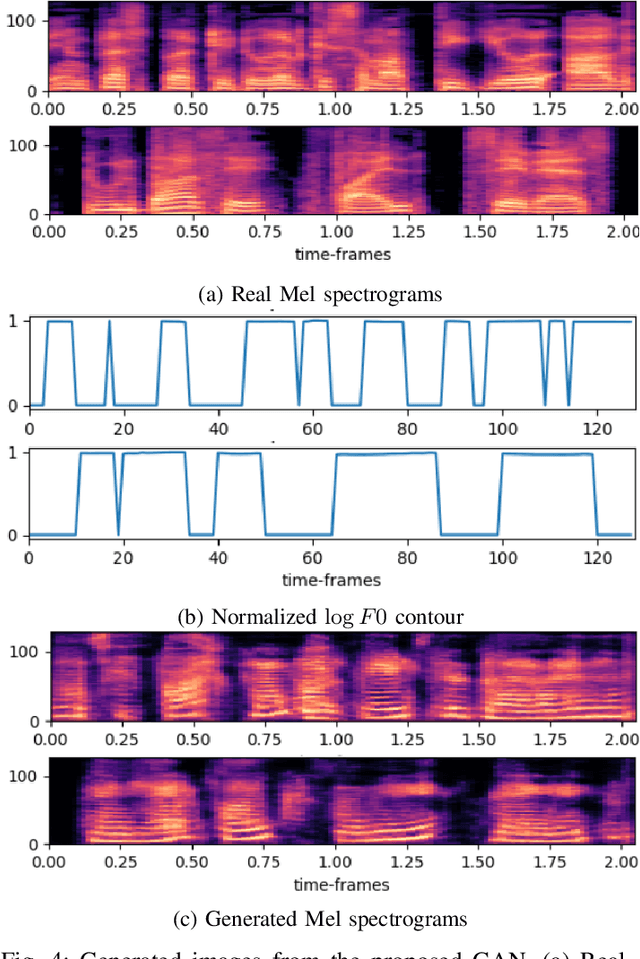
Spoken Language Identification (LID) is an important sub-task of Automatic Speech Recognition(ASR) that is used to classify the language(s) in an audio segment. Automatic LID plays an useful role in multilingual countries. In various countries, identifying a language becomes hard, due to the multilingual scenario where two or more than two languages are mixed together during conversation. Such phenomenon of speech is called as code-mixing or code-switching. This nature is followed not only in India but also in many Asian countries. Such code-mixed data is hard to find, which further reduces the capabilities of the spoken LID. Due to the lack of avalibility of this code-mixed data, it becomes a minority class in LID task. Hence, this work primarily addresses this problem using data augmentation as a solution on the minority code-switched class. This study focuses on Indic language code-mixed with English. Spoken LID is performed on Hindi, code-mixed with English. This research proposes Generative Adversarial Network (GAN) based data augmentation technique performed using Mel spectrograms for audio data. GANs have already been proven to be accurate in representing the real data distribution in the image domain. Proposed research exploits these capabilities of GANs in speech domains such as speech classification, automatic speech recognition,etc. GANs are trained to generate Mel spectrograms of the minority code-mixed class which are then used to augment data for the classifier. Utilizing GANs give an overall improvement on Unweighted Average Recall by an amount of 3.5\% as compared to a Convolutional Recurrent Neural Network (CRNN) classifier used as the baseline reference.
Unsupervised Mismatch Localization in Cross-Modal Sequential Data
May 05, 2022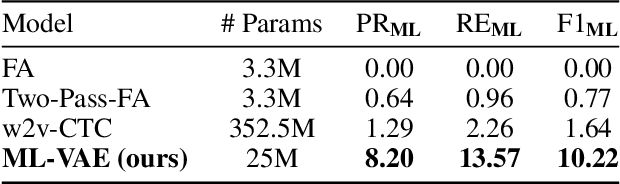


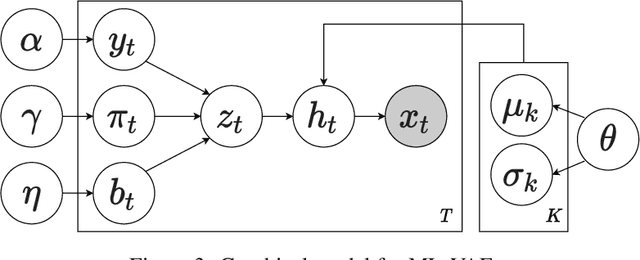
Content mismatch usually occurs when data from one modality is translated to another, e.g. language learners producing mispronunciations (errors in speech) when reading a sentence (target text) aloud. However, most existing alignment algorithms assume the content involved in the two modalities is perfectly matched and thus leading to difficulty in locating such mismatch between speech and text. In this work, we develop an unsupervised learning algorithm that can infer the relationship between content-mismatched cross-modal sequential data, especially for speech-text sequences. More specifically, we propose a hierarchical Bayesian deep learning model, named mismatch localization variational autoencoder (ML-VAE), that decomposes the generative process of the speech into hierarchically structured latent variables, indicating the relationship between the two modalities. Training such a model is very challenging due to the discrete latent variables with complex dependencies involved. We propose a novel and effective training procedure which estimates the hard assignments of the discrete latent variables over a specifically designed lattice and updates the parameters of neural networks alternatively. Our experimental results show that ML-VAE successfully locates the mismatch between text and speech, without the need for human annotations for model training.
CAB: Comprehensive Attention Benchmarking on Long Sequence Modeling
Oct 19, 2022
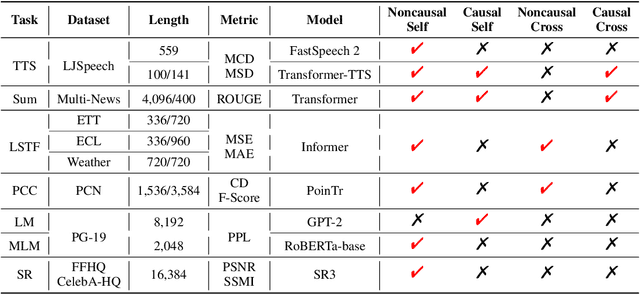
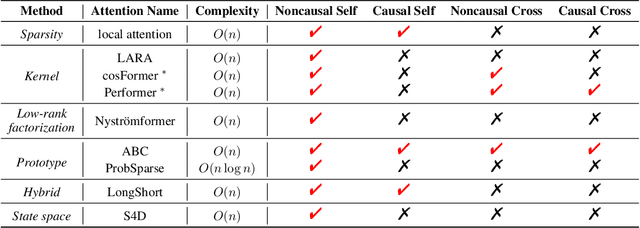
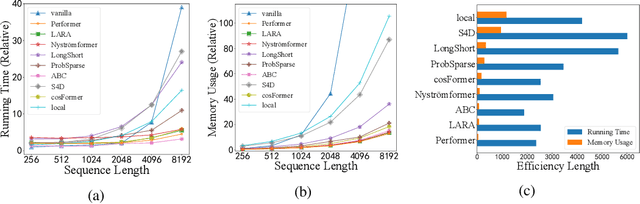
Transformer has achieved remarkable success in language, image, and speech processing. Recently, various efficient attention architectures have been proposed to improve transformer's efficiency while largely preserving its efficacy, especially in modeling long sequences. A widely-used benchmark to test these efficient methods' capability on long-range modeling is Long Range Arena (LRA). However, LRA only focuses on the standard bidirectional (or noncausal) self attention, and completely ignores cross attentions and unidirectional (or causal) attentions, which are equally important to downstream applications. Although designing cross and causal variants of an attention method is straightforward for vanilla attention, it is often challenging for efficient attentions with subquadratic time and memory complexity. In this paper, we propose Comprehensive Attention Benchmark (CAB) under a fine-grained attention taxonomy with four distinguishable attention patterns, namely, noncausal self, causal self, noncausal cross, and causal cross attentions. CAB collects seven real-world tasks from different research areas to evaluate efficient attentions under the four attention patterns. Among these tasks, CAB validates efficient attentions in eight backbone networks to show their generalization across neural architectures. We conduct exhaustive experiments to benchmark the performances of nine widely-used efficient attention architectures designed with different philosophies on CAB. Extensive experimental results also shed light on the fundamental problems of efficient attentions, such as efficiency length against vanilla attention, performance consistency across attention patterns, the benefit of attention mechanisms, and interpolation/extrapolation on long-context language modeling.
Reducing language context confusion for end-to-end code-switching automatic speech recognition
Jan 28, 2022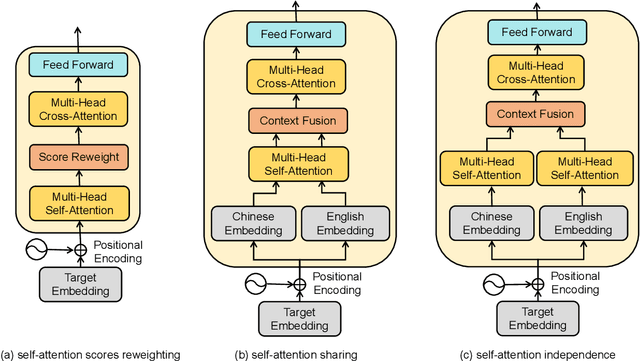
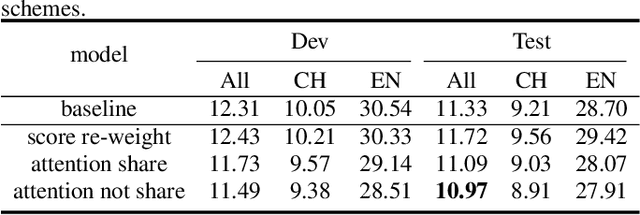
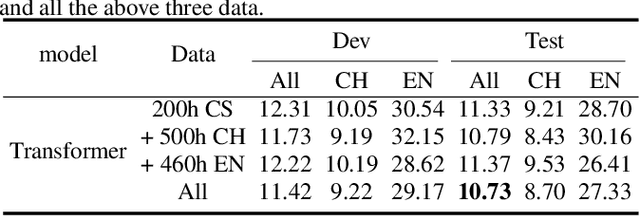
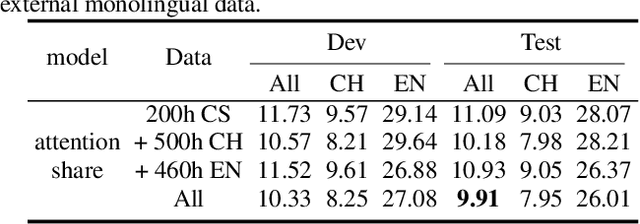
Code-switching is about dealing with alternative languages in the communication process. Training end-to-end (E2E) automatic speech recognition (ASR) systems for code-switching is known to be a challenging problem because of the lack of data compounded by the increased language context confusion due to the presence of more than one language. In this paper, we propose a language-related attention mechanism to reduce multilingual context confusion for the E2E code-switching ASR model based on the Equivalence Constraint Theory (EC). The linguistic theory requires that any monolingual fragment that occurs in the code-switching sentence must occur in one of the monolingual sentences. It establishes a bridge between monolingual data and code-switching data. By calculating the respective attention of multiple languages, our method can efficiently transfer language knowledge from rich monolingual data. We evaluate our method on ASRU 2019 Mandarin-English code-switching challenge dataset. Compared with the baseline model, the proposed method achieves 11.37% relative mix error rate reduction.
Advancing Speech Recognition With No Speech Or With Noisy Speech
Jul 17, 2019
In this paper we demonstrate end to end continuous speech recognition (CSR) using electroencephalography (EEG) signals with no speech signal as input. An attention model based automatic speech recognition (ASR) and connectionist temporal classification (CTC) based ASR systems were implemented for performing recognition. We further demonstrate CSR for noisy speech by fusing with EEG features.
Meta-Learning for Adaptive Filters with Higher-Order Frequency Dependencies
Sep 20, 2022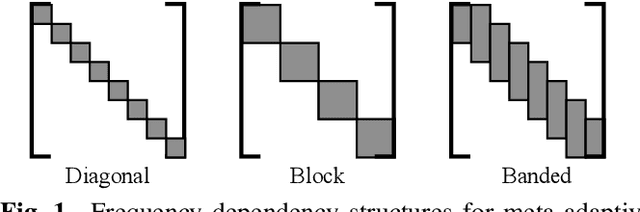
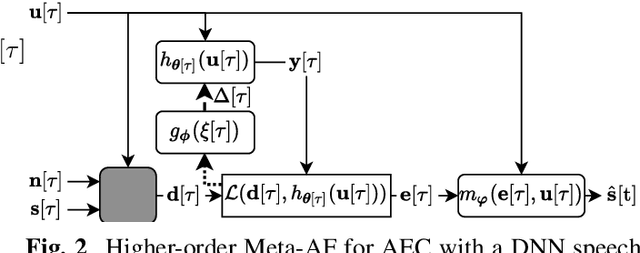
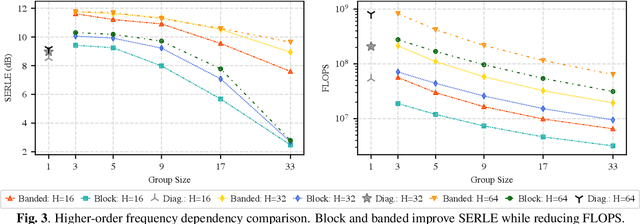
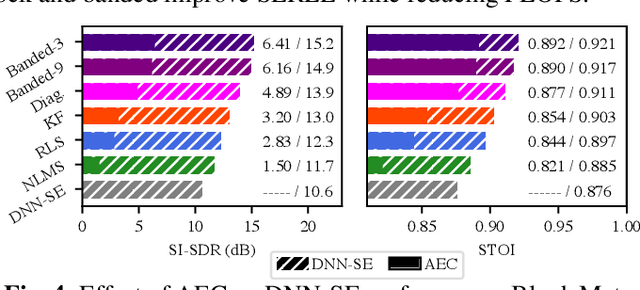
Adaptive filters are applicable to many signal processing tasks including acoustic echo cancellation, beamforming, and more. Adaptive filters are typically controlled using algorithms such as least-mean squares(LMS), recursive least squares(RLS), or Kalman filter updates. Such models are often applied in the frequency domain, assume frequency independent processing, and do not exploit higher-order frequency dependencies, for simplicity. Recent work on meta-adaptive filters, however, has shown that we can control filter adaptation using neural networks without manual derivation, motivating new work to exploit such information. In this work, we present higher-order meta-adaptive filters, a key improvement to meta-adaptive filters that incorporates higher-order frequency dependencies. We demonstrate our approach on acoustic echo cancellation and develop a family of filters that yield multi-dB improvements over competitive baselines, and are at least an order-of-magnitude less complex. Moreover, we show our improvements hold with or without a downstream speech enhancer.
Multiple-hypothesis RNN-T Loss for Unsupervised Fine-tuning and Self-training of Neural Transducer
Jul 29, 2022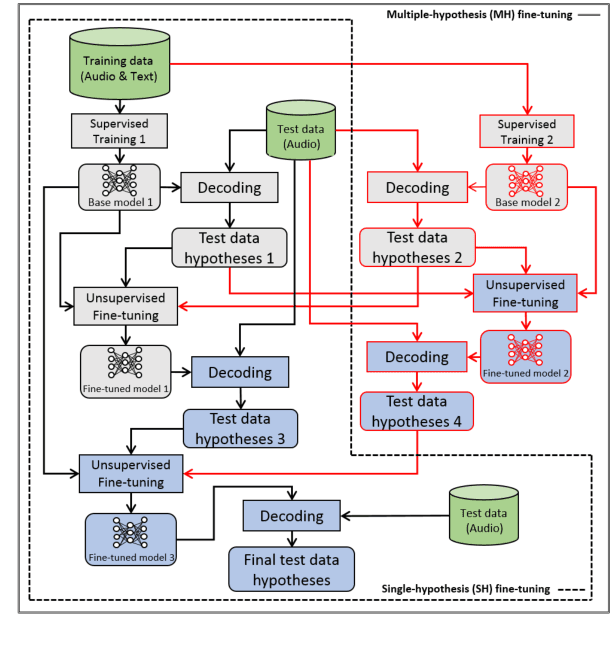
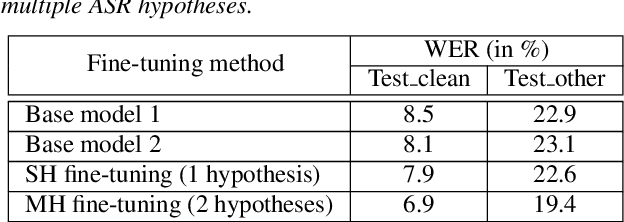
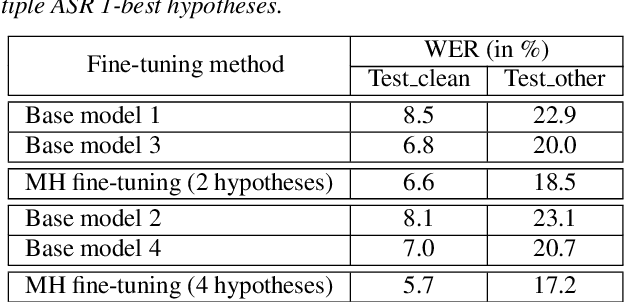
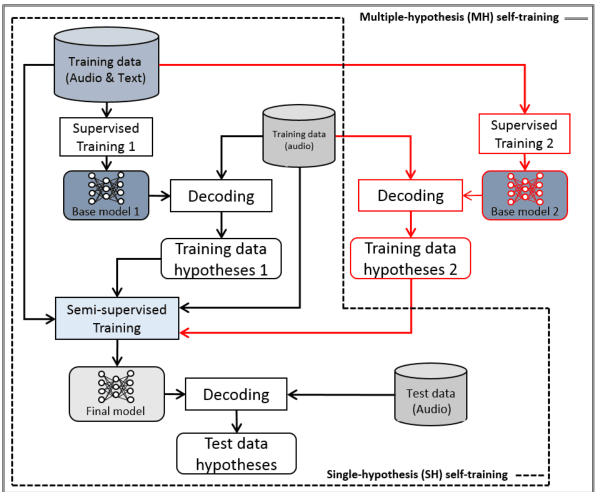
This paper proposes a new approach to perform unsupervised fine-tuning and self-training using unlabeled speech data for recurrent neural network (RNN)-Transducer (RNN-T) end-to-end (E2E) automatic speech recognition (ASR) systems. Conventional systems perform fine-tuning/self-training using ASR hypothesis as the targets when using unlabeled audio data and are susceptible to the ASR performance of the base model. Here in order to alleviate the influence of ASR errors while using unlabeled data, we propose a multiple-hypothesis RNN-T loss that incorporates multiple ASR 1-best hypotheses into the loss function. For the fine-tuning task, ASR experiments on Librispeech show that the multiple-hypothesis approach achieves a relative reduction of 14.2% word error rate (WER) when compared to the single-hypothesis approach, on the test_other set. For the self-training task, ASR models are trained using supervised data from Wall Street Journal (WSJ), Aurora-4 along with CHiME-4 real noisy data as unlabeled data. The multiple-hypothesis approach yields a relative reduction of 3.3% WER on the CHiME-4's single-channel real noisy evaluation set when compared with the single-hypothesis approach.